
1. Background
Audio-Visual Classification
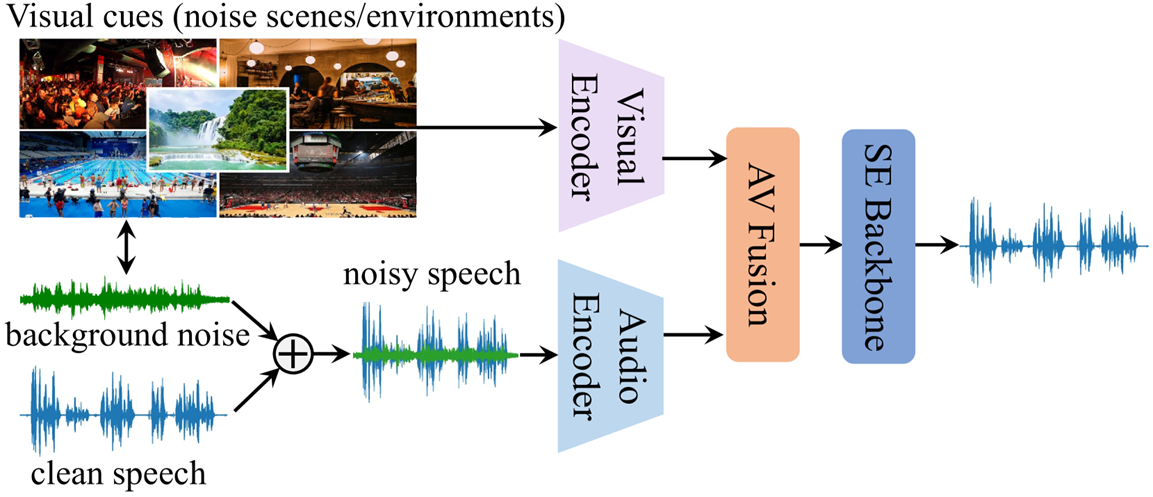
Audio-Visual Classification은 음성과 비쥬얼 데이터를 동시에 활용하여 다양한 분류 작업을 수행하는 멀티모달 학습 분야의 대표적인 사례입니다. 해당 테스크는 단일 모달리티에 의존하는 모델보다 풍부한 정보를 처리할 수 있어, 감정 인식, 객체 탐지와 같은 실제 응용에서 뛰어난 성능을 제공합니다.
한계점
그러나 실제 환경에서는 다음과 같은 문제로 인해 Audio-Visual Classification 모델의 성능이 저하될 수 있습니다:
- Missing Modality
센서 오류, 네트워크 문제 등으로 특정 모달리티 데이터가 누락될 가능성이 존재합니다. 예를 들어, 소리가 누락된 상황에서 영상만으로 분류를 수행해야 하는 경우 모델 성능이 저하될 수 있습니다.
- Noise
수집된 오디오나 비쥬얼 데이터에 불필요한 잡음이 포함될 수 있습니다. 예를 들어, 영상 데이터의 품질 저하나 오디오에 배경 소음이 포함되는 상황은 모델이 올바르게 분류하지 못하도록 방해할 수 있습니다.
이러한 상황은 모델이 특정 모달리티에 과도하게 의존하거나, 결손된 정보를 적절히 보완하지 못할 경우 큰 성능 저하를 초래합니다. 특히, 실제 응용에서는 예측 불가능한 데이터 결손이나 잡음이 빈번히 발생하며, 이를 해결하기 위한 강건한 학습 방법이 요구됩니다.
(Uncertain) Missing Modality
기존 연구들은 일반적으로 특정 모달리티가 결손되는 상황을 사전에 가정하여 모델을 설계합니다. 예를 들어, 비디오 모달리티만 결손되거나, 오디오 모달리티만 결손되는 상황에 대해 독립적으로 학습을 진행합니다. 그러나 이러한 접근은 실제 환경에서 발생할 수 있는 Uncertain Missing Modality을 고려하지 못하는 한계를 지닙니다.
Uncertain Missing Modality이란 ?
