
Service Overview
서비스 개발 배경
📢 바쁘다 바빠 취준생을 위한 AI Agent
고학년이 되면서 주변에 취업 준비에 뛰어든 친구들이 많아졌는데요. 이런 취준생 친구들에게 필요한 서비스가 무엇일지 고민했습니다. 친구들에게 취업 준비를 하면서 언제 LLM의 도움을 받는지 물어봤을 때, 다음과 같은 답을 들을 수 있었습니다.

그렇다면 LLM을 활용해 취업 준비를 할 때 취준생들이 느끼는 불편함에는 무엇이 있을지, 페인 포인트를 알아보았습니다.
- 원하는 결과를 얻기 위해 직접 훈련시키는 과정이 귀찮고 번거로워요
- 프롬프트를 어떻게 작성해야 질 높은 답변을 얻을 수 있을지 모르겠어요
- 트렌드에 관한 면접 질문을 뽑아달라고 했을 때 정말 최신 트렌드를 반영하고 있을지 의문이 들어요
- 개인화된 답변을 생성하기보다는 일반적인 답변을 생성하는 것 같아요
이러한 페인 포인트를 통해 기존 LLM만 활용해서는 실질적으로 취업 준비에 도움이 되는 답변을 얻기까지 너무 많은 과정을 거쳐야 한다는 사실을 알게 되었습니다.
그래서 저희는 아래와 같은 기능을 가진 서비스를 기획하게 되었습니다.
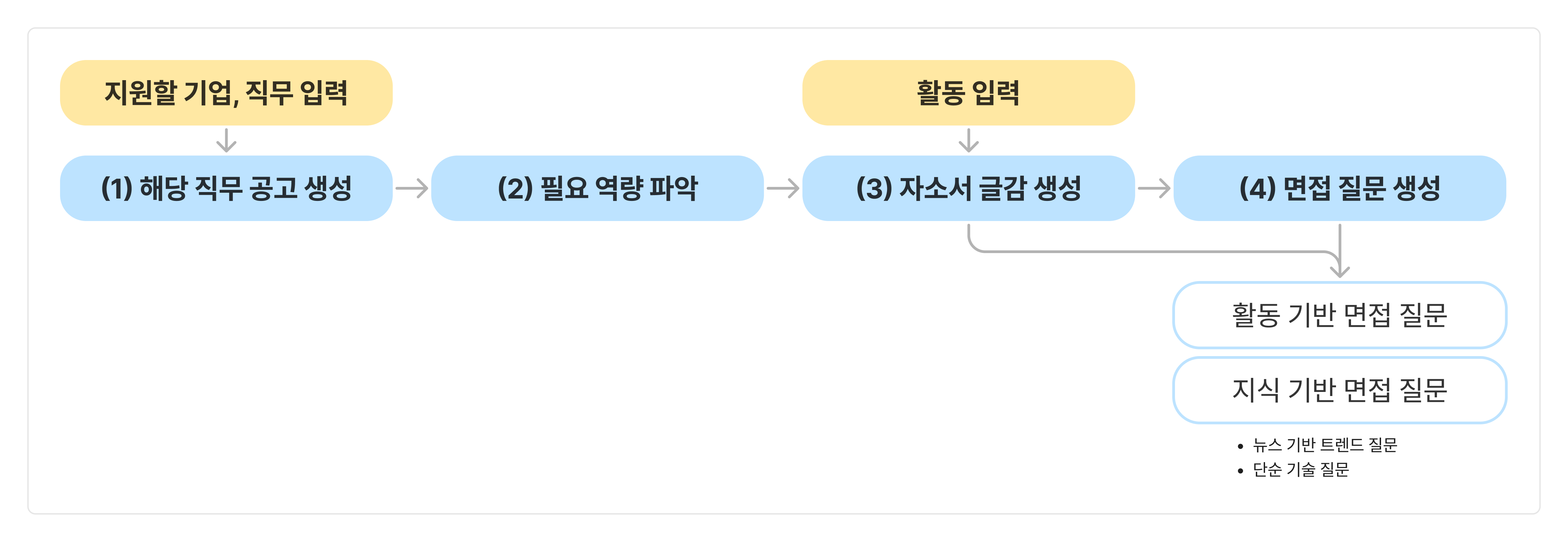
- 직무를 입력하면 해당 직무의 채용 공고 생성
- 채용 공고를 바탕으로 필요한 역량 추출
- 해당 역량을 어필할 수 있도록 자소서 글감 구성
- 활동 기반 면접과 지식 기반 면접을 모두 준비할 수 있도록 예상 질문 생성
위 세 단계의 프로세스를 통해 취업 준비 전반에서 사용자가 느꼈던 번거로움이나 막막함을 완화하고자 하는데요. 이러한 세 단계를 실제로 구현하기 위해서는, LLM에게 매번 적절한 질문, 즉 프롬프트를 입력하고 사용자의 활동 이력을 반영하며, 최신 트렌드까지 고려하는 과정이 필요합니다. 사용자가 직접 모든 프롬프트를 작성하고 수정하는 것은 번거로운 일이기 때문에, 이를 대신 해 주는 AI Agent로써의 역할을 수행할 수 있도록 서비스를 설계했습니다. 여기서 AI Agent가 무엇인지 간단하게 짚고 넘어가고자 합니다.
AI Agent
최근 AI Agent는 자율성과 학습 능력을 통해 다양한 분야에서 주목받으며 화제가 되고 있습니다. 특히, 연구 자동화를 다룬 《The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery》 논문이 2024년 8월에 발행되면서, 2025년은 AI Agent의 해라고 불릴 정도로 관심과 논의가 크게 증가하고 있습니다. 해당 논문은 연구 아이디어 생성, 실험 설계 및 반복, 논문 작성 과정을 자동화하여 과학적 연구의 효율성을 극대화한 사례로, AI Agent의 잠재력을 보여주는 중요한 자료로 평가받고 있습니다.
The AI Scientist : Towards Fully Automated Open-Ended Scientific Discovery
AI Scientist란?
대규모 언어 모델(LLM)을 활용하여 연구 Idea Generation, Experiment Iteration, Paper Write-up을 자동화하여 과학적 발견을 수행하는 EndToEnd 프레임워크입니다. 구성요소
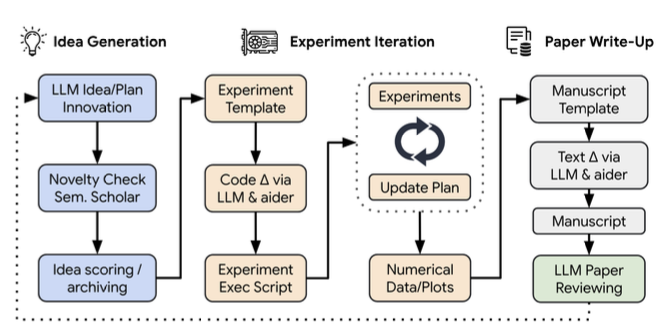
IDEA GENERATION 대규모 언어 모델(LLM)을 활용해 새로운 연구 아이디어와 계획을 생성합니다. 생성된 아이디어는 Semantic Scholar를 이용해 독창성을 평가하며, 흥미로움, 실현 가능성, 독창성을 기준으로 점수를 매기고 아카이브에 저장합니다.
EXPERIMENT ITERATION 미리 정의된 실험 템플릿과 실행 스크립트를 기반으로 LLM과 Aider를 활용해 실험을 설계하고 실행합니다. 실험 결과는 시각화된 데이터로 정리되며, 이를 바탕으로 연구 계획이 업데이트되고 실험을 반복적으로 수행합니다.
PAPER WRITE-UP LaTeX 템플릿을 사용해 LLM이 자동으로 논문의 각 섹션을 작성합니다. 작성된 논문은 LLM 기반 리뷰어를 통해 검토되어 품질이 평가되고, 피드백을 반영해 완성도를 높입니다.
주요 성과 1️⃣ 연구 효율성의 혁신적인 향상 AI Scientist는 아이디어 생성부터 실험 실행, 논문 작성까지 연구 과정을 자동화하여 기존의 연구 프로세스를 혁신적으로 간소화했습니다. 단일 논문당 약 \$15의 비용으로 학술적 수준의 결과를 도출하며, 시간과 비용 소모를 크게 줄였습니다.
2️⃣ 다양한 연구 분야에서의 성공적인 작용 Diffusion 모델링, 언어 모델링, Grokking 분석 등 다양한 머신러닝 분야에서 AI Scientist는 독창적인 아이디어와 성과를 보여주었습니다. 예를 들어, Diffusion 모델링에서는 Adaptive Dual-Scale Denoising 알고리즘을 제안해 데이터 구조를 더 효과적으로 학습했으며, Grokking 분석에서는 학습 속도를 향상 시키는 데이터 증강 기법을 탐구해 유의미한 결과를 도출했습니다.
3️⃣ 자동화된 리뷰 시스템의 성과 AI Scientist는 LLM 기반의 자동화된 리뷰 시스템을 통해 논문의 강점과 약점을 정확히 평가하며, 인간 수준의 리뷰 정확도 (66%)와 F1-Score(0..57)를 달성했습니다. 이러한 성과는 논문 품질 평가 과정에서 AI 활용 가능성을 입증하며, 학술적 평가의 공정성과 효율성을 높일 수 있음을 보여줍니다.
4️⃣ 반복적인 개선과 확장 가능성 이전 연구 결과를 아카이브에 저장한 후, 이를 기반으로 새로운 아이디어를 발전시키며 연구를 이어갑니다. 실험과 결과를 반복적으로 분석하는 과정을 통해 점진적으로 연구 품질을 향상시키고, 인간 연구자와 유사한 방식으로 지속적으로 확장 가능한 구조를 보여줍니다.
한계 및 결론


→ 위는 AI Scientist가 생성한 논문 “Adaptive Dual- Scale Denoising”입니다. 이 논문은 새로운 알고리즘을 제안하고 실험 결과와 시각화를 통해 학술 논문의 기본 요건을 충족했습니다. 그러나 실제 사용되지 않은 GPU 정보 기재, 과도한 긍정적 해석, 저차원 데이터셋에 국한된 실험 등에서 한계가 드러났습니다. 이와 같은 제한에도 불구하고, AI Scientist는 연구 과정의 자동화를 통해 효율성과 접근성을 크게 향상시켰습니다. 앞으로 더 복잡한 문제와 데이터에 적용 가능하도록 발전한다면, 과학적 발견의 패러다임을 변화시킬 중요한 도구가 될 것으로 보입니다.
그렇다면 저희의 서비스를 AI Agent라고 할 수 있을까요? 동적인 프롬프트 생성이나 복잡한 자동화 시스템은 아니기 때문에 앞서 말씀드린 AI Scientist처럼 완전한 형태의 AI Agent라고 보기는 어렵습니다. 하지만 핵심 원리인 자동화, 효율성, 사용자 편의성을 적용했습니다. 자소서 DB를 호출하고 각 단계에서 필요한 주요 프롬프트를 미리 정교하게 작성하여, 사용자의 간단한 입력(직무, 회사명, 활동 이력 등)만으로 원하는 결과물들을 얻을 수 있도록 설계했습니다. 매번 새로운 질의를 작성할 필요 없이 단계별로 준비된 프로세스를 통해 일관되고 높은 품질의 답변을 생성하는 거죠. 이처럼 [직무/회사 입력 → 역량 추출 → 자소서 글감 구성 → 면접 질문 생성]으로 자동화된 프로세스가 통합된 사용자 경험을 제공합니다.
Methodology
01 Prompt Engineering
LLM에게 특정 작업을 지시하고 원하는 결과를 얻기 위해서는, 먼저 ‘프롬프트(prompt)’라는 입력이 필요합니다. 프롬프트는 모델에게 수행해야 할 역할이나 작업을 설명해 주는 일종의 가이드라인인데, 모델은 이 지침을 해석한 뒤 결과를 생성하게 됩니다. 유저가 원하는 결과가 무엇인지 구체적으로 표현해서 작성해야, LLM이 그 의도에 맞는 출력을 해줄 수 있는 거죠. ‘프롬프트 엔지니어링(Prompt Engineering)’은 프롬프트를 효과적으로 만들고 최적화하는 과정을 뜻합니다. LLM이 다양한 분야에서 이전보다 더욱 중요한 역할을 차지하면서, 적절한 프롬프트 구성에 대한 관심이 크게 증가했습니다. 일반적으로 프롬프트를 작성할 때는, 맥락과 예시를 얼마나 제시하느냐에 따라 Zero-shot, One-shot, Few-shot 프롬프팅으로 구분됩니다. Zero-shot Prompting은 사전 예시 없이 오직 질문이나 지시사항만 주는 형태이고, One-shot과 Few-shot Prompting은 각각 하나의 예시와 여러 개(보통 2개 이상)의 예시를 제시한 뒤, 모델에게 비슷한 유형의 답을 요구하는 방식입니다. 이런 식으로 예시를 제공하면 맥락이 풍부해지고, 모델이 예시 패턴을 학습해 더 일관되고 정확한 답변을 낼 확률이 높아집니다. 프로젝트에서는 다양한 세팅으로 프롬프트 실험을 진행하고, 가장 적절한 프롬프트를 선택했습니다.
02 RAG
저희 프로젝트에서는 LLM이 실제 채용 공고 데이터를 활용해 더 정확한 응답을 생성하게하기 위해 RAG를 사용하는데요. 우선 RAG가 무엇인지 알아볼까요? RAG(Retrieval-Augmented Generation), 검색 증강 생성은 대규모 언어 모델(LLMs)과 정보 검색 시스템의 강점을 결합하여 고품질 응답을 생성하는 프레임워크로 3가지 세부 단계로 나누어 설명할 수 있습니다.
- Retrieval 단계:
사용자의 쿼리에 따라 외부 데이터베이스나 문서 집합에서 관련 정보를 검색합니다. 이 단계는 검색 정확도가 전체 RAG 시스템의 성능을 좌우하는 매우 중요한 요소로, 효율적인 검색 모델(예: BM25, DPR(Dense Passage Retrieval))과 강력한 임베딩 모델이 활용됩니다. 이 과정에서 RAG는 Query Expansion 기법을 통해 검색 범위를 넓히거나 문맥적 적합성을 강화하여 높은 품질의 정보를 추출할 수 있습니다.
- Augmentation 단계:
검색된 문서나 데이터를 대규모 언어 모델의 입력으로 제공하기 전에, 관련성과 품질을 보장하기 위해 선택 및 필터링 과정을 거칩니다. 이 단계에서는 중요도 기반 문서 선택, 중복 제거, 그리고 문서의 맥락 보강 작업이 수행됩니다. 이를 통해 생성 단계의 성능을 극대화합니다.
- Generation 단계:
최종적으로, 필터링된 검색 데이터를 언어 모델에 입력하여 사용자의 질문에 대한 자연스러운 응답을 생성합니다. 이 과정에서 언어 모델은 검색된 문서의 내용을 기반으로 응답을 생성하므로, 원본 데이터의 품질과 언어 모델의 생성 능력이 모두 중요합니다. RAG의 이러한 구조는 단순한 LLM의 한계(고정된 지식 및 최신 정보 부족)를 극복하고, 최신 정보 및 특정 도메인 지식을 반영한 답변을 제공할 수 있습니다. RAG는 기존 언어 모델 기반 접근법보다 정보 신뢰성(reliability), 도메인 적합성(domain relevance), 그리고 확장성(scalability) 측면에서 뛰어납니다. 특히, RAG는 검색된 정보와 언어 모델의 상호작용을 통해 사실에 기반한 답변을 생성하는 데 강점이 있으며, 추론적 질문이나 다중 문서 검색 문제에서도 유용하게 사용될 수 있습니다.
