#148 위클리 딥 다이브 | 2026년 6월 17일
이번주 뉴스레터에는 이런 내용을 담았어요!
- World Model이 제안된 초기 개념을 설명합니다.
- World Model이 발전해온 과정과 분화된 개념을 정리합니다.
- World Model의 최근 연구 과제를 소개합니다.
World Model은 어떻게 진화해왔나
안녕하세요, 에디터 배니입니다.
올 6월 들어 AI 업계에는 여러 이슈가 있었습니다. OpenAI는 IPO를 준비 중이라고 밝혔고, 올해 4분기에 상장될 것으로 전망하고 있습니다. Anthropic이 출시한 Fable 5는 국가 안보를 침해할 수 있다는 이유로 공개 3일만에 서비스를 중단해야 했습니다. 각각의 사안을 면면이 들여다 보면 또 전달드리고 싶은 내용이 많지만, 이번주 준비한 내용은 조금 다른 내용입니다.
바로 World Model입니다. AI와 경제, AI와 거버넌스도 모두 중요하지만 AI 연구에서는 World Model 분야의 조짐이 심상치 않습니다. NVIDIA는 지난 1일, COMPUTEX(GTC Taipei)에서 Physical AI를 위한 World Model인 Cosmos 3를 공개했는데요. 지난해 10월 COSMOS 2를 공개한 지 8개월만입니다.
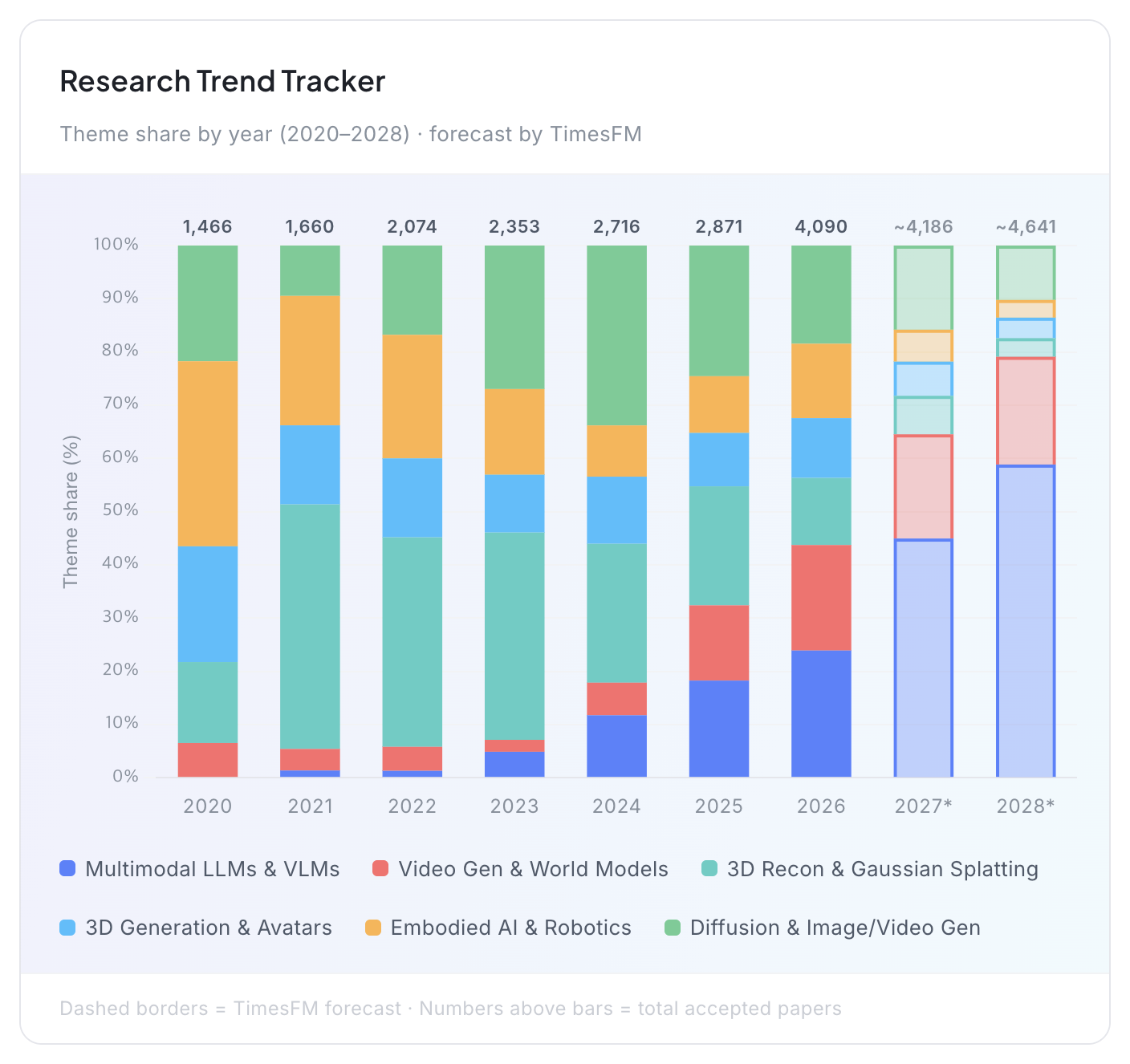
출처: Bohrium Blog, CVPR 2026 Accepted Papers: Trends, Big Tech Bets & Top Highlights
또한 지난 3일부터 7일까지 덴버에서 개최된 CVPR 2026에서도 World Model과 관련된 논문들이 두드러졌습니다. 과학 연구를 위한 AI를 분석하는 Bohrium의 분석에 따르면, 비디오 생성과 World Model 관련 발표는 하이라이트 기준으로 3.8%에서 8.8%로 지난해 대비 약 2.3배 늘었고, 전체에서 두 번째로 큰 테마가 됐습니다.