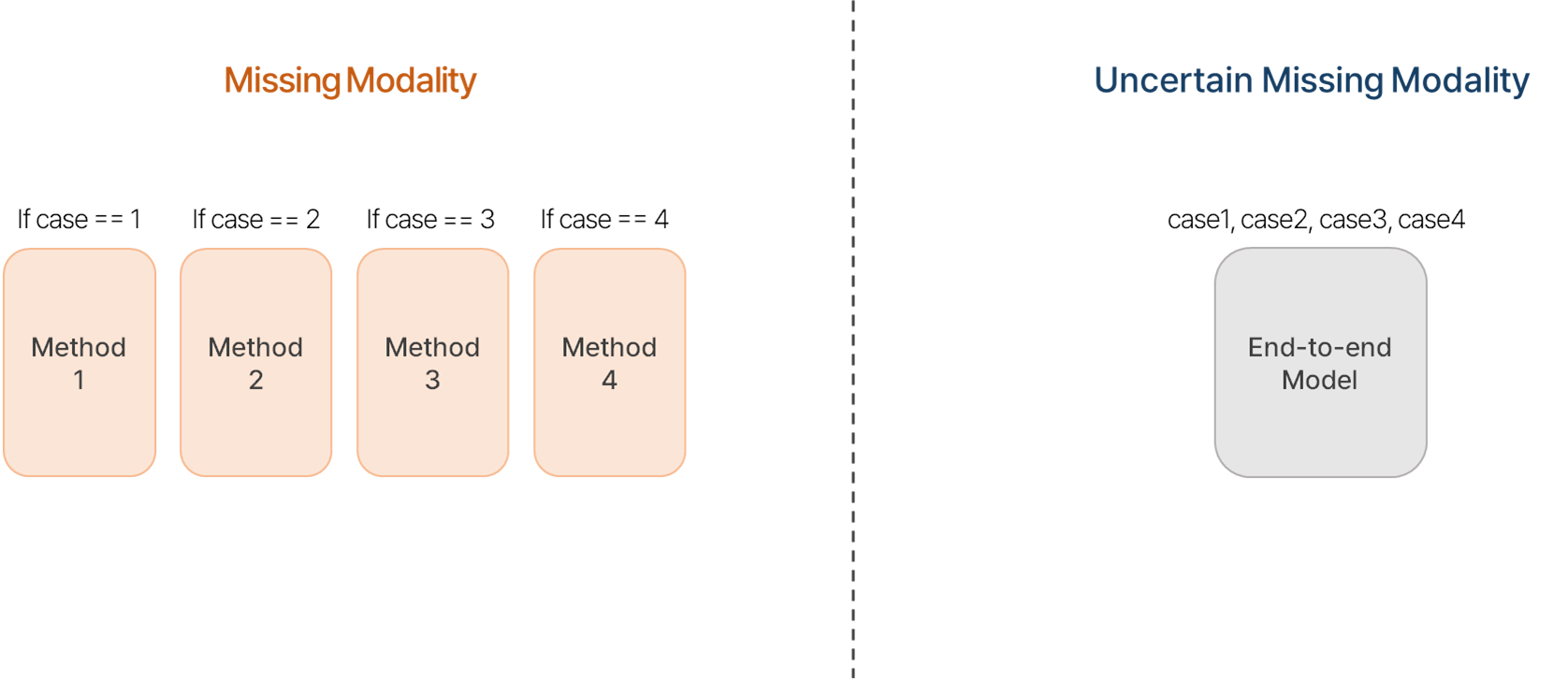
Uncertain Missing Modality는 실제 환경에서 발생하는 데이터 결손 문제를 다루는 개념으로, 다음과 같은 특징을 가집니다: 1. 불확실성 (Uncertainty)
- 테스트 시점에서 어떤 모달리티가 결손되었는지 사전에 알 수 없는 상황을 의미합니다.
- 예측 및 분류 과정에서 데이터 결손의 형태나 결손 여부가 명확하지 않아, 모델이 모든 가능한 Missing 조합에 대해 강건한 성능을 발휘해야 합니다.
