
0️⃣ What is VTG?
Video Temporal Grounding (VTG)
Video Temporal Grounding (VTG)는 주어진 텍스트 쿼리에 대해 비디오 내에서 관련된 시간 구간을 찾아내는 태스크입니다. 이 태스크는 비디오의 시간적 특성을 효과적으로 반영해야 하며, 자연어 텍스트가 비디오에 어떻게 연결되는지를 학습하는 데 중점을 둡니다. 비디오 내에서 특정 이벤트나 행동이 일어나는 시간적 구간을 정확하게 식별하는 것은 VTG의 핵심 목표입니다. 예를 들어, "빨간 모자를 쓴 투수가 공을 던지는 장면을 보여줘"라고 요청했을 때, VTG는 비디오 내에서 이 장면이 시작하는 시점과 끝나는 시점을 찾아냅니다. VTG 모델은 이 요청에 맞는 비디오 구간을 찾기 위해, 비디오 내에서 투수가 공을 던지는 장면이 시작되고 끝나는 시간 범위를 식별해야 합니다. 이 과정에서 텍스트의 의미를 비디오의 시간적 컨텍스트에 매핑하는 작업이 필요합니다.

1️⃣ Motivation
“Multimodal스러운 Task”
비디오는 이미지와 시간 정보를 포함하며 텍스트와 오디오 등 다양한 데이터를 담고 있어 분석 가치가 높은 멀티모달 특성을 지니고 있습니다. 특히, Video Temporal Grounding (VTG)은 비디오의 시간적 특성을 효과적으로 반영할 수 있는 테스크로, 최근 활발히 연구되고 있는 주제입니다. 저희 팀은 기존 VTG 모델 중 Training-Free 방식을 다룬 논문에서 영감을 받아 학습 과정 없이도 효율적이고 직관적인 방법을 제안하는 것을 목표로 삼았습니다.
2️⃣ Our Task
Temporal Information
그렇다면 동영상의 프레임 하나만 잘 이해하면 동영상을 이해했다고 할 수 있을까요? 예를 들어 공이 크롭 된 이미지를 본다면, 그 공이 운동 경기의 어느 상황에서 나온 것인지 알 수 없습니다. 즉, 단순히 비디오의 정적인 프레임만 이해한다고 해서 동영상의 맥락을 완벽히 파악할 수 없습니다. 따라서 비디오를 제대로 이해하려면 연속적인 프레임 간의 시간 정보를 이해하는 것이 필수적입니다.


3️⃣ Methodology
기존 VTG 모델의 Pipeline

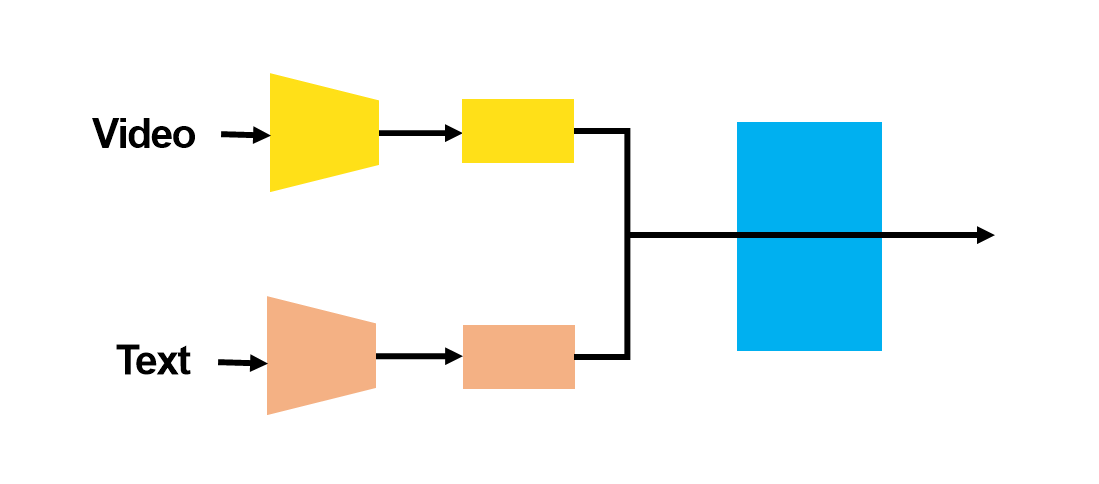
VTG 모델의 일반적인 파이프라인은 다음과 같은 과정을 거칩니다. 먼저, 비디오에서 Video Embedding 추출하고, Temporal Modeling을 통해 맥락, 동작의 연속성 등 시간 차원에서의 변화를 학습합니다. 생성된 Video Feature는 텍스트 인코더를 통해 추출한 Text Feature와 결합됩니다. 이 과정에서 Multimodal Fusion이 사용되며, 필요에 따라 Proposal Model을 적용해 비디오 내에서 해당 문장과 매칭되는 시간 구간을 추출하게 됩니다. Proposal Model은 대게 Sliding window 방식으로 Fusion에 함께 들어갑니다.