이러한 연구 흐름이 시사하는 바는 무엇일까요? World Models의 개념이 획일화되지 않고 분화되어 다양한 연구로 이어지고 있다는 것입니다. 이번주 뉴스레터에서는 World Model의 발전해온 흐름을 소개합니다.
World Model의 개념은 어떻게 달라져 왔나
World Model(세계 모델)을 한마디로 정의하기는 생각보다 어렵습니다. 전 Meta AI 수석인 Yann LeCun(얀 르쿤)이 'LLM은 세계의 물리 법칙을 모른다'며, 세계의 모든 정보를 통합해 이해할 수 있는 World Model을 제안하며 다시 화두에 올랐는데요. 그가 던진 문제의식은 분명합니다. 지금의 언어 모델은 텍스트 속 통계적 패턴은 잘 맞히지만, 컵을 떨어뜨리면 깨진다는 식의 물리적 인과는 직접 겪어본 적이 없다는 겁니다. 그러니 텍스트가 아니라 세계 그 자체를 모형으로 가진 AI가 필요하다는 것이죠.
사실 World Model이라는 개념이 얀 르쿤에게서 처음 나온 건 아닙니다. 본격적으로 이름을 알린 건 2018년 David Ha와 Jürgen Schmidhuber가 발표한 논문 <World Models>였습니다. 발상 자체는 단순합니다. 사람이 세상을 이해하듯이, AI에게도 유사한 방식으로 해석하도록 만드는 것입니다. 사람은 눈앞의 모든 정보를 일일이 처리하지 않습니다. 머릿속에 세계를 압축한 모형을 만들어둔 뒤, 그 모형으로 다음에 벌어질 일을 미리 그려보죠. AI에게도 우리가 이미 알고 있는 정답을 제공하는 것이 아니라, 세계를 먼저 이해할 수 있도록 학습한 뒤에 다음에 일어날 수 있는 일을 예측하도록 만드는 것입니다.