03 Query Expansion
Query Expansion는 정보 검색 및 자연어 처리 분야에서 사용되는 기술로, 사용자가 입력한 쿼리의 의미를 확장하거나 보강하여 검색 결과의 품질을 개선하는 방법입니다. 이는 사용자가 입력한 쿼리를 확장하여 검색 대상 문서의 범위를 넓히거나 문맥적 적합성을 보장하는 데 초점을 맞춥니다. 이 프로젝트에서는 기존 검색 방식의 한계를 극복하고자 Query Expansion을 사용했는데요. 기존에는 사용자가 입력한 직무와 회사명만을 활용하여 유사한 채용 공고를 검색해야 했습니다. 해당 정보만으로는 키워드 일치 기반 검색 정도만 가능하기 때문에 유연성이 부족해 유사한 공고를 찾기 어렵다는 한계가 있었습니다. 따라서 직무와 회사명을 입력하면 가상의 채용 공고 텍스트를 생성해 Query 자체를 확장시켜준 것이죠. Query Expansion 이후에는 이전 단계에서 생성한 가상의 채용 공고 텍스트를 활용하여 검색을 진행합니다. 단순 키워드 검색이 아니라 채용 공고 텍스트를 임베딩 한 뒤 DB와의 유사도를 계산하기 때문에, 더 높은 연관성을 가진 유사 공고를 추출할 수 있습니다. 《A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models》 에서는 Retrieval 단계에서 Query Expansion과 유사한 개념이 암묵적으로 다양한 방식으로 활용될 가능성을 논의합니다. 첫 번째 접근법으로, 사용자의 쿼리와 관련된 문맥적 정보를 보강하거나, 코퍼스 내에서 자주 함께 등장하는 단어를 기반으로 검색 범위를 확장할 수 있습니다(통계적 접근, statistical methods). 두 번째는 단어의 의미적 유사성을 고려하여 관련 개념을 확장하는 의미론적 접근(semantic methods)으로, Word2Vec, BERT, GPT와 같은 임베딩 모델을 통해 구현됩니다. 이러한 접근법은 Retrieval 단계에서 더 많은 관련 데이터를 검색하도록 돕고, 쿼리의 언어적 한계를 극복하는 데 유용합니다. 특히, 사용자가 간결한 쿼리를 제공하거나 특정 도메인 지식이 부족할 때, Query Expansion과 유사한 기법은 사용자의 의도를 더 심층적으로 이해하고, 높은 품질의 검색 결과를 제공하는 데 기여합니다.
Implementation
01 API 및 데이터
OpenAI API OpenAI의 LLM을 활용하기 위해 OpenAI API를 사용했으며, gpt-4o-mini 모델을 주로 사용하여 텍스트 요약, 텍스트 생성 등 다양한 작업을 수행했습니다. 응답 속도가 빠르고 비용이 저렴한데 적정 수준의 성능과 효율성을 제공한다는 점에서 해당 모델을 선택했습니다.
딥서치 뉴스 API 지식 기반 면접 질문을 생성할 때 활용할 트렌드 관련 국내 뉴스 기사를 수집하기 위해 딥서치 API를 사용했습니다. 원하는 키워드나 날짜 범위, 기사 개수 등 다양한 파라미터를 지정하여 기사 목록을 가져올 수 있습니다. 출력 데이터는 다음과 같습니다.
- Title: 기사 제목
- Date: 기사 발행 날짜
- Section: 기사 카테고리
- Publisher: 기사 발행 매체
- Summary: 기사 요약
- Content URL: 기사 본문 URL
직무 별 키워드를 해당 API를 이용해 검색하고, 관련 기사를 최신순 30개씩 수집했습니다.
채용 공고 DB 채용 공고 텍스트를 보다 효율적으로 수집하기 위해, 독립적인 채용 페이지를 운영하는 세 기업(네이버, 토스, 카카오)을 대상으로 크롤링을 진행했습니다. 위 기업의 채용 페이지는 어느 정도 통일된 페이지 양식을 갖추고 있어, 데이터를 수집하고 정리하는 과정을 단순화할 수 있었습니다. 크롤링을 통해 확보한 421건의 채용 공고의 텍스트는 직무, 조직 설명, 업무 설명, 필요 역량 및 우대 역량, 이력서 · 포트폴리오 어필 포인트, 직군 등을 담고 있었는데요. 데이터 파싱을 통해 직무(job), 조직 설명(org), 업무 설명(work), 필요 역량(skills), 직군(category)으로 텍스트를 분류했고, 정규 표현식을 활용해 불필요한 기호나 문자를 제거한 뒤 .xlsx 파일로 저장했습니다. 위와 같이 데이터 파싱 및 전처리를 마친 뒤, 불필요한 장황한 설명을 줄이고 핵심 정보만 빠르게 파악할 수 있는 형태로 데이터를 재가공했습니다. gpt-4o-mini 모델을 이용하여 아래와 같은 지시 사항을 바탕으로 조직 설명, 업무 설명, 필요 역량 열을 각각 요약하도록 했습니다.
- 조직 설명: 해당 회사나 팀, 조직의 역할과 목표, 운영 방식
- 업무 설명: 직무 담당자가 주로 수행할 일과 책임, 기대되는 활동
- 필요 역량: 해당 직무를 성공적으로 수행하기 위해 요구되는 기술·비기술적 역량

자기소개서 DB 자기소개서 글감 구성을 위한 프롬프트를 작성할 때 참고하고자 자기소개서 예시를 수집하여 DB를 구축했습니다. 질문 유형에 따라 카테고리를 [동기/포부], [성장/가치관], [역량/경험], [협업/성과], [기업/아이디어] 총 5개로 분류했습니다.

02 공고 생성 및 유사도 계산
공고 생성 공고 생성하기에 앞서 기존 채용공고DB에 관련 직무 및 회사 데이터가 있는지 확인합니다. 데이터가 없는 경우 가상의 공고를 생성합니다. 공고 생성은 사용자가 입력한 user_job과 user_company를 바탕으로 채용 공고 초안을 작성하는 것을 목적으로 합니다. gpt-4o-mini 모델을 활용하여 이루어지며, 프롬프트에는 조직 설명, 직무 설명, 필요 역량과 같은 주요 요소에 어떤 걸 작성해야 하는지에 대한 설명이 포함됩니다. 조직 설명에는 직무와 관련된 팀의 역할 및 목표를, 직무 설명에는 주요 업무, 책임, 기대되는 활동을, 필요 역량에는 직무 수행에 필요한 기술적 및 비기술적 역량을 상세히 기술하라고 요청합니다. 이를 기반으로 gpt-4o-mini모델은 사용자의 요구에 맞는 채용 공고 초안을 생성하고 반환합니다. 저희는 검색 범위를 확장하고 관련성이 높은 결과를 도출하기 위해 공고 텍스트를 생성하는 방식으로 Query Expansion을 수행했습니다.
💡Query Expansion 기존 검색 방식의 한계를 극복하기 위한 방안으로, 직무와 회사명을 입력하면 가상의 채용 공고 텍스트를 생성하여 이를 검색에 활용합니다. 기존에는 사용자가 입력한 직무, 회사명만 활용하여 유사한 채용 공고를 검색해야 했는데, 이는 키워드 일치 기반 검색이기 때문에 유연성이 부족하다는 한계가 존재했습니다. Query Expansion 후에는단순 키워드 검색이 아니라 채용 공고 텍스트를 임베딩 한 뒤 DB와의 코사인 유사도를 계산하여더 높은 연관성 가진 유사 공고를 추출할 수 있습니다.
Query Expansion 전 Query Expansion 후
당근마켓 – 서비스 기획자
- 조직 설명: 당근마켓의 서비스 기획팀은 사용자 중심의 혁신적인 서비스 개발을 통해 지역 커뮤니티의 연결을 강화하고, 사용자에게 최적화된 거래 경험을 제공하는 것을 목표로 합니다. 이 팀은 사용자 피드백과 시장 트렌드를 분석하여 서비스 개선 및 신규 기능 개발에 주력하고 있습니다.
- 직무 설명: 서비스 기획자는 당근마켓의 서비스 전략을 수립하고, 사용자 요구를 반영한 기능 기획 및 개선 작업을 담당합니다. 주요 업무에는 시장 조사 및 사용자 분석, 서비스 기획 문서 작성, 프로토타입 개발 및 테스트, 그리고 다양한 이해관계자와의 협업을 통한 서비스 런칭 및 운영이 포함됩니다.
- 필요 역량: 직무를 성공적으로 수행하기 위해서는 서비스 기획 및 UX/UI 디자인 경험이 3년 이상 필요하며, 데이터 분석 및 사용자 조사 능력이 요구됩니다. 또한, Agile 방법론에 대한 이해와 프로젝트 관리 경험이 중요하며, 원활한 소통 능력과 문제 해결 능력이 필수적입니다. 서비스 기획 관련 도구(예: Figma, Jira 등) 사용 경험이 있으면 더욱 우대됩니다.
유사도 계산 이어지는유사도 계산 단계는 검색 증강 생성, RAG를 위한 것이라고 볼 수 있는데요. 생성된 공고와 기존 데이터베이스(DB)의 공고 간 유사도를 측정하여 가장 관련성이 높은 기존 공고를 선별, 즉 검색해내는 것을 목적으로 합니다.
💡Retrieval-Augmented Generation(RAG) gpt-4o-mini 모델을 사용하여 입력 데이터를 기반으로 채용 공고를 생성한 뒤, 기존 데이터베이스의 공고 임베딩과의 코사인 유사도를 계산하여 가장 유사한 공고 3건을 선택합니다.
본격적으로 유사도를 계산하기 앞서 텍스트 임베딩 모델을 선택해야 하는데요. 텍스트 임베딩 생성, 유사도 계산, MSE 기반 평가의 세 가지 프로세스로 구성됩니다. 먼저, 채용 공고 DB 내에서 조직 설명, 업무 설명, 필요 역량 열을 각각 요약한 결과인 org_sum, work_sum, skills_sum 열의 텍스트를 다양한 임베딩 모델을 사용해 벡터로 변환합니다. 이때 사용한 임베딩 모델은 다음과 같습니다.
BM25
- 전통적인 정보 검색 모델로, TF-IDF를 기반으로 가중치를 계산합니다.
- 정확한 키워드 매칭에 강점을 가지지만, 문맥을 고려하지 못하는 단점이 있습니다.
Word2Vec
- 단어 간 관계를 벡터화하는 모델로, 특정 단어가 주변 단어와 어떤 관계를 가지는지 학습합니다.
- 문맥을 부분적으로 반영할 수 있으나, 문장 단위의 의미 파악에는 한계가 있습니다.
Upstage Solar LLM 기반의 임베딩 모델로, 문맥을 보다 정교하게 반영합니다.
CLIP 텍스트와 이미지를 함께 학습하는 멀티모달 모델로, 문맥과 의미를 동시에 반영합니다.
이후 각각 변환된 벡터를 활용해 직무 간 코사인 유사도를 측정해 유사도 매트릭스를 만들었습니다. 이때 실제 직군 분류와 얼마나 일치하는지 계산하여 모델 별 성능을 평가하고자 했는데요. 실제 같은 직군에 대해 유사도 1, 다른 직군에 대해 유사도 0으로 설정한 기준을 활용하여 평가가 이루어졌습니다. 예를 들어 ‘Engineering - Engineering’ 직군 간 유사도는 1로, ‘Engineering - Design’ 직군 간 유사도는 0으로 설정되는 거죠. 이를 토대로 MSE(Mean Squared Error)를 계산하여 실제 직군 분류와 가장 적은 오차를 보이는 모델을 최적의 임베딩 방식으로 선정하고자 했습니다.
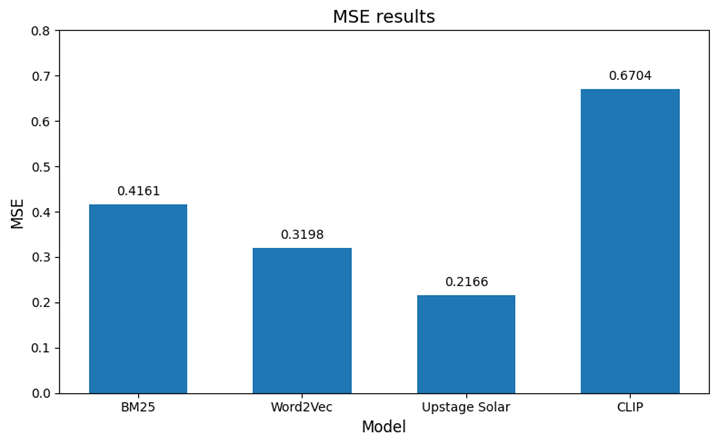
네 가지 임베딩 모델에 대해 MSE를 계산한 결과, 가장 낮은 값을 기록한 Upstage Solar 모델이 최적의 임베딩 방식으로 선정되었습니다. 가장 좋은 성능을 보인 이유는 Solar 모델이 LLM 기반의 텍스트 임베딩 모델이기 때문에 의미론적 유사도를 가장 잘 반영하여 생성된 공고와 기존 공고 간의 정확한 유사성을 측정할 수 있었습니다. 단순한 단어 기반 모델보다 문장 수준의 의미를 정교하게 포착하여 직무 간 관계를 보다 정확하게 모델링할 수 있었던 것이죠. 사용자의 입력에 의해 생성된 공고 텍스트와 유사한 공고 텍스트를 불러오기 위해 본격적인 유사도 계산을 수행했습니다. 새로 생성된 공고 텍스트를 Solar 모델로 임베딩하고, 기존 채용 공고 DB를 임베딩 해둔 결과와 코사인 유사도를 계산했는데요. 이때 가장 유사한 상위 3개의 공고를 선별하기 위해 주어진 기준(org_sum, work_sum, skills_sum) 각각에서 가장 유사도가 높은 상위 3개의 항목을 먼저 선정한 후, 이들 항목을 재정렬(Reranking)하여 최종 상위 3개의 항목을 선정했습니다. 이렇게 추출된 유사 공고는 이후 단계인 필요 역량 도출 과정에서 참고 데이터로 활용됩니다.
03 필요 역량 파악
필요 역량 파악 과정은 공고 생성 및 유사도 계산 과정의 결과물을 바탕으로 직무에 적합한 핵심 역량을 효과적으로 도출하는 것을 목적으로 합니다. 이를 통해 직무 수행에 필요한 구체적인 역량을 명확히 정의하고, 자소서 작성이나 면접 질문 생성 등에도 활용하고자 합니다. 이때 유사 공고를 활용하는 이유는 무엇일까요? 새롭게 생성된 공고는 AI가 자동 생성한 것이므로 일부 정보가 부족하거나 일반적일 수 있습니다. 따라서 기존 유사 공고를 프롬프트에 제공함으로써, 실제 채용 시장에서 요구하는 핵심 역량과 직무의 구체적 요구사항을 반영할 수 있는 것이죠.
필요 역량 파악 프롬프트
prompt = (
f"""
아래는 새로 생성된 ''에 관한 채용 공고와 기존 유사 공고입니다.
이 내용을 바탕으로 직무를 성공적으로 수행하기 위해 필요한 역량(기술적 3개, 비기술적 3개)을 구체적으로 도출하세요.
[새로 생성된 공고]
[기존 유사 공고]
1.
2.
3.
**출력 형식**
1. **기술적 역량**:
- [역량1: 설명]
- [역량2: 설명]
- [역량3: 설명]
2. **비기술적 역량**:
- [역량1: 설명]
- [역량2: 설명]
- [역량3: 설명]
"""
)이 프롬프트는 새로 생성된 공고와 기존 DB에서 추출된 유사 공고 내용을 gpt-4o-mini 모델에 전달하여, 기술적 역량과 비기술적 역량을 각각 3개씩 구체적으로 출력하도록 요청합니다.