▶️ 기존 VTG 모델의 주요 구성 요소
- Video Encoder : 비디오의 각 프레임을 처리하여 비디오 임베딩 생성
- Text Encoder : 텍스트 데이터를 처리하여 텍스트 임베딩 생성
- Temporal Modeling : 시간적인 맥락을 학습하여 비디오 내에서의 시간적 특징을 추출
- 예: 연속적인 프레임 간의 관계를 모델링
- Proposal Model : 비디오 내 특정 구간(시작-끝 프레임)을 후보로 생성
- Multimodal Fusion : 비디오와 텍스트의 임베딩을 결합하여 텍스트 쿼리에 가장 적합한 비디오 구간을 탐색
- Proposal Scoring : 생성된 후보 구간의 점수를 계산하여 가장 적합한 구간을 선택
❓ Temporal Modeling 없이도 시간 정보를 받고 Multimodal Fusion으로 학습하지 않고도 구간을 추출해 낼 수 있지 않을까요?
제안 모델 Pipeline

저희 모델은Training-Free를 목표로 하며, 학습이 필요한 Temporal Modeling과 Multimodal Fusion을 사용하지 않고 간단한 구조로 구간을 추출하는 방식을 제안합니다. 기존의 VTG 모델이 Video Embedding과 Temporal Modeling을 통해 시간적 정보를 학습하는 반면, 저희는 이를 Image Feature로 대체하여 학습 과정 없이도 시간적 정보를 추출하고자 했습니다. 간단한 블록을 추가하여 이미지와 Text Feature 만으로 구간을 추출하는 구조를 설계했습니다.
💡주요 변경점
- Video Feature를 Image Feature로 대체
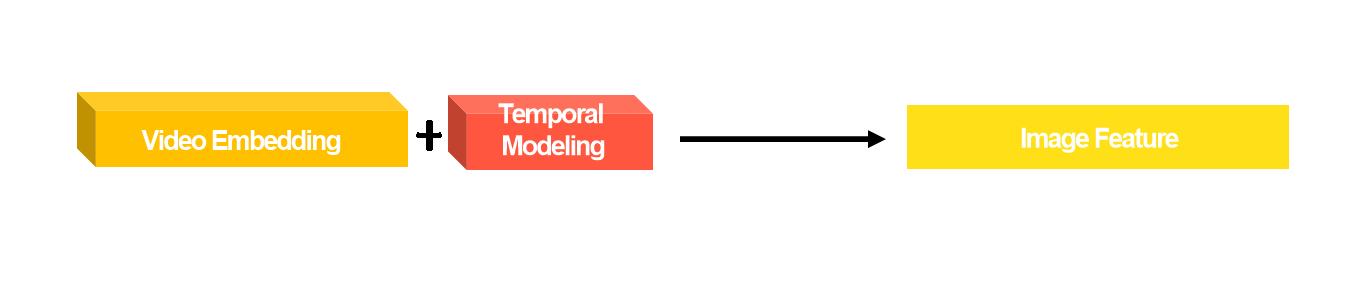
Image Feature만을 이용해서 시간적 정보를 얻습니다. 이를 통해 시간 차원이 줄어들어 훨씬 가벼운 모델로 실행이 가능합니다.