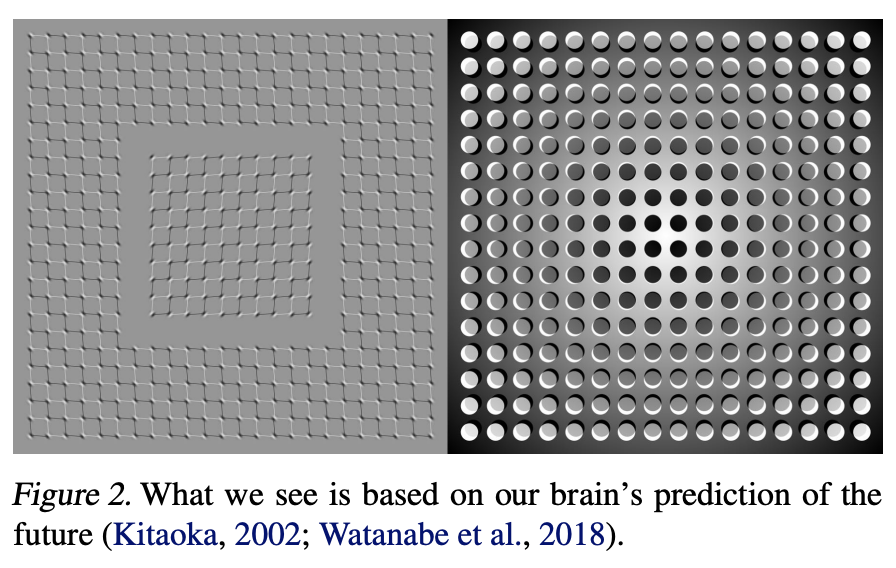
출처: World Models (Ha & Schmidhuber, 2018)
이와 같이 얀 르쿤의 World Model은 세계를 추상적으로 '이해'하는 데 방점을 두고, 비지도 학습 방식으로 레이블 없는 관찰한 그 데이터 그 자체만으로 세계가 돌아가는 규칙을 스스로 익힙니다. 여기서 중요한 점은, 눈에 보이는 픽셀을 하나하나 복원하는 게 아니라 예측 가능한 부분만 추상적인 표현으로 압축해 맞히고 나머지 사소한 디테일은 과감히 버린다는 것입니다. 이렇듯 얀 르쿤의 World Model은 무언가를 '그려내는' 모델이라기보다, 다음에 벌어질 일을 머릿속에서 가늠하는 것에 가깝습니다.
그런데 World Model과 유사한 개념이 다른 이름으로 등장합니다. 2024년 2월, OpenAI가 Sora를 공개하며 비디오 생성 모델을 World Simulator(세계 시뮬레이터)로 규정한 겁니다. 영상을 그럴듯하게 만들어내는 능력 자체가 곧 세계를 시뮬레이션하는 능력이라는 프레임을 만들어 낸 것입니다. 이는 르쿤이 말한 '이해'와는 다르게, 세계를 '다시 그려내는' 데 방점이 찍혀 있습니다. 조금 더 시각 생성에 가까운 개념으로 인식된 것입니다.

World Model의 방향이 본격적으로 달라진 건 2025년 1월 CES입니다. NVIDIA가 Physical AI(피지컬 AI, 현실 세계에서 직접 움직이는 AI)를 전면에 내세우며, 로봇과 자율주행을 위한 파운데이션 World Foundation Model로 Cosmos를 공개했습니다. Meta에서눈 아마 똑같이 World Model을 표방하며 JEPA 시리즈의 연구 논문을 공개하고 있었는데요. 이때부터 World Model의 방향성은 크게 두 갈래로 달라졌습니다.
Genie와 Waymo, 생성된 세계 속으로
최근 World Model 연구의 흐름은 초기 세계를 ‘생성’하는 데 초점을 맞추고 있습니다. 대표적인 사례는 Google DeepMind의 Genie입니다. Sora가 공개된 지 한 달이 채 되지 않아 2024년 3월 공개된 Genie 1은 인터넷 영상만으로 학습해, 이미지 한 장을 주면 그 안에서 직접 움직여볼 수 있는 2D 인터랙티브 환경을 만들어냈습니다. 핵심은 '플레이할 수 있는' 세계라는 점입니다. 단순히 영상을 재생하는 게 아니라, 사용자가 행동을 입력하면 다음 장면이 그에 맞춰 생성됩니다. 흥미롭게도 Genie는 영상에 행동 레이블이 없어도 Latent Action(잠재 행동)을 스스로 학습합니다.
이후 Genie 2(2024년 12월)는 3D로 차원을 넓혔고, Genie 3(2025년 8월)에서는 실시간 상호작용과 수 분 단위의 일관성(720p/24fps)을 확보했습니다. 즉, 사용자가 한참 생성된 맵에서 돌아다녀도 방금 본 장면이 어그러지지 않고 유지되는 수준에 이른 겁니다. 오랫동안 화제를 일으킨 Genie 모델은 마침내 2026년 1월, Project Genie라는 이름으로 제품화돼, AI Ultra 구독자가 직접 써볼 수 있게 됐습니다.