프롬프트 중요 요소
- 새롭게 생성된 채용 공고
job_posting - 사용자가 입력한 직무와 회사를 바탕으로 생성된 새로운 채용 공고 포함
- 새롭게 생성된 채용 공고에서 직무의 조직 설명, 직무 설명, 필요 역량 등 직무 수행의 전반적인 사항 기술
- 기존 유사 공고
similar_sum - 유사도 계산 과정을 통해 선별된 기존 공고들, 해당 직무와 관련된 주요 트렌드 및 요구 사항 반영
- 상위 3개의 유사 공고를 선택하여 도출된 내용은 신규공고와 비교 및 참조
- 요청사항
- 기술적 역량과 비기술적 역량 각각 3개씩 출력
- 각 역량에는 설명을 추가하여 직무와의 연관성을 구체적으로 설명
[출력 예시]
직무: 서비스 기획자 회사: 당근마켓
===== 최종 필요 역량 =====
1. 기술적 역량:
- **데이터 분석 능력**: 서비스 기획자는 사용자 피드백과 시장 트렌드를 분석하여 서비스 개선 및 신규 기능 개발에 필요한 인사이트를 도출해야 합니다. 이를 위해 데이터 분석 도구와 기법에 대한 이해가 필수적입니다.
- **사용자 경험(UX) 설계 이해**: 사용자 중심의 서비스 기획을 위해서는 UX 설계 원칙과 방법론에 대한 깊은 이해가 필요합니다. 이는 사용자 요구를 반영한 서비스 개선 및 신규 기능 개발에 직접적으로 연결됩니다.
- **Agile 방법론 이해**: Agile 방법론을 활용하여 빠르게 변화하는 시장 환경에 적응하고, 효율적으로 프로젝트를 관리하며, 팀원들과의 협업을 원활하게 진행할 수 있는 능력이 요구됩니다.
2. 비기술적 역량:
- **문제 해결 능력**: 서비스 기획 과정에서 발생하는 다양한 문제를 효과적으로 분석하고 해결할 수 있는 능력이 필요합니다. 이는 서비스 개선 및 신규 기능 개발에 있어 중요한 요소입니다.
- **커뮤니케이션 능력**: 다양한 이해관계자와 협력하여 서비스의 방향성을 설정하고, 사용자 경험을 최적화하기 위한 전략을 수립하기 위해서는 원활한 커뮤니케이션 능력이 필수적입니다.
- **협업 능력**: 여러 부서와의 협업을 통해 서비스 기획 및 개선을 진행해야 하므로, 팀워크와 협업 능력이 중요합니다. 이는 다양한 직군과의 원활한 소통과 조율을 통해 이루어집니다.04 자기소개서 글감 구성
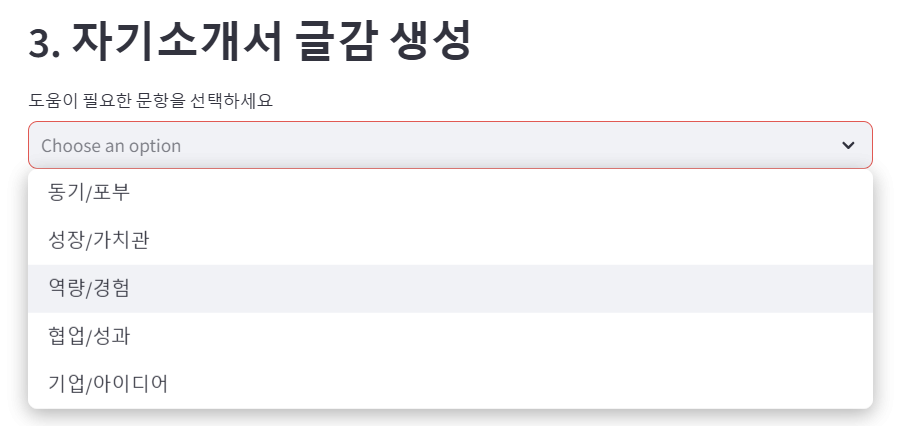
자기소개서 글감 구성 단계는 사용자가 입력한 활동과 RAG(검색 기반 생성)를 통해 추출된 직무 필요 역량을 바탕으로 개인화 된 자기소개서의 주요 주제를 도출하고 이를 구체적으로 확장하는 것을 목적으로 합니다. 사용자로부터 user_job를 입력 받은 뒤, 사전에 다수의 자기소개서 데이터들을 바탕으로 나누어 놓은 다섯 가지 항목을 제시해줍니다. 그 다음, 5가지 항목들 중 사용자 본인의 자기소개서 글감 추출을 바라는 항목의 번호 selected_indexes 를 복수 선택이 가능하도록 최소 1개~ 최대 5개 입력 받습니다. 다수의 자기소개서들을 모은 DB를 분석하여 정한 5가지 항목들은 다음과 같습니다.
- 동기/포부
- 성장/가치관
- 역량/경험
- 협업/성과
- 기업/아이디어
선택한 항목에 따라서 해당 항목과 관련된 구체적인 활동 데이터를 입력받습니다. 이후 gpt-4o-mini 모델을 활용하여 직무 필요 역량과 사용자의 활동 데이터를 바탕으로 프롬프트를 설계하고 글감을 생성합니다. 프롬프트에는 직무 정보, 사용자가 입력한 활동 내용, 글감과 개요 생성을 위한 세부 지침이 포함되며, 이를 통해 사용자 활동에서 도출된 주요 주제를 기반으로 글감과 개요가 출력됩니다. 생성된 글감은 활동의 배경 설명, 성과 및 결과, 직무나 기업과의 연결을 포함하며, 이를 통해 사용자의 경험이 직무나 기업에 기여할 수 있는 방식을 서술합니다. 또한, 활동에서 도출할 수 있는 주요 역량을 개인이 입력한 활동에 맞춤화하여 창의성, 리더십, 데이터 분석 능력과 같이 적절한 강조 역량을 도출합니다. RAG를 통해 도출된 필요 역량과 사용자가 입력한 활동 데이터를 매칭하여 주요 과제, 문제 해결 방식, 성과를 기반으로 강조 역량을 생성합니다. 코드 흐름은 사용자 입력 항목과 활동 데이터를 기반으로 GPT 모델에 프롬프트를 구성하여 호출하고, 항목별로 맞춤화된 글감과 개요를 생성하는 방식으로 진행됩니다. 이를 통해 사용자는 직무와 관련된 구체적이고 효과적인 자기소개서를 작성할 수 있습니다.
[입/출력 예시]
문항 활동 글감, 개요
역량/경험 ’소확행 기록 서비스, MADII(마디)’ iOS 앱 개발 프로젝트에 기획 파트로 참여하여 유저 리서치를 전담함. 워커홀릭 및 자기 돌봄에 대한 유저 리서치를 설계, 수행하고 Python을 활용해 다양한 그래프 시각화를 통해 인사이트를 도출함. ‘소확행’이라는 주제로 자신이 좋아하는 것을 찾고 실천할 수 있도록 앱을 기획했으며, 실제 작년 5월 출시하여 현재도 운영 중임. UX 라이팅과 QA를 담당하며 서비스의 완성도를 높였으며, 현재 GA 연동을 통해 유저 데이터를 분석함으로써 지속적인 개선을 추진하고 있음.
- 강조 역량: 데이터 분석 능력
글감: 사용자 피드백과 시장 트렌드를 기반으로 한 인사이트 도출
개요:
- 배경 설명: ‘소확행 기록 서비스, MADII’ iOS 앱 개발 프로젝트에서 기획 파트로 참여하며, 사용자 리서치를 전담했습니다. 특히, 워커홀릭 및 자기 돌봄에 대한 유저 리서치를 설계하고 수행하여, 사용자의 실제 요구와 시장의 흐름을 파악하는 데 집중했습니다.
- 성과/결과: 리서치 결과를 바탕으로 ‘소확행’이라는 주제로 사용자가 좋아하는 것을 찾고 실천할 수 있도록 앱을 기획하였고, 실제로 작년 5월에 출시하여 현재도 운영 중입니다. 이 과정에서 Python을 활용한 데이터 시각화를 통해 다양한 인사이트를 도출하였으며, UX 라이팅과 QA를 담당하여 서비스의 완성도를 높였습니다. 현재는 GA 연동을 통해 유저 데이터를 분석하며 지속적인 서비스 개선을 추진하고 있습니다.
- 직무/기업과의 연결: 서비스 기획자로서 데이터 분석 능력은 필수적입니다. 사용자 피드백과 시장 트렌드를 분석하여 인사이트를 도출하고, 이를 바탕으로 서비스 개선 및 신규 기능 개발을 추진할 수 있는 능력은 제가 가진 강점입니다. 이러한 경험은 귀사의 서비스 기획 및 개선에 기여할 수 있는 중요한 자산이 될 것입니다.
협업/성과 IT경영학회에서 교육기획팀원으로 일하면서 가장 큰 행사인 데모데이를 총괄함. 성공적인 행사 진행을 위해 업무 분담을 명확히 하고, 모든 일정을 노션을 활용해 체계적으로 관리함. 학회원 및 외부 심사위원, 협찬사를 위한 자료를 피그마로 제작하여 전달력을 높였으며, 내부 팀과 외부 관계자 간 협업을 조율하며 원활한 커뮤니케이션을 이끌어냄. 이를 통해 협업 능력과 일정 관리 역량을 강화하고, 행사 운영의 성과를 극대화함.
- 강조 역량: 원활한 소통 능력
글감: 효과적인 커뮤니케이션을 통한 성공적인 행사 운영 개요:
- 배경 설명: IT경영학회에서 교육기획팀원으로 활동하며, 가장 큰 행사인 데모데이를 총괄하게 되었습니다. 이 행사는 학회원과 외부 심사위원, 협찬사 등 다양한 이해관계자가 참여하는 중요한 행사로, 성공적인 진행을 위해서는 원활한 소통과 협업이 필수적이었습니다.
- 성과/결과: 행사 진행을 위해 업무 분담을 명확히 하고, 모든 일정을 노션을 활용해 체계적으로 관리했습니다. 또한, 피그마를 통해 자료를 제작하여 전달력을 높였고, 내부 팀과 외부 관계자 간의 협업을 조율하여 원활한 커뮤니케이션을 이끌어냈습니다. 이러한 노력 덕분에 행사 운영의 성과를 극대화할 수 있었고, 참석자들로부터 긍정적인 피드백을 받았습니다.
- 직무/기업과의 연결: 서비스 기획자로서 다양한 이해관계자와의 협업이 중요한 만큼, 이 경험은 제가 서비스 기획 과정에서 원활한 소통과 협업을 통해 프로젝트를 성공적으로 이끌 수 있는 역량을 갖추고 있음을 보여줍니다. 이는 서비스 개선 및 신규 기능 개발에 있어 필수적인 요소로, 기업의 목표 달성에 기여할 수 있는 기반이 될 것입니다.
05 예상 면접 질문 생성
1) 활동 기반 면접
이전 단계에서 생성된 자소서 글감을 바탕으로, gpt-4o-mini 모델을 이용해 활동 기반 면접 대비 예상 질문을 생성합니다. 사용자의 구체적인 활동이나 경험을 깊이 탐색할 수 있도록 면접 질문을 구성했습니다. 사용자가 처음 입력한 직무명 user_job 과 생성된 자소서 글감 user_personal_statement 를 입력으로 받아, 프롬프트를 생성하는데요. 면접 빈출 질문을 분석한 결과인 아래의 지침을 따르도록 작성했습니다.
- 경험 기반 질문: 활동의 주요 성과나 과정에 초점
- 문제 해결 질문: 직면한 과제와 해결 과정을 묻는 질문
- 역량 기반 질문: 직무와 관련된 기술적/분석적 능력을 평가하는 질문
이를 통해 모델이 보다 구조적이고 의도에 부합하는 질문을 생성할 수 있도록 유도했습니다.
[출력 예시]
- 사용자 리서치를 설계하고 수행한 경험에 대해 구체적으로 설명해 주실 수 있나요? 특히, 어떤 방법론을 사용하였고, 그 결과로 도출된 인사이트가 앱 기획에 어떻게 반영되었는지 궁금합니다.
- 데모데이 행사 운영을 총괄하면서 발생한 주요 문제나 도전 과제는 무엇이었으며, 이를 해결하기 위해 어떤 접근 방식을 취했는지 설명해 주실 수 있나요? 또한, 팀원들과의 협업 과정에서 어떤 역할을 하셨는지도 말씀해 주세요.
- 소확행 기록 서비스 개발 및 데모데이 운영 경험을 통해 얻은 교훈 중 하나를 말씀해 주시고, 이 교훈이 서비스 기획자로서의 역할에 어떻게 적용될 수 있을지 구체적으로 설명해 주실 수 있나요?
2-1) 지식 기반 면접 - 뉴스 트렌드 질문
뉴스 트렌드 관련 면접 질문을 생성하기 위해서는 사용자가 입력한 직무와 관련된 트렌드에는 무엇이 있는지 파악하고, 그 트렌드를 검색해 뉴스 기사를 수집하는 과정이 선행되어야 합니다.
1️⃣ 뉴스 키워드 추출 및 검색 gpt-4o-mini 모델을 호출하여 특정 회사의 특정 직무와 관련된 구체적이고 세부적인 최신 트렌드 키워드 3개를 생성하도록 했습니다. 이때 내용의 적절성과 검색의 용이성을 위해 키워드가 충족해야 하는 조건은 다음과 같습니다.
- 입력된 직무와 밀접하게 관련된 2025년 최신 트렌드, 기술, 사례를 반영해야 함
- 뉴스 사이트나 검색 엔진에서 검색했을 때, 구체적이고 신뢰할 수 있는 정보를 바로 찾을 수 있는 형태여야 함
- 키워드는 명확하고 세부적인 주제를 포함해야 함
- 키워드는 명사 + 명사 형식으로 작성해야 하며, "~의" 같은 조사나 불필요한 접속사를 포함하지 않아야 함
- 입력된 직무나 회사의 산업 도메인 특성을 반영하며, 일반적이지 않고 관련성이 높아야 함
사용자가 직무와 회사를 입력하면 그와 관련된 트렌드 키워드 3개를 리스트 형식으로 받아옵니다. 앞서 언급한 딥서치 API를 이용하여 해당 키워드 별 30건씩 뉴스 기사를 수집합니다. 키워드 별로 [Title / Date / Section / Publisher / Sumamry / Content URL] 로 구성된 DataFrame을 생성합니다.
2️⃣ 뉴스 클러스터링 및 선정 비슷한 소재를 다루고 있는 기사들을 하나의 주제로 묶어주기 위해 K-Means 클러스터링을 수행합니다. DataFrame에서 Summary 열, 즉 뉴스 요약 데이터를 리스트로 변환하고 전처리를 수행하여 명사만 추출합니다. TfidfVectorizer를 사용하여 각 단어가 해당 기사에서 얼마나 중요한지를 나타내는 TF-IDF 값을 계산하여 TF-IDF 벡터화합니다. 이후 PCA(Principal Component Analysis, 주성분 분석)로 차원을 축소하는데요. PCA는 고차원 데이터를 저차원 공간으로 투영하여, 데이터의 분산을 최대한 유지하면서 중요한 특징을 추출해 내는 차원 축소 방법입니다. PCA를 수행하지 않고 클러스터링을 진행해봤을 때, 클러스터 수가 너무 많아져서 의미 있는 그룹화를 놓치는 경향이 있었습니다. 반면 차원 축소를 통해 노이즈나 중복된 정보를 제거했을 때에는 유사 주제끼리 좀 더 잘 묶일 가능성이 있다는 장점이 있었습니다. 따라서 PCA를 수행하기로 결정했고, 다음과 같은 이유로 n_components=8 로 결정했습니다.
- PCA에서 적절한
n_components구하기 - PC1 ~ PC_N까지 분산 비율의 합을 누적했을 때 전체 대비 70% 이상이 되는 PC_N을 구하면 되는데, 전체 분산 대비 분산 비율이 70%는 되어야 원본 데이터가 충분히 설명된다고 보기 때문입니다. 해당 조건을 만족하는 N을 구하면 N≥10 으로 나타났으나, 이때 클러스터 개수가 너무 많아져 굳이 나누지 않아도 될 클러스터까지 나누는 문제가 발생했습니다.
