
1. Intro


최근 몇 년간 프로그래밍 능력은 여러 분야에서 중요한 역량으로 자리 잡았습니다. 특히, IT 업계에서는 코딩 테스트가 채용 과정의 필수적인 단계가 되며 알고리즘 문제 해결 능력을 평가하는 것이 보편적입니다. 따라서 많은 사람들이 알고리즘 문제를 해결하는 기술을 학습하기 위해 노력하고 있습니다. 이때, 대규모 언어 모델(LLM, Large Language Models)인 ChatGPT와 같은 AI 기술의 발전으로, 알고리즘 문제를 풀기 위한 도구로 활용하는 사례가 늘어나고 있습니다. LLM은 코드 생성, 알고리즘 설계, 디버깅 등을 빠르고 효율적으로 지원할 수 있지만, 그 성능은 사용자가 작성하는 프롬프트의 품질에 크게 의존합니다. 예를 들어, 명확하고 구체적인 프롬프트는 최적의 응답을 유도하는 반면, 모호하거나 불완전한 프롬프트는 부정확하거나 비효율적인 응답을 초래할 수 있습니다. 그래서 저희는 이러한 문제를 해결하고자 했습니다. 알고리즘 구현과 관련하여 사용자가 작성한 프롬프트가 LLM 응답에 어느 정도 영향을 미치는지 분석하고, 이를 시각화하는 실용적인 인터페이스를 제공합니다. 이를 통해 사용자가 더 나은 프롬프트를 작성하고, 알고리즘을 효과적으로 학습할 수 있기를 기대합니다.

즉, 저희는 사용자가 더 효과적이고 정확한 프롬프트를 작성할 수 있는 Pro Prompter로 거듭나는 것을 목표로 삼았습니다.
이와 관련해서 재미있는 제목을 고민하던 중, 헤어지자고 너 누군데 밈을 떠올리게 되었습니다. 이 밈은 라이즈 팬이 트위터(X)에서 소희의 사진을 이용해 남긴 개그성 트윗에서 시작되었습니다. 이를 차용해서 사용자가 능력있는 프로 프롬프터가 되기를 바라는 마음을 가득 담아, 헤어지자고? 나 프로 프롬프턴데 라는 제목이 탄생했답니다.
Prototype
인터페이스의 제목은 Prompt Explainer로, 직관적으로 어떤 기능을 제공하는지 와닿을 수 있게 지었습니다. 다음으로 저희가 목표한 태스크에 맞추어 아래와 같이 prototype을 디자인해보았습니다.

기능에 따라 섹션을 크게 3가지로 나눴습니다.
[ Main Section ] 사용자가 LLM과 대화를 하는 구역입니다. 사용자는 자신이 입력한 프롬프트와 그에 대한 LLM의 응답을 확인하며, 프롬프트의 각 토큰이 응답에 미친 기여도를 시각적으로 확인할 수 있습니다.
[ Left Section ] ChatGPT와 같이 대화 기록을 축적하며, 이전 대화를 필요에 따라 찾아볼 수 있도록 하였습니다. 또 Main section의 알고리즘 버튼을 누르면, 사용자가 프롬프트 작성에 참고할 수 있도록 시스템 프롬프트를 제공하는 기능 또한 추가하였습니다.
[ Right Section ] 프롬프트 작성에 참고할 수 있도록, 시각화된 이미지로 각 알고리즘에 관련된 단어를 추천하는 기능을 넣어보았습니다.
2. Methodology
본격적인 인터페이스 제작에 앞서, 저희의 큰 주제라고 볼 수 있는 XAI에 대해 다뤄보겠습니다.
(1) XAI

기존의 많은 머신러닝 모델은 Black Box로 작동하며, 내부에서 어떤 과정을 거쳐 결과를 도출하는지 알 수 없다는 한계가 있었습니다. 특히, 딥러닝으로 기술이 발전하면서 모델 구조가 점점 더 복잡해짐에 따라 이러한 블랙박스 모델에 대한 의문과 우려가 커지고 있습니다. 이러한 한계를 극복하기 위해 등장한 개념이 바로 XAI(Explainable AI)입니다. XAI는 “설명 가능한 인공지능”이라는 의미로, 기계 학습 모델의 동작 원리를 명확히 이해하거나, 특정 결과가 도출된 이유를 설명하는 도구와 방법론을 제공합니다. 이를 통해 블랙박스 모델을 더 투명하고 해석 가능한 시스템으로 전환하는 것을 목표로 합니다. 또한 XAI는 단순히 모델의 투명성을 높이는 것을 넘어, 사용자와 AI 간의 신뢰를 쌓고 다양한 문제를 해결하는 데 기여합니다. 특히, Explainability는 다음과 같은 이유로 더욱 주목받고 있습니다.