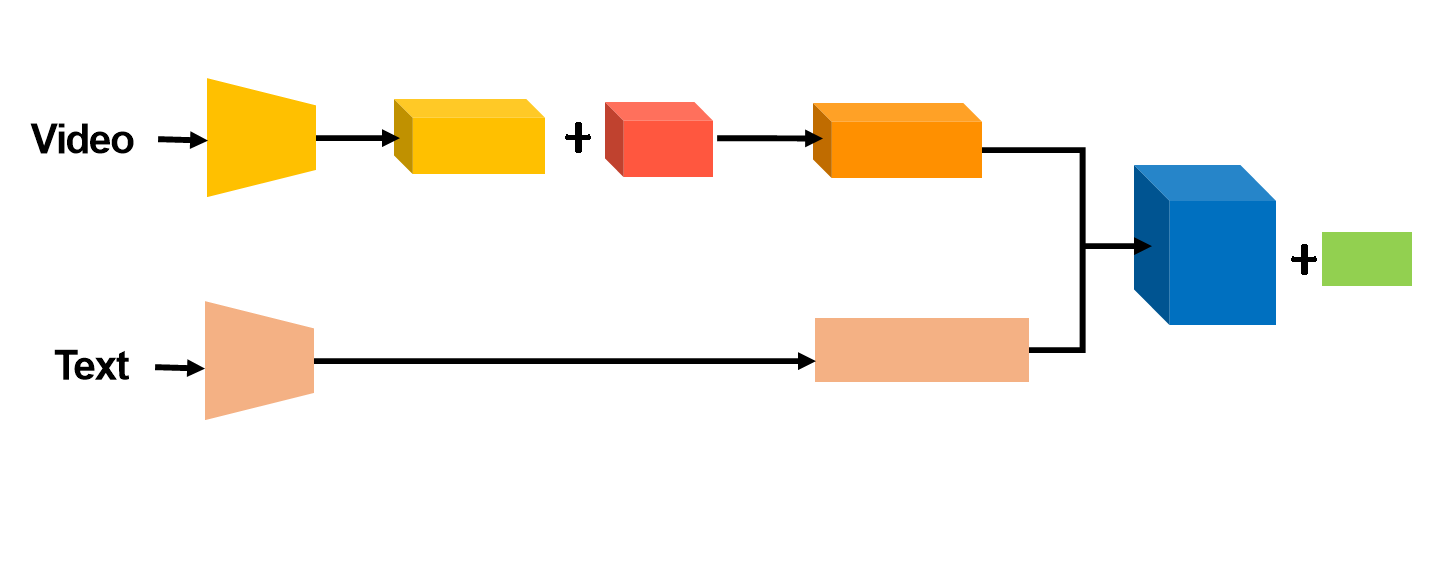
- Temporal Modeling 제거
학습 없이 Image Feature와 Text Feature를 이용한 단순 계산으로 구간 탐색 수행합니다. 직관적이면서 효율적인 구간 추출이 가능합니다.
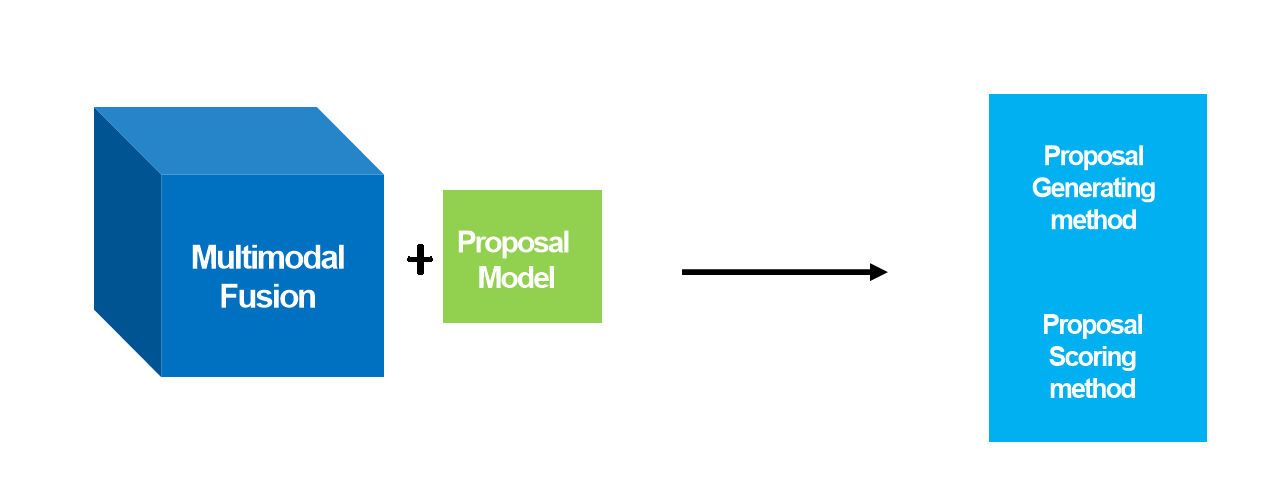
▶️ 제안하는 모델의 주요 구성 요소
- Image Encoder : 비디오의 각 프레임을 이미지 단위로 처리하여 특징을 추출
- Text Encoder : 텍스트 데이터를 처리하여 텍스트 임베딩 생성
- Proposal Generating Method :
- 프레임 간 유사도의 변화량(증가/감소)을 기반으로 구간 후보를 생성
- Gaussian Smoothing과 1차/2차 Gradient를 활용하여 급격한 유사도 변화 지점 탐지