- N이 작을 때에는 주제를 크게 묶다 보니 주제 다양성이 부족하거나 개별 클러스터에서 다루는 범위가 한정되었습니다. 따라서 trade-off를 고려하여 N=8로 결정했습니다.
K-Means 클러스터링은 비지도 학습(unsupervised learning) 알고리즘 중 하나로, 주어진 데이터셋을 K개의 그룹(클러스터)으로 분할하는 데 사용됩니다. 이때, 각 데이터 포인트를 가장 가까운 군집 중심(centroid)에 할당함으로써, 클러스터 내부의 응집도를 최대화하고 클러스터 간의 분리도를 높이려고 시도합니다. 이 과정을 통해, 알고리즘은 각 데이터 포인트, 즉 뉴스 기사들을 서로 유사성이 높은 그룹으로 묶고, 각 그룹의 중심점을 찾아갑니다. 이때 클러스터의 개수는 어떻게 정해야 할까요?
- K-Means 클러스터링에서 적절한
n_clusters구하기 - 단순히 임의의 클러스터 수를 지정해 진행하는 대신, 실루엣 스코어를 이용하여 가장 적합한 클러스터 수를 찾아냅니다.
- 가능한 클러스터 수에 대해 K-Means 클러스터링을 수행한 뒤 실루엣 스코어를 산출하고, 가장 높은 스코어를 기록한 n_clusters를 최적의 클러스터 수로 확정합니다.
최적의 클러스터 수가 결정되면, K-Means 클러스터링을 수행해 최종 클러스터를 얻고, 원본 데이터에 cluster_id 열을 추가해 어떤 문서가 어느 클러스터에 속했는지 알 수 있도록 표시합니다. 중요한 클러스터를 주요 토픽으로 선정하기 위해 gpt-4o-mini 모델을 호출해서 사용했는데요. 위의 결과와 직무, 회사, 검색 키워드를 입력으로 넣었을 때, 3개의 핵심 클러스터와 요약을 생성하도록 프롬프트를 작성했습니다. 클러스터가 얼마나 유용한지를 우선순위 기준에 따라 평가하도록 지시합니다. 우선순위 기준은 다음과 같습니다.
- 지원자의 직무 채용 준비 과정에서 직무 트렌드를 깊이 이해하는 데 실질적인 도움을 주는가
- 검색 키워드와의 연관성이 높으며, 직무 수행에 있어 필수적인 키워드를 포함하고 있는가
- 주제가 특정 기업의 홍보에 치우치지 않고, 업계 전반의 흐름을 포괄하며 다양한 시각을 제공하는가
아래와 같이 적절한 클러스터와 부적절한 클러스터에 대한 예시를 추가해 모델이 더욱 정확한 평가를 내릴 수 있도록 했습니다.
‘디지털 금융의 발전과 핀테크 산업 성장’ (적절한 클러스터)
: 핀테크 및 디지털 금융 트렌드, 기업들의 투자 및 혁신 사례가 포함되어 있어 금융 분야의 변화 흐름을 이해하는 데 적합함.
‘글로벌 경기 둔화와 국내 금융 정책 대응’ (적절한 클러스터)
: 경제 환경 변화에 따른 정책적 대응 전략을 포함하고 있어 지원자가 경제 전반의 맥락을 파악하는 데 도움을 줄 수 있음.
‘은행별 새로운 서비스 출시 소식’ (부적절한 클러스터)
: 특정 은행의 개별 서비스 홍보에 초점이 맞춰져 있으며, 산업 전체의 흐름을 이해하는 데는 한계가 있음.
이렇게 출력된 키워드 당 3개씩, 총 9개의 주요 토픽(핵심 클러스터)이 사용자에게 제공되고, 사용자는 주요 토픽 중 면접 질문을 제공받고 싶은 한 가지 토픽을 고릅니다.
[출력 예시]
키워드 토픽 - 설명 토픽 - 설명 토픽 - 설명
사용자 경험 디자인
- AI 통합 운영체제와 개인화된 사용자 경험
: 삼성전자의 갤럭시 S25 시리즈는 AI 기능을 고도화하여 개인 맞춤형 사용자 경험을 제공하며, AI 버튼과 통합형 AI 플랫폼을 통해 여러 앱을 동시에 활용할 수 있는 혁신적인 스마트폰으로 평가받고 있음. 이는 사용자 경험 디자인의 발전 방향을 제시하며, 서비스 기획자에게 중요한 인사이트를 제공함.
- AI 에이전트 도입에 따른 UX/UI 트렌드
: 기업들이 AI 에이전트를 구축하고 활용하는 과정에서 UX/UI 설계의 효율화가 이루어지고 있으며, 이는 서비스 기획자에게 AI 시대의 사용자 경험 디자인에 대한 새로운 접근 방식을 제시함. 전문가들이 AI 기반 UX/UI 트렌드에 대해 논의하고 있어, 직무 수행에 필수적인 키워드를 포함하고 있음.
- D2C 전략을 통한 유통 비용 절감
: 식음료 및 프랜차이즈 업계가 D2C(Direct to Consumer) 전략을 통해 이커머스 플랫폼 의존도를 낮추고 유통 비용을 절감하며 브랜드 충성도를 높이고 있음. 이는 사용자 경험 디자인과 밀접한 관련이 있으며, 소비자와의 직접적인 접점을 통해 서비스 기획의 방향성을 이해하는 데 도움을 줄 수 있음.
데이터 기반 의사결정
- 산업 AI 확산을 위한 정부의 정책 및 전략
: 정부는 산업 AI의 확산을 위해 AI 반도체 육성, 휴머노이드 로봇 개발 등 10대 과제를 추진하고 있으며, 민관 합동 프로젝트를 통해 성공 사례를 창출하고 법령 및 제도를 개선하여 AI 인프라를 강화할 계획임. 이는 서비스 기획자가 데이터 기반 의사결정을 내리는 데 필수적인 AI 기술의 발전과 관련이 깊음.
- AI 기반 금융 투자 플랫폼의 발전
: SK C&C는 SK텔레콤과 협력하여 AI 금융 투자 플랫폼 '마켓캐스터'를 개발하고 있으며, 이를 통해 고객 맞춤형 AI 인텔리전스 서비스를 제공하고 있음. 이러한 기술은 데이터 분석과 의사결정의 고도화를 통해 다양한 산업에서 필수적인 요소로 자리잡고 있음.
- 기업의 AI 도입 현황 및 향후 계획
: 많은 기업들이 생성형 AI를 도입하고 있으며, 내년 공급망 관리를 위한 AI 투자를 늘릴 계획임. AI는 직원 생산성을 향상시키고 업무 방식을 혁신하는 데 기여하고 있어, 서비스 기획자가 직무 수행에 있어 데이터 기반 의사결정의 중요성을 인식하는 데 도움이 됨.
커뮤니티 중심 플랫폼
- 1인 가구를 위한 배달 플랫폼의 성장
: 모바일 배달 애플리케이션 '두잇'이 1인 가구를 타겟으로 한 서비스로 시리즈A 투자를 유치하며, 이웃과의 커뮤니티 형성을 통해 배달 음식 외 다양한 소비 영역으로의 확장을 계획하고 있음.
- 중고거래 플랫폼의 진화와 커뮤니티 기능
: 당근마켓은 중고거래를 넘어 구인구직 서비스로 확장하며, 지역 사회와의 연결을 통해 지속 가능한 커뮤니티 중심 플랫폼으로 자리매김하고 있음.
- AI와 데이터 기반 혁신의 중요성
: 다양한 산업에서 AI와 머신러닝 기술을 활용한 서비스 개발이 활발히 이루어지고 있으며, 데이터 기반의 혁신이 기업의 경쟁력을 높이는 데 중요한 역할을 하고 있음.
3️⃣ 뉴스 트렌드 질문 생성 사용자는 제공된 뉴스 요약 중 원하는 내용을 선택하여 입력할 수 있으며, 이를 기반으로 뉴스 관련 면접 질문 4개를 생성합니다. 기존 DB에 제한되지 않고, IT 계열 직무 외의 다양한 직무와 회사에서도 적절한 질문이 생성되도록 하는 데 중점을 두었습니다. 이를 통해 사용자는 입력한 직무와 회사 정보만으로도 높은 품질의 질문을 얻을 수 있으며, 다양한 직무와 산업에 유연하게 적용 가능한 질문 생성 시스템을 구현했습니다.
뉴스 기반 질문 프롬프트 뉴스 기반 질문 프롬프트는 사용자가 입력한 직무 user_job와 회사user_company, 직무와 회사 입력에 따른 뉴스 키워드k_idx, 선택한 뉴스 토픽topic 그리고 해당 뉴스의 요약 내용full_text을 기반으로 작성됩니다. 면접관의 관점에서 어떤 질문을 해야 할지 고민한 결과, 지원자의 직무 관련 역량과 사고력을 평가하기 위해 도메인 관심도 평가, 상황 기반 질문, 토론 유도 질문, 창의적 사고 질문의 4가지 유형을 선정했습니다.
# 프롬프트 작성
prompt = (f"""
아래 text는 회사의 직무에 지원하는 지원자가 면접 준비 과정에서를 검색어로 뉴스 기사를 검색한 후,
자신이 원하는 주제의 기사만 골라서 요약한 결과입니다.
아래 뉴스 텍스트를 바탕으로 '' 직무를 준비하는 지원자에게 도움이 될 만한 질문 4개를 생성하고, 각 질문을 평가한 뒤, Top개의 질문만 출력하세요.
**입력 내용**:
뉴스 주제:
요약 내용:
**질문 생성 및 평가 지침**
1. 질문 생성:
- 도메인 관심도 평가: 기사 내용 및 관련 트렌드를 기반으로 지원자가 해당 도메인에 대한 관심과 이해도를 나타낼 수 있는 질문을 작성하세요.
- 상황 기반 질문: 기사에서 다루는 특정 상황을 바탕으로 지원자의 사고력과 문제 해결 능력을 평가할 수 있는 질문을 작성하세요.
- 토론 유도 질문: 기사에서 언급된 산업 동향, 경쟁 상황, 또는 소비자 행동 변화와 관련하여 지원자의 의견을 유도할 수 있는 질문을 작성하세요.
- 창의적 사고 질문: 기사에서 다룬 주제를 확장하거나 새로운 아이디어를 제시할 수 있도록 창의적인 사고를 유도하는 질문을 작성하세요.
2.질문 평가
- 도메인 관련 지식 평가 (최대 5점): '' 직무와 관련된 도메인의 지식을 평가할 수 있어야 함.
- 직무 수행에 필요한 이해도 평가 (최대 5점): 직무 수행에 필요한 도메인 이해도를 평가할 수 있어야 함.
- 질문의 적절성 및 범용성 (최대 3점): 특정 기업이나 기술에 치우치지 않으며 보편적으로 평가 가능해야 함. 지엽적일 경우 감점(-3점).
- 창의적 사고 유도 (최대 3점): 창의적 사고를 유도하는 질문일 경우 높은 점수.
- 지나치게 일반적인 질문 방지 (-2점): 지나치게 일반적인 질문은 감점 처리.
3. 점수를 기반으로 상위개의 질문만 출력하세요.
**출력 형식**
1. 생성된 질문 4개:
- 질문 1: [질문 내용]
유형: [도메인 관심도 평가 / 상황 기반 질문 / 토론 유도 질문 / 창의적 사고 질문]
- 질문 2: [질문 내용]
유형: [유형]
- 질문 3: [질문 내용]
유형: [유형]
- 질문 4: [질문 내용]
유형: [유형]
2. 각 질문에 대한 점수 및 평가:
- 질문 1: [총 점수] [평가 이유]
- 질문 2: [총 점수] [평가 이유]
- 질문 3: [총 점수] [평가 이유]
- 질문 4: [총 점수] [평가 이유]
3. Top개의 질문:
- 질문 1: [질문 내용]
- 질문 2: [질문 내용]
"""
)이 프롬프트는 기사의 내용에 따라 생성되는 질문이 달라질 수 있다는 점을 고려하여, 우선적으로 4개의 질문을 생성한 뒤 특정 기준에 따라 평가하고, 상위 n개의 질문만 출력하도록 구성되었습니다.
다음은 여러 프롬프트 실험을 통해 가장 적합한 질문이 선정된 기준입니다:
Top n개 선정 생성된 각 질문은 사전에 정의된 평가 기준에 따라 점수가 부여되며, 이와 함께 간단한 평가 이유가 제공됩니다. 평가 항목은 질문이 직무와 도메인에 얼마나 관련성이 있는지, 직무 수행 능력을 효과적으로 평가할 수 있는지, 그리고 질문의 범용성과 창의성을 얼마나 포함하고 있는지를 기준으로 합니다. 이 과정에서 출력된 평가 이유는 상위 n개의 질문이 선정된 이유를 사용자에게 명확히 전달하는 역할을 합니다. 이를 통해 사용자는 질문의 점수와 평가 과정을 이해하고, 왜 해당 질문들이 최종적으로 선택되었는지 납득할 수 있습니다. 이러한 접근은 결과의 신뢰성을 높이고, 사용자가 생성된 질문의 품질에 대해 긍정적인 인식을 가지도록 돕습니다.
예시 출력 직무 : 서비스 기획자 회사: 당근마켓
===== 생성된 뉴스 트렌드 질문 =====
[중고 거래 플랫폼의 진화와 글로벌 확장]
1. 중고 거래 플랫폼의 글로벌 확장에 있어, 샤오미와 같은 기업들이 한국 시장에 진입할 때 어떤 전략을 사용할 수 있을지에 대한 당신의 의견은 무엇인가요?
2. 최근 라이브 커머스 시장의 성장이 중고 거래 플랫폼에 미치는 영향은 무엇이라고 생각하며, 이를 어떻게 활용할 수 있을까요?
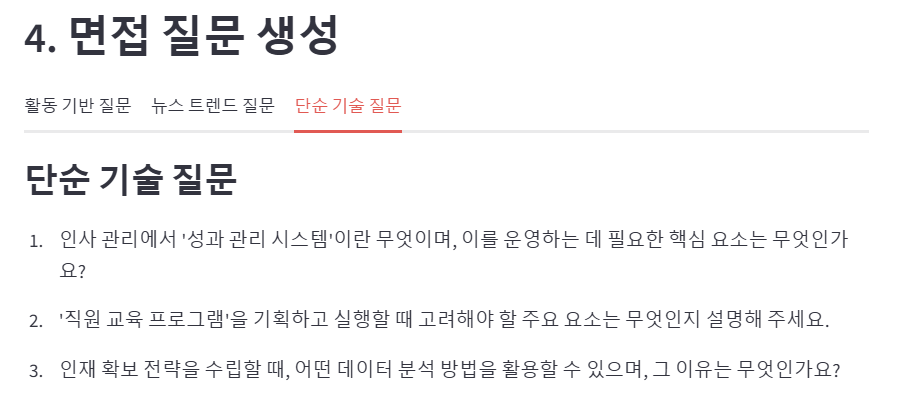
3. AI와 IoT 기술이 중고 거래 플랫폼의 사용자 경험을 어떻게 개선할 수 있을지에 대한 당신의 아이디어는 무엇인가요?2-2) 지식 기반 면접 - 단순 기술 질문
저희는 직무와 회사에 따라 면접 질문을 제공할 때 두 가지 유형으로 나누어 제공하려고 했습니다. 첫 번째는 앞서 작성한 뉴스 기반 질문이고, 두 번째는 직무명을 활용해 기본적인 기술 이해도를 평가할 수 있는 질문 3개를 출력하는 방식입니다. 이 두 번째 유형의 질문은 직무의 기초적인 기술적 지식과 배경을 평가하는 데 중점을 둡니다.