(2) Goal
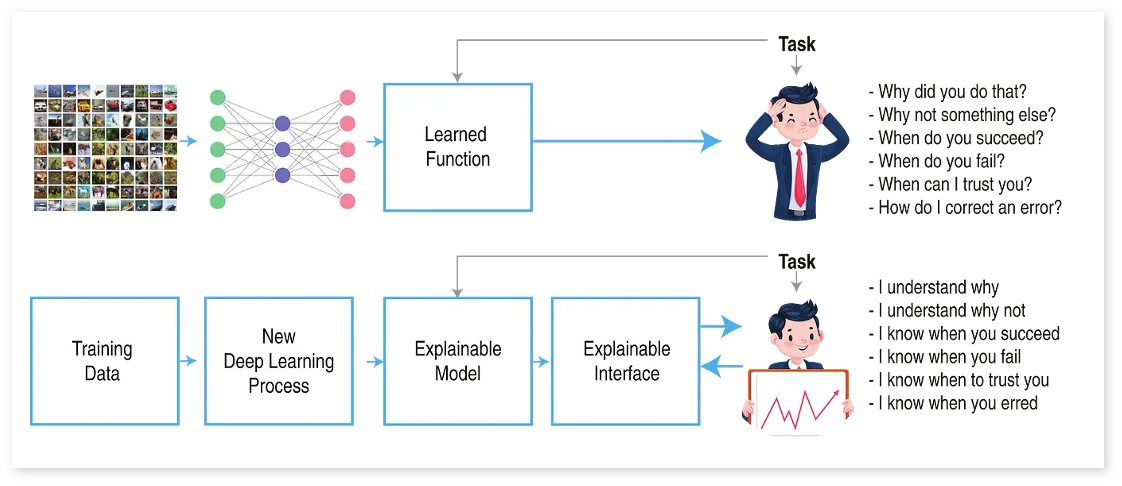
저희는 딥러닝 모델에 XAI를 적용하여, 사용자가 모델의 설명 가능성에 쉽게 접근할 수 있도록 하는 것을 목표로 합니다. 특히, 모델 사용자와 가장 가까운 단계에 위치한 Explainable Interface를 제작하는 데 중점을 두고 있습니다. 본격적으로 프로젝트를 소개하기에 앞서, 이러한 Explainable Interface를 제작하기 위해 기본적으로 알아야 할 몇 가지 핵심 요소를 살펴보고자 합니다. 좋은 시각화란 무엇인지, 사용자에게 인지적으로 부담을 주지 않으면서 효과적으로 정보를 전달하는 방법은 무엇인지, 그리고 XAI의 해석과 시각화를 보완하는 핵심 도구로서 차원 축소를 어떻게 활용할 수 있는지를 다뤄보겠습니다.
(3) Visualization
Visualization는 데이터를 그래프, 차트, 다이어그램 등의 이미지로 변환하는 전체 과정입니다. 사용자가 쉽게 이해하고 인사이트를 도출할 수 있게 도와주는 것이 목적입니다.
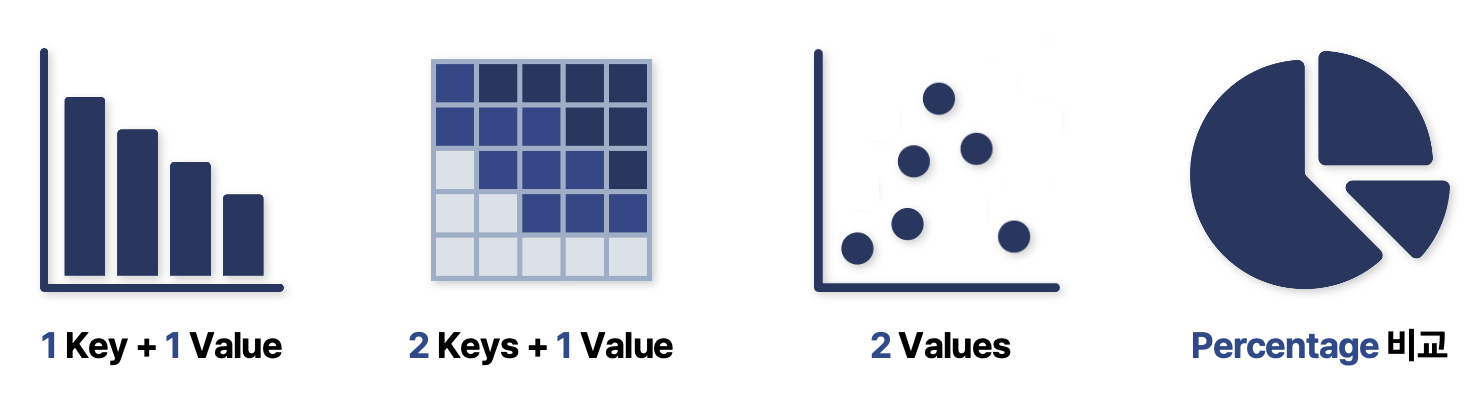
데이터를 어떻게 기술하고, 어떤 차트를 써야 할까요?
데이터의 특성을 고려하는 것이 가장 중요합니다. 연도별 아이폰 사용자 수를 표현하기에 좋은 시각화 방법은 무엇일까요? 연도라는 한가지 고유한 값에 사용자 수라는 한가지 매핑되는 값이 존재하므로, bar plot이 가장 적절할 것입니다. 그리고 bar plot이 이런 데이터의 모든 정보를 표현해주면서도, 중요한 정도와 시각적 두드러짐 정도가 매칭되는 효과적인 시각화 방식이라고 할 수 있습니다. 이처럼 Key (중복된 값이 없는 유일한 값) 그리고 Value (key에 대응되는 값) 같은 특성에 따라, 또 효과적으로 모든 정보를 제공할 수 있는지 Expressiveness와 Effective라는 원칙을 고려한다면 좋은 시각화가 될 수 있습니다.
Color Scheme
인지적으로 부담주지 않기 위해, 적절한 Color Scheme를 활용하는 것 또한 중요합니다. 범주형 데이터의 경우, 서로 명확히 구분되는 색상(hue)로 나타내야합니다. 또 정량적 데이터의 경우, 색상의 휘도와 채도를 조절한 시각화가 가장 효과적으로 표현됩니다.