2. Missing 조합의 다양성 Uncertain Missing Modality 상황에서는 다음과 같은 다양한 데이터 조합이 존재할 수 있습니다:
- 완전한 데이터 (Complete):
오디오와 비쥬얼 데이터가 모두 사용 가능한 정상적인 상황.
- 단일 결손 (Single Missing):
오디오 또는 비쥬얼 중 하나가 누락된 상황.
- 이중 결손 (Double Missing):
오디오와 비쥬얼 모두 누락된 극단적인 상황. 이처럼 Uncertain Missing Modality는 멀티모달 환경의 불확실성을 다루는 중요한 문제로, 이를 해결하기 위해 프롬프트 러닝과 같은 새로운 접근법이 주목받고 있습니다.
Prompt Learning
프롬프트 러닝이란?
프롬프트 러닝(Prompt Learning)은 기존 Fine-Tuning 방식을 대체할 수 있는 새로운 학습 패러다임으로, 모델의 입력 데이터에 추가적인 프롬프트(learnable tokens)를 삽입하여 모델 출력을 유도하는 방법입니다. 특히, NLP 분야에서 시작된 이 기법은 멀티모달 학습으로 확장되어 다음과 같은 장점을 제공합니다:
- 효율성:
- 전체 모델 파라미터를 업데이트하는 Fine-Tuning과 달리, 소수의 프롬프트 파라미터만 학습하여 메모리와 계산 자원을 절약할 수 있습니다.
- 대규모 모델에서도 학습 비용을 크게 줄이는 데 효과적입니다.
- 적응성:
- 프롬프트의 학습을 통해 다양한 작업에 적응 가능하며, 새로운 데이터셋이나 도메인에 대해 빠른 전이를 지원합니다.
- 모달리티 간 정보 강화:
- 프롬프트는 오디오와 비디오 간의 상호작용을 강화하며, 결손된 모달리티의 정보를 보완하는 역할을 수행합니다.
- 특히, 결손 모달리티가 예측 불가능한 Uncertain Missing Modality 상황에서 유용합니다.
Fine-Tuning vs Prompt Learning
Fine-Tuning과 Prompt Learning은 각각의 학습 방식에서 명확한 차이를 보입니다. 아래는 Fine-Tuning과 Prompt Learning의 차이를 비교한 표입니다:
구분 Fine-Tuning Prompt Learning
학습 대상 모델의 모든 파라미터를 업데이트 추가된 프롬프트 토큰만 학습
효율성
- 높은 메모리 및 계산 자원 소모
- 대규모 모델에서 학습 비용이 큼
- 적은 메모리와 계산 자원 사용
- 대규모 모델에서도 학습 비용 절감 가능
적응성
- 새로운 작업(task)마다 모델 전체를 재학습해야 함
- 작업 간 전환 속도가 느림
- 프롬프트만 조정하여 다양한 작업에 적응 가능
- 작업 간 전환이 빠르고 유연함
학습 자원 사용
- 높은 메모리 사용량
- 학습 시간이 오래 걸림
- 메모리 사용량 감소
- 학습 시간 단축
이 표를 통해 Prompt Learning이 Fine-Tuning의 한계를 극복하며, 효율성과 적응성을 향상시킬 수 있음을 명확히 보여줍니다. 결과적으로, Prompt Learning은 Fine-Tuning의 한계를 극복하고 효율성과 적응성을 모두 향상시킬 수 있는 효과적인 학습 방법으로 자리 잡았습니다.
본 연구의 방향
기존 Fine-Tuning 방식의 한계를 극복하기 위해, 본 연구는 Prompt Learning을 활용하여 다음과 같은 목표를 달성하고자 합니다:

- 효율적이고 강건한 학습 설계: 모든 모달리티 조합에 대해 안정적인 성능을 제공하며, 학습 자원(메모리 및 계산 시간)을 효율적으로 활용합니다.
- Uncertain Missing Modality 문제 해결: Missing된 모달리티를 보완하고, 멀티모달 간 상호작용을 강화하여 강건한 학습 구조를 제안합니다.