단순 기술 질문 프롬프트 단순 기술 질문 프롬프트는 한국어 전처리, TF-IDF 기반 키워드 추출, 그리고 LLM을 활용한 질문 생성이라는 세 가지 주요 단계를 통해 생성됩니다. 1️⃣ 한국어 전처리 먼저, 직무와 관련된 텍스트 데이터를 전처리하여 자연어 처리가 가능하도록 단순화합니다. Kiwi 형태소 분석기를 이용하여 채용 공고 텍스트에서 불필요한 기호와 불용어를 제거하고 명사를 추출했습니다. 이때 사용자 정의 불용어 사전에 ‘토스’, ‘서비스’ 등의 단어를 추가하여 이후 수행할 키워드 추출의 정확도를 높이고자 했습니다. 예를 들어, "데이터 분석가는 데이터를 처리하고 모델링하여 유용한 인사이트를 도출합니다"라는 텍스트가 주어을 때, 위와 같은 한국어 전처리를 거치면 "데이터, 분석, 모델링, 인사이트"와 같은 명사가 추출됩니다.
2️⃣ TF-IDF 기반 키워드 추출 전처리된 데이터를 바탕으로 TF-IDF(Term Frequency-Inverse Document Frequency) 알고리즘을 사용하여 가장 중요한 키워드를 추출합니다. TF-IDF는 단어의 빈도와 다른 문서에서의 희소성을 고려하여, 직무와 관련된 가장 중요한 상위 10개의 키워드를 도출합니다. 예를 들어, "데이터, 분석, 모델링, PCA, 결측값"과 같은 키워드가 추출될 수 있으며, 이는 면접 질문 생성을 위한 핵심 데이터로 사용됩니다.
3️⃣ 키워드와 직무명을 바탕으로 LLM을 이용한 면접 질문 생성 추출된 키워드와 직무명을 바탕으로 LLM을 활용해 직무와 관련된 기본적인 기술 이해도를 평가할 수 있는 질문 3개를 생성합니다. 프롬프트는 직무와 키워드를 포함하여 질문 생성을 위한 구체적인 지침을 제공합니다.
def generate_q3(job, keywords, job_posting):
"""
LLM을 이용하여 직무와 관련된 지식 중심의 질문을 생성합니다.
"""
prompt = f"""
당신은 직무 관련 면접 질문을 생성하는 전문가입니다.
주어진 직무와 키워드를 바탕으로, 면접 질문에서 사용자의 특정 지식이나 기술 이해도를 평가할 수 있는 질문 3개를 생성하세요.
질문은 다음 조건을 충족해야 합니다:
1. 질문은 "" 직무에서 필요한 구체적인 지식(예: 기술, 개념, 이론)에 대해 물어야 합니다.
2. 질문 형식은 간단하며, 예를 들어 ""와 관련된 특정 개념이나 기술에 대해 설명을 요청하는 형태여야 합니다.
3. 채용 공고인 ''을 1순위로 참고하고, ''는 2순위로 참고하세요.
예시:
직무: "데이터 분석가"
추출된 키워드: "데이터, 분석, 문제 해결"
출력 (면접 질문):
1. "데이터 분석에서 'hierarchical clustering'이란 무엇인가요?"
2. "'k-means clustering'의 작동 방식을 설명해주세요."
3. "데이터 분석 과정에서 'PCA(주성분 분석)'가 사용되는 이유는 무엇인가요?"
이제 아래 정보를 바탕으로 면접 질문 3개를 생성하세요.
직무: ""
채용 공고: ""
추출된 키워드:
출력 (면접 질문 3개):
"""
예시출력 직무: 서비스 기획자 회사: 당근마켓
===== 생성된 단순 기술 질문 =====
1. "사용자 요구 분석 과정에서 수집한 데이터를 어떻게 활용하여 서비스 기획에 반영하나요?"
2. "Agile 방법론을 적용한 서비스 기획 프로젝트의 경험에 대해 설명해주시고, 이 방법론이 어떤 장점을 제공했는지 말씀해 주세요."
3. "신규 기능 개발 시, 어떻게 사용자 피드백을 반영하여 서비스 개선 전략을 수립하나요?"Result
결과 예시
다음은 데모 웹 페이지 스크린샷입니다.





다양한 데이터셋을 입력했을 때의 결과입니다.
서비스 기획자 / 당근마켓
활동1 IT경영학회에서 교육기획팀원으로 일하면서 가장 큰 행사인 데모데이를 총괄함. 성공적인 행사 진행을 위해 업무 분담을 명확히 하고, 모든 일정을 노션을 활용해 체계적으로 관리함. 학회원 및 외부 심사위원, 협찬사를 위한 자료를 피그마로 제작하여 전달력을 높였으며, 내부 팀과 외부 관계자 간 협업을 조율하며 원활한 커뮤니케이션을 이끌어냄. 이를 통해 협업 능력과 일정 관리 역량을 강화하고, 행사 운영의 성과를 극대화함.
활동2 ’소확행 기록 서비스, MADII(마디)’ iOS 앱 개발 프로젝트에 기획 파트로 참여하여 유저 리서치를 전담함. 워커홀릭 및 자기 돌봄에 대한 유저 리서치를 설계, 수행하고 Python을 활용해 다양한 그래프 시각화를 통해 인사이트를 도출함. ‘소확행’이라는 주제로 자신이 좋아하는 것을 찾고 실천할 수 있도록 앱을 기획했으며, 실제 작년 5월 출시하여 현재도 운영 중임. UX 라이팅과 QA를 담당하며 서비스의 완성도를 높였으며, 현재 GA 연동을 통해 유저 데이터를 분석함으로써 지속적인 개선을 추진하고 있음.
===== 생성된 채용 공고 =====
1. 조직 설명: 당근마켓의 서비스 기획팀은 사용자 중심의 혁신적인 서비스 개발을 통해 지역 커뮤니티의 연결을 강화하고, 사용자에게 더 나은 거래 경험을 제공하는 것을 목표로 합니다. 이 팀은 시장 트렌드와 사용자 피드백을 분석하여 서비스 개선 및 신규 기능 개발에 주력하고 있습니다.
2. 직무 설명: 서비스 기획자는 당근마켓의 서비스 전략을 수립하고, 사용자 요구를 반영한 기능 기획 및 개선 작업을 담당합니다. 주요 업무에는 시장 조사 및 사용자 분석, 서비스 기획 문서 작성, 프로토타입 개발, 그리고 다양한 이해관계자와의 협업을 통한 서비스 런칭 및 운영 지원이 포함됩니다.
3. 필요 역량: 직무를 성공적으로 수행하기 위해서는 서비스 기획 및 UX/UI 디자인 경험이 3년 이상 필요하며, 데이터 분석 및 사용자 조사 능력이 요구됩니다. 또한, Agile 방법론에 대한 이해와 프로젝트 관리 경험이 중요하며, 원활한 소통 능력과 문제 해결 능력도 필수적입니다.
===== 최종 필요 역량 =====
1. 기술적 역량:
- **서비스 기획 및 UX/UI 디자인 경험**: 사용자 중심의 서비스 개발을 위해서는 서비스 기획 및 UX/UI 디자인에 대한 실무 경험이 필수적입니다. 이는 사용자 요구를 반영한 기능 기획 및 개선 작업을 효과적으로 수행하는 데 필요합니다.
- **데이터 분석 능력**: 시장 트렌드와 사용자 피드백을 분석하여 서비스 개선 및 신규 기능 개발에 기여하기 위해 데이터 분석 능력이 요구됩니다. 이를 통해 정량적 및 정성적 인사이트를 도출할 수 있습니다.
- **Agile 방법론 이해 및 프로젝트 관리 경험**: Agile 방법론에 대한 이해는 빠르게 변화하는 환경에서 효율적으로 프로젝트를 관리하고, 다양한 이해관계자와 협업하여 서비스 런칭 및 운영을 지원하는 데 중요합니다.
2. 비기술적 역량:
- **원활한 소통 능력**: 다양한 이해관계자와의 협업을 통해 서비스 기획 및 개선 작업을 진행하기 위해서는 원활한 소통 능력이 필수적입니다. 이는 팀 내외부의 의견을 조율하고, 효과적으로 정보를 전달하는 데 중요합니다.
- **문제 해결 능력**: 서비스 기획 과정에서 발생할 수 있는 다양한 문제를 신속하고 효과적으로 해결할 수 있는 능력이 필요합니다. 이는 서비스 개선 및 사용자 경험 향상에 기여합니다.
- **사용자 중심 사고**: 사용자 요구를 이해하고 이를 반영한 서비스 기획을 위해서는 사용자 중심의 사고가 중요합니다. 이는 고객의 목소리를 반영하여 최적의 거래 경험을 제공하는 데 기여합니다.
다음 문항 중 도움이 필요한 문항을 선택하세요 (최소 1개, 최대 5개 선택 가능)
1. 동기/포부
2. 성장/가치관
3. 역량/경험
4. 협업/성과
5. 기업/아이디어
===== 자기소개서 항목 글감 및 개요 =====
[ 역량/경험 ]
- **강조 역량**: 데이터 분석 능력
**글감**: 사용자 피드백을 기반으로 한 서비스 개선 및 신규 기능 개발
**개요**:
- **배경 설명**: 제가 참여한 ‘소확행 기록 서비스, MADII’ iOS 앱 개발 프로젝트에서 기획 파트로 활동하며, 사용자 리서치를 전담했습니다. 특히, 워커홀릭 및 자기 돌봄에 대한 유저 리서치를 설계하고 수행하여, 사용자들이 어떤 기능을 필요로 하는지 깊이 이해할 수 있었습니다.
- **성과/결과**: 리서치 결과를 바탕으로 ‘소확행’이라는 주제를 중심으로 앱을 기획하였고, 실제로 작년 5월에 출시하여 현재도 운영 중입니다. UX 라이팅과 QA를 담당하며 서비스의 완성도를 높였고, Google Analytics(GA) 연동을 통해 유저 데이터를 분석하여 지속적인 개선을 추진하고 있습니다. 이를 통해 사용자 만족도를 높이고, 앱의 사용성을 개선하는 데 기여하였습니다.
- **직무/기업과의 연결**: 서비스 기획자 직무는 사용자 요구를 반영한 서비스 개선과 신규 기능 개발이 핵심입니다. 제가 수행한 데이터 분석 경험은 시장 트렌드와 사용자 피드백을 효과적으로 분석하여 서비스 개선에 기여할 수 있는 강력한 기반이 됩니다. 이러한 경험은 귀사의 서비스 기획 및 UX/UI 디자인 과정에서 중요한 역할을 할 것으로 확신합니다.
[ 협업/성과 ]
- **강조 역량**: 원활한 소통 능력
**글감**: 다양한 이해관계자와의 협업을 통한 성공적인 행사 운영
**개요**:
- **배경 설명**: IT경영학회에서 교육기획팀원으로 활동하면서, 가장 큰 행사인 데모데이를 총괄하게 되었습니다. 이 행사는 학회원, 외부 심사위원, 협찬사 등 다양한 이해관계자가 참여하는 중요한 행사로, 원활한 소통과 협업이 필수적이었습니다.
- **성과/결과**: 행사 진행을 위해 업무 분담을 명확히 하고, 모든 일정을 노션을 활용해 체계적으로 관리했습니다. 피그마를 통해 학회원 및 외부 심사위원, 협찬사를 위한 자료를 제작하여 전달력을 높였고, 내부 팀과 외부 관계자 간의 협업을 조율하여 원활한 커뮤니케이션을 이끌어냈습니다. 이러한 노력 덕분에 행사 운영의 성과를 극대화할 수 있었습니다.
- **직무/기업과의 연결**: 서비스 기획자는 다양한 이해관계자와의 협업을 통해 서비스 기획 및 개선 작업을 진행해야 합니다. 제가 경험한 원활한 소통 능력은 서비스 기획 과정에서 팀 내외부의 의견을 조율하고, 효과적으로 정보를 전달하는 데 큰 도움이 될 것입니다. 이러한 경험은 서비스 기획자로서의 제 역량을 더욱 강화시켜 줄 것입니다.
===== 활동 기반 면접 질문 =====
1. **사용자 리서치를 설계하고 수행한 경험에 대해 구체적으로 설명해 주실 수 있나요? 특히, 어떤 방법론을 사용하였고, 그 결과로 어떤 기능 개선이나 신규 기능 개발이 이루어졌는지에 대해 말씀해 주세요.**
2. **IT경영학회에서 데모데이를 총괄하면서 발생한 주요 문제나 도전 과제는 무엇이었으며, 이를 해결하기 위해 어떤 접근 방식을 사용하셨는지 구체적으로 설명해 주실 수 있나요?**
3. **사용자 피드백을 기반으로 한 서비스 개선 과정에서 얻은 교훈이나 배운 점은 무엇이며, 이러한 경험이 서비스 기획자로서의 역할에 어떻게 기여할 수 있을 것이라고 생각하시나요?**
===== 트렌드 기반 뉴스 =====
키워드: 사용자 경험 최적화
1. LG전자의 로봇 사업 확장 및 AI 기술 통합
: LG전자가 AI 기반 상업용 자율주행로봇 기업 베어로보틱스의 경영권을 확보하여 로봇 사업을 통합하고, 가정용 및 산업용 로봇 시장을 강화할 계획임. 이를 통해 LG전자는 로봇 사업 전반에 시너지를 창출하고 미래 먹거리를 확보하는 데 집중하고 있음.
2. 삼성전자의 확장현실(XR) 시장 진출 및 안드로이드 XR 플랫폼
: 삼성전자가 구글과 협력하여 안드로이드 XR 플랫폼을 탑재한 '프로젝트 무한' 헤드셋을 연내 출시할 예정이며, 다양한 XR 기기에 적용 가능한 범용성과 확장성을 강조하고 있음. 이는 XR 생태계 구축에 기여할 것으로 기대됨.
3. 갤럭시 S25 시리즈의 AI 기능 및 사용자 경험 최적화
: 삼성전자의 갤럭시 S25 시리즈는 고도화된 AI 기능을 통해 사용자에게 직관적이고 편리한 경험을 제공하며, 멀티모달 AI를 통해 다양한 정보 유형을 동시에 처리할 수 있는 능력을 갖추고 있음. 이는 사용자 경험 최적화에 중요한 역할을 할 것으로 보임.
-----------------------------
키워드: 인공지능 추천 시스템
1. AI 중심의 새로운 산업 및 서비스 창출
: AI 기술을 중심으로 한 새로운 비즈니스 모델이 등장하고 있으며, CES 2025에서는 AI+X 비즈니스의 대전환이 예고되고 있음. 이는 기존 산업에 AI를 통합하여 혁신적인 가치를 창출하는 방향으로 나아가고 있음을 보여줌.
2. 인공지능 기술을 통한 사회적 문제 해결
: 네이버는 인명사고 탐지 AI 기술을 '클린봇 옵저버'에 적용하여 악플 감지 및 알림 기능을 강화하고, 사회적 문제에 대한 대응을 강화하고 있음. 이는 AI 기술이 사회적 책임을 다하는 데 기여할 수 있음을 시사함.
3. AI 기반 맞춤형 서비스 개발 및 혁신
: OCI를 도입한 다양한 산업 분야의 기업들이 AI와 머신러닝 기술을 활용하여 맞춤형 서비스 개발에 성공하고 있으며, 신세계백화점은 추천 시스템 'S-마인드 4.0'을 통해 고객의 생활 패턴을 분석하여 최적의 상품을 추천하는 시스템을 고도화하고 있음. 이는 AI가 개인화된 경험을 제공하는 데 중요한 역할을 하고 있음을 나타냄.
-----------------------------
키워드: 커뮤니티 기반 거래 플랫폼
1. 커뮤니티 기반 거래 플랫폼의 다각화 및 지역 확장
: '두잇'과 같은 모바일 배달 애플리케이션이 1인 가구를 위한 서비스로 투자 유치를 통해 커뮤니티 형성을 목표로 하며, 다양한 소비 영역으로의 확장을 계획하고 있음. 이는 커뮤니티 기반 거래 플랫폼의 서비스 다각화와 지역적 확장을 보여주는 사례로, 서비스 기획자에게 중요한 인사이트를 제공함.
