
1 Motivation
시험이 코앞인데 아직 강의자료를 펼쳐보지도 못했다면 어떤 기분이 들까요? 대학생 김호재 씨(27세)는 시험 시작 2시간 전, 벼락치기를 위해 강의자료를 펼쳤습니다. 문제는 방대한 자료를 시간 내에 모두 검토할 수 없다는 것입니다. 어디서부터 시작해야 할지, 무엇이 중요한지 판단할 여유조차 없는 상황에서 그는 선택의 기로에 섰습니다. 이때 김호재 씨의 머릿속에 AI 요약 모델이 단비와도 같은 도구로 떠오릅니다. 그러나 문제는 이 요약본의 신뢰성입니다. AI가 뽑아낸 내용이 정말 시험에 나올 핵심인지, 혹은 중요한 부분을 놓치진 않았는지 빠르게 검토하지 않으면 불안감이 밀려옵니다. 시간은 계속 흐르고, 자료는 여전히 산더미처럼 쌓여 있습니다. 이런 상황에서 단순히 요약된 내용을 받아보는 것만으로는 충분하지 않습니다. 요약본이 원본과 얼마나 일치하는지, 요약이 정말로 자료의 본질을 담아냈는지를 확인하며 학습의 효율을 높일 수 있는 시스템이 필요합니다.
기존 AI 요약 서비스는 어떨까?
요새 녹음 파일을 텍스트로 변환해주고, 이를 요약해주는 AI 어플리케이션들이 나와 많은 사람들이 유용하게 사용하고 있습니다. 대학생들 사이에서는 주로 강의 내용을 녹음하고, 녹음본을 텍스트로 변환해 강의 내용을 대본으로 만들어 공부하고 있는데요. 이 때 흔히 사용하는 서비스들은 다글로와 클로바 노트입니다.

두 AI 음성 요약 서비스 모두, 음성 기록을 텍스트로 전환한 내용을 왼쪽에 보이고, 오른쪽에는 해당 대본에 대한 요약 내용을 보여주고 있습니다.


Daglo와 클로바 노트는 요약을 제공하기는 해도 그 요약 부분이 대략적으로 스크립트의 어디서부터 어디까지정도에 해당하는 내용인지 알려주는 역할만을 하고 있는데요. 저희는 이런 서비스들이 어떻게 이런 부분들을 사용자에게 알려줄 수 있는지 궁금했습니다. 대학생들이 사실 이런 식으로 강의 요약 서비스로 사용하지만, 사실 이 두 어플리케이션의 경우 그 시작은 AI 회의록 작성 도구입니다. 강의 요약이라는 목적 자체는 기존 어플리케이션의 목적과는 사뭇 다르다는 것이죠. 교육과 관련된 어플리케이션은 아닙니다. 강의 음성 파일을 넣으면 텍스트화 하고 그걸 정리하는 것까지는 잘하지만, 유저와 Interactive하게 상호작용을 할 수 있지는 않습니다. 저희가 벼락치기에 유용한 툴을 만든다고 했죠. 따라서, 사용자들이 더 똑똑하게 학습할 수 있도록 요약본과 대본의 연관성과 어느 부분을 집중해서 공부하면 좋을지를 사용자에게 직접 보여주면 더욱 더 유저 친화적으로 사용자들이 교육 보조 도구로서 사용 가능하다고 생각했습니다.
2 What is XAI?
사용자에게 인공지능이 어째서 이런 판단을 하고 출력하게 되었는지는 어떻게 알려주면 좋을까요? 인공지능의 사고 과정을 알려주면 좋겠죠. 인공지능의 판단 과정을 설명하기 위해서는 먼저 몇 가지 중요한 개념을 이해해야 합니다.
2.1 알고리즘
알고리즘은 기계가 특정 목표를 달성하기 위해 따르는 규칙의 집합입니다. 이는 입력에서 출력에 이르기까지 필요한 모든 단계를 정의하는 레시피라고 할 수 있습니다. 요리에 비유하자면, 재료를 '입력'으로 보고, 요리된 음식을 '출력'으로 비유할 수 있습니다. 이 과정에서 재료를 다듬고 조리하는 각 단계는 바로 ‘알고리즘’인 셈이죠.