- 실제 응용 가능성 향상: 프롬프트 러닝 기반 접근은 기존 Fine-Tuning보다 학습 비용이 낮고 효율적이므로 실제 응용에서 보다 활용 가능성이 높습니다.
결론적으로, Prompt Learning은 Uncertain Missing Modality 문제를 해결하기 위한 효과적이고 실질적인 솔루션으로, 멀티모달 학습의 새로운 가능성을 열어줄 수 있습니다.
2. Framework
Input Level Prompt
Prompt 구조
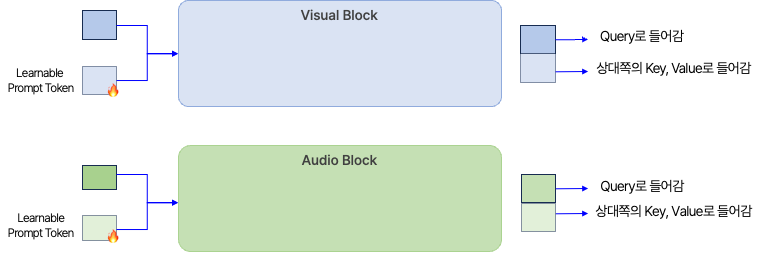
- 오디오 데이터셋의 차원은 (Batch_size, Seq_len, Hidden_dim) 이며, 비전 데이터셋의 차원은 (Batch_size, Seq_len, Hidden_dim) 입니다.
- 추가적으로 입력되는 토큰은 Audio와 Visual 각각에 대해 하나씩 존재하며, 각각의 차원은 (1, Prompt_length, Hidden_dim) 입니다. Prompt_length는 하이퍼파라미터로 설정하였습니다. 실험은 Prompt_length가 16인 상태로 진행되었습니다.
- torch에서 제공하는 Expand 메서드를 통해 토큰을 Batch_size만큼 복사해주었고, 따라서 토큰의 차원을 (Batch_size, Prompt_length, Hidden_dim)으로 만들어 주었습니다.
- 최종적으로, 입력 데이터에 추가적인 토큰을 병합하여 모델의 입력으로 사용하였습니다. 첫 번째 차원을 기준으로 병합하였기 때문에, 차원은 (Batch_size, Seq_len + Prompt_length, Hidden_dim)이 됩니다.
기대효과
Input Level Prompt는 각각 모달리티에 대한 트랜스포머에 입력되기 때문에, 각각 모달리티의 상태를 구분하는 데 도움이 되는 효과를 기대하였습니다. 예를 들어 이미지가 검정색 이미지로 아무런 의미가 없이 들어오거나, 오디오에 잡음이 심하게 끼어 있어 인식이 불가능한 경우, 임베딩에 이러한 상태를 더욱 더 잘 나타낼 수 있도록 하는 역할을 기대하였습니다.
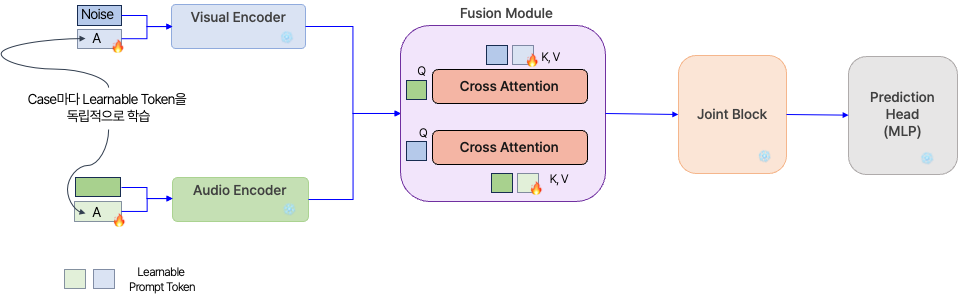
Fusion Module
Module 구조
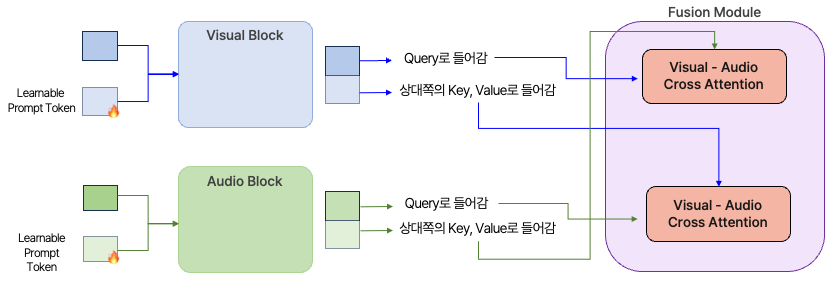
- Visual Transformer Block과 Audio Transformer Block을 거친 임베딩 값에 대해 Cross Attention을 수행하는 레이어를 추가해 주었습니다.