- Proposal Scoring Method :
- 구간 내 프레임 유사도 평균과 구간 외 유사도 평균의 차이를 기반으로 점수를 계산
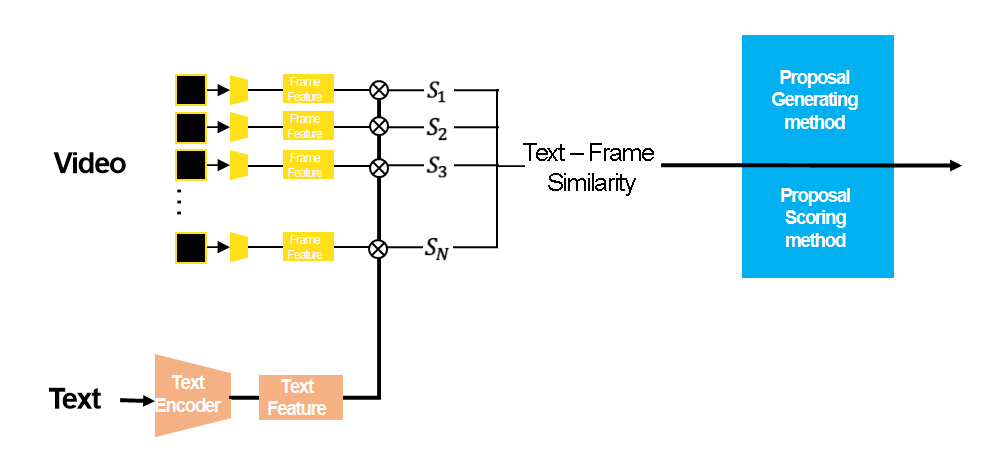
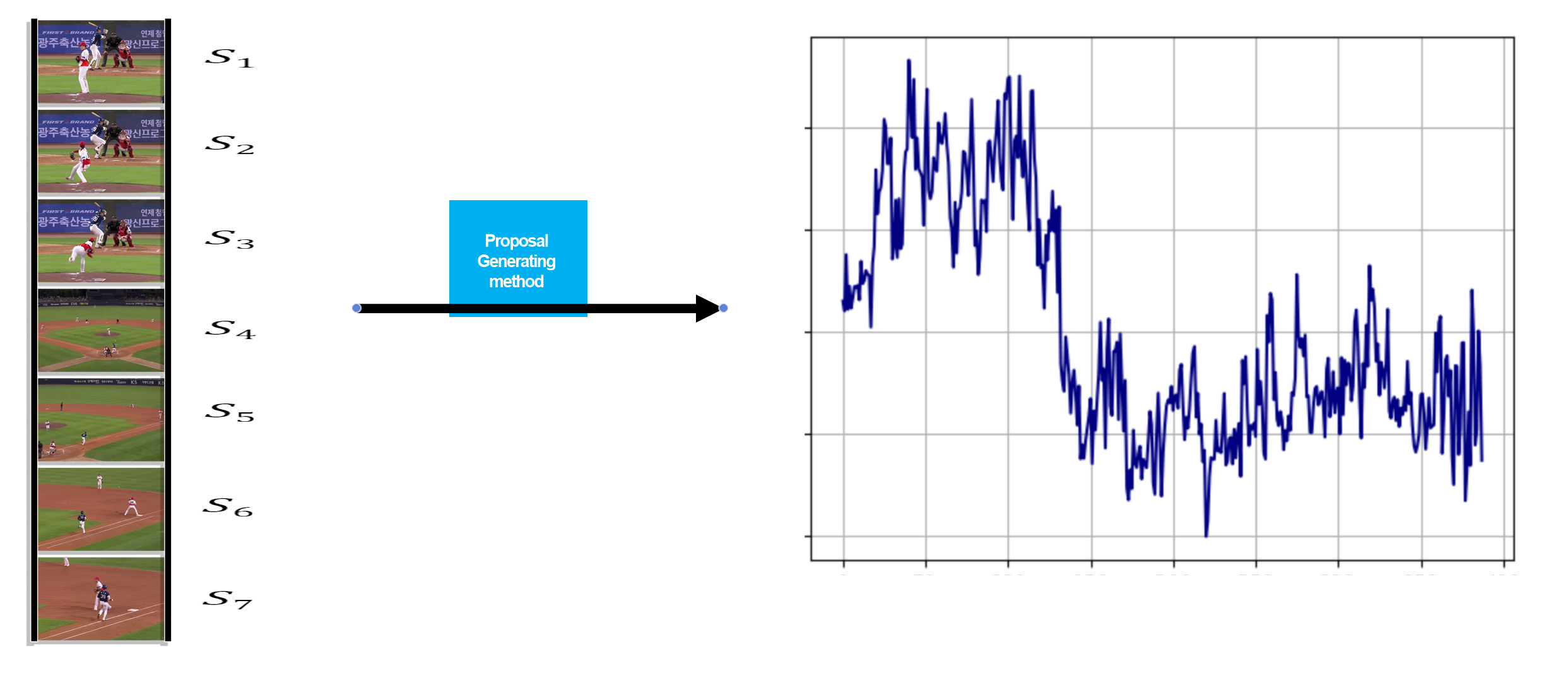
비디오는연속적인 이미지 프레임으로 구성됩니다. 기존 모델이 Temporal Modeling과 Multimodal Fusion을 필요로 한다면, 저희는 프레임과 Text Feature의 내적을 통해 프레임과 텍스트 유사도를 생성하여 시간 구간을 추출합니다. 이 방식은 비디오와 텍스트 간의 직접적인 연관성을 계산하여, 훈련이 필요 없는 효율적인 방법으로 구간을 찾을 수 있습니다. 이를 통해 텍스트와 가장 유사한 구간을 추출하는 방식으로 구간 추출을 수행합니다.