2.2 기계 학습(Machine Learning)과 블랙박스 모델(Black Box Model)
기계 학습은 데이터를 활용해 컴퓨터가 스스로 학습하고 예측할 수 있도록 하는 기술입니다. 기존의 명시적인 프로그래밍과는 달리, 컴퓨터에 데이터만 제공하고 그 데이터로부터 규칙을 학습하는 방식입니다. 이를 '간접 프로그래밍'이라고도 합니다.
graph LR
Data --> |Model| Prediction이제 데이터를 보고, 모델이 알고리즘에 의해 Prediction을 내놓을 것입니다. 모델의 알고리즘을 명확히 보여줄 수 있다면, 이제 인공지능의 사고 과정을 볼 수 있겠죠. 기계 학습 모델은 데이터를 입력받아 예측 결과를 출력합니다. 그러나 딥러닝처럼 복잡한 기술에서는 '왜 이런 결과가 나왔는지' 설명하기가 어렵습니다. 딥러닝 모델은 내부 작동 원리가 명확히 드러나지 않는 블랙박스 모델로 알려져 있습니다. 특히 인공 신경망(Neural Network) 같은 모델은 선형성을 넘어 비선형성도 도입하며 모델이 점점 더 복잡해졌죠. 매개변수와 구조를 들여다보더라도 그 작동 방식을 바로 이해하기 어려운 이유가 바로 여기 있습니다.
2.3 XAI 기술들
저희가 프로젝트에서 사용한 XAI 기술은 다음과 같습니다.
UMAP
우리가 직면하는 보통의 데이터(Raw Data)는 고차원 데이터입니다. 고차원 데이터들은 우리가 실제로 보는 2D나 3D보다도 더 높은 차원에 있어서 다루기가 어렵죠. 이를 보다 쉽게 다루기 위해 차원축소(Dimensionality Reduction)가 사용됩니다.
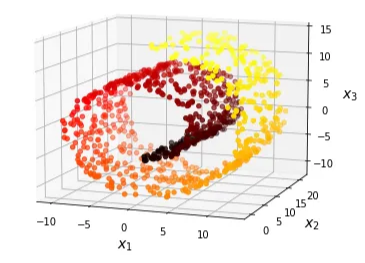
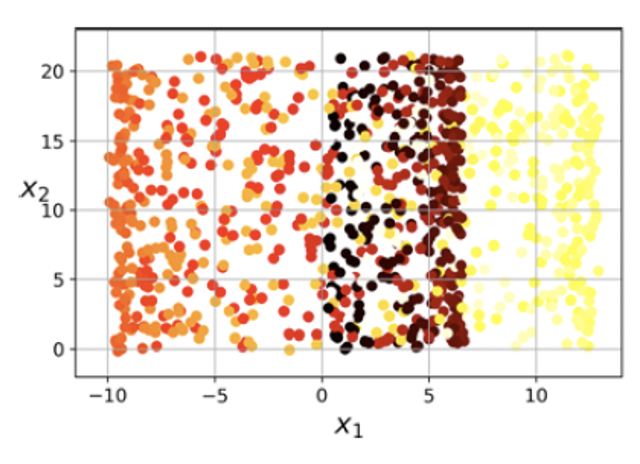
차원 축소는 고차원 데이터를 저차원으로 변환하여 중요한 정보를 유지하면서도 데이터의 복잡성을 줄이는 과정을 의미합니다. 이 과정을 통해 데이터는 더욱 간소화되고, 분석과 시각화에 용이해집니다. UMAP(Unifold Manifest Approximation and Projection)은 비교적 최근에 등장한 비선형적인 차원 축소 기법으로, 데이터의 지역적(Local) 구조를 보존하면서도 전역적인(Global) 구조 역시 더 잘 보존한다는 특징이 있습니다. 이는 고차원 데이터의 전체적인 구조를 잘 나타내며, 데이터의 관계를 더욱 명확히 이해하는 데 도움을 제공하죠.