- 기존에는 단순히 임베딩을 병합하여 Joint Transformer Block에 들어가는 형태였기 때문에, 모달리티 간 Cross Attention이 수행되지 않았습니다.
- 그런데 오디오 데이터의 Seq_len은 512로 고정되어 있었고, 비주얼 데이터의 Seq_len은 196으로 고정되어 있었습니다. 이러한 Seq_len의 차이 때문에 애초에 오디오 데이터에 더 집중을 하고 있다는 점을 관찰하였습니다.
- 따라서 오디오 데이터와 비주얼 데이터 간의 정보를 혼합하는 레이어가 필요하다고 느끼게 되었고, 이를 Cross Attention으로 구현하였습니다.
- 어떤 모달리티의 데이터가 Query로 사용되는지에 따라, 두 가지 Cross Attention을 별도로 구성하였습니다.
기대효과
Fusion Module을 통해 일차적으로 모달리티 간의 정보를 혼합해줌으로써, 모달리티별로 임베딩의 길이가 다른 데에서 나타나는 일종의 편향을 최소화하고자 하였습니다.
Attention Level Prompt
Prompt 구조
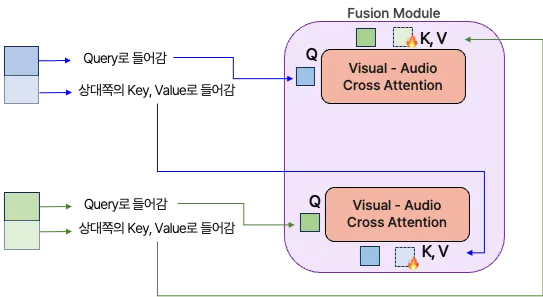
- Fusion Module에서 Cross Attention 수행 시, 어텐션의 Key와 Value에도 또한 추가적인 프롬프트를 병합하여 계산하였습니다.
- 이 때 들어오는 추가적인 프롬프트는 Input Level Prompt가 각각 모달리티의 Trasnformer를 거친 임베딩 값으로 설정하였습니다.
- Query의 차원은 (Batch, Seq_len, Hidden_dim) 이며, Key와 Value에는 프롬프트가 병합되어 (Batch, Seq_len + Prompt_length, Hidden_dim) 차원이 됩니다.
- Cross Attention을 거친 뒤에는 (Batch, Seq_len + Prompt_length, Hidden_dim) 차원이 됩니다.
기대효과
모달리티의 누락이 일어나는 상황에는, 나머지 온전한 모달리티를 보고 Classification을 잘 수행할 수 있어야 합니다. Attention의 Key와 Value에 토큰이 들어감으로써 어느 모달리티에 더 집중하게 될 지 직접적으로 영향을 줄 수 있게 되어 미싱 모달리티 문제를 해결하기를 기대하였습니다.
Workflow
Train
Complete, Audio-Only, Vision-Only, Noise-to-Both 네 가지 상황을 가정하여 각각 상황에 따라 서로 다른 프롬프트를 학습하였습니다. 멀티모달 데이터셋 그 자체로 Complete이므로, 나머지 세 가지 상황은 인위적으로 노이즈를 주입하여 상황을 세팅하였습니다.