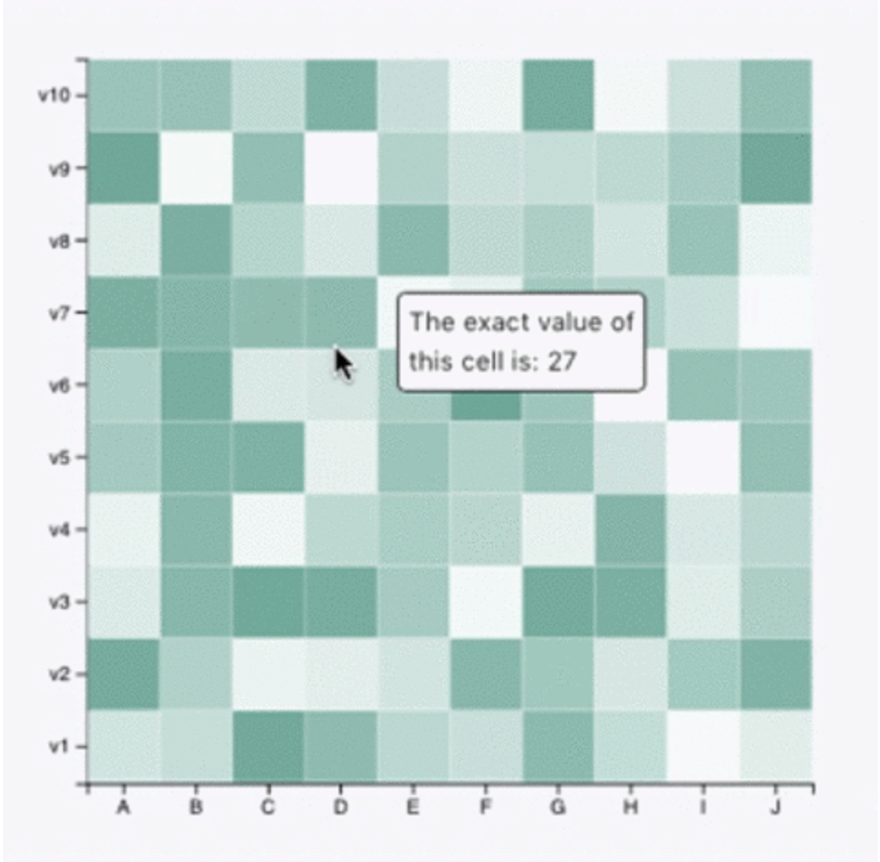
View Manipulation - Selection / Navigation
사용자 친화적인 인터페이스라면, View Manipulation을 통해 데이터를 더 잘 탐색하거나 특정 데이터, 트렌드, 또는 인사이트에 주목할 수 있도록 화면을 조작할 수 있도록 해야합니다. Selection에는 Hovering과 Brushing이 있는데요, Hovering은 아래 사진과 같이 특정 데이터포인트 위에 커서를 올리면 추가 정보를 표시하는 기능입니다. Brushing은 여러 데이터포인트를 동시에 선택 및 강조하는 조작방법입니다.
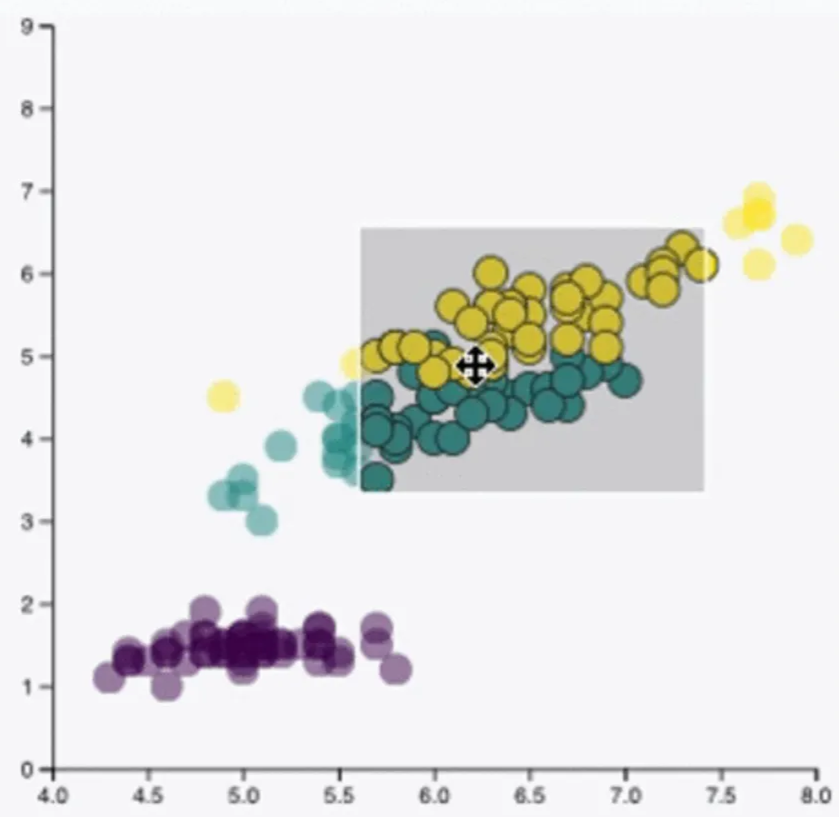
Navigation은 데이터 집합 간의 계층적인 이동으로 Zooming과 Panning이 있습니다. Zooming은 데이터를 확대/축소하여 세부 정보를 보거나 큰 그림을 확인하는 것이고, Panning은 화면을 이동하여 데이터의 다른 부분을 탐색하는 것을 의미합니다.