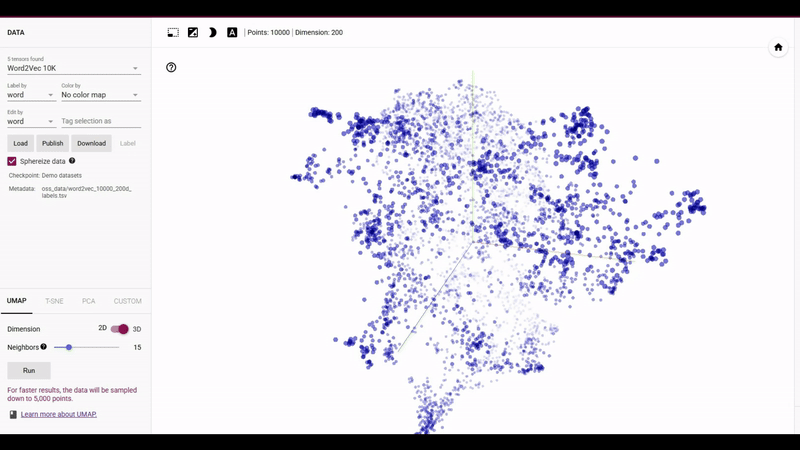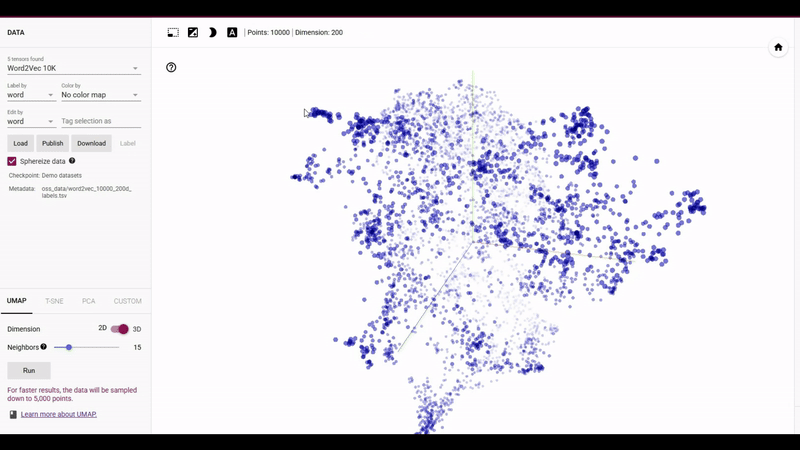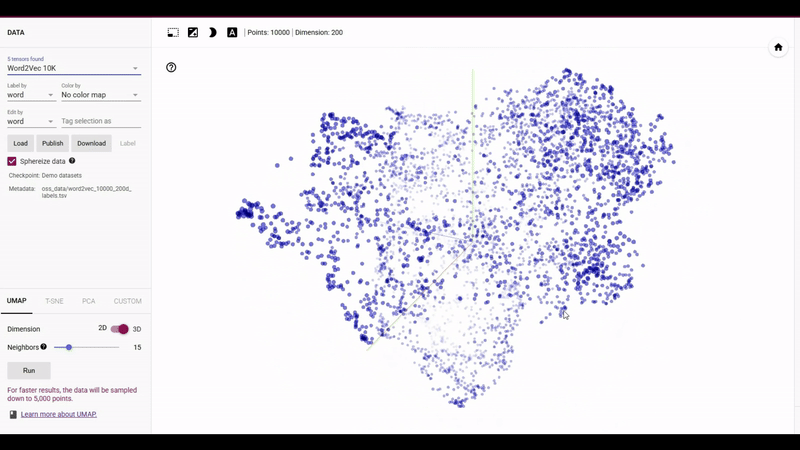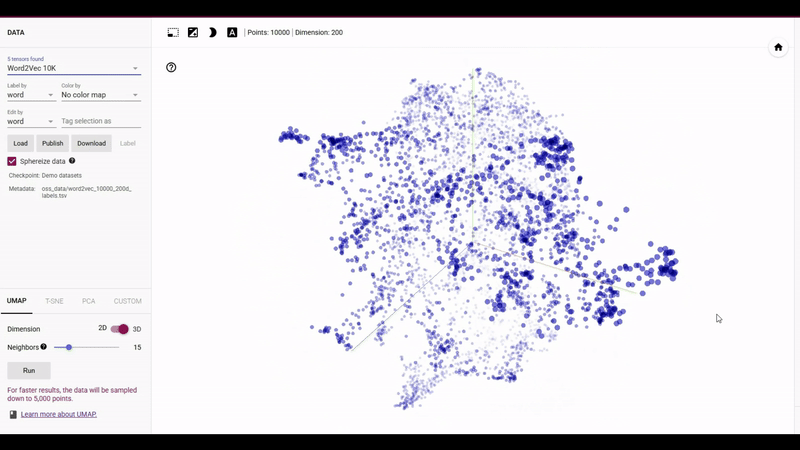
뿐만 아니라 UMAP은 그래프 기반 접근법과 탄탄한 수학적 이론에 기초하고 있습니다. UMAP은 고차원 데이터의 근접성 정보를 k-NN을 기반으로 그래프로 표현한 후, 이 그래프를 저차원 공간에서 최적화하는 방식으로 작동합니다. 이 과정은 리만 기하학(Riemannian Geometry)과 고급 위상수학(Topological DataAnalysis)에 기반하였기에, 데이터의 구조적 특성을 잘 보존하면서 차원을 축소합니다. 그리고 이는 흔히 차원축소에서 사용하는 t-SNE보다 계산 속도가 빠르며, 선형과 비선형 데이터 모두에서 뛰어난 성능을 보입니다. 특히, 대규모 데이터셋에서 역시 효율적으로 작동하여 현재까지 가장 우수한 차원 축소 알고리즘 중 하나로 사용되고 있습니다.