2. 중고 거래 플랫폼의 진화와 커뮤니티 형성
: 당근마켓은 중고 거래를 넘어 구인구직과 지역 커뮤니티 형성으로 서비스 영역을 확장하고 있으며, 이는 플랫폼의 지속 가능한 성장과 사용자 참여를 증대시키는 전략으로 평가됨. 이러한 변화는 커뮤니티 기반 거래 플랫폼의 발전 방향을 이해하는 데 중요한 정보를 제공함.
3. AI 기반 맞춤형 서비스의 발전
: 풀무원이 운영하는 '엠버십' 플랫폼은 AI를 활용하여 개인화된 복지 서비스를 제공하며, 이는 직장인 커뮤니티 커머스 플랫폼으로 발전할 계획임. 이러한 AI 기반 서비스의 발전은 커뮤니티 중심의 거래 플랫폼에서 필수적인 요소로, 서비스 기획자에게 중요한 트렌드로 작용할 수 있음.
선택한 토픽 - 중고 거래 플랫폼의 진화와 커뮤니티 형성
관련 기사
https://www.chosun.com/economy/tech_it/2025/01/23/ZVAR4ZPMBNAAHFRBHEEUW6AMEA/?utm_medium=referral&utm_campaign=naver-news 무작정 캐나다로 간 CEO… “이젠 190만명이 ‘당근’ 해요”
https://www.dt.co.kr/contents.html?article_no=2025012302109931076001 [이미선의 디지털라이프] `감귤따기 알바`부터 `불꽃놀이 명당` 임대까지…중고거래앱에 "없는 게 없네"
===== 생성된 뉴스 트렌드 질문 =====
[중고 거래 플랫폼의 진화와 커뮤니티 형성]
1. 중고 거래 플랫폼의 글로벌 진출에 있어 가장 중요한 요소는 무엇이라고 생각하며, 당근마켓이 이를 어떻게 활용할 수 있을까요?
2. 커뮤니티 기반 거래 플랫폼에서 사용자 간의 신뢰를 구축하기 위한 효과적인 방법은 무엇이라고 생각하나요?
3. 당근마켓이 중고 거래 외에 구인구직 서비스로 확장한 것에 대해 어떻게 평가하며, 추가적으로 어떤 서비스가 필요할까요?
===== 생성된 단순 기술 질문 =====
1. 서비스 기획에서 사용자 요구를 수집하고 분석하는 방법에 대해 설명해 주세요.
2. Agile 방법론이 서비스 기획 과정에서 어떻게 활용되는지 구체적인 예를 들어 설명해 주시겠어요?
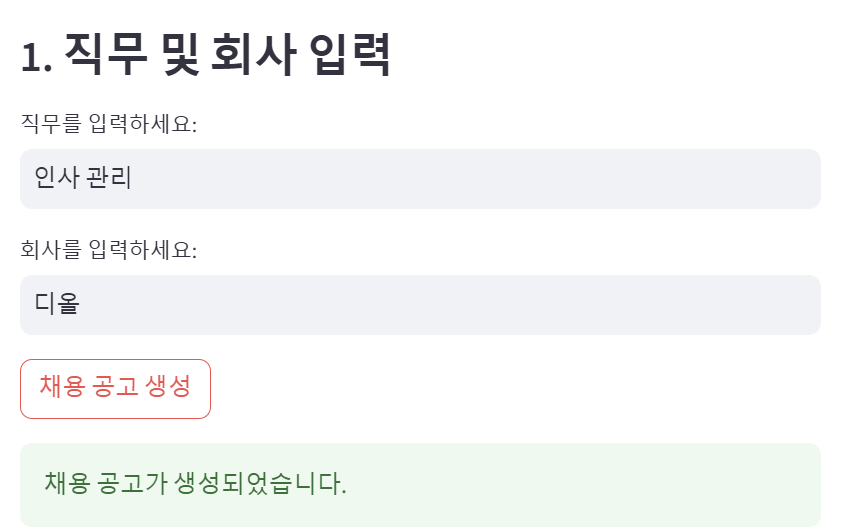
3. 시장 조사 과정에서 중요한 요소는 무엇이라고 생각하며, 이를 어떻게 분석할 것인지 설명해 주세요.인사관리 / 디올
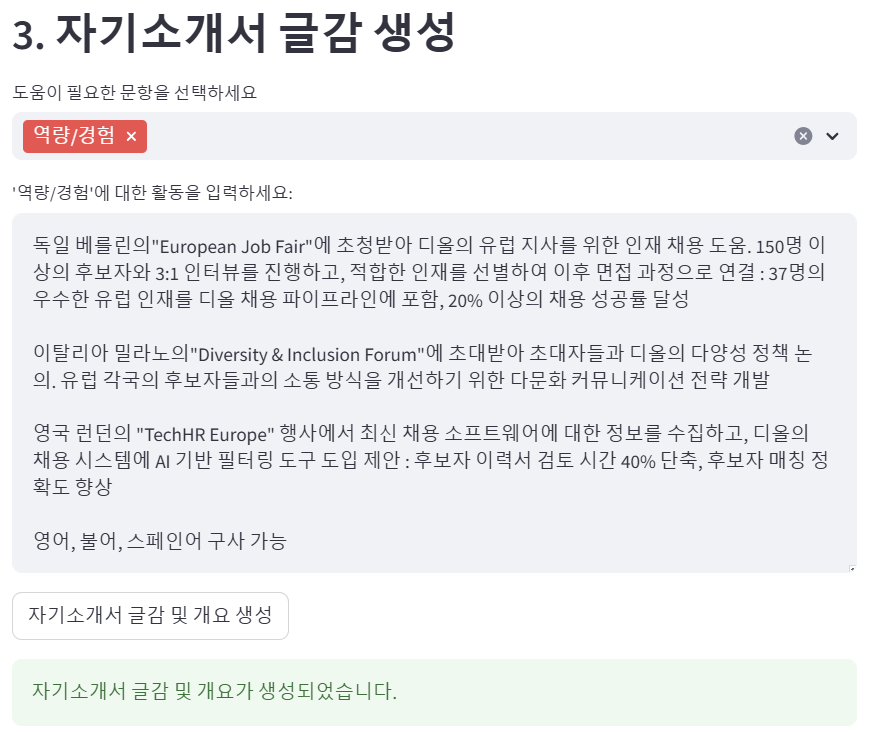
활동1 독일 베를린의"European Job Fair"에 초청받아 디올의 유럽 지사를 위한 인재 채용 도움. 150명 이상의 후보자와 3:1 인터뷰를 진행하고, 적합한 인재를 선별하여 이후 면접 과정으로 연결 : 37명의 우수한 유럽 인재를 디올 채용 파이프라인에 포함, 20% 이상의 채용 성공률 달성
활동2 이탈리아 밀라노의"Diversity & Inclusion Forum"에 초대받아 초대자들과 디올의 다양성 정책 논의. 유럽 각국의 후보자들과의 소통 방식을 개선하기 위한 다문화 커뮤니케이션 전략 개발
===== 생성된 채용 공고 =====
1. 조직 설명: 디올의 인사 관리 팀은 회사의 인재 확보 및 관리 전략을 수립하고 실행하여, 브랜드의 가치를 높이고 지속 가능한 성장을 지원하는 역할을 합니다. 이 팀은 직원의 역량 개발과 조직 문화 개선을 통해 디올의 글로벌 인재를 육성하고, 직원들이 최고의 성과를 낼 수 있는 환경을 조성하는 데 중점을 두고 있습니다.
2. 직무 설명: 인사 관리 직무는 인재 채용, 교육 및 개발, 성과 관리, 직원 관계 및 복리후생 프로그램 운영을 포함한 다양한 인사 관련 업무를 담당합니다. 주요 책임에는 인재 확보 전략 수립, 직원 교육 프로그램 기획 및 실행, 성과 평가 시스템 운영, 직원 만족도 조사 및 피드백 관리가 포함됩니다. 또한, 조직의 목표에 부합하는 인사 정책을 개발하고, 직원들의 경력 개발을 지원하는 역할도 수행합니다.
3. 필요 역량: 이 직무를 성공적으로 수행하기 위해서는 인사 관리 분야에서의 경험이 3년 이상 필요하며, 인재 채용 및 교육 프로그램 개발에 대한 깊은 이해가 요구됩니다. 또한, 효과적인 커뮤니케이션 능력과 문제 해결 능력이 필수적이며, 데이터 분석 및 HR 관련 소프트웨어 사용 능력이 우대됩니다. 글로벌 환경에서의 인사 관리 경험이나 다문화 팀과의 협업 경험이 있는 지원자를 선호합니다.
===== 최종 필요 역량 =====
1. 기술적 역량:
- **인재 채용 및 교육 프로그램 개발 능력**: 인사 관리 직무에서 인재 확보와 직원 교육 프로그램 기획 및 실행이 중요한 역할을 하므로, 이 분야에 대한 깊은 이해와 경험이 필요합니다.
- **데이터 분석 능력**: 직원 만족도 조사 및 피드백 관리, 성과 평가 시스템 운영 등에서 데이터를 분석하고 인사이트를 도출하는 능력이 필수적입니다. 이를 통해 인사 정책을 효과적으로 개발하고 개선할 수 있습니다.
- **HR 관련 소프트웨어 사용 능력**: HRIS(인사 정보 시스템) 및 다양한 채용 도구를 활용할 수 있는 능력이 요구됩니다. 이는 인사 관리의 효율성을 높이고, 데이터 기반의 의사 결정을 지원합니다.
2. 비기술적 역량:
- **효과적인 커뮤니케이션 능력**: 직원들과의 원활한 소통과 협업을 위해 유연한 커뮤니케이션 능력이 필요합니다. 이는 인재 채용, 교육 및 성과 관리 과정에서 중요한 역할을 합니다.
- **문제 해결 능력**: 인사 관리 과정에서 발생할 수 있는 다양한 문제를 정의하고 해결하는 능력이 중요합니다. 이는 조직의 목표에 부합하는 인사 정책을 개발하는 데 필수적입니다.
- **조직 문화 개선 및 직원 역량 개발에 대한 열정**: 직원들이 최고의 성과를 낼 수 있는 환경을 조성하기 위해 조직 문화 개선과 직원 역량 개발에 대한 강한 의지와 열정이 필요합니다. 이는 지속 가능한 성장을 지원하는 데 중요한 요소입니다.
다음 문항 중 도움이 필요한 문항을 선택하세요 (최소 1개, 최대 5개 선택 가능)
1. 동기/포부
2. 성장/가치관
3. 역량/경험
4. 협업/성과
5. 기업/아이디어
===== 자기소개서 항목 글감 및 개요 =====
[ 역량/경험 ]
- **강조 역량**: 인재 채용 및 교육 프로그램 개발 능력
**글감**: 디올 유럽 지사를 위한 인재 채용 경험을 통해 인재 확보의 중요성을 실감하다.
**개요**:
- **배경 설명**: 독일 베를린에서 열린 "European Job Fair"에 초청받아, 디올의 유럽 지사를 위한 인재 채용을 지원하는 기회를 가졌습니다. 이 행사에서는 다양한 배경을 가진 150명 이상의 후보자와 3:1 인터뷰를 진행하며, 적합한 인재를 선별하는 과정에서 인사 관리의 중요성을 깊이 이해하게 되었습니다.
- **성과/결과**: 이 과정에서 37명의 우수한 유럽 인재를 디올 채용 파이프라인에 포함시켰고, 20% 이상의 채용 성공률을 달성했습니다. 이는 저의 인재 채용 및 교육 프로그램 개발 능력이 실제로 효과를 발휘했음을 보여주는 결과입니다.
- **직무/기업과의 연결**: 인사 관리 직무에서는 인재 확보와 직원 교육 프로그램 기획이 핵심입니다. 제가 경험한 대규모 채용 프로젝트는 이러한 역량을 강화하는 데 큰 도움이 되었으며, 이를 통해 조직의 목표에 부합하는 인재를 확보하고, 지속 가능한 성장을 지원할 수 있는 기반을 마련했습니다. 따라서, 이 경험은 인사 관리 직무에서 요구되는 기술적 역량을 충족시키는 데 중요한 역할을 할 것입니다.
[ 협업/성과 ]
- **강조 역량**: 효과적인 커뮤니케이션 능력
**글감**: 다문화 커뮤니케이션 전략 개발을 통한 직원 소통 방식 개선
**개요**:
- **배경 설명**: 이탈리아 밀라노에서 열린 "Diversity & Inclusion Forum"에 초대받아, 다양한 문화적 배경을 가진 후보자들과의 소통 방식을 개선하기 위한 필요성을 느꼈습니다. 글로벌 기업 환경에서의 다양성과 포용성은 매우 중요하며, 이를 위해서는 효과적인 커뮤니케이션 전략이 필수적입니다.
- **성과/결과**: 포럼에서 다양한 의견을 수렴하고, 이를 바탕으로 다문화 커뮤니케이션 전략을 개발하였습니다. 이 전략은 직원들 간의 이해도를 높이고, 협업을 촉진하는 데 기여하였습니다. 또한, 이 전략을 통해 직원들의 만족도와 팀워크가 향상되었음을 확인할 수 있었습니다.
- **직무/기업과의 연결**: 인사 관리 직무에서는 직원들과의 원활한 소통이 매우 중요합니다. 효과적인 커뮤니케이션 능력은 인재 채용, 교육 및 성과 관리 과정에서 필수적이며, 조직 문화 개선과 직원 역량 개발에 기여할 수 있습니다. 이러한 경험은 제가 지원하는 기업의 인사 정책 개발 및 실행에 직접적으로 기여할 수 있는 역량으로 연결됩니다.
===== 활동 기반 면접 질문 =====
1. 디올 유럽 지사를 위한 인재 채용 과정에서 150명 이상의 후보자와 3:1 인터뷰를 진행하셨다고 하셨습니다. 이 과정에서 어떤 기준으로 후보자를 평가하였고, 그 결과로 37명의 우수한 인재를 선별하는 데 어떤 전략을 사용하셨는지 구체적으로 설명해 주실 수 있나요?
2. 이탈리아 밀라노에서 열린 "Diversity & Inclusion Forum"에서 다문화 커뮤니케이션 전략을 개발하셨다고 하셨습니다. 이 과정에서 발생한 주요 도전 과제는 무엇이었으며, 이를 해결하기 위해 어떤 협업 방식이나 의사결정 과정을 거쳤는지 말씀해 주실 수 있나요?
3. 디올의 대규모 채용 프로젝트와 다문화 커뮤니케이션 전략 개발 경험을 통해 어떤 교훈을 얻으셨으며, 이러한 경험이 인사 관리 직무에서 어떻게 활용될 수 있을지 구체적으로 설명해 주실 수 있나요?