최종 구간 추출은 다양한 구간의 후보 중에서 Score이 제일 높은 구간을 추출합니다. 이를 위해서 구간 후보 생성 방안과 구간의 Score 측정 방안이 필요합니다.
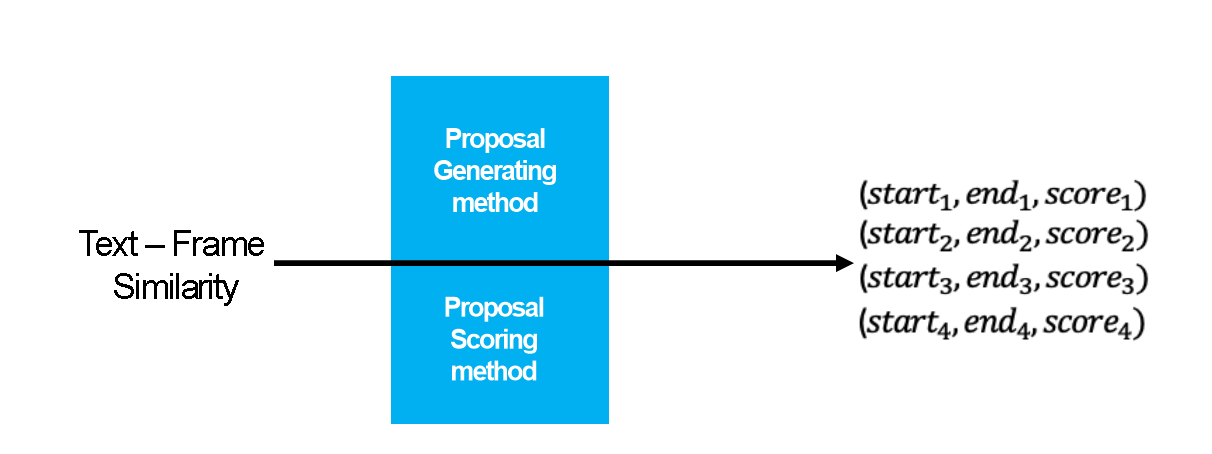
❓어떻게 시간적 정보 없이 구간을 추출할까요?

시간적 정보 없이 구간을 추출하기 위해 프레임 간 유사도 변화량을 활용합니다. 비디오는 연속적인 프레임들의 집합입니다. 따라서 프레임마다의 Text-Frame Similarity 차이를 활용하면 시간 정보를 간접적으로 얻을 수 있습니다. “프레임마다 차이를 구한다”는 말은 프레임의 시간에 따른 변화량을 계산해서 시간적 흐름을 유추하겠다는 뜻입니다. 예를 들어, 공의 움직임만 본다면 방향성을 알기 어려울 수 있지만 프레임 속 맥락을 해석하면 투수가 공을 던지는 장면임을 알 수 있습니다. 이를 통해 시간 정보를 추론할 수 있어 모든 시간 정보를 다 활용할 필요가 없습니다. 시간 정보를 직접 활용하지 않아도 인접한 프레임 간 유사도 변화를 통해 시간적 변화를 감지 할 수 있어, 이 변화를 기반으로 구간을 생성하는 방식이 가능하다고 판단합니다.
❓어떻게 구간의 점수를 측정할까요?
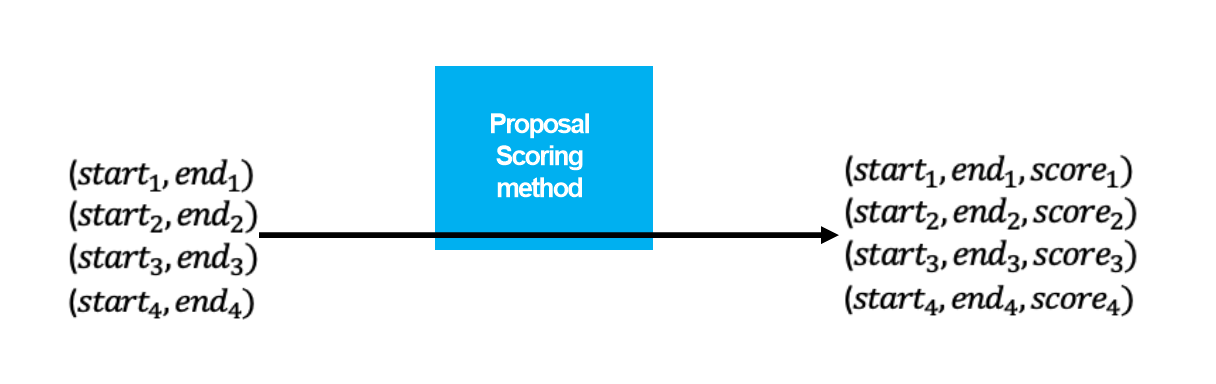
구간의 Score는 구간 내부와 외부의 유사도 차이를 기반으로 계산합니다. 높은 Score는 해당 구간이 텍스트와 밀접하게 관련된다는 것을 의미합니다.