Gradients
Gradient는 모델의 출력 값이 입력 값의 작은 변화에 얼마나 민감하게 반응하는지를 측정하는 지표입니다. 예를 들어, 입력 단어 가 모델 출력 에 얼마나 영향을 미쳤는지를 분석하려면 출력 를 해당 입력 에 대해 미분합니다:
이 값이 크다면, 해당 입력 는 모델 출력에 큰 영향을 미친 것이고, 반대로 작다면 상대적으로 영향을 덜 미쳤다는 뜻입니다. 요약 모델은 입력된 텍스트를 요약하는 과정에서 여러 단어(Segment)와 문장들의 중요도를 학습합니다. 하지만 모델이 왜 특정 문장이나 단어를 더 중요하게 여겼는지는 명확하지 않습니다. 이를 알아보기 위해 Gradients를 이용해 단어의 중요도를 시각화하고 해석 가능성을 강화할 수 있습니다. 이해를 돕기 위해 예시를 한 번 들어보겠습니다.
- 입력 텍스트: "Explainable AI는 인공지능 모델의 신뢰성과 투명성을 높이는 데 핵심적인 역할을 합니다. XAI 기술은 의료, 금융, 법률 등 다양한 분야에서 활용되며, 사용자가 모델의 예측을 이해하고 신뢰할 수 있도록 돕습니다. 하지만 XAI 구현은 계산 비용이 높고, 복잡한 모델에서 설명력을 확보하는 데 어려움이 따릅니다."
- 요약 결과: “XAI는 모델의 신뢰성과 투명성을 높이며 다양한 분야에서 활용된다.”
만약 어떤 모델이 입력 텍스트를 넣었을 때 다음과 같은 요약 결과가 나왔다고 가정해봅시다. 이제 여기서 출력 요약 결과에 대해 입력 텍스트 각 단위(단어나 구문 등)의 Gradient를 계산합니다. 이때 모델의 Backpropagation을 활용해 각 입력 가 출력 에 미친 영향을 평가합니다.
입력 단어 Gradient 값 중요도(%)
"Explainable AI는" 0.72 22.0%
"인공지능 모델의" 0.35 10.7%
"신뢰성과" 0.50 15.3%
"투명성을" 0.40 12.2%
"다양한 분야에서" 0.60 18.4%
"활용되며" 0.55 16.8%
다음과 같은 정보를 바탕으로 우리는 왜 모델이 “XAI는 모델의 신뢰성과 투명성을 높이며 다양한 분야에서 활용된다.”이라는 요약 결과를 내뱉었는지 알 수 있습니다. 비록 예시는 간단하지만 이를 활용한다면 핵심 단어나 덜 중요한 단어를 파악하고 이를 중심으로 요약본을 바라볼 수 있겠죠.
2.4 Visual Component
Something over the Rainbow?
그럼 우린 어떻게 결과를 효과적으로 시각화할 수 있을까요? 대부분의 사람들은 시각화를 위해 흔히 아는 색상 체계인 Rainbow Colormaps, 즉 무지개를 생각하고는 합니다.

그러나 무지개 색은 변화가 불균일하다는 단점이 있습니다. 위의 사진을 보시면 다른 색에 비해 노란색과 하늘색이 더 빛나 보이는 걸 알 수 있습니다. 밝기가 훨씬 밝죠. 색의 밝기, 휘도(Luminance)는 실제로 데이터를 구분하는데 사용되는 값이기 때문에 무지개 색의 이러한 특징은 사용자에게 혼란을 줄 수 있습니다. 또한, 무지개의 경우 빨간색, 주황색, 노란색, 초록색, 하늘색, 파란색, 보라색의 순서를 가지고 있습니다. 다들 자연스레 생각하는 순서가 존재한다는 뜻이죠. 색상의 불균일한 변화와 순환 구조로 이루어진 색상 체계로 인해 무지개 색은 우리가 효과적으로 데이터를 시각화 하기에는 맞지 않는 요소라고 할 수 있습니다.