(4) Dimensionality Reduction - UMAP
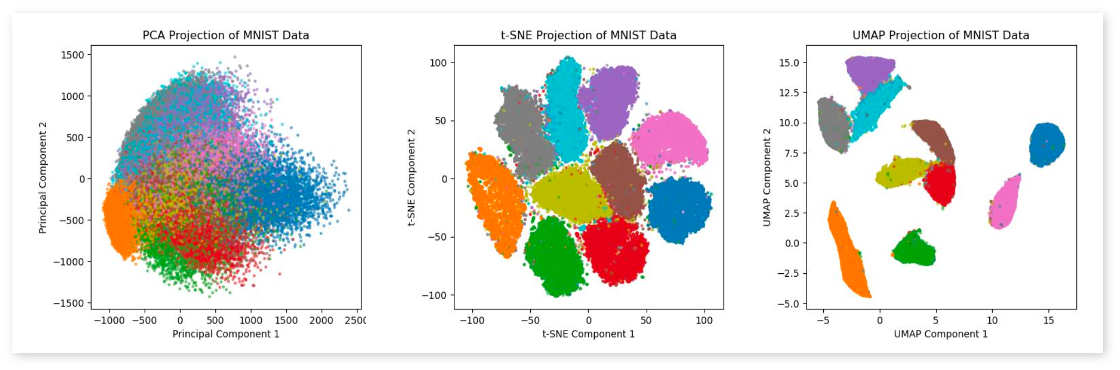
Prompt Explainer 에서는 각 알고리즘 문제 카테고리별 관련 단어를 scatter plot 형태로 제공합니다. 이를 위해 각 알고리즘 카테고리의 단어들을 정의하고, Word2Vec 모델을 사용하여 임베딩합니다. 각 단어를 벡터로 변환한 뒤 UMAP(Unified Manifold Approximation and Projection)을 통해 저차원으로 축소하여 시각화를 준비합니다. UMAP은 비교적 최근에 등장한 비선형 차원 축소 기법으로, t-SNE와 유사하게 데이터의 지역적 구조를 보존하면서도, 글로벌 구조도 더 잘 보존한다는 특징이 있습니다. 이는 고차원의 전체적인 데이터 구조를 더 정확히 나타내며, 데이터의 관계를 더욱 명확히 이해하는 데 도움을 제공합니다. 또다른 주요 장점은 그래프 기반 접근법과 탄탄한 수학적 이론에 기초한다는 점입니다. UMAP은 고차원 데이터의 근접성 정보를 k-NN을 기반으로 그래프로 표현한 후, 이 그래프를 저차원 공간에서 최적화하는 방식으로 작동합니다. 이 과정은 리만 기하학(Riemannian Geometry)과 고급 위상수학(Topological DataAnalysis)에 기반하였기에, 데이터의 구조적 특성을 잘 보존하면서도 차원을 축소합니다. 그리고 이는 t-SNE보다 계산 속도가 빠르며, 선형 및 비선형 데이터 모두에서 뛰어난 성능을 보입니다. 특히, 대규모 데이터셋에서도 효율적으로 작동하여 현재까지 가장 우수한 차원 축소 알고리즘 중 하나로 여겨집니다.
(5) XAI Methods
Shapley Values는 XAI에서 자주 사용되는 방법 중 하나로, 모델의 출력 결과를 해석하고 설명하는 데 매우 강력한 도구로 인정받고 있습니다. 특히 특징 중요도 분석에 강점을 갖고 있어, 프롬프트의 각 토큰 Attribution을 시각화하는 저희의 태스크에 적합하다고 판단하여 사용하고자 합니다. 이에 앞서 먼저 Shapley Values에 대해 알아보겠습니다.
Shapley Values
Shapely Values는 게임 이론에서 도입된 개념으로,협동 게임에서 각 플레이어가 게임의 결과에 기여한 정도를 공정하게 분배하는 방법입니다. 이또한 모델 해석에 적용하여, 각 특성이 모델의 예측값에 얼마나 기여했는지 정량적으로 분석 가능합니다. Shapley Values의 특징은 다음과 같습니다. (1) 모든 가능한 특징 조합을 고려하여 공정한 기여도 계산 (2) 모든 조합을 고려한 특징 기여도를 계산하기 때문에, 각 특징 간의 상호작용을 포함 (3) 특정 특징을 추가하거나 제외했을 때의 모델 출력값의 변화량(marginal contribution)을 계산
Shapely Values에 대해 아래 예시 그림으로 더 쉽게 이야기 해보겠습니다.
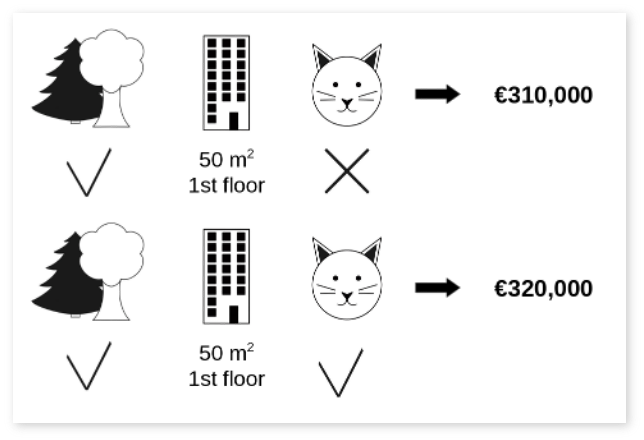
집의 특징인 공원 여부 & 고양이 허용 여부 & 면적 크기가 각각 “얼마나 집 가격에 기여했을까?”
