
🌱 Introduction
“ 아름다운 사람은 머문 자리도 아름답습니다. ”
우리의 흔적은 공간 속에서 어떤 아름다움을 만들어낼 수 있을까요? 지나가는 순간들은 사라져버리지만, 그 자리에 남겨진 움직임은 하나의궤적이 되어 이야기를 만들어나갑니다. 우리가 걷고, 멈추고, 서로 스쳐 지나가는 모든 순간은 보이지 않은 선을 끊임없이 그리며 공간 속에 새겨집니다. 저희가 선정한 프로젝트 “아름다운 사람은 머문 자리도 아름답습니다.” 는 단순한 움직임들을 기록하고 모아 예술로 승화시키는 의미를 담은 주제입니다. 사람들이 지나다니는 비디오에서 추적된 이동 궤적을 기록해 보이지 않은 선들을 시각화하고, 그 궤적을 이용해 새로운 시각적 작품으로 재탄생시키고자 합니다. 이 프로젝트를 통해 우리는 눈에 보이지 않던 순간과 공간을 새롭게 바라보고, 작은 움직임들이 모여 하나의 예술로 완성되는 과정을 통해 사람이 만들어내는 공간의 아름다움을 재발견하고자 합니다.
이 프로젝트는 “컴퓨터 비전(Computer Vision)기술”을 활용하여 인간의움직임과 흔적을 데이터로 기록하고, 이를 새로운 시각적 경험으로 재창조하는 과정을 탐구합니다. 여기서 컴퓨터 비전(Computer Vision)이란, 컴퓨터가 디지털 이미지나 비디오를 통해 인간처럼 시각 정보를 분석하고 이해하는 기술로, 이 기술은 이미지 인식, 객체 탐지, 동작 추적 등 다양한 분야에서 활용됩니다. 프로젝트에 활용할 주요 비전 태스크(Vision Task)는 총 두 가지 입니다.
- 객체 탐지(Object Detection) & 객체 추적(Object Tracking)
- 스타일 변환(Style Transfer)
🌱 Computer Vision Task
Part 1. Tracking
Object Tracking은 딥러닝의 한 응용 분야로, 프로그램이 초기 객체 감지 세트를 받아 각 객체에 고유한 식별자(ID)를 부여한 후, 비디오 프레임에서 이동하는 객체를 추적하는 기술입니다. 이는 비디오에서 자동으로 객체를 식별하고 높은 정확도로 이를 일련의 궤적으로 해석하는 작업을 의미합니다. 일반적으로 추적 중인 객체 주위에는 아래 사진과 같이 Bounding Box가 나타나 사용자가 화면에서 객체의 위치를 파악할 수 있도록 합니다.

Object Tracking 알고리즘은 단일 객체 추적(Single Object Tracking, SOT)과 다중 객체 추적(Multiple Object Tracking, MOT)으로 분류됩니다. SOT는 한 번에 하나의 객체를 추적하는 반면, MOT는 동시에 여러 객체를 추적합니다. 그 중 MOT는 객체 간의 상호작용과 겹침으로 인해 더 복잡한 문제로 간주됩니다. MOT에 대해 좀 더 자세히 알아보겠습니다. 다중 객체 추적(Multiple Object Tracking, MOT)은 비디오 시퀀스에서 여러 객체를 동시에 추적하는 컴퓨터 비전 분야의 핵심 과제입니다. MOT의 주요 목표는 각 프레임에서 객체를 정확하게 감지하고, 동일한 객체를 연속된 프레임에서 일관되게 식별하여 그 이동 경로를 추적하는 것입니다.
MOT 관련 주요 모델
다중 객체 추적(MOT)을 구현하기 위해 다양한 모델과 알고리즘이 개발되었습니다. 주요 모델들은 다음과 같습니다:
SORT(Simple Online and Realtime Tracking): 객체 감지 결과를 기반으로 칼만 필터와 Bounding Box의 IoU를 이용하여 객체들을 추적하는 알고리즘입니다. 여기서 IoU란, Intersection over Union 의 약자로, 두 Bounding Box 영역의 합집합을 분모, 교집합을 분자로 두고 계산합니다. 값이 1에 가까울수록 두 Box가 겹치는 영역이 큽니다.