Evaluation
Evaluation 시에는 상황을 직접적으로 구분할 수 없다는 것이 ‘Uncertain Missing Modality’ 세팅의 가정이기 때문에, 네 가지 상황 모두에 대해 하나의 방법론을 통합적으로 이용해야 합니다. 따라서 저희는 네 상황에서 학습된 토큰을 모두 병합한 뒤, 학습 시 입력되었던 위치에 동일하게 입력해 주었습니다. 모두 병합하여 입력하는 것이 아무런 의미가 없을 것이라고 생각이 될 수 있습니다. 하지만 저희는 네 가지 ‘상황에서 학습 된 토큰을 모두 병합하여 넣어준다면, 상황에 맞는 토큰에 더 큰 집중(Attention)을 줌으로써 모델이 모든 케이스를 자동적으로 처리할 수 있을 것이다’라는 가설을 설정하였습니다. 따라서 이 가설에 의거하여 실험을 진행하였습니다.
3. Results
Experiment Setting
Pre-Training Dataset
- AudioSet
AudioSet은 오디오와 비주얼 간 상호작용을 학습하기 위해 설계된 대규모 데이터셋입니다. 이 데이터셋은 1,789,621개의 비디오와 632개의 클래스로 구성되어 있으며, 특정 도메인에 제한되지 않고 광범위한 소리 이벤트를 포함합니다. 이러한 특성은 다양한 환경에서 멀티모달 데이터를 학습하고 테스트하는 데 적합하며, 모델이 오디오와 비주얼 간의 상관관계를 효과적으로 학습할 수 있도록 지원합니다.
- VGGSound
VGGSound는 200,000개 이상의 비디오와 300개의 클래스로 이루어진 유튜브 기반 데이터셋으로, 자연스러운 환경에서 멀티모달 학습에 적합한 특성을 보입니다. 특히, 라벨링 오류가 적어 데이터의 신뢰도를 높였으며, 현실 세계의 다양한 오디오-비주얼 이벤트를 학습하는 데 활용되었습니다.
Fine-Tuning Dataset
UrbanSound8K - AV UrbanSound8K - AV는 기존의 오디오 중심 데이터셋, UrbanSound8K을 멀티모달 학습이 가능하도록 확장한 데이터셋입니다. 이 데이터셋은 8,732개의 레이블과 10개의 클래스로 구성되어 있으며, 도심 환경에서 발생하는 다양한 소음과 이를 시각적으로 나타낸 이미지를 포함합니다. 특히, 오디오와 이미지를 결합함으로써, 멀티모달 학습을 통해 모달리티 간 상호작용을 학습하고 결손 모달리티에 대응할 수 있는 기반을 제공합니다.
Experiment Results
Fine-Tuning vs Prompt Learning 능 비교
Fine-Tuning(FT)과 Prompt Learning(PL)을 결합한 실험은 다양한 Noise 및 Missing Modality 상황에서 두 학습 방식의 성능 차이를 평가했습니다. 실험은 총 네 가지 환경(Complete, Vision Only, Audio Only, Noise to Both)에서 수행되었으며, 각각의 결과를 통해 Prompt Learning의 효과를 분석하였습니다.

- Complete Case (정상 데이터)
정상 데이터 환경에서는 FT와 FT+PL 모두 완벽에 가까운 0.99의 성능을 기록하였으며, 성능 차이가 없었습니다. 이는 Prompt Learning이 추가적인 학습 비용 없이 기존 Fine-Tuning의 성능을 유지함을 보여줍니다.
- Vision Only Case (오디오에 노이즈 추가)
오디오 데이터에 노이즈가 포함된 상황에서 FT+PL은 FT 대비 0.10만큼 성능이 향상되었습니다. 이는 프롬프트 러닝이 비주얼 모달리티를 통해 오디오의 결손을 보완하고, 안정적인 성능을 유지할 수 있도록 지원한 결과입니다. 특히, FT의 경우 노이즈 데이터에서 성능이 급격히 저하된 반면, PL은 학습된 프롬프트를 활용해 노이즈를 효과적으로 극복했습니다.