즉, 기존의 Temporal Modeling 없이 Feature에 대한 계산을 하는 블록 구조로 구현됩니다. Image Feature와 Text Feature만으로 구간을 추출 및 Scoring하며, 모델 구조가 간소화됩니다.
4️⃣ Comparing Method
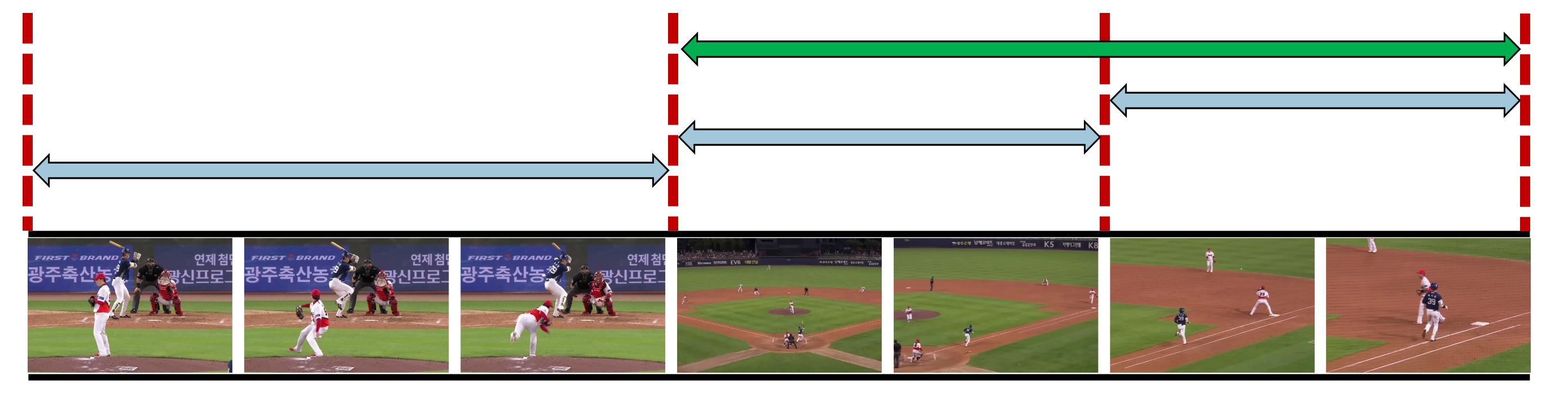
기존의 VTG 모델들은ㅍ방식을 이용합니다. 일정한 크기의 윈도우를 사용해 비디오를 일정 구간으로 나눈 후, 각 구간의 후보를 평가하여 가장 적합한 구간을 선택합니다. 다양한 구간 후보를 생성할 수 있어 효율적인 구간 탐색이 가능하지만 구간이 중복되거나 애매하게 잘리는 문제가 발생할 수 있습니다.
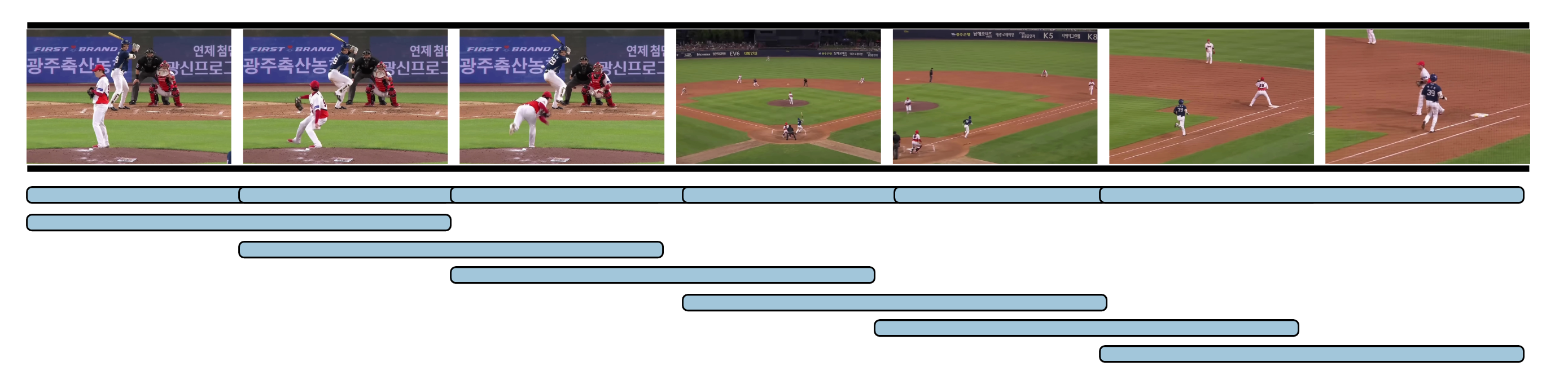
Making Proposal
❓사람이 하는 것처럼 직관적으로 구간을 나눌 수 없을까요?