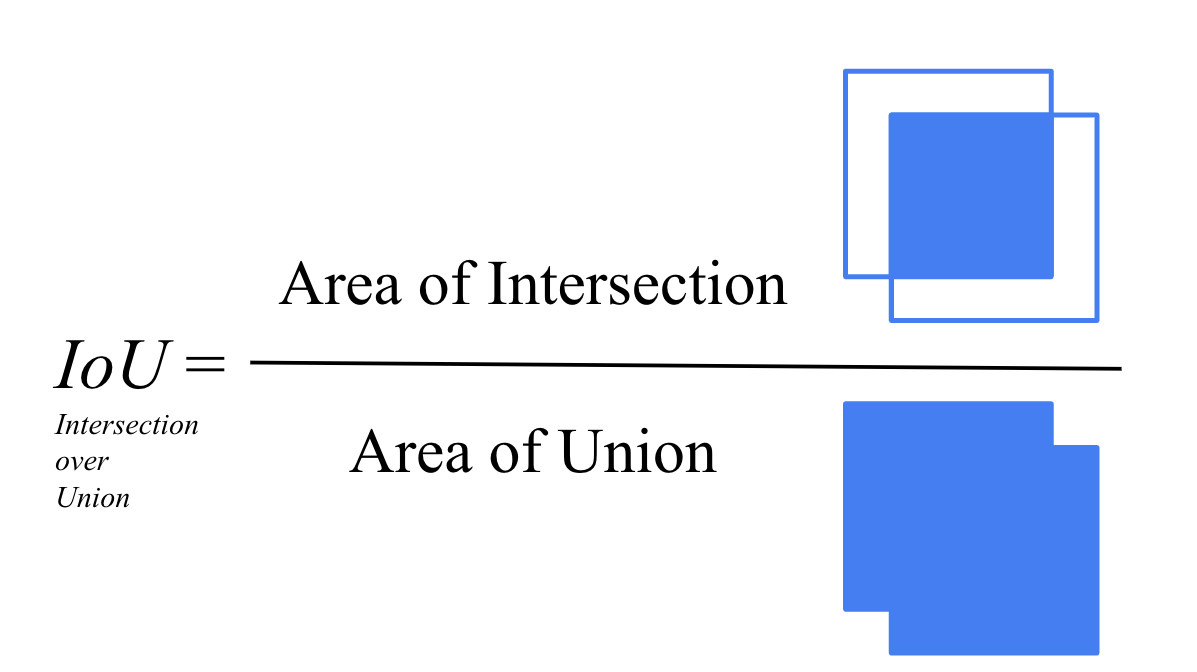
DeepSORT: SORT의 확장 버전으로, 딥러닝을 활용한 특징 추출을 통해 객체의 재식별(Re-identification) 기능을 강화하여 추적 성능을 향상시킨 모델입니다.Tracktor: 객체 감지기를 추적기(Tracktor)로 활용하는 접근법으로, 감지기의 Bounding Box 회귀를 사용하여 객체의 위치를 업데이트하는 방식으로 진행됩니다.
Part 2. Style Transfer
Style Transfer는 말 그대로 스타일을 전송(Transfer)한다는 의미로, 원본 이미지의 콘텐츠를 유지하면서 다른 이미지의 스타일을 결합하는 기술을 말합니다. 이는 머신러닝 알고리즘을 활용하여 이미지, 동영상, 음악 등 새로운 데이터를 생성하는 데에 자주 사용되는 기술입니다. Style Transfer의 기본 개념은 비교적 간단합니다. 먼저 원본 이미지에서 콘텐츠(Content)와 스타일(Style)을 분리한 후, 이를 새로운 이미지에 결합하는 방식입니다. 예를 들어, 반 고흐의 초상화에서 그의 독특한 화풍(Style)을 추출해 다른 사람의 초상화에 적용하면, 마치 고흐가 그린 것처럼 보이는 새로운 초상화를 생성할 수 있습니다.
- 스타일: 질감, 색상, 시각적 패턴과 같은 이미지의 미적인 특징.