그리고 2026년 2월, Waymo는 Genie 3를 기반으로 한 Waymo World Model을 공개하며, 자율주행 시뮬레이션의 핵심 엔진으로 투입했습니다. Genie가 게임 속 세계를 모델링했다면 Waymo는 실제 세계를 모델링한 것입니다. Waymo는 Genie 3를 자율주행 도메인에 맞게 추가 학습하여, 카메라 영상뿐 아니라 라이다(Lidar) 포인트 클라우드까지, 시간적으로 일관되게 함께 생성합니다. 쉽게 말하면, Waymo Driver가 실제 도로에서 받아들이는 센서 신호와 똑같은 형태로 가상의 관측을 만들어내는 것이죠. 덕분에 자율주행 스택은 이 가상 데이터를 실제 주행 로그와 같은 조건으로 그대로 소비할 수 있습니다.
그렇다면 왜 굳이 World Model을 쓸까요? 가장 큰 이유는 '롱테일(Long-tail)' 상황 때문입니다. 대부분의 자율주행 시뮬레이터는 자사 차량이 실제로 수집한 데이터로만 학습하기 때문에, 차량이 겪어본 날씨·도로·교통 상황 안에만 갇혀 있습니다. 반면 Waymo World Model은 Genie 3가 방대한 영상으로 사전학습하며 쌓은 폭넓은 세계 지식을 빌려옵니다. 덕분에 토네이도, 물에 잠긴 도로, 눈 덮인 Golden Gate Bridge, 심지어 도로 위의 코끼리처럼 현실에서 일부러 만들어내기 어렵거나 위험한 상황까지 생성해낼 수 있습니다. 현실에서 자주 마주치기 힘든 안전 위험 상황을, 생성된 세계 안에서 미리 굴려보며 대비하는 셈이죠.
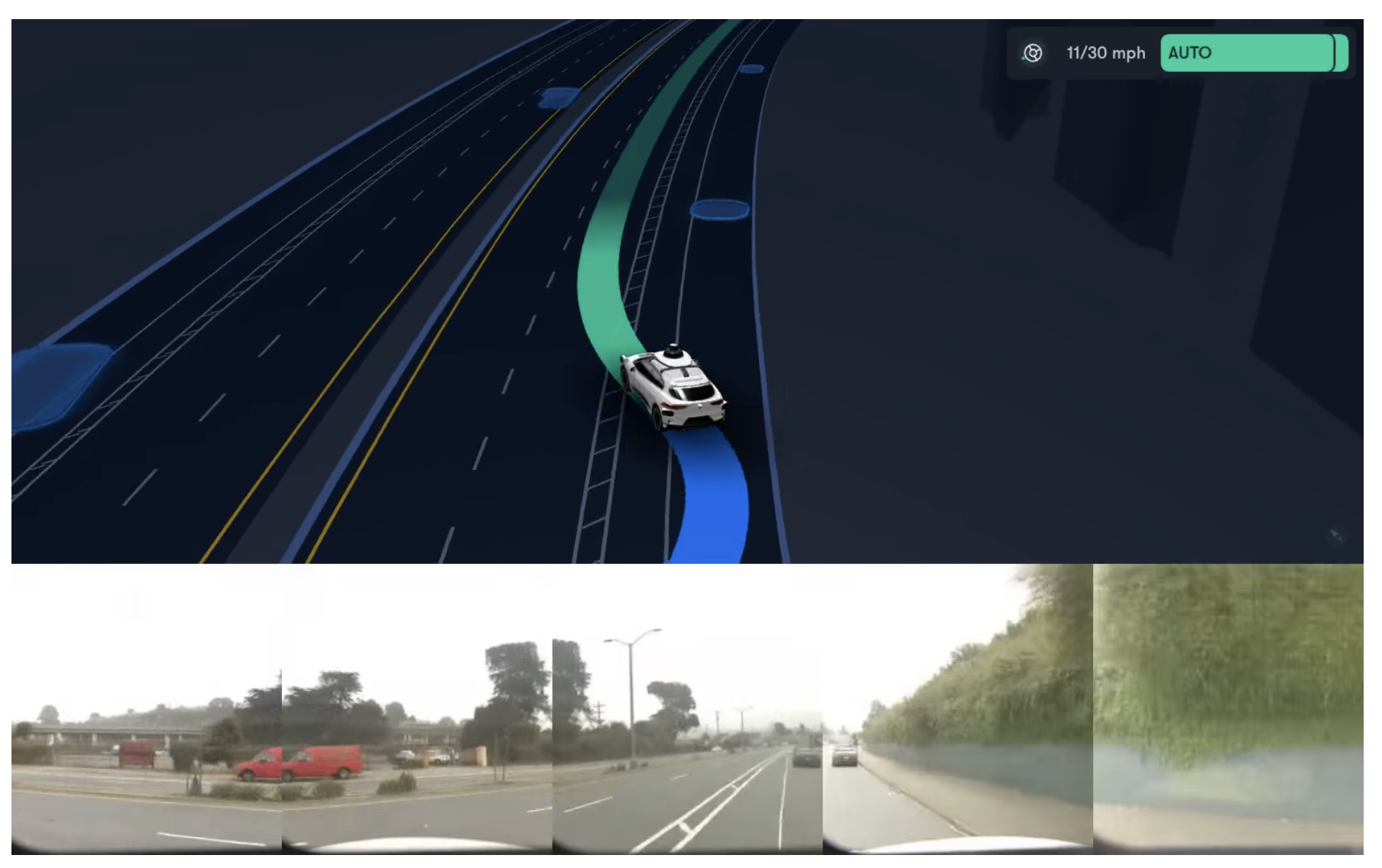
출처: Waymo Blog, The Waymo World Model: A New Frontier For Autonomous Driving Simulation
여기에 더해, 엔지니어가 언어 프롬프트나 주행 입력, 장면 배치만으로 상황을 자유롭게 바꿀 수 있고, 대시캠이나 휴대폰으로 찍은 평범한 영상을 멀티센서 시뮬레이션으로 변환할 수도 있습니다. Waymo는 이미 공공 도로에서 약 2억 마일을 완전 자율로 주행했는데, 그 뒤에는 수십억 마일에 달하는 가상 주행이 있었습니다. 이 연구는 이후로도 이어져, 2026년 5월에는 Google Street View와 연동해 실제 거리를 그대로 시뮬레이션하는 단계까지 나아갔습니다.