본 모델은 쿼리와 프레임 유사도의 급격한 변화를 기반으로 구간을 추출합니다. 사람이 7개의 이미지를 직접 나눠보면 프레임의 급격한 변화를 이용하게 됩니다. 이 점에 주목하여 쿼리와 프레임의 유사도 변화를 이용합니다.
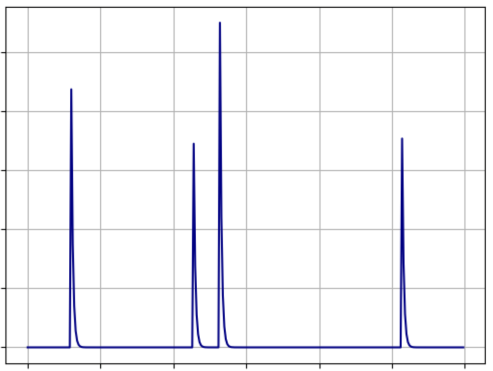
각 프레임의 유사도에서 급격한 상승과 하강이 발생하는 구간을 추출하여, 그 구간을 시작점과 끝점으로 설정합니다. 사람처럼 변화가 뚜렷한 구간을 기준으로 직관적인 구간을 추출할 수 있습니다.
구간 추출의 정확도를 높이기 위해 해당 방법을 적용합니다.
- Gaussian Smoothing : 프레임별 유사도 곡선에 적용해서 노이즈를 완화
- 1st, 2nd Gradient : 프레임별 유사도의 급상승이나 급하강 구간을 찾아내는 데 사용
- Rising/Falling Threshold : 특정 변화(급상승/급하강)가 실제로 중요한지 여부를 판단
- Weighted Sum : 급상승/급하강 구간에서 점수를 누적할 때, 변화의 중요도를 반영한 가중치 합산을 적용
Scoring Proposal
구간 후보가 시작점과 끝점으로 설정된 후,구간 내의 프레임 유사도 평균과 구간 외의 프레임 유사도 평균의 차이를 통해 Scoring이 이루어집니다.
(21, 131, 2305.736129760742), (21, 117, 2302.8108825683594), (41, 113, 2116.8413162231445) ... 출력: (21, 131) frame Ground Truth: (19, 132) frame
그중에서 가장 높은 점수를 얻은 구간을 최적 구간으로 선택합니다. 예를 들어, 구간 후보가 21프레임부터 131 프레임까지라면, 이 구간이 가장 높은 점수를 가져 출력값으로 선택됩니다.
정리하자면 기존 Sliding Window 방식을 보완하기 위해 프레임별로 텍스트와의 유사도 변화를 기반으로 구간을 추출합니다. 급격한 유사도 상승과 하강 구간을 기준으로 구간 후보를 생성하고, 구간 내외 유사도 점수 차이를 비교하여 최적 구간을 선정합니다.
기존 VTG 모델 제안하는 VTG 모델
시간적 정보 활용 Temporal Modeling을 통해 직접 학습 유사도 증감을 통해 간접적으로 반영
비디오 특징 추출 Video Embedding 활용 Image Feature로 대체
효율성 계산 비용이 높음 경량화된 구조로 효율성 증가
구간 생성 방식 Sliding Window 유사도 변화량을 기반으로 직관적으로 생성
Training 필요 여부 추가 학습 필수 Training-Free
5️⃣ Experiments
기본 모델 - TFVTG
- 논문: Training-free Video Temporal Grounding using Large-scale Pretrained Models (2024.08.29)
본 논문에서는 LLM (OpenAi API)+ VLM (Pretrained BLIP2)을 결합하여 텍스트 쿼리를 여러 개로 쪼개어 다양한 쿼리들에 대해 구간을 추출하는 방식을 제시합니다. 이 방식은 OpenAI API를 활용하여 텍스트 쿼리의 응답을 구간으로 매핑하는데 초점을 맞추고 있습니다. 기존 모델은 VLM과 LLM을 사용하여 동영상과 텍스트 특징을 추출하는데, LLM의 프롬프트 엔지니어링에 많은 자원이 소모된다는 단점이 있습니다. 본 실험에서는 VLM만을 사용하여 성능을 비교합니다.