이러한 의문에 대해 해당 그림은 두 가지의 경우를 보여줍니다. 첫번째 조합의 경우, 고양이를 집에서 키우는 것이 허용되지 않아 집 가격이 €310,000로 측정되었습니다. 두번째 조합의 경우, 고양이가 허용되어 집 가격이 €320,000로 더 높게 측정된 것을 확인할 수 있습니다. Shapley Values는모든 가능한 특징 조합에서 기여도를 계산한 후, 이를 평균하여 각 특징의 중요도를 평가합니다. 예를 들어, 고양이 허용 여부라는 특징의 Shapley Value는 아래와 같은 모든 조합에서 고양이가 포함되었을 때와 포함되지 않았을 때의 출력 차이를 계산한 후, 이 차이의 평균을 구해 계산됩니다.
해당 그림에서는 공원 여부+면적 크기이라는 단일 조합에서 고양이 허용 여부로 인해 발생한 가격 차이를 보여주기에, 정확한 Shapley Value를 계산할 수 없지만, 위와 같은 단일 조합에서는 고양이의 기여도가 €10,000라고 할 수 있습니다.
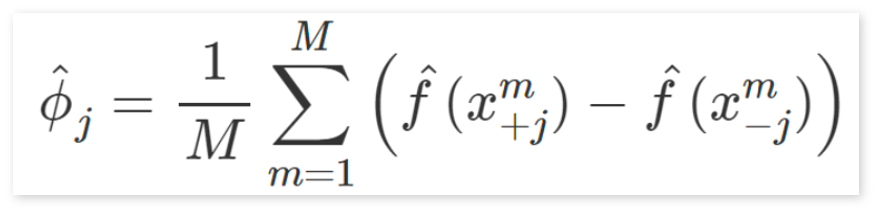
특징의 조합을 모두 고려하기에 Shapley Values는 특징의 조합이 많아질수록 모든 가능한 경우를 계산하는 데 드는 비용이 기하급수적으로 증가합니다. 또한 정확한 계산이 오히려 비효율적인 경우가 존재할 수 있는데, 이때 일부 조합만 샘플링하여 계산하는 방식으로 Shapley Values를 근사할 수 있습니다. 계산량을 크게 줄이면서도 Shapley Values의 근사치를 얻을 수 있으며, 정확한 계산 대신 일부 조합만을 선택해 효율적으로 평가 가능하다는 장점으로 샘플링 방식이 많이 사용됩니다.
또 이러한 Shapley Values를 LLM과 같은 대규모 모델에 적용한다면 연산량이 매우 증가하는데요, Shapley Values와 유사하게 기여도를 계산하지만 좀 더 간소화된 방식으로 저희는 Feature Ablation을 사용하였습니다.
Feature Ablation(특징 소거)
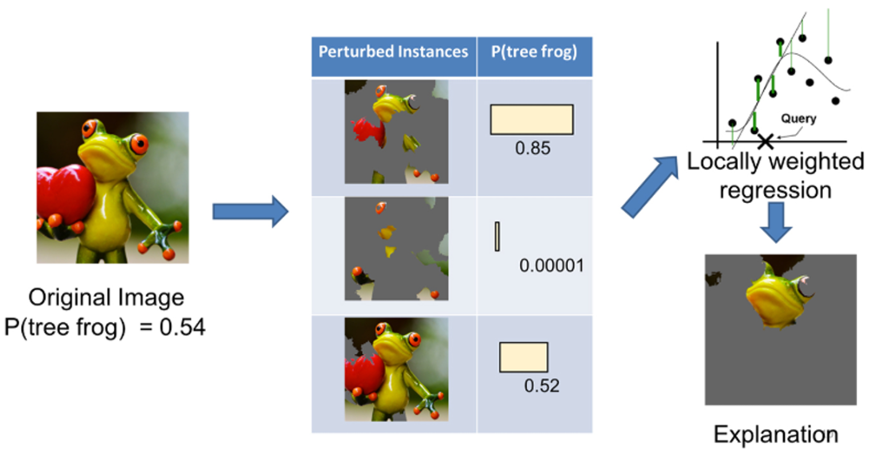
Feature Ablation에 대해 더 자세히 알아보겠습니다. Feature Ablation은 Perturbation 기반 접근법으로 기여도를 계산합니다. 이는 입력 데이터를 의도적으로 변경하여, 그 변화가 모델의 출력에 미치는 영향을 측정하는 방식입니다. 특정 값을 0으로 대체한다거나 혹은 입력의 일부를 마스킹하거나 제거하는 방식으로 특징을 변경합니다. 입력 데이터의 특징 수가 많을수록 계산 비용이 높을 수 있다는 단점이 있지만, 직관적이고 다양한 데이터 유형에 적용 가능하다는 장점이 존재합니다. Feature Ablation은 이러한 접근법을 바탕으로 실제로 입력 데이터를 기준값으로 대체하여, 이로 인해 모델 출력이 얼마나 변하는지를 측정하는 작업이라고 할 수 있습니다. 예시로, 이미지 데이터의 경우 특정 픽셀이나 영역을 검은색으로 덮는 방식으로 해당 영역의 중요도를 평가할 수 있고, 텍스트 데이터의 경우 특정 단어를 제거하거나 대체하여 그 단어가 출력에 미치는 영향을 측정하는 방식으로 기여도를 평가할 수 있습니다.
이는 Pytorch 기반의 Captum이라는 라이브러리를 통해 사용할 수 있습니다. Captum은 Gradients, Integrated Gradients, Feature Ablation등 다양한 방법을 지원하며, 모델 예측의 설명력을 더하고 분석할 수 있도록 도와주는 도구를 제공합니다.