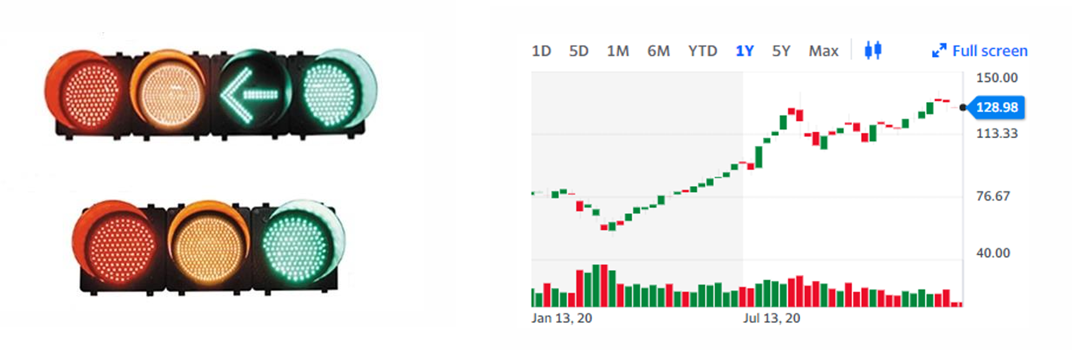
빨간색, 초록색의 색깔은 잘 구분되기 때문에 함께 사용되는 경우가 많습니다. 하지만 그렇기 때문에 더욱이 이러한 색들은 편향을 일으킬 수도 있죠. 특히 주식의 경우, 국내 주식과 해외 주식의 주가 상승의 색상이 다릅니다. 외국은 상승이 초록색, 하락이 빨간색인 반면에 국내는 상승 빨간색, 하락 파란색이 디폴트죠. 모두가 사용하는 색상임에도 반해 오히려 모두가 사용하기 때문에 문화권마다 다르게 이를 해석할 수도 있다는 것을 명심해야 합니다.
Hue, Luminance, Saturation
자, 그럼 여기서 그럼 본디 시각화를 할 때 중요하게 생각해야 하는 세 가지 용어를 한 번 짚고 넘어가 봅시다. 먼저 색상(Hue)란 색의 종류를 나타내는 것으로 범주형 데이터를 표현할 때 사용합니다. 시각화를 할 때 주로 사용되는 색상 체계는 Category10 또는 Tableau10입니다.

위 색상은 어느 하나 구분하기 어려운 색상이 없으며, 밝기가 튀는 색상이 없습니다. 특히 Tableau10의 경우, 시각 장애가 있는 사람도 잘 구분하기 쉬운 색상으로만 구성되어 있어 시각화하는데 주로 Tableau10을 사용하곤 합니다. 다음은 휘도(Luminance)와 채도(Saturation)입니다. 각각 색의 밝기와 진하기를 나타내는데, 이는 정량적 데이터를 표현하는데 사용됩니다. 어떤 Continuous한 값을 나타내는데는 한 가지 값의 밝기를 조정하면 편하겠죠?

이러한 색상 요소들을 목적에 맞게 사용해 저희는 정보를 사용자에게 보다 더 직관적이고 명료한 형태로 제공할 수 있습니다.