- 콘텐츠: 이미지 내 개체와 배열(구조) 등 이미지의 주요 정보
Style Transfer는 컨볼루션 신경망(CNN)이나 적대적 생성 신경망(GAN)과 같은 딥러닝 모델을 활용합니다. 이러한 모델은 대규모 이미지 데이터로 훈련되어 스타일과 콘텐츠를 정의하는 기본 패턴을 학습합니다. 사전 학습된(Pre-trained) 모델은 입력 이미지에서 스타일과 콘텐츠 특징을 추출하며, 이를 통해 다음과 같은 과정을 수행합니다:
- 스타일 추출: CNN의 여러 레이어 간 상관 관계 분석
- 콘텐츠 추출: 특정 레이어의 활성화 분석
스타일과 콘텐츠가 추출되면, 이를 결합해 콘텐츠는 동일하지만 스타일이 다른 새로운 이미지를 생성합니다. 이 과정은 손실 함수를 최소화하는 최적화 알고리즘(예: Gradient Descent)을 사용해 출력 이미지의 픽셀 값을 반복적으로 업데이트하여 이루어집니다. 손실 함수는 다음 두 가지 차이를 최소화하도록 설계됩니다:
- 입력 이미지와 출력 이미지 간 콘텐츠 특징의 차이
- 스타일 이미지와 출력 이미지 간 스타일 특징의 차이
Style Transfer의 대표적인 연구는 2016년 발표된 논문 “Image Style Transfer Using Convolutional Neural Networks”입니다. 이 연구는 딥러닝을 기반으로 Style Transfer를 구현한 최초의 사례로, 이후 관련 기술 발전에 중요한 기초가 됐습니다.

🌱 Pipeline
저희가 진행할 프로젝트의 파이프라인은 다음과 같습니다. 파이프라인은 크게 3단계로 나눌 수 있습니다.
graph TD
Video_Sequence:::data --> Detection_Model:::model --> Color:::data --> Tracking_Model:::model
Detection_Model:::model --> Video_Sequence_with_Bounding_Box:::data --> Tracking_Model:::model
Tracking_Model:::model --> Color_Lines:::data --> Generation_Model:::model --> Art:::data
Another_Image:::data --> Generation_Model
classDef data fill:#ffcc00,stroke:#333,stroke-width:2px, color:#0a0a0a;
classDef model fill:#ff6666,stroke:#333,stroke-width:2px, color:#0a0a0a;[ Detection Part ]
입력(Video_Sequence):
- 영상 시퀀스
과정(Detection_Model):
- 사전 학습된 객체 탐지 모델로 영상 내 사람을 탐지
- 탐지된 객체의 Bounding Box 영역에서 고유한 대표 색상을 추출
출력(Color&Video_Sequence_with_Bounding_Box):
- 탐지된 객체에 고유한 색상의 Bounding Box가 표시된 영상 시퀀스

[ Tracking Part ]
입력(Color&Video_Sequence_with_Bounding_Box):
- 객체 탐지 모델의 Bounding Box를 포함한 영상 시퀀스 및 각 객체 별 고유 색상
과정(Tracking_Model):
- 객체 추적 모델을 통해 여러 프레임에 걸쳐 여러 객체의 위치 추적
- 추적되는 객체의 이동 경로를 객체의 고유한 색상으로 시각화하여 영상 내에 동선을 표시
출력(Color_Lines):
- 객체의 이동 흔적이 추가된 비디오 프레임

[ Generation Part ]
입력(Color_Lines&Another_Image):
- 추적선이 포함된 영상 시퀀스
- 스타일로 적용할 이미지
과정(Generation_Model):
- Image-to-Image 생성 모델을 활용
- 영상 시퀀스를 스타일 이미지의 스타일을 적용하여 생성
출력(Art):
- 관람객의 이동 패턴을 추상적이고 예술적으로 표현한 이미지


🌱Model
Part 1. Detection & Tracking
저희는 길거리 속 사람들이 움직이는 비디오에서 사람을 Detection하고, Tracking 하기 위해 YOLO 모델을 사용했으며, YOLO의 여러 버전 중 가장 높은 성능을 보이는 YOLOv11 모델을 사용했습니다.
여러 특징 중에서 YOLO 모델이 Tracking-by-Detection방식을 지원한다는 점과 데이터의 형태가비디오인 점에 주목해, Detection 단계에서는 객체를 신속하고 정확히 탐지하고, Tracking 단계에서는 탐지된 객체를 프레임 간 연결하여 궤적을 추적할 수 있는 가장 적합한 모델이라고 판단해 해당 모델로 선정했습니다.
YOLOv11
Ultralytics YOLO 시리즈의 최신 버전으로, 실시간 객체 탐지 분야에서 정확도, 속도, 효율성 측면에서 혁신적인 최신 모델입니다. 이전 YOLO 버전들의 발전을 바탕으로, YOLOv11은 아키텍처와 학습 방법,비디 성능적인 측면에서 이전 버전 대비 효율성을 높였습니다.