- Audio Only Case (이미지에 노이즈 추가)
이미지 데이터에 노이즈가 추가된 환경에서 FT+PL은 FT 대비 0.03의 성능 향상을 기록했습니다. 비록 향상 폭이 Vision Only 케이스보다 작았지만, 이는 오디오 모달리티가 노이즈에 더 강건한 특성을 가짐을 반영합니다. PL은 학습된 프롬프트를 통해 오디오와 비주얼 간의 상호작용을 증진시키며, 노이즈로 인한 성능 저하를 최소화했습니다.
- Noise to Both Case (오디오와 이미지 모두 노이즈 추가)
오디오와 이미지 모두에 노이즈가 포함된 환경에서는 FT+PL이 FT 대비 0.09만큼 성능이 향상되었습니다. 이는 프롬프트 러닝이 두 모달리티 간의 정보를 효과적으로 교환하며, 결손 및 왜곡된 데이터에서도 안정적인 성능을 유지할 수 있음을 보여줍니다.
자원 효율성 분석

- 메모리 사용량 분석
FT와 PL의 메모리 사용량을 비교한 결과, PL은 FT 대비 82.3%의 메모리 절감 효과를 보였습니다. FT는 모델의 모든 파라미터를 업데이트하는 데 반해, PL은 프롬프트 파라미터만 학습하기 때문에 메모리 요구량이 크게 감소했습니다.
- FT의 Total Memory: 95.12 GiB
- PL의 Total Memory: 17.85 GiB특히, Training Memory에서 PL은 FT 대비 약 80 GiB의 메모리를 절감하였으며, 이는 대규모 모델 및 데이터셋에서도 실질적인 학습 비용 절감을 가능하게 합니다.
- 학습 시간 분석
학습 시간 측면에서도 PL은 FT 대비 96% 이상의 시간 절감을 보였습니다.
- FT의 에폭당 학습 시간: 1분
- PL의 에폭당 학습 시간: 2.4초이는 프롬프트 러닝의 설계가 전체 모델 파라미터 업데이트를 생략하고, 효율적으로 학습을 수행하도록 최적화되었음을 보여줍니다.
Contribution
- Uncertain Missing Modality 문제 해결을 위한 End-to-End 모델 구현
- 본 연구는 Uncertain Missing Modality 문제를 처리할 수 있는 End-to-End Multimodal 모델을 설계하고 구현하였습니다.
- 기존의 멀티모달 모델들이 특정 모달리티의 결손을 명확히 정의하고 다루는 데 국한된 반면, 본 연구는 결손 모달리티의 불확실성(Uncertainty) 상황을 고려하여 설계된 점에서 차별성을 가집니다.
- Prompt Learning을 통한 네 가지 케이스에서의 성능 향상
- 오디오 및 비주얼 데이터 각각에 노이즈를 추가한 네 가지 실험 환경(Complete, Vision Only, Audio Only, Noise to Both)에서 Prompt Learning이 Fine-Tuning 방식 대비 안정적이고 우수한 성능 향상을 달성하였습니다.
- 특히, 노이즈 및 결손 모달리티 상황에서도 프롬프트 러닝이 Fine-Tuning 대비 약 10% 이상의 성능 향상을 보여, 불확실한 데이터 환경에서의 강건성을 증명하였습니다.
- 효율적 학습: 시간적 및 자원적 효율성 증대
- Prompt Learning을 통해 메모리 사용량을 82.3% 절감하였고, 학습 시간을 에폭당 약 96% 단축함으로써, 기존 Fine-Tuning 방식보다 효율적인 학습 방법임을 입증하였습니다.
- 이는 대규모 모델 및 데이터셋에서도 자원 제약 조건 하에서 실용적으로 적용 가능한 학습 방법임을 보여줍니다.
- 학술적 기여 및 확장 가능성
- 본 연구는 멀티모달 학습의 기존 연구 방향에 Prompt Learning 기법을 통합하여, Uncertain Missing Modality 문제를 다루는 새로운 프레임워크를 제안하였습니다.
- 이 접근법은 다양한 멀티모달 학습 및 Noise-Robust Classification 문제에도 확장 가능하며, 향후 멀티모달 시스템 설계의 기초 자료로 활용될 수 있습니다.