Using Captum to Explain Generative Language Models
3. Process of Project
(1) Setting
Code Generation
사용자의 프롬프트에 대한 답변을 제공하는 LLM을 선정하기 앞서, 다음과 같은 Awesome Code LLM를 참고하였습니다. [ Top Code LLMs ]
Rank Model Params HumanEval MBPP
1 o1-mini-2024-09-12 - 97.6 93.9
2 o1-preview-2024-09-12 - 95.1 93.4
3 Qwen2.5-Coder-32B-Instruct 32B 92.7 90.2
4 Claude-3.5-Sonnet-20241022 - 92.1 91.0
5 GPT-4o-2024-08-06 - 92.1 86.8
6 Qwen2.5-Coder-14B-Instruct 14B 89.6 86.2
7 Claude-3.5-Sonnet-20240620 - 89.0 87.6
8 GPT-4o-mini-2024-07-18 - 87.8 86.0
9 Qwen2.5-Coder-7B-Instruct 7B 88.4 83.5
10 DS-Coder-V2-Instruct 21/236B 85.4 89.4
11 Qwen2.5-Coder-3B-Instruct 3B 84.1 73.6
12 DS-Coder-V2-Lite-Instruct 2.4/16B 81.1 82.8
13 CodeQwen1.5-7B-Chat 7B 83.5 70.6
14 DeepSeek-Coder-33B-Instruct 33B 79.3 70.0
15 DeepSeek-Coder-6.7B-Instruct 6.7B 78.6 65.4
16 GPT-3.5-Turbo - 76.2 70.8
17 CodeLlama-70B-Instruct 70B 72.0 77.8
18 Qwen2.5-Coder-1.5B-Instruct 1.5B 70.7 69.2
19 StarCoder2-15B-Instruct-v0.1 15B 67.7 78.0
20 Qwen2.5-Coder-0.5B-Instruct 0.5B 61.6 52.4
21 Pangu-Coder2 15B 61.6 -
22 WizardCoder-15B 15B 57.3 51.8
23 CodeQwen1.5-7B 7B 51.8 61.8
24 CodeLlama-34B-Instruct 34B 48.2 61.1
25 Code-Davinci-002 - 47.0 -
이 표에 따르면, OpenAI의 o1-mini-2024-09-12이 가장 성능이 좋은 Code Generation LLM으로 평가받은 것을 확인할 수 있습니다. 하지만 API 호출 방식으로 사용가능한 OpenAI의 LLM들의 경우, 내부에 접근하여 Weights를 활용해야하는 저희의 프로젝트에서는 적합하지 않았습니다. 따라서 o1-mini 다음으로 좋은 성능을 보인다고 평가된 Alibaba의 Qwen2.5-Coder시리즈의 모델을 채택하였습니다. 최종적으로 원활한 상호작용을 위해 Qwen2.5-Coder-1.5B-Instruct 모델을 사용했습니다.
(2) Interface: Prompt Explainer
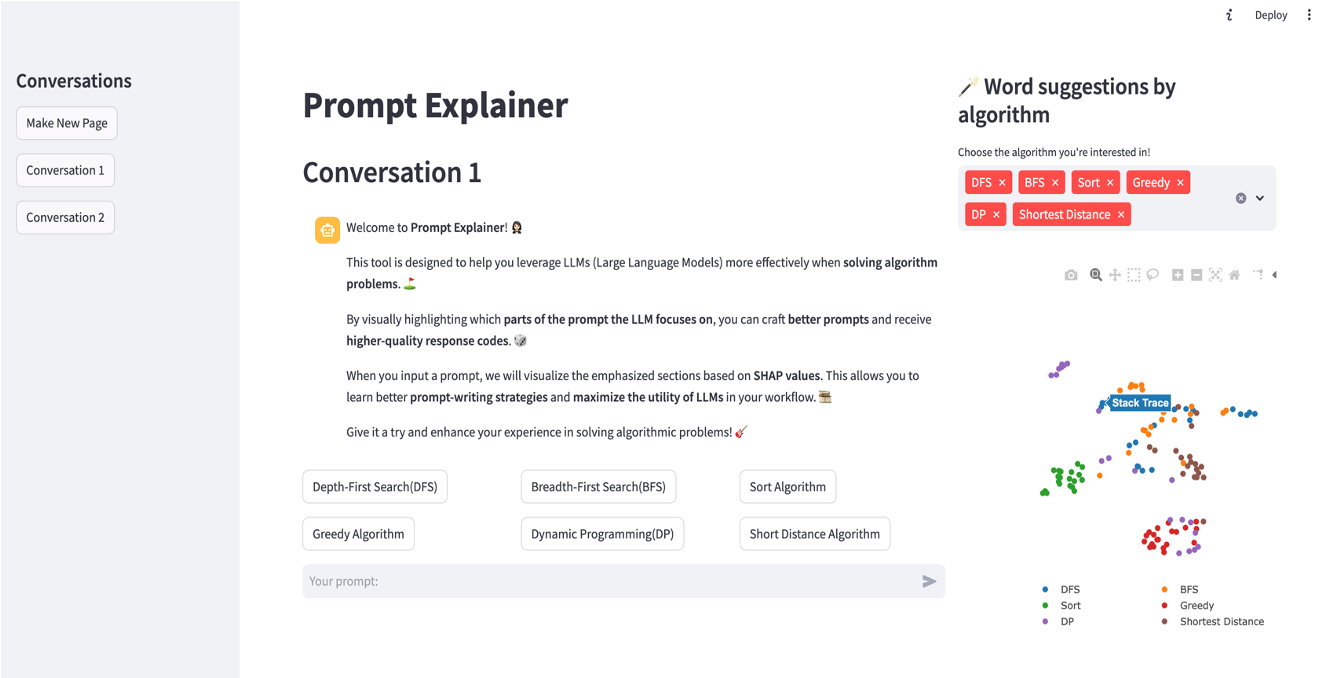
Main Functionalities
[ System Prompt ] Prompt Explainer의 왼쪽 섹션에서는 사용자가 각 알고리즘에 대한 프롬프트 작성에 참고할 수 있도록, 시스템 프롬프트를 제공합니다.