3 Process of project
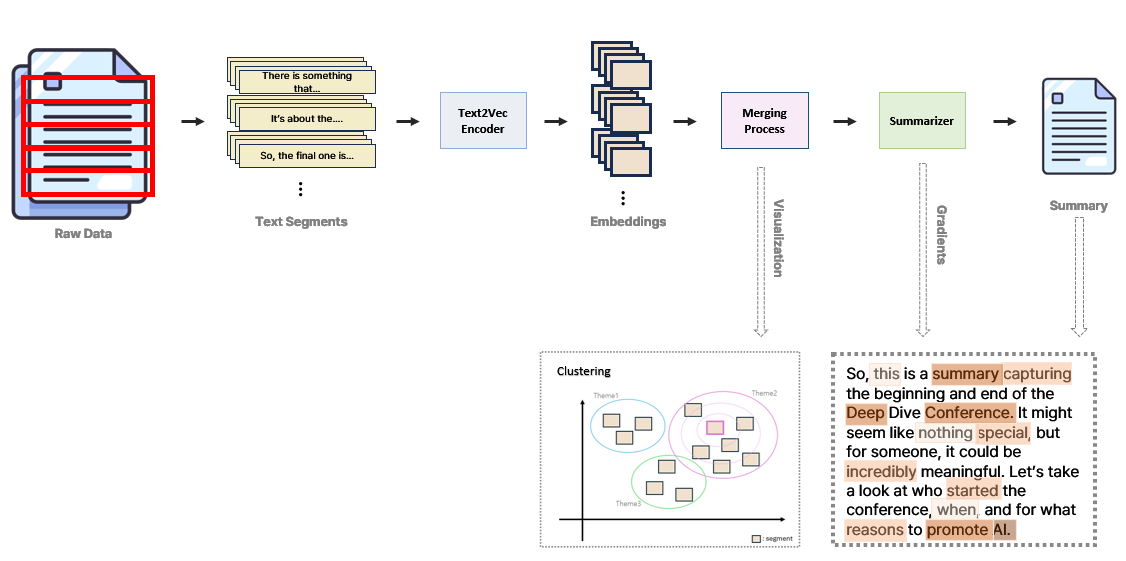
전체적인 프로세스는 다음과 같습니다. 저희가 실험을 할 때 중심적으로 사용한 요약 모델은 “huggingface/facebook/bart-large-cnn”이며 실제 데모에서는 여러 요약 모델을 사용할 수 있습니다. 프로세스는 크게 Clustering, Summarization, Resummarization으로 나뉩니다. 프로세스별로 어떤 과정이 이루어지고 있는지 설명해보겠습니다.
3.1 Clustering & Visualization
요약 모델의 한계
현재 Huggingface에서 사용 가능한 요약 모델은 입력 토큰 수에 1,024 토큰이라는 한계가 존재합니다. 이 한계를 초과할 경우, 모델이 정상적으로 작동하지 않거나 뒷부분이 잘려서 들어가는 문제가 발생합니다. 특히 긴 텍스트 데이터를 다룰 때는 이러한 제약이 큰 문제가 될 수 있습니다.
해결책: 클러스터링
강의 대본과 같은 데이터에서는, 주제에서 벗어난 이야기가 섞이거나, 초반에 언급된 주제가 나중에 다시 등장하는 경우가 많습니다. 이를 효과적으로 정리하여 입력 토큰의 수를 줄이고, 유저에게 주제별로 구조화된 내용을 제공하기 위해 클러스터링을 활용했습니다. 먼저 Raw Data를 문장별 Segment로 나눈 다음, 이를 Text2Vec Encoder를 이용해 벡터화(Embedding)합니다. Embedding된 데이터에 K-means Clustering을 적용하여 주제별 그룹으로 나눈 후 이를 시각화하면 각 그룹의 분포를 한눈에 파악할 수 있습니다.
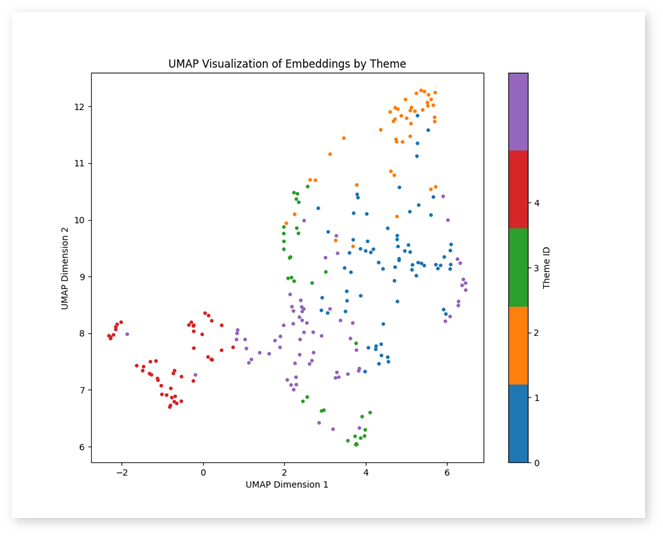
시각화는 단순히 데이터를 보기 좋게 만드는 것을 넘어 클러스터링된 데이터의 구조와 패턴을 이해하는데 필수적인 역할을 합니다. 사용자는 각 클러스터가 어떤 주제에 해당하는지, 어떤 관계를 가지고 있는지 파악할 수 있으며 클러스터 내 데이터 포인트들이 어떻게 분포되어 있는지 직관적으로 알 수 있어 특정 클러스터(주제)의 중요도를 파악할 수 있습니다.