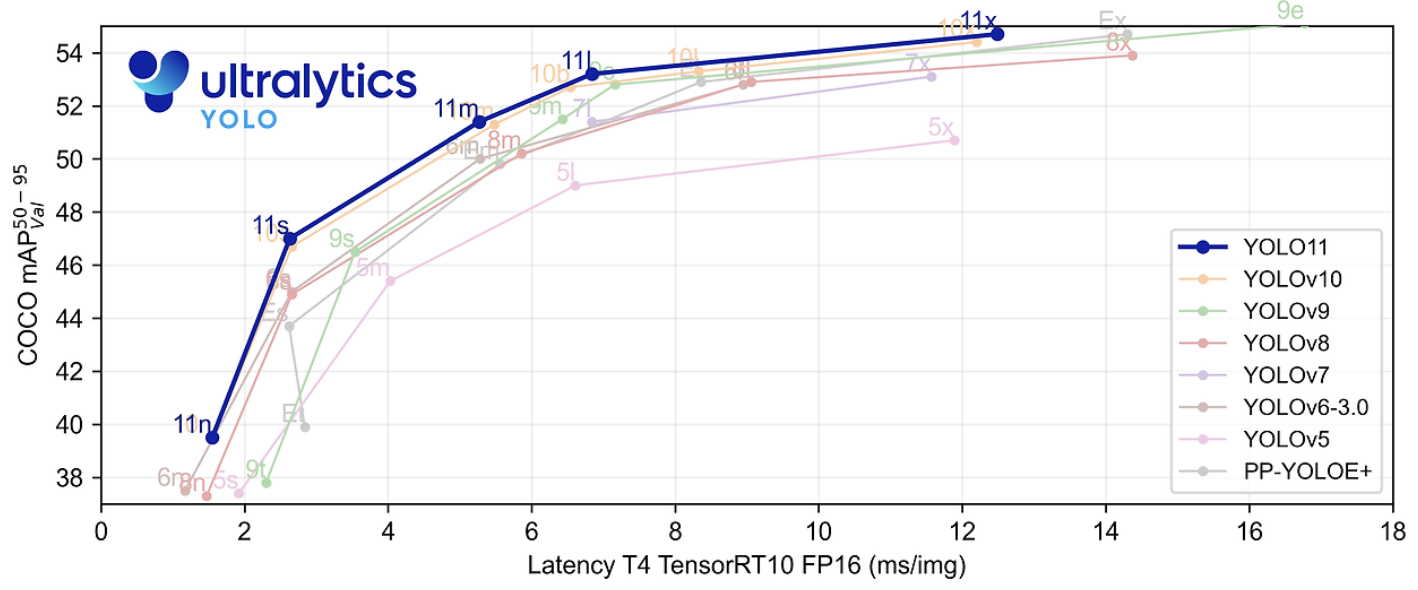
위의 그래프와 같이 YOLOv11은 YOLOv8에 비해 22% 적은 파라미터로 COCO 데이터셋에서 더 높은 평균 정밀도(mAP)를 달성하여 계산 효율성을 유지하면서도 정확도를 향상시켰습니다. 또한 세밀한 아키텍처 디자인과 최적화된 학습 파이프라인을 도입하여 처리 속도를 높이면서 정확도와 성능 간의 최적의 균형을 유지하여 효율성 및 속도를 최적화했습니다.
YOLOv11 in Detection
Detection 단계에서는 입력된 비디오의 각 프레임(frame)에서 객체(person)의 위치를 파악하고, 이를 Bounding Box로 표현합니다.
model = YOLO("yolo11n.pt")
# YOLO 객체 탐지 및 추적
results = model.track(frame, persist=True)
boxes = results[0].boxes.xywh.cpu() # Bounding Box- YOLO 모델(
model = YOLO("yolo11n.pt"))은 영상 프레임을 입력으로 받아 객체를 탐지. 이때 YOLO는 사전에 학습된 가중치(yolo11n.pt)를 사용하여 특정 클래스(사람)를 인식합니다. model.track()메서드는 Tracking-by-Detection 방식을 기반하므로 Detection과 Tracking을 동시에 수행합니다.- 탐지된 객체의 위치는
boxes에 저장되며, 이는 각 객체의 중심 좌표(x, y), 너비(w), 높이(h)로 구성됩니다.