시스템 프롬프트는 LLM에게 역할 부여, 알고리즘 구현 시 지켜야할 규칙 등 구체적이고 효과적인 프롬프트로 작성되었으며, 사용자가 가운데 섹션에서 각 알고리즘 버튼을 누르면 출력되어 확인 가능합니다.
[ Word Suggestion by Algorithm ] Prompt Explainer의 오른쪽 섹션에서 사용자의 프롬프팅을 돕기 위한 “🪄 Word suggestions by algorithm” 기능을 구현하였습니다. 이는 각 알고리즘과 관련된 주요 단어들을 UMAP을 사용해 차원축소한 형태로 제공되며, 사용자는 scatter plot 상의 점을 클릭하고, 확대하며 각 알고리즘별 프롬프팅에 참고할 단어 20개를 확인할 수 있습니다. 이때 각 단어들의 임베딩을 위한 도구로 저희는 sentence-transformers/all-MiniLM-L12-v2을 사용하였습니다. 이는 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화합니다. 또한 상대적으로 가볍고 빠르며, GPU가 필요하지 않아 저자원 환경에서도 효과적으로 동작하기 때문에 채택하게 되었습니다.
유저 파이프라인

사용자는 위와 같은 흐름으로 이 인터페이스를 사용할 수 있습니다. 먼저 구현하고자 하는 알고리즘 카테고리를 선택하고, 이와 관련된 시스템 프롬프트를 확인합니다. 그리고 이를 바탕으로 프롬프트를 구체적으로 작성하고, LLM의 응답을 확인합니다. 그리고 응답에 대한 프롬프트의 기여도를 확인하고 알고리즘과 관련된 추천 단어를 참고하여 프롬프트를 수정합니다. 이 모든 과정을 반복함으로써 사용자는 원하는 응답을 볼 수 있도록, 효과적인 프롬프트로 최적화할 수 있습니다.
4. Results
제작한 인터페이스를 검증하기 위해 “Given an array of integers, find the most frequently occurring element. Example array: [1, 2, 2, 3, 2, 1, 4, 2],Expected output: 2” 라는 공통된 문제에 대해 정렬과 dictionary 를 활용해서 해결해달라는 프롬프트를 작성했습니다.
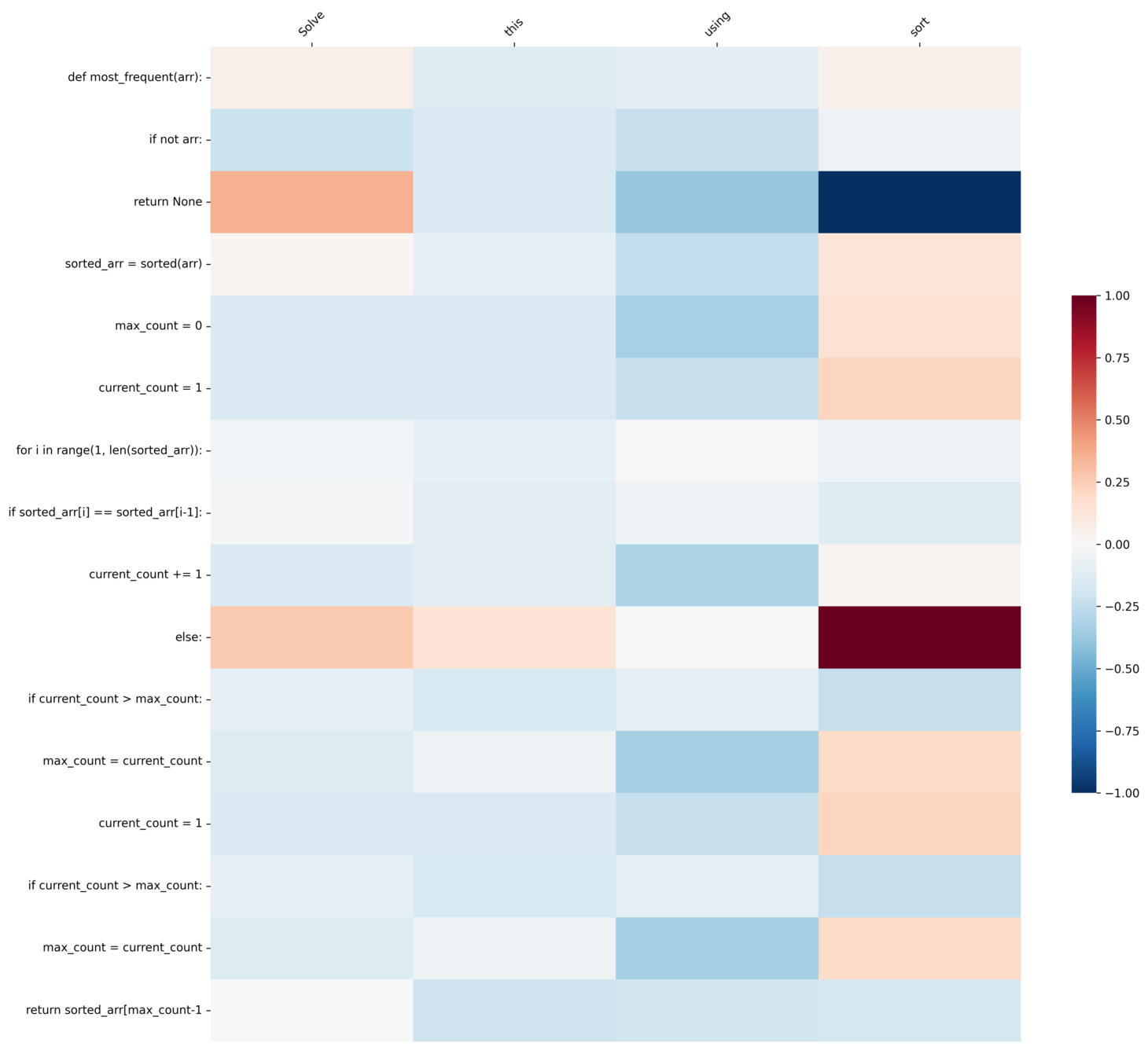
1️⃣
Solve this using sort라는 프롬프트를 작성한 결과, sorted 함수, max_count, current_count 같이 정렬을 활용하는 코드에sort 토큰이 가장 영향을 많이 준 것을 확인할 수 있습니다.