===== 트렌드 기반 뉴스 =====
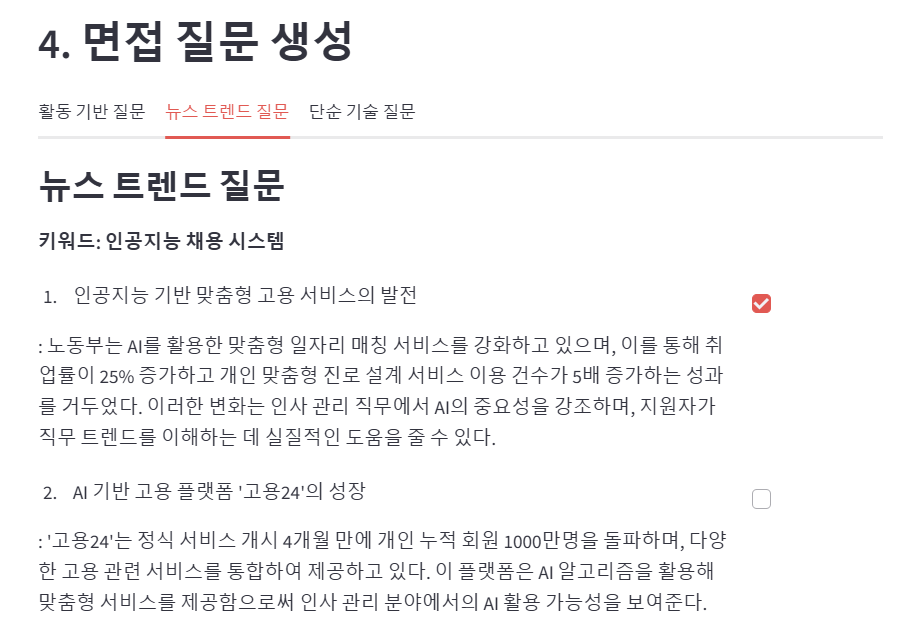
키워드: AI 기반 인재 채용
1. AI 기반 통합 고용 서비스 플랫폼의 발전
: '고용24'는 다양한 고용 서비스를 통합하여 사용자 편의성을 높이고, AI 기술을 활용해 구직자에게 맞춤형 일자리 추천을 강화하고 있으며, 이는 인사 관리 직무에서의 AI 기반 인재 채용 트렌드를 반영하고 있음.
2. AI 기반 개인 맞춤형 진로 및 경력 설계 서비스의 확장
: 인공지능(AI) 일자리 매칭을 통한 취업자 수가 증가하고 있으며, 개인 맞춤형 진로·경력설계 서비스의 이용이 급증하고 있어, AI 기술이 인사 관리 및 채용 과정에서 중요한 역할을 하고 있음을 보여줌.
3. 디지털 기술을 통한 인재 양성 및 취업 지원
: AI와 디지털 기술을 기반으로 한 맞춤형 교육과 취업 지원이 이루어지고 있으며, 이는 인사 관리 직무에서 필요한 인재를 양성하는 데 기여하고 있음.
-----------------------------
키워드: 직무 맞춤형 교육 플랫폼
1. [직무 맞춤형 교육 플랫폼의 혁신과 AI 활용]
: 아이비엠의 맞춤형 학습경로 및 커리큘럼 생성 솔루션은 직원의 기술 수준을 분석하여 개인화된 교육을 제공하며, 생성형 AI의 도입이 기업 서비스 관리의 혁신을 이끌고 있음. 이러한 기술들은 인사 관리 직무에서 필요한 역량을 체계적으로 개발하는 데 실질적인 도움을 줄 수 있음.
2. [스타트업과 기업의 AI 기반 교육 및 지원]
: 다양한 스타트업들이 AI 기반의 교육 프로그램과 투자 지원을 통해 인재 양성을 촉진하고 있으며, 스노우플레이크의 데이터 및 AI 전문 인재 양성 프로그램은 실무 역량 강화를 목표로 하고 있음. 이는 인사 관리 분야에서의 인재 개발 및 채용 전략에 중요한 통찰을 제공함.
3. [규제과학 인재 양성을 위한 맞춤형 교육 플랫폼]
: 식품의약품안전처의 '규제과학IN' 플랫폼은 수요자 중심의 맞춤형 교육과정을 제공하여 규제과학 분야의 전문 인력을 양성하는 데 기여하고 있음. 이러한 플랫폼은 인사 관리 직무에서 필요한 규제 이해 및 전문성을 높이는 데 유용할 수 있음.
-----------------------------
키워드: 직원 경험 데이터 분석
1. AI를 통한 조직 투명성 및 데이터 기반 의사결정 강화
: 90%의 기업이 AI가 조직의 투명성과 책임성을 향상시킬 것이라고 믿으며, 데이터 기반 의사결정과 직원 역량 강화를 우선시하고 있음. AI 활용이 이제는 필수적인 흐름으로 자리잡고 있으며, 다양한 산업에서 AI 기술을 접목하여 고객 경험을 확대하고 있음.
2. 생성형 AI의 도입과 업무 혁신
: 기업의 82%가 생성형 AI를 도입하거나 평가 중이며, 실제 운영에 활용하는 비율도 증가하고 있음. 생성형 AI는 직원 생산성을 42% 향상시키고, 업무 방식을 혁신적으로 변화시키는 데 기여하고 있음. 특히, 발전소 설비 운영에 특화된 AI 서비스가 개발되어 업무 효율성을 높이고 있음.
3. 맞춤형 HR 솔루션과 AI 기술의 접목
: PSI컨설팅은 인재 선발부터 육성까지 맞춤형 HR 솔루션을 제공하며, AI 기술을 도입하여 HR 서비스 혁신을 가속화하고 있음. 한국형 ERP 솔루션을 발전시키며 각 산업의 요구를 충족하는 맞춤형 솔루션을 제공하고, 고객 만족과 품질 개선에 주력하고 있음.
선택한 토픽 - 생성형 AI의 도입과 업무 혁신
관련 기사
https://view.asiae.co.kr/article/2025011715491730313 우리은행 117억 투입해 생성형 AI 인프라 구축한다
https://zdnet.co.kr/view/?no=20250123155901 "유통업체 절반, AI 6개 이상 활용"…엔비디아 보고서
https://www.etnews.com/20250122000200 유알피, 서부발전과 협력 발전사 최초 생성형 AI '더블유피 지피티(WP-GPT)' 개발
===== 생성된 뉴스 트렌드 질문 =====
[생성형 AI의 도입과 업무 혁신]
1. 생성형 AI가 인사 관리 분야에서 직원 경험을 어떻게 향상시킬 수 있다고 생각하십니까?
2. 기업들이 생성형 AI를 도입하면서 직원들의 업무 방식이 변화하고 있는데, 이러한 변화가 인사 관리에 미치는 영향은 무엇이라고 보십니까?
3. 생성형 AI를 활용한 직원 경험 데이터 분석이 인사 관리 전략에 어떻게 기여할 수 있을지에 대한 귀하의 의견은 무엇입니까?
===== 생성된 단순 기술 질문 =====
1. 인재 확보 전략을 수립할 때 고려해야 할 주요 요소는 무엇인가요?
2. 직원 교육 프로그램을 설계할 때, 어떤 기준을 사용하여 교육 내용을 결정하시겠습니까?
3. 성과 관리 시스템의 중요성과 그 운영 방식을 설명해 주세요.ML 엔지니어 / 네이버
활동1 개인형 이동장치 사고 다발지 데이터를 분석하여 취약지를 예측하는 머신러닝 모델을 개발했습니다. XGBoost, LinearSVR, Ridge, Random Forest 모델을 비교한 결과, MSE가 가장 낮은 XGBoost를 선정하여 최종 모델로 사용했습니다. 데이터 EDA를 통해 주요 특징을 도출했으며, Tableau로 시각화해 집중 단속 구역을 효과적으로 제안했습니다.
활동2 사용자 입력 데이터를 기반으로 코사인 유사도를 계산하여 데이트 코스를 추천하는 시스템을 설계했습니다. 선유도역 주변의 카페와 맛집 정보를 분석하고, 개인화된 추천 알고리즘을 구현해 사용자 맞춤형 서비스를 제공했습니다.
===== 생성된 채용 공고 =====
1. 조직 설명: 네이버의 ML 엔지니어 팀은 인공지능 및 머신러닝 기술을 활용하여 다양한 서비스의 성능을 향상시키고, 사용자 경험을 개선하는 것을 목표로 합니다. 이 팀은 데이터 분석과 모델링을 통해 네이버의 플랫폼에 혁신적인 솔루션을 제공하며, 최신 기술을 적용하여 경쟁력을 유지하고 있습니다.
2. 직무 설명: ML 엔지니어는 머신러닝 모델의 설계, 개발 및 최적화를 담당합니다. 주요 업무에는 데이터 수집 및 전처리, 모델 학습 및 평가, 성능 개선을 위한 하이퍼파라미터 튜닝, 그리고 모델 배포 및 운영이 포함됩니다. 또한, 다양한 서비스에 적용할 수 있는 머신러닝 알고리즘 연구 및 개발도 수행합니다.
3. 필요 역량: ML 엔지니어로서 성공적으로 업무를 수행하기 위해서는 머신러닝 및 딥러닝 관련 기술에 대한 깊은 이해와 경험이 필요합니다. Python, TensorFlow, PyTorch 등의 프로그래밍 언어 및 프레임워크 사용 능력이 요구되며, 데이터 분석 및 통계적 방법론에 대한 지식도 필수적입니다. 또한, 문제 해결 능력과 팀 내 협업을 위한 소통 능력이 중요하며, 최신 AI 기술 동향에 대한 관심과 학습 의지가 필요합니다.
===== 기존 DB의 유사 채용 공고 =====
토스의 메이커 조직인 사일로(Silo)는 프로덕트 오너, 프로덕트 디자이너, 개발자, 데이터 분석가 등 다양한 직군의 68명이 모여 자율적으로 운영되는 팀입니다. 이 조직은 작은 스타트업처럼 독립적으로 일하며, 머신러닝을 통해 개인화 추천, 광고 최적화 등 도메인 문제를 해결하는 것을 목표로 하고 있습니다. 사일로는 토스의 주요 제품과 비즈니스 성장을 지원하는 역할을 수행합니다.ML Engineer는 딥러닝 및 머신러닝 모델을 설계하고 프로덕션 환경에 적용하여 제품 성능을 지속적으로 개선하는 업무를 맡습니다. 이들은 프로덕션 레벨의 고성능 ML 모델을 구축하고 최적화하며, 추천 광고 최적화를 위한 딥러닝 모델을 실제 서비스에 서빙하고 운영합니다. 또한, 프로덕트 담당자와 협력하여 비즈니스 요구 사항을 이해하고 적합한 기술적 솔루션을 제안 및 구현하며, 대규모 시스템을 안정적으로 운영하고 최적화하는 책임을 집니다.ML Engineer로서 성공적으로 업무를 수행하기 위해서는 딥러닝과 머신러닝에 대한 탄탄한 지식이 필요합니다. Pytorch, TensorFlow와 같은 딥러닝 프레임워크를 사용하여 프로덕션 환경에서 모델을 개발하고 운영한 경험이 요구됩니다. 또한, SQL과 같은 데이터베이스 기술 및 Hadoop, Spark 등 빅데이터 플랫폼을 활용한 경험이 필요합니다. 비기술적 역량으로는 복잡한 기술적 문제를 명확하고 효과적으로 해결할 수 있는 능력과, 진행한 과제가 조직에 미친 영향력을 설명할 수 있는 커뮤니케이션 능력이 중요합니다.
ML Engineer Platform은 ML 플랫폼 팀의 일원으로, 데이터 과학자(DS) 및 MLOps 엔지니어와 협력하여 머신러닝(ML) 기술을 활용해 토스팀의 다양한 문제를 해결하고 ML 기반의 서비스 및 제품을 제공합니다. 이 팀은 새로운 제품 탐색, 데이터 파이프라인 구축, ML 모델링 및 서빙, 모니터링 등 ML의 전 과정을 유기적으로 다루며, 개인화 추천, 검색 광고 최적화, 생성형 AI 어플리케이션 개발 등 다양한 프로젝트를 진행합니다. 또한, ML 파이프라인의 효율성을 높이기 위한 플랫폼 개발과 MLOps 인프라 구축에도 집중하고 있습니다.ML Engineer는 대규모 데이터에 기반한 Feature Store, Model Trainer, ML Monitoring 시스템 등을 설계하고 개발하여 ML 파이프라인을 최적화하는 역할을 맡습니다. 여러 팀이 공통으로 사용하는 ML 라이브러리를 개발하고 성능을 개선하여 효율적이고 확장 가능한 시스템을 지원하며, 머신러닝 모델을 개발하고 토스의 다양한 서비스에 맞게 최적화합니다. 또한, ML 시스템의 확장성과 안정성을 확보하고, 머신러닝 작업을 효과적으로 수행할 수 있도록 베스트 프랙티스와 가이드라인을 작성 및 공유합니다. 마지막으로, ML 모델을 프로덕션 환경에 서빙하여 안정적인 운영을 보장하고 최적화하는 업무를 수행합니다.이 직무를 성공적으로 수행하기 위해서는 머신러닝과 딥러닝에 대한 깊이 있는 지식과 대규모 시스템 설계 및 엔지니어링 문제에 대한 경험이 필요합니다. Pytorch, TensorFlow, HuggingFace와 같은 주요 머신러닝 및 딥러닝 라이브러리를 능숙하게 사용할 수 있어야 하며, SQL 및 빅데이터 플랫폼(Hadoop, Spark 등)을 다룰 수 있는 능력이 요구됩니다. 또한, 머신러닝 모델 경량화 및 서빙 최적화 경험이 중요하며, 복잡한 기술적 개념을 명확하고 쉽게 설명할 수 있는 커뮤니케이션 능력도 필수적입니다. 과거에 진행한 프로젝트가 조직에 미친 영향력이나 오픈소스 기여 경험도 중요한 평가 요소입니다.
ML Engineer LLM은 ML 플랫폼 팀의 일원으로, 데이터 과학자(DS) 및 MLOps 엔지니어와 협력하여 대규모 언어 모델(LLM)을 활용해 다양한 문제를 해결하고 서비스를 제공하는 역할을 맡고 있습니다. 이 팀의 목표는 LLM을 기반으로 한 새로운 제품과 유스케이스를 탐색하고 발굴하며, ML 기술을 통해 개인화 추천, 검색 광고 최적화, 생성형 AI 어플리케이션 개발 등 다양한 비즈니스 요구사항을 충족하는 것입니다. 팀은 ML 전체 파이프라인의 효율성을 높이고 MLOps 인프라를 구축하는 데 중점을 두고 있습니다.ML Engineer LLM의 주요 업무는 LLM을 활용한 유스케이스의 발굴, 설계, 구현 및 실시간 서비스 배포입니다. 이 과정에서 LLM 모델의 훈련 및 파인튜닝, 데이터 파이프라인 구현, 성능 모니터링 및 개선 작업을 포함합니다. 또한, LLM의 효율성을 극대화하기 위한 최적화 작업과 하이퍼파라미터 튜닝을 수행하며, 오픈소스 LLM을 활용한 유스케이스 개발 및 커스터마이징 경험이 요구됩니다. 팀은 복잡한 모델 아키텍처를 이해하고 설명할 수 있는 능력도 중요시합니다.이 직무를 성공적으로 수행하기 위해서는 다음과 같은 기술적 역량이 필요합니다: Pytorch 및 TensorFlow와 같은 딥러닝 프레임워크를 활용한 모델 개발 및 최적화 경험, LLM 훈련 데이터 준비 및 파이프라인 구축 경험, 하이퍼파라미터 튜닝에 대한 깊이 있는 이해. 비기술적 역량으로는 복잡한 모델 아키텍처와 성능을 쉽게 설명할 수 있는 커뮤니케이션 능력, 문제 해결을 위한 창의적 접근 방식, 그리고 실전에서의 다양한 상황을 설명할 수 있는 경험이 요구됩니다. LLM 기술에 대한 비전과 목표를 명확히 하는 것도 중요합니다.
===== 최종 필요 역량 =====
1. 기술적 역량:
- **머신러닝 및 딥러닝 지식**: 머신러닝 및 딥러닝 알고리즘에 대한 깊은 이해와 경험이 필요하며, 이를 통해 다양한 문제를 해결하고 모델을 설계 및 최적화할 수 있어야 합니다.
- **프로그래밍 언어 및 프레임워크 사용 능력**: Python, TensorFlow, PyTorch와 같은 프로그래밍 언어 및 머신러닝 프레임워크를 능숙하게 다룰 수 있어야 하며, 이를 통해 모델 개발 및 배포를 효과적으로 수행할 수 있어야 합니다.
- **데이터 분석 및 통계적 방법론**: 데이터 수집, 전처리 및 분석에 대한 지식이 필요하며, 통계적 방법론을 활용하여 모델의 성능을 평가하고 개선할 수 있는 능력이 요구됩니다.