3.2 Visualize Importance
중요도 계산
그렇게 그룹으로 묶인 각 Embeddings들을 Summarizer를 이용해서 최종적인 요약본을 보여주게 됩니다. 그런데 여기서 중요한 것이 하나 남았죠. 바로, 해당 요약 문장들이 ‘어떤 단어’에 초점을 맞췄는지 보여주는 것입니다. 모델이 문장의 어떤 ‘단어’이나 부분을 더 주의 깊게 보고 있는지 알 수 있다면, 모델의 판단 과정을 더 잘 이해할 수 있을겁니다. Gradient를 기반으로, 실제 중요도 점수로 변환하는 과정에 대해 설명해보겠습니다.
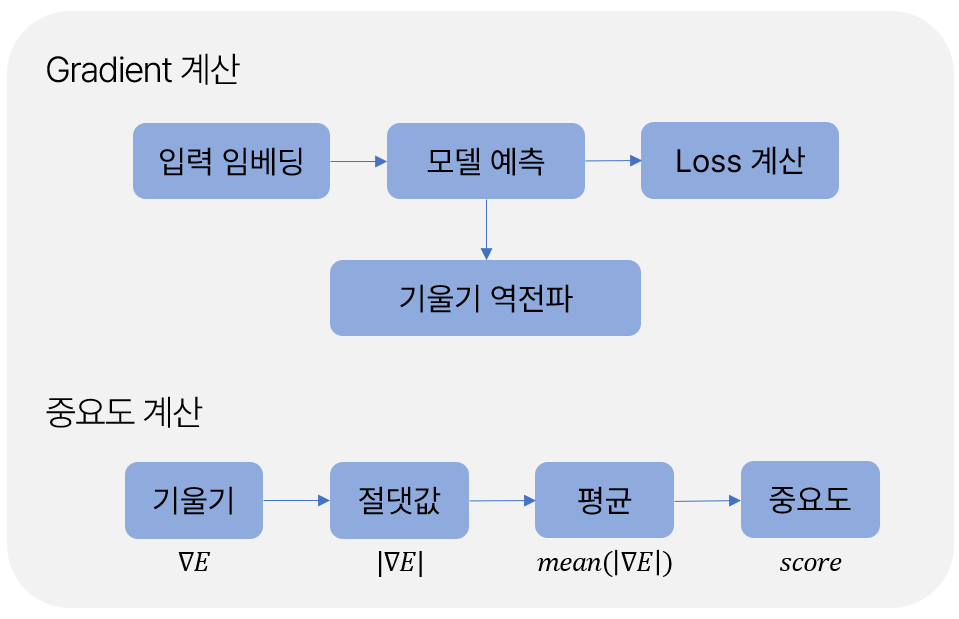
우선 Gradient를 뽑아내서 이의 절댓값을 구해줍니다. 우리가 관심있는 것은 영향력의 방향이 아닌, 이게 얼마나 큰 영향을 미치는지를 보고 싶은 것이니까요! 그 다음, Gradient의 절댓값의 평균을 계산하여 각 단어당 하나의 대표값을 얻습니다. 이 과정을 거치면 각 단어마다 하나의 중요도 점수가 할당되겠죠.
중요도 시각화

숫자로 된 점수는 사람이 직관적으로 이해하기 쉽지 않아요. 그래서 우리는 이를 시각화해줄겁니다. 사용자에게 직관적으로 단어당 중요도 점수를 알려주기 위해 이를 정규화 시켜주고, 마치 히트맵처럼 색상을 통해 중요도를 알려주는 것이죠. 앞서 Color Scheme 때 말했다시피, 데이터를 표현할 때 색을 사용하기도 합니다. 지금 현재 Gradient 쪽은 중요도 점수를 계산했으니 즉, 정량적(Quantitative) 데이터를 다루고 있죠. 각 토큰의 중요도는 연속적인 수치 값으로, 이를 가장 효과적으로 표현하기 위해 휘도(Luminance)를 주요 시각적 채널로 선택했습니다.

밝기의 변화는 데이터의 크기 변화를 직관적으로 전달하죠. 자연스럽게 그 연속적임과 높고 낮음이 잘 드러납니다. 중요도가 높은 단어는 진한 색상으로, 덜 중요한 단어는 연한 색상으로 표시해 모델이 어떤 단어에 주목해서 판단을 내렸는지 한 눈에 알 수 있게 해줍니다.