YOLOv11 in Tracking
Detection 결과를 바탕으로 YOLOv11은 객체 추적을 수행합니다. 이 단계는 각 프레임에서 탐지된 객체를 고유 ID와 연결하여, 객체의 궤적을 추적하는 데 중점을 둡니다.
track_ids = results[0].boxes.id.int().cpu().tolist() # 객체 추적 ID
track = track_history[track_id]
track.append((x, y))- 탐지된 객체의 위치 정보를 기반으로 객체를 추적하며, 각 객체에 고유한
ID를 부여합니다. 이 고유 ID는 객체의 궤적을 관리하고, 프레임 간 동일 객체를 식별하는데 사용합니다. track_ids: 현재 프레임에서 탐지된 각 객체의 고유 ID를 말합니다. 동일한 객체의 위치를 이전 프레임의 궤적 데이터와 연결합니다.- 각 객체의 위치는
track_history딕셔너리에 저장되며, 프레임 간 객체 위치를 누적 저장하여 궤적을 생성합니다.
Part 2. Style Transfer for Image
객체를 Detection하고 Tracking하여 추적선이 그려진 이미지를 바탕으로 Style Transfer를 진행했습니다. Neural Style Transfer는 2016년 논문 "Image Style Transfer Using Convolutional Neural Networks"에서 처음 제안되었습니다. 이 연구는 딥러닝을 활용한 스타일 변환으로, 최적화 기반 접근법(Optimization-based Approach)을 사용하여 Style Transfer 문제를 해결했습니다. Neural Style Transfer는 딥러닝을 기반으로 이미지의 스타일과 콘텐츠를 조합하여 새로운 이미지를 생성하는 기술입니다. 이 기술은 원본 이미지의 구조를 유지하면서, 선택한 스타일 이미지를 결합하여 독창적인 결과를 만들어냅니다. Neural Style Transfer는 다음의 에너지 함수(Energy Function)를 최소화하여 스타일 변환을 수행합니다:
- : 콘텐츠 이미지
- : 스타일 이미지
- : 스타일 변환 결과 이미지
- 에너지 함수는 콘텐츠 손실(Content Loss)과 스타일 손실(Style Loss)의 두 항목으로 구성됩니다. 이를 최소화하면 콘텐츠와 스타일이 결합된 최적의 결과 이미지 를 얻을 수 있습니다.
1) 콘텐츠 표현 (Content Representation) 콘텐츠 표현은 이미지 구조를 반영하는 고수준 특징(High-Level Features)을 기반으로 정의됩니다.
- 딥러닝 모델(VGG 네트워크 등)의 높은 계층(Higher Layer)에서 추출된 특징맵(Feature Map)을 사용합니다.
- 높은 계층의 특징은 이미지의 구체적인 구조(예: 물체의 형태)만 남고, 색상이나 텍스처와 같은 저수준 정보는 제거됩니다.
2) 스타일 표현 (Style Representation) 스타일 표현은 이미지의 텍스처와 색상 분포를 반영하며, 이를 위해 Gram Matrix가 사용됩니다.
- Gram Matrix는 특징맵의 채널 간 상관관계를 계산하여, 이미지의 통계적 스타일 정보를 제공합니다.
- 수식:
여기서 는 -번째 계층에서 -번째 채널의 -번째 공간 위치에 해당하는 값입니다.
같은 해 발표된 논문 “Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization"에서는 AdaIN 레이어를 도입해 Style Transfer를 실시간으로 수행하는 방식을 제안했습니다. AdaIN은 콘텐츠와 스타일 특징맵의 분포를 정규화하여 스타일 변환을 수행합니다:
- : 콘텐츠 입력의 특징맵
- : 스타일 입력의 특징맵
- : 의 평균과 표준편차
이 접근법은 VGG 네트워크 기반의 인코더-디코더 구조로 구현되며, 기존의 최적화 기반 방식보다 빠른 처리 속도를 제공합니다.