2. 비기술적 역량:
- **문제 해결 능력**: 복잡한 문제를 분석하고 창의적인 해결책을 제시할 수 있는 능력이 중요하며, 이를 통해 팀의 목표를 달성하는 데 기여할 수 있어야 합니다.
- **소통 및 협업 능력**: 팀 내 다양한 직군과 효과적으로 소통하고 협력할 수 있는 능력이 필요하며, 이를 통해 비즈니스 요구 사항을 이해하고 적합한 기술적 솔루션을 제안할 수 있어야 합니다.
- **학습 의지 및 최신 기술 동향에 대한 관심**: 최신 AI 및 머신러닝 기술 동향에 대한 지속적인 관심과 학습 의지가 필요하며, 이를 통해 팀의 경쟁력을 유지하고 혁신적인 솔루션을 제공할 수 있어야 합니다.
다음 문항 중 도움이 필요한 문항을 선택하세요 (최소 1개, 최대 5개 선택 가능)
1. 동기/포부
2. 성장/가치관
3. 역량/경험
4. 협업/성과
5. 기업/아이디어
선택한 문항의 번호를 입력하세요 (쉼표로 구분): 3,4
===== 자기소개서 항목 글감 및 개요 =====
[ 역량/경험 ]
- **강조 역량**: 머신러닝 및 딥러닝 지식
**글감**: 개인형 이동장치 사고 다발지 데이터를 활용한 머신러닝 모델 개발 경험
**개요**:
- **배경 설명**: 최근 개인형 이동장치의 보급이 증가함에 따라 사고 발생률 또한 증가하고 있습니다. 이러한 문제를 해결하기 위해, 저는 사고 다발지 데이터를 분석하여 취약지를 예측하는 머신러닝 모델을 개발하는 프로젝트에 참여했습니다. 이 과정에서 데이터의 중요성을 인식하고, 효과적인 데이터 분석 및 모델링의 필요성을 느꼈습니다.
- **성과/결과**: 다양한 머신러닝 알고리즘을 비교 분석한 결과, XGBoost 모델이 가장 낮은 MSE를 기록하여 최종 모델로 선정되었습니다. 또한, 데이터 탐색적 분석(EDA)을 통해 주요 특징을 도출하고, Tableau를 활용하여 시각화함으로써 집중 단속 구역을 효과적으로 제안할 수 있었습니다. 이로 인해 관련 기관에서 사고 예방을 위한 정책 결정에 기여할 수 있었습니다.
- **직무/기업과의 연결**: ML 엔지니어로서 요구되는 머신러닝 및 딥러닝 지식은 이 프로젝트를 통해 실질적으로 강화되었습니다. 또한, 다양한 알고리즘을 비교하고 최적의 모델을 선택하는 과정은 직무에서의 모델 설계 및 최적화 능력과 직접적으로 연결됩니다. 이러한 경험은 기업의 데이터 기반 의사결정 및 문제 해결에 기여할 수 있는 강력한 자산이 될 것입니다.
[ 협업/성과 ]
- **강조 역량**: 문제 해결 능력
**글감**: 개인화된 추천 알고리즘을 통한 사용자 맞춤형 서비스 제공
**개요**:
- **배경 설명**: 선유도역 주변의 카페와 맛집 정보를 분석하여 사용자에게 최적의 데이트 코스를 추천하는 시스템을 설계했습니다. 이 과정에서 다양한 데이터 소스를 활용하여 사용자 선호도를 반영한 추천 알고리즘을 개발하는 데 집중했습니다.
- **성과/결과**: 이 시스템을 통해 사용자들은 보다 개인화된 경험을 제공받았으며, 추천의 정확도가 향상되어 사용자 만족도가 크게 증가했습니다. 또한, 이 프로젝트는 팀 내에서의 협업을 통해 진행되었으며, 다양한 피드백을 반영하여 알고리즘을 지속적으로 개선했습니다.
- **직무/기업과의 연결**: ML 엔지니어로서 요구되는 문제 해결 능력은 이 프로젝트에서 발휘되었습니다. 복잡한 데이터 분석 및 알고리즘 설계 과정에서 창의적인 해결책을 제시하며 팀의 목표를 달성하는 데 기여했습니다. 이러한 경험은 머신러닝 및 딥러닝 알고리즘을 활용하여 다양한 문제를 해결하는 데 필요한 역량을 강화하는 데 도움이 되었습니다.
===== 활동 기반 면접 질문 =====
1. 개인형 이동장치 사고 다발지 데이터를 활용한 머신러닝 모델 개발 과정에서, 데이터 탐색적 분석(EDA)을 통해 도출한 주요 특징은 무엇이었으며, 이 특징들이 모델 성능에 어떤 영향을 미쳤는지 구체적으로 설명해 주실 수 있나요?
2. 개인화된 추천 알고리즘을 개발하는 과정에서 팀원들과의 협업은 어떻게 이루어졌으며, 다양한 피드백을 반영하여 알고리즘을 개선하는 데 어떤 구체적인 방법을 사용하셨는지 말씀해 주실 수 있나요?
3. 개인형 이동장치 사고 예측 모델 개발과 개인화된 추천 알고리즘 프로젝트에서 얻은 경험을 바탕으로, ML 엔지니어로서 직무를 수행하는 데 가장 중요한 교훈이나 배운 점은 무엇이며, 이를 어떻게 적용할 계획인지 설명해 주실 수 있나요?
===== 트렌드 기반 뉴스 =====
키워드: AutoML 플랫폼
1. 데이터 통합 플랫폼과 AI 모델 관리의 중요성
: 많은 기업들이 데이터 통합 플랫폼과 자동화된 AI 모델 관리 시스템을 도입하여 AI 활용의 효율성과 안전성을 높이고 있으며, 데이터 거버넌스 기능을 강화하여 AI 모델의 신뢰성을 보장하고 있음.
2. MLOps 플랫폼을 통한 AI 기술 상용화
: MLOps(Machine Learning Operations) 플랫폼은 AI 개발과 운영의 모든 과정을 통합 관리하여 AI 기술 활용 효과를 극대화하며, 현대 비즈니스에서 필수적인 요소로 자리잡고 있음.
3. 자동화 MLOps 플랫폼 개발의 진전
: 와이즈넛은 자동화된 MLOps 플랫폼 기술 개발을 완료하여, 전문가뿐만 아니라 비전문가도 쉽게 AI 모델을 활용할 수 있도록 지원하며, AutoML 기술과 GPU 클러스터링을 통해 고성능 AI 모델 개발을 용이하게 하고 있음.
-----------------------------
키워드: Federated Learning
1. 개인정보 보호와 연합 학습의 중요성
: 정부는 개인정보 보호 강화기술을 논의하며, 연합 학습(Federated Learning)을 통해 민감한 데이터를 안전하게 활용할 수 있는 방안을 모색하고 있음. 이는 AI 모델 개발에 있어 개인정보 보호와 데이터 활용의 균형을 이루는 중요한 기술로 자리잡고 있음.
2. 연합 학습을 통한 AI 혁신과 신약 개발
: 연합 학습은 여러 기관이 보유한 데이터를 외부로 전송하지 않고도 공동 AI 모델을 개발할 수 있게 하여, K-MELLODY 프로젝트와 같은 신약 개발 플랫폼 구축에 기여하고 있음. 이는 보건 의료 분야에서 개인정보 보호와 데이터 활용을 동시에 가능하게 하는 혁신적인 접근법임.
3. 제약바이오 산업의 AI 데이터 활용 문제
: 제약바이오 산업은 AI 학습 데이터 확보에 어려움을 겪고 있으며, 이를 해결하기 위한 정책적 방향과 인재 양성의 필요성이 강조되고 있음. AI 신약 개발을 위한 데이터 활용 전략이 필요하며, 정부의 지원과 IT 기술의 결합이 중요하다는 의견이 제시됨.
-----------------------------
키워드: AI 윤리 기준
1. [AI 헬스케어 및 연구 윤리 가이드라인]
: 정부가 생성형 AI 헬스케어 시대를 대비하여 연구 윤리 가이드라인을 제정하고, 세계 최초로 생성형 AI 의료기기 허가 지침을 마련함으로써 의료 분야의 혁신과 안전성을 동시에 확보하려는 노력을 하고 있음.
2. [생성형 AI 의료기기 허가 및 심사 기준]
: 한국이 세계 최초로 생성형 AI 의료기기 허가 및 심사 가이드라인을 제정하여, 안전성과 유효성을 평가하고 제품화를 지원하는 체계를 구축함으로써 AI 기술의 의료 분야 적용을 선도하고 있음.
3. [AI 안전성과 산업 적용 가능성]
: 한국 인공지능산업협회가 AI 기술의 안전성과 산업 적용 가능성을 논의하며, 기업들이 AI 규제 장벽을 극복할 수 있도록 지원하겠다는 포부를 밝힘으로써 AI 기술의 발전과 안전성을 동시에 추구하고 있음.
원하는 키워드를 고르세요: 1
원하는 뉴스 토픽을 고르세요: 2
선택한 토픽 - MLOps 플랫폼을 통한 AI 기술 상용화
관련 기사
https://www.sedaily.com/NewsView/2DGX3A5XTM 와이즈넛, 미래 AI 기술 선도할 'MLOps 플랫폼' 3차년도 연구 성료
http://www.segye.com/newsView/20241120509521 와이즈넛, 'MLOps 플랫폼' 기술 개발 과제 3차년도 연구 완료
https://www.seoul.co.kr/news/economy/2024/11/20/20241120500112 와이즈넛, 비전문가도 쉽게 AI 기술 활용 가능한 ‘MLOps 플랫폼’ 3차년도 연구 완료
===== 생성된 뉴스 트렌드 질문 =====
[MLOps 플랫폼을 통한 AI 기술 상용화]
1. MLOps 플랫폼의 주요 구성 요소와 그 역할에 대해 설명해 주시겠습니까? 특히 AutoML 기술이 어떻게 통합되어 있는지에 대해 논의해 주세요.
2. AI 모델의 배포와 운영 모니터링 과정에서 발생할 수 있는 주요 도전 과제는 무엇이며, 이를 해결하기 위한 전략은 무엇이라고 생각하십니까?
3. 비전문가도 쉽게 사용할 수 있는 MLOps 플랫폼을 구축하기 위해 어떤 기능이나 인터페이스가 필요하다고 생각하십니까?
===== 생성된 단순 기술 질문 =====
1. 머신러닝 모델을 훈련시키기 위한 데이터 전처리 과정에서 어떤 단계들이 포함되는지 설명해 주세요.
2. '하이퍼파라미터 튜닝'의 중요성에 대해 설명하고, 이를 위해 어떤 기법들을 사용할 수 있는지 예시를 들어주세요.
3. 딥러닝 모델을 배포할 때 고려해야 할 주요 요소들은 무엇이며, 이를 통해 사용자 경험을 어떻게 개선할 수 있는지 설명해 주세요.의의
이 프로젝트는 취업 준비 과정에서 LLM을 활용할 때 사용자들이 겪는 불편함과 어려움을 해결하고자 하는 목적에서 시작되었는데요. 기존 LLM 사용 방식에서는 원하는 결과를 얻기 위해 사용자가 직접 모델을 훈련하거나, 적합한 프롬프트를 작성하고 수정하는 번거로운 과정을 거쳐야 했습니다. 더불어, 제공되는 답변이 개인화되지 않거나 최신 트렌드를 반영하지 못할 가능성도 있었습니다. 이러한 페인 포인트는 특히 취업 준비라는 복잡한 과정에서 사용자들이 느끼는 막막함과 부담을 가중시키는 요인으로 작용했습니다. 이를 해결하기 위해 사용자 친화적인 AI Agent를 설계하여, 사용자가 겪는 번거로움을 최소화하고 실질적으로 도움이 되는 지원을 제공하고자 했습니다. 복잡한 프롬프트 작성이나 모델 훈련 과정 없이도 사용자 맞춤형 결과를 도출할 수 있습니다. 첫째, 사용자가 입력한 희망 직무와 회사 정보에 따라 자동으로 관련 데이터를 검색하고 분석하여 적절한 가상 공고를 생성합니다. 둘째, 사용자의 활동 이력을 반영해 개인화 된 자기소개서 작성 아이디어를 제공함으로써, 개별 사용자의 경험과 목표에 맞는 지원을 가능하게 했습니다. 셋째, 최신 트렌드와 직무 요구사항을 반영한 면접 질문을 생성함으로써, 변화하는 산업 환경에 맞는 정보를 제공합니다. 기술적으로는 RAG(Retrieval-Augmented Generation) 방식을 활용해 데이터 검색과 요약 과정을 통합함으로써, 정보의 정확성과 적합성을 높였습니다. 매일 업데이트되는 뉴스 API와 실제 채용 공고 DB를 활용함으로써 정확한 직무 정보를 제공했습니다. Upstage Solar 모델을 활용하여 텍스트를 임베딩해 유사성을 분석하고, gpt-4o-mini 모델을 통해 정보를 요약 및 생성하는 과정을 자동화하여, 사용자가 보다 직관적이고 효율적으로 결과를 얻을 수 있도록 지원했습니다. 이와 같은 접근은 기존 LLM의 한계를 보완하고, 취업 준비라는 특정 도메인에서 개인화 된 경험을 제공하는 데 기여했다는 점에서 중요한 의의를 가집니다. 마지막으로 신속하고 비용 효율적인 솔루션을 제공합니다. 직무 입력부터 공고 생성, 자기소개서 글감 개요 생성과 다양한 종류의 면접 예상 질문 생성까지 모든 프로세스가 2분 이내로 완료됩니다. OpenAI API 호출 비용 역시 전체 프로세스에 대해 0.01 달러 미만으로, 매우 적은 비용으로도 취업 준비에 큰 도움을 받을 수 있습니다.
한계
이 서비스는 취업 준비 과정의 사용자들에게 역량 파악, 자기소개서 글감 생성, 면접 질문 생성 등 여러가지 도움을 주지만 여전히 몇 가지 한계를 지니는데, LLM 및 RAG 기술의 특성상 입력된 데이터와 프롬프트에 대한 의존도가 높습니다. 데이터에 노이즈가 포함되거나 프롬프트가 부정확할 경우, 생성된 결과물이 사용자의 기대에 미치지 못할 위험이 존재합니다. 특히, 개인화된 답변을 제공하려는 목표에도 불구하고, 사용자가 기대한 만큼의 세부적이고 맥락에 맞는 결과를 제공하지 못할 가능성도 있습니다. 이는 프로젝트가 지향하는 개인화와 정확성의 수준이 기술적 한계에 따라 달라질 수 있음을 보여줍니다. 아울러, 최신 트렌드를 반영하는 면에서의 어려움도 한계로 작용합니다. 면접 질문 생성이나 산업 동향 분석에서 최신 정보를 제공하는 것을 목표로 하지만, 데이터 업데이트가 실시간으로 이루어지지 않거나 모델 학습이 적시에 진행되지 않으면 최신성을 유지하기 어렵습니다. 이는 사용자들이 변화하는 환경에 맞는 정보를 얻는 데 장애가 될 수 있습니다. 또한, 서비스의 효과를 객관적으로 평가하고 검증하는 데 있어 한계가 있습니다. 자기소개서 작성 아이디어의 품질이나 사용자가 느끼는 만족도를 정량적으로 측정하는 것은 쉽지 않으며, 이러한 평가는 대체로 주관적인 피드백에 의존할 수밖에 없습니다. 마지막으로, 채용 공고 DB의 한계도 존재하는데, 우선 수동으로 DB를 업데이트해야 합니다. 또한 현재 채용 공고 DB는 IT 기업 채용 공고 데이터 위주로, 그 외 산업의 직무 요구사항이 충분히 반영되지 않을 수 있습니다. 이는 다양한 직군, 다양한 도메인의 채용 공고를 수집함으로써 어느 정도 보완될 수 있으리라 생각합니다.