3.3 Resummarization
마지막으로 재요약(Resummarization) 과정에 대해 살펴보겠습니다. 요약된 결과를 보며 우리는 특정 문장이나 주제를 중심으로 한 요약을 한 번 더 보고 싶다고 느낄 수 있습니다. 이럴 때 사용하는 것이 바로 Resummarization입니다.
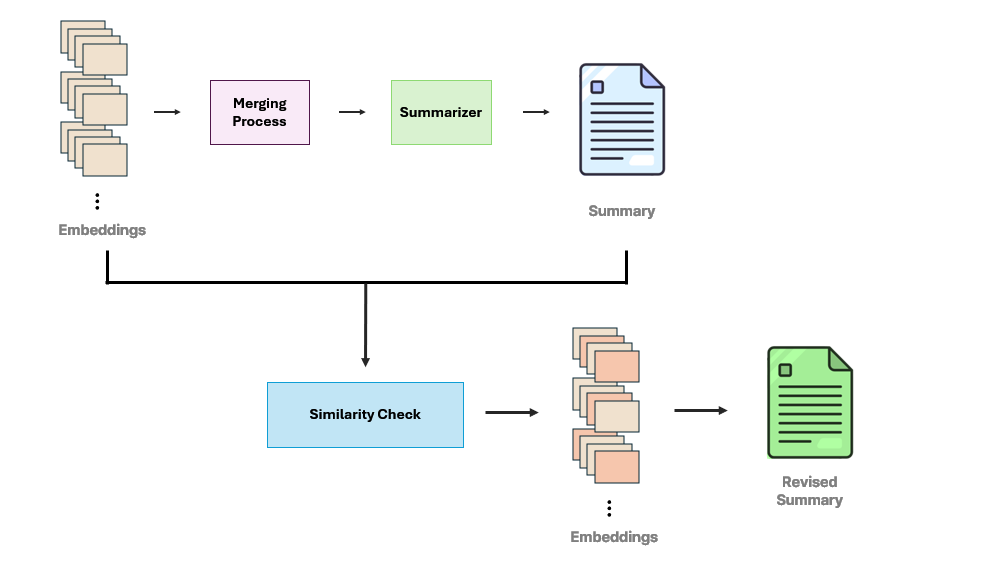
먼저 유저가 Summary에서 원하는 문장을 클릭하면, 이미 요약할 때 생성된 Embeddings에서 Cosine Similarity를 계산해 선택된 문장과 유사한 문장들을 뽑아내 이를 이용해 재요약합니다. 이 재요약 서비스가 필요한 이유는 무엇일까요? 먼저 요약 결과에서 클러스터링 시각화를 본 유저는 특정 주제나 문제를 중심으로 요약본을 보고 싶을 수 있습니다. 유저가 관심 있는 부분을 중심으로 요약을 재구성함으로써 ‘개인화된’ 요약 결과를 제공할 수 있습니다.
4 제작한 Application
4.1 어플리케이션 구현 소개
결과적으로 만들어진 Application은 다음과 같습니다. 저희는 Streamlit을 통해서 프론트를 제작하고, Runpod을 통해 Flask로 제작한 백엔드 파트를 배포했습니다.

왼쪽에 있는 사이드바를 통해 요약할 텍스트와 요약 모델을 선택할 수 있습니다. 요약하기 버튼을 누르면 스크린에 요약 결과와 원본 텍스트가 보여집니다. 그럼 요약이 잘 되었는지 어떻게 알 수 있을까요? 왼쪽 사이드바를 보시면 로그 스코어와 Bert 점수를 통해서 어느 정도로 요약을 잘 했는지 보여줍니다. 그리고 요약 결과에서 특정 문장을 누른다면 원본 텍스트에 관련 있는 부분들이 하이라이트 되어 중요도를 표시하게 됩니다. 이를 통해 요약 결과와 관련 있는 원문을 더 효과적으로 볼 수 있습니다.


마지막으로 특정 주제에 대해 re-summarization을 진행할 수 있습니다. 먼저 요약 결과를 그래프를 통해 어떻게 묶여 있는지 확인할 수 있으며, 요약 문장을 클릭하면 해당 문장과 관련 있는 문장들을 모아 재요약본을 보여줍니다. 아래 영상을 통해 해당 과정을 확인하실 수 있습니다.
4.2 시현 Video
최종 데모의 모습. 시간이 조금 더 오래 걸리나 해당 부분은 편의를 위해 배속 처리 하였습니다.