Our Model - Using Pretrained Model + Our Segment Method
uform3-image-text-english 모델은 소형(multimodal AI) 모델로 이미지와 텍스트 간의 Multimodal Embedding이 가능하여 두 가지 데이터를 기반으로 유사도 측정을 수행합니다. 모델의 크기와 성능을 비교하기 위해 Small과 Large 모델을 모두 사용하여 실험을 진행합니다.
Model Name Parameter Architecture
uform3-image-text-english-small 79M 4 layer BERT, ViT-S/16
uform3-image-text-english-large 365M 12 layer BERT, ViT-L/14
TFVTG 188M BLIP-2 Q-Former
6️⃣ Results
Experiment 1 : LLM 없이 단일 쿼리에 대한 VLM 성능 평가
테스트 세트 : VidSTG (Video-based Spatio-Temporal Grounding) 평가지표 : MIoU (Mean Intersection over Union)
실험1에서는 Large Language Model(LLM)을 사용하지 않고, 단일 쿼리에 대한 Vision-Language Model(VLM)의 성능을 평가하였습니다.
MIoU Ratio of IoU=0 GPU Usage
TFVTG’s VLM BLIP-2 24.52 31.8% 28216
Uform3-Small based 33.70 6.6% 718
Uform3-Large based 34.24 8.2% 2208
- 성능 확인
우리의 방법이 MIoU 기준으로 기존 방법보다 훨씬 우수한 성능을 보입니다. IoU=0인 비율이 현저히 낮아, 예측 구간이 Ground Truth와 유사한 구간에서 생성됨을 확인할 수 있습니다.
- Small 모델과 Large 모델 성능이 비슷한 이유
정확한 수치 기반 예측보다는 증감 패턴을 활용한 구간 생성 방식 덕분에, 성능이 큰 폭으로 떨어지지 않았으며 튜닝을 통해 유사한 성능을 얻은 것으로 보입니다.
- GPU 사용량 차이
GPU 사용량의 차이는 비디오 임베딩과 이미지 임베딩 구조적 차이에서 기인합니다. 비디오 임베딩은 시간적 정보를 처리해야 하므로 연산량이 크며, 이에 따라 GPU 메모리 사용량이 급증합니다.
Experiment 2 : VLM으로 추출된 Feature를 활용한 구간 생성 방안 비교
테스트 세트 : Feature Extracted ActivityNet (3Hz로 Feature 추출)
실험2에서는 Vision-Language Model(VLM)에서 추출된 Feature를 활용하여 구간을 생성하는 방법을 비교하였습니다. 특히, 3FPS로 Feature를 추출했을 때의 성능과 그 한계를 분석했습니다.
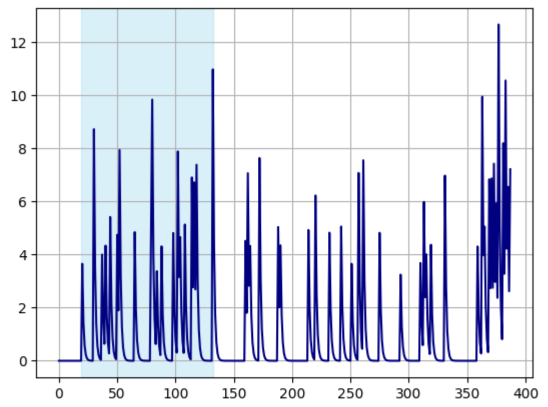
- 3FPS 환경에서의 한계
초당 3프레임으로 Feature를 받을 경우, 유사도의 변화를 관찰하기 어려운 문제가 발생합니다. 유사도의 증감 패턴을 포착하는 것이 어려워지며, 이에 따라 모델의 성능이 급격히 저하됩니다. 실제로 생성된 그래프를 보면, 프레임 수가 적을수록 유사도 증감에 대한 정보 손실이 명확하게 드러납니다.
7️⃣ Conclusion
기존의 VTG 방식을 수정하여 직관적이고 효율적인 방안을 고안하였으며, Training Free 방식으로도 이미지 차원을 활용해 비디오를 이해하면서 VLM보다 높은 성능을 달성했습니다. 이러한 방식은 Image Encoder의 성능에 대해 상대적으로 관대하며, 효율성을 유지하면서도 LLM 없이 단일 쿼리(Single Query)에 대해 성능을 확보할 수 있음을 확인했습니다. 현재 방식은 입력 텍스트 쿼리를 그대로 모델에 입력하는 방식이 비효율적일 가능성을 시사하며, 이를 대체할 더 효율적인 방안에 대한 연구가 필요합니다. 또한, Image와 Text Encoder에 대한 높은 의존성을 완화할 수 있는 방법을 고려해야 합니다. Hyperparameter Tuning을 통해 어느 정도 강건성을 확보할 수 있었지만, 이를 넘어서는 새로운 접근 방안이나 개선 방법을 모색해야 할 필요가 있습니다.