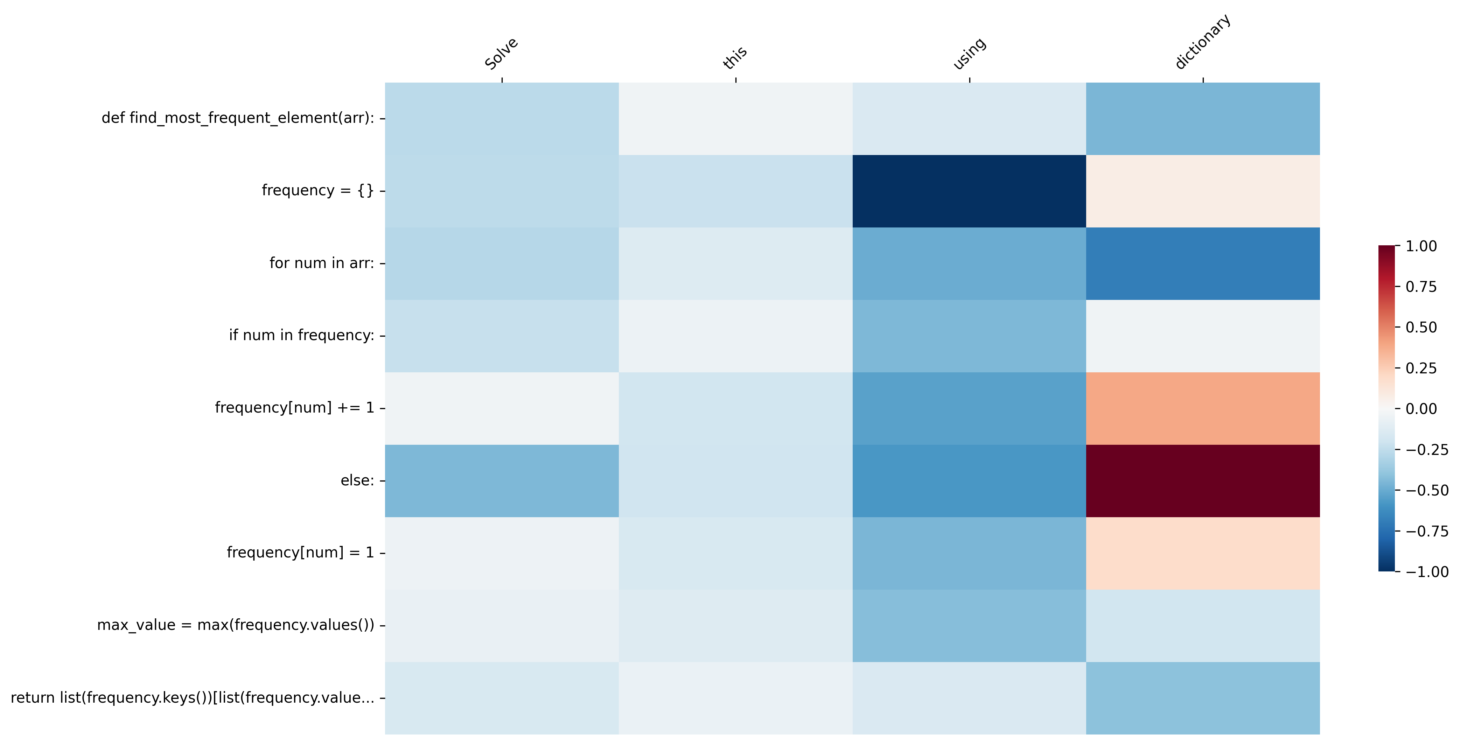
2️⃣
Solve this using dictionary라는 프롬프트를 작성한 결과, 빈도 수를 딕셔너리 자료 구조로 정의하는 것, 정의한 딕셔너리를 활용하여 빈도를 축적하여 연산하는 부분에dictionary 토큰이 높은 기여도를 보이고 있습니다.
비슷한 문장에서 중요한 키워드인 방식에만 차이를 두어 프롬프팅함으로써, 확연히 다른 코드와 시각화를 확인할 수 있게 됩니다. 이는 유의미한 차이를 한 시나리오를 통해 검증한 사례 중 일부이며, 이 외의 다양한 경우에도 prompt explainer를 활용할 수 있습니다.