CVPR에서 보여준 World Model의 트렌드는?
World Model은 이제 이해에 그치지 않습니다. 물론, 그 기저에는 임베딩 수준에서 추상화된 세계의 개념을 활용하고 있기는 지만 실용적인 이유로 ‘생성 모델’에 가깝게 이해되고 있습니다. 이번 CVPR Highlight로 선정된 두 편의 World Model 논문을 살펴보겠습니다.
- NeoVerse: 평범한 영상 한 편으로 4D로
첫 번째는 〈NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos〉입니다. CASIA와 CreateAI 연구진이 발표했고, CVPR 2026 Highlight이자 VideoWorldModel 워크숍 Best Paper로 선정됐습니다.
출처: NeoVerse Blog
여기서 4D란 3차원 공간(3D)에 시간 축을 더한 것입니다. 장면의 입체 구조뿐 아니라, 그 구조가 시간에 따라 어떻게 움직이는지까지 모델링한다는 뜻이죠. 문제는 이런 4D 모델을 만들기가 까다로웠다는 점입니다. 기존 방식은 여러 대의 카메라를 동기화한 멀티뷰 촬영 장비가 필요하거나, 깊이와 카메라 위치(Pose)를 따로 추정하는 전처리를 거쳐야 했습니다. 그러다 보니 실험실 밖의 다양한 영상으로 확장하기가 어려웠습니다. 연구진은 이를 '4D 데이터 병목'이라고 부릅니다.
NeoVerse는 이 병목을 정면으로 겨냥합니다. 핵심은 카메라 한 대로 아무렇게나 찍은 영상만으로 4D 장면을 복원한다는 점입니다. 카메라 위치 정보가 없어도 되고(Pose-free), 장면마다 따로 최적화하지 않고 한 번의 순전파로 처리합니다. 실제로 학습에 필요한 건 RGB 영상과 텍스트 프롬프트뿐이고, 3D 구조와 카메라 경로는 모델이 그 자리에서 알아서 추정합니다. 덕분에 인터넷에 널린 방대한 영상을 그대로 학습 재료로 쓸 수 있게 됐습니다.