Part 3. Style Transfer for Video
객체를 Detection하고 Tracking하여 추적선이 그려진 영상 시퀀스를 바탕으로 Style Transfer를 진행했습니다. 동영상의 스타일을 변환하는 과정은 이미지 스타일 전환 기법을 비디오에 확장한 것으로, 시간적 일관성을 보장하며 프레임 간 불연속성을 최소화하는 데 중점을 둡니다. 이를 가능하게 하기 위해 기존의 Neural Style Transfer 방식에 기반하여 비디오 전용 최적화 기법과 손실 함수를 추가로 개발했습니다. 이 글에서는 동영상 스타일 전환 기술을 가능하게 한 기본 모델, 주요 논문인 "Artistic Style Transfer for Videos"을 소개합니다. 이미지 전환 기술을 단순히 비디오에 적용하면 다음과 같은 문제가 발생합니다.
- 프레임 간 깜빡임 현상: 독립적으로 스타일을 전환하면 각 프레임 간 일관성이 없어 깜빡이는 듯한 부자연스러운 영상이 생성됩니다.
- 가려짐(Occlusion)과 움직임 경계: 비디오에서는 움직이는 객체와 가려진 영역이 많아, 이들 간의 일관성을 유지하기 어렵다는 문제가 있습니다.
이를 해결하기 위해, 아래와 같이 시간적 일관성을 보장하는 최적화 전략과 새로운 손실 함수가 필요합니다.
- 초기화 방법 개선
이전 프레임의 스타일 변환 결과를 광학 흐름으로 왜곡하여, 현재 프레임의 초기값으로 사용했습니다. 이를 통해 이전 프레임과의 연결성을 보장하고, 불필요한 계산을 줄이며, 정적 배경과 움직이는 객체 간의 부드러운 전환을 구현하여 스타일 전환 결과의 시간적 일관성을 향상시켰습니다.
- 단기적 시간적 일관성 손실 함수
연속된 프레임 간의 급격한 변화를 제어하기 위한 손실 함수로, 움직임 경계와 가려진 영역을 효과적으로 처리했습니다.
- 장기적 시간적 일관성 기법
움직이는 객체가 가려졌다가 다시 나타나는 경우에도 스타일이 일관되도록 장기 움직임 추정 기법을 활용했습니다.
- 다중 패스 접근 방식
전체 비디오 시퀀스를 여러 번 처리하면서, 순방향 및 역방향 광학 흐름을 활용해 안정적인 스타일 전환 결과를 생성했습니다.
해당 논문에서 제안한 스타일 전환 손실 함수는 다음과 같이 구성됩니다:
- 콘텐츠 손실
원본 프레임의 콘텐츠 정보와 스타일 전환된 프레임 간 차이를 최소화합니다.
- 스타일 손실
스타일 이미지와 변환된 프레임 간 Gram Matrix 차이를 기반으로 정의됩니다.
- 단기적, 장기적 시간적 일관성 손실
이전 프레임과 광학 흐름으로 연결된 현재 프레임 간의 차이를 최소화합니다. 또한, 단순히 이전 가중치를 사용하는 것이 아니라 더 먼 과거의 프레임에서 계산된 광학 흐름을 참조하여 손실 함수를 개선했습니다.
전체 손실 함수는 아래와 같습니다:
여기서 , , 는 각각 콘텐츠, 스타일, 시간적 일관성 손실의 가중치입니다.
- 다중 패스 알고리즘
출력 이미지는 경계 부근에서 대비와 다양성이 낮아지는 경향이 있습니다. 카메라 움직임이 큰 경우, 시간적 제약을 적용함으로써 이미지 경계의 낮은 화질이 시간이 지날수록 중앙으로 뻗어나가 품질이 저하되는 문제가 발생합니다.
- : 번째 프레임의 번째 pass에서의 초기값
- : pass를 지난 출력물
- : 벡터의 각 요소끼리 곱하는(element-wise) 연산자
전방향:
후방향:
🌱 Result
- 이미지 변환 결과

사람들의 이동 흐름과 사람들에게서 추출한 고유한 색상이 잘 반영된 예술 작품으로 탄생했습니다. 이로써 사람들의 이동과 일상의 공간을 새롭게 기록하고 기억할 수 있는 창작물로써 가치를 기대해볼 수 있습니다.
- 비디오 변환 결과


비디오를 변환하였을 때에는 이미지의 결과와 달리 사람들의 추적선과 배경이 조화롭게 섞이지 않고 분리되어 보이는 현상이 발생했습니다. 추적선과 배경 사이의 경계를 부드럽게 이을 수 있는 방법이 모색된다면 더욱 자연스러운 예술 작품으로 탄생할 수 있을 것으로 기대됩니다.