NeoVerse는 단안(Monocular) 영상에서 4D Gaussian Splatting(4DGS)을 복원한 뒤, 그것을 일부러 '망가진' 시점으로 렌더링합니다. 그리고 이 저품질 렌더링을 다시 고품질의, 시공간적으로 일관된 영상으로 되돌리도록 생성 모델을 학습시키죠. 쉽게 말하면, 일부러 흐릿하게 만든 장면을 선명하게 복원하는 연습을 시키는 셈입니다. 여기에 듬성듬성한 키프레임 사이를 양방향으로 보간하는 기법을 더해, 새로운 카메라 경로로 움직여도 장면이 매끄럽게 이어지도록 합니다.
이 방식의 강점은 속도와 확장성입니다. 비슷한 계열의 기존 방법(TrajectoryCrafter)이 81프레임 영상에 150초 넘게 걸렸다면, NeoVerse는 같은 작업을 20초 안팎으로 끝냅니다(A800 GPU 기준). 평범한 영상 한 편을 '돌아다닐 수 있는 4D 디지털 트윈'으로 바꾸는 일이, 이제 실험실 장비 없이도 가능해진 것입니다.
- A Frame is Worth One Token: 프레임 하나를 토큰 하나로
두 번째는 이번에 특히 눈에 띄는 〈A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens〉입니다. Amazon과 Eindhoven University of Technology 연구진이 발표했고, 역시 CVPR 2026 Highlight로 선정됐습니다.
영상에서 인접한 두 프레임은 대부분 비슷합니다. 카메라가 조금 움직이거나 물체 하나가 이동할 뿐, 화면 대부분은 그대로죠. 그런데 기존 생성형 World Model은 매 프레임을 수많은 토큰으로 표현하고, 그 프레임을 통째로 다시 만들어냅니다. 바뀌지 않은 부분까지 매번 새로 생성하니 연산이 무거울 수밖에 없습니다. 이 연구는 이 문제를 지적합니다.
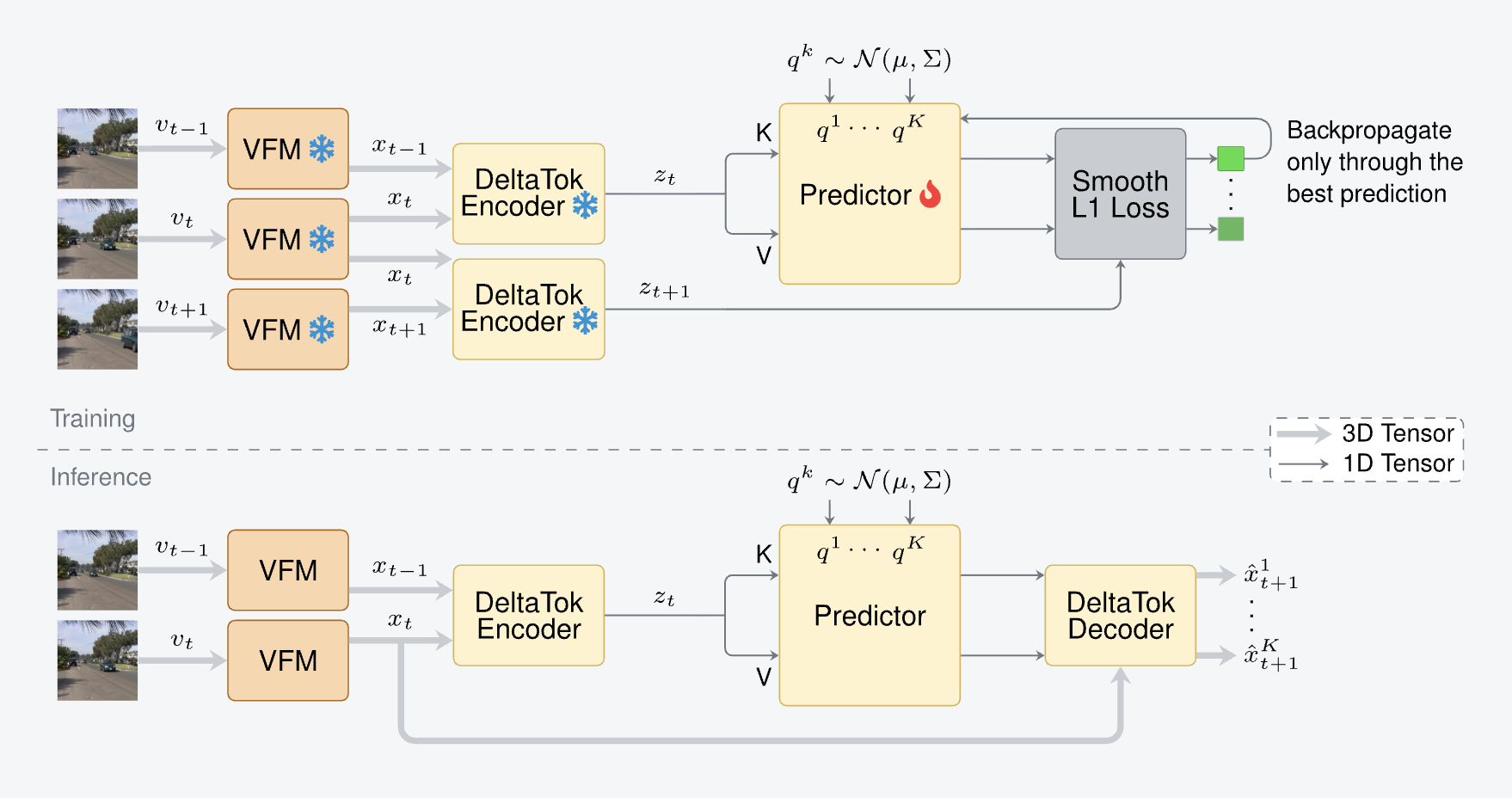
출처: A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens Blog
연구진은 프레임 전체가 아니라, 연속된 두 프레임 사이의 '변화량'만 하나의 Delta Token으로 압축했습니다. 어떻게 달라졌는지 예측하며 전체 그림을 새롭게 그리는 것이 아니라, 무엇이 '달라졌는지'만 담는 것이죠. 제목 그대로 한 프레임을 Delta Token 하나로 표현하겠다는 발상입니다. 비유하자면, 매 순간 그림을 처음부터 다시 그리는 대신 '바뀐 부분에만 덧칠'하는 방식에 가깝습니다.
여기서 중요한 점은, 이 변화량을 픽셀이 아니라 비전 파운데이션 모델(DINOv3)의 특징 공간에서 계산한다는 것입니다. 픽셀 복원에 매달리지 않는다는 점에서, 앞서 본 '이해' 갈래의 철학과도 묘하게 맞닿아 있죠. 그 결과 512×512 영상 기준으로 토큰 수를 약 1,000분의 1로 줄였고, 기존 생성형 World Model 대비 파라미터는 35배 이상, 연산량(FLOPs)은 2,000배가량 적게 쓰면서도 더 그럴듯한 미래를 예측했다고 합니다.
이렇게 세계를 ‘이해’하는 측면에서의 World Model이 직접 세계를 ‘생성’하는 방향으로 발전해온 과정을 설명드렸습니다. 그렇다면 JEPA 계열의 논문은 사장되고 있을까요? 그렇지 않습니다. 2026년 5월, 얀 르쿤이 공동저자로 참여한 〈When Does LeJEPA Learn a World Model?〉가 공개됐는데요. JEPA 계열 모델이 '언제' 실제 세계의 구조를 제대로 복원하는지를 수학적으로 증명한 연구입니다. 핵심은, 일정한 조건 아래에서 이런 모델이 관측 너머에 숨은 세계의 잠재 변수(latent variable)를 선형적으로 복원할 수 있다는 것 — 이른바 선형 식별 가능성(linear identifiability)입니다. 쉽게 말하면, '세계를 그리지 않고도 세계의 진짜 구조를 붙잡을 수 있다'는 주장을 경험적 직관이 아니라 증명으로 뒷받침한 셈이죠. 화려한 데모는 없지만, 이해 갈래가 어디를 향하는지 분명히 보여주는 신호입니다.
흥미로운 점은, 두 갈래가 조금씩 서로를 닮아 간다는 것입니다. Cosmos 3는 '생성 전에 먼저 이해한다'며 이해 쪽으로 한 걸음 다가갔고, Delta Token 연구는 픽셀이 아니라 특징 공간에서 변화를 다루며 예측 쪽 철학을 빌려왔습니다. 과연 World Model의 표준은 세계를 그리는 쪽이 될까요, 가늠하는 쪽이 될까요? 아니면 그 사이 어딘가에서 만나게 될까요?