#149 위클리 딥 다이브 | 2026년 6월 24일
이번주 뉴스레터에는 이런 내용을 담았어요!
- 온디바이스와 서버 모델을 선택하는 하이브리드 모델을 소개합니다.
- 하이브리드 모델을 구현하는 2가지 방법을 설명합니다.
- Apple WWDC26에서 발표된 AFM의 특징을 정리합니다.
Apple 파운데이션 모델의 이면에 있는 것
안녕하세요, 에디터 배니입니다.
지난 8일, Apple의 세계 개발자 회의 WWDC26이 개최됐습니다. Apple의 신제품이나 신기술이 공개되는 자리인 만큼, 매년 세간의 화제를 모으는 큰 행사인데요. 2024년에는 Apple Intelligence를, 2025년에는 Liquid Glass 디자인을 선보였죠.

이번 행사에서 Apple은 3세대 Apple Foundation Models(AFM)를 공개했습니다. 이번 모델 패밀리는 크게 온디바이스 모델과 서버 모델로 구분해볼 수 있습니다. 온디바이스 모델에는 AFM 3 Core, AFM 3 Core Advanced, 그리고 클라우드 서버 모델에는 AFM 3 Cloud, ADM 3 Cloud, AFM 3 Cloud Pro으로 구성되어 있습니다. Apple은 이 다양한 모델군을 하나의 통합된 시스템 안에서 동작시키고자 합니다. 때문에 필요에 따라 적절한 모델을 선택할 수 있는 방법이 중요해졌습니다.
클라우드 서버 모델로 모든 것을 처리할 수 있다면, 온디바이스 모델은 사용하지 않아도 괜찮을 텐데 Apple이 모델을 다양하게 구성한 이유가 무엇일까요? 당장은 서버 모델만 운영하는 게 사용자에게 더 좋은 성능을 제공하는 방향일 수 있습니다. 그러나 장기적인 관점에서 본다면 클라우드 서버 비용을 낮추고, 온디바이스 전환을 유연하게 할 수 있다는 점에서 이와 같은 시도는 지속적으로 필요하다고 봅니다. 더구나 Apple은 자체 칩셋(Apple Silicon)을 개발할 수 있기 때문에 다른 서비스 기업보다도 더 유리한 입지에 있는 것도 사실이고요.
Apple의 청사진과도 같은 Apple Foundation Models. 이번주 뉴스레터에서는 그 배경이 되는 하이브리드 모델의 특징과 Apple이 다양한 모델을 하이브리드로 구현한 방법에 대해서 알아보겠습니다.
온디바이스 모델
사용자의 기기 안에서 직접 실행되는 AI 모델을 의미합니다. 요청을 서버로 보내지 않고 스마트폰이나 노트북 내부에서 처리하기 때문에 응답 속도와 개인정보 보호 측면에서 장점이 있습니다. 다만 메모리, 배터리, 발열, 연산 성능의 제약이 있어 대형 서버 모델만큼 복잡한 추론을 수행하기는 어렵습니다.
왜 ‘하이브리드 모델’이 필요할까?
앞서 말한 것처럼 하이브리드 모델 구성을 지속적으로 시도하는 것은 장기적인 관점에서 서버 운영 비용 절감과 신기술 확보에 있어 유리하기 때문입니다.. 온디바이스 AI 모델의 성능이 너무 뛰어나서 서버는 사용할 일조차 없는 것이 가장 이상적일 테지만 현실적으로는 하드웨어 제약과 모델 성능 이슈로 많이 어렵죠.
온디바이스 AI로 동작할 수 있는 모델의 파라미터 크기는 보통 3B 남짓입니다. 이해하기 쉽게 용량으로 표현하자면 (16비트 기준으로) 6GB 정도 차지한다고 보면 되는데요. 언어 모델이 3B라고 하면 작은 모델에 속하는데도 생각보다 용량이 큽니다. 모바일 기기에서 6GB 크기의 게임을 플레이한다고 생각해도 버벅거리거나 지연이 발생하는 등의 문제들이 쉽게 예상되는 것처럼, 온디바이스 AI 모델도 마찬가지입니다. 모델 경량화 기법인 양자화(Quantization) / 가지치기(Pruning) 등을 적용한다고 해도 최소한 2-3GB는 차지하게 됩니다.
그렇다고 해서 파라미터 3B 크기의 모델이 많은 역할을 할 수 있는 것은 아닙니다. 문서 요약 / 번역과 같이 비교적 단순한 태스크는 해결할 수 있지만, 깊은 사고와 추론이 필요한 문제에 답하기는 어렵습니다. 이미 사용자의 눈높이는 ChatGPT나 Claude 같은 상용 모델에 맞춰져 있기에 온디바이스 모델을 내놓는다고 해도 오히려 비판만 받을 수도 있고요.
그래서 간단한 문제는 사용자의 디바이스 내에서 작동할 수 있도록 하고, 복잡한 문제는 클라우드에서 처리하여 좋은 답변을 출력하는 하이브리드 모델이 제안됐습니다. 그렇다면 언제 어떤 모델을 사용할지, 어떻게 결정할 수 있을까요? 사용자에게 매 순간 결정하게 한다면 편의성이 크게 떨어질 것이기에, 어떤 모델을 사용할지 판단하는 것도 분명 AI 모델의 몫이어야 할 것입니다.
여기서 진퇴양난의 상황이 발생합니다. 결국, 적절한 판단을 위해서는 모델 성능이 좋아야 하는데 이를 위해 서버 모델을 사용한다면 비용 절감은 되지 않을 것이고요. 반대로 온디바이스 모델을 그대로 사용한다면 애초에 고성능 온디바이스 모델을 개발해야 합니다. 애초에 판단할 수 있다는 것은 그만한 지식 체계를 갖고 있다는 말이기도 하니까요.
하이브리드 모델을 구현하는 현실적인 방법
하이브리드 모델을 구현한다는 것은 결국 어떤 요청을 어떤 모델에 맡길지 결정하는 문제입니다. 하지만 실제로는 그 경계를 정하는 일이 어렵습니다. 요청이 짧다고 쉬운 것도 아니고, 길다고 반드시 어려운 것도 아니기 때문입니다. 그래서 하이브리드 시스템에서는 모델 자체의 성능만큼이나 분기 판단을 어떻게 할 것인가가 중요해집니다.
가장 대표적인 방법은 두 가지로 볼 수 있습니다. 첫 번째는 답변을 생성하기 전에 사용자의 요청을 보고 판단하는 Router(라우터) 방식입니다. 두 번째는 작은 모델이 먼저 답변을 생성한 뒤, 그 답변을 그대로 사용할지 큰 모델로 넘길지 정하는 Deferral(디퍼럴) 방식입니다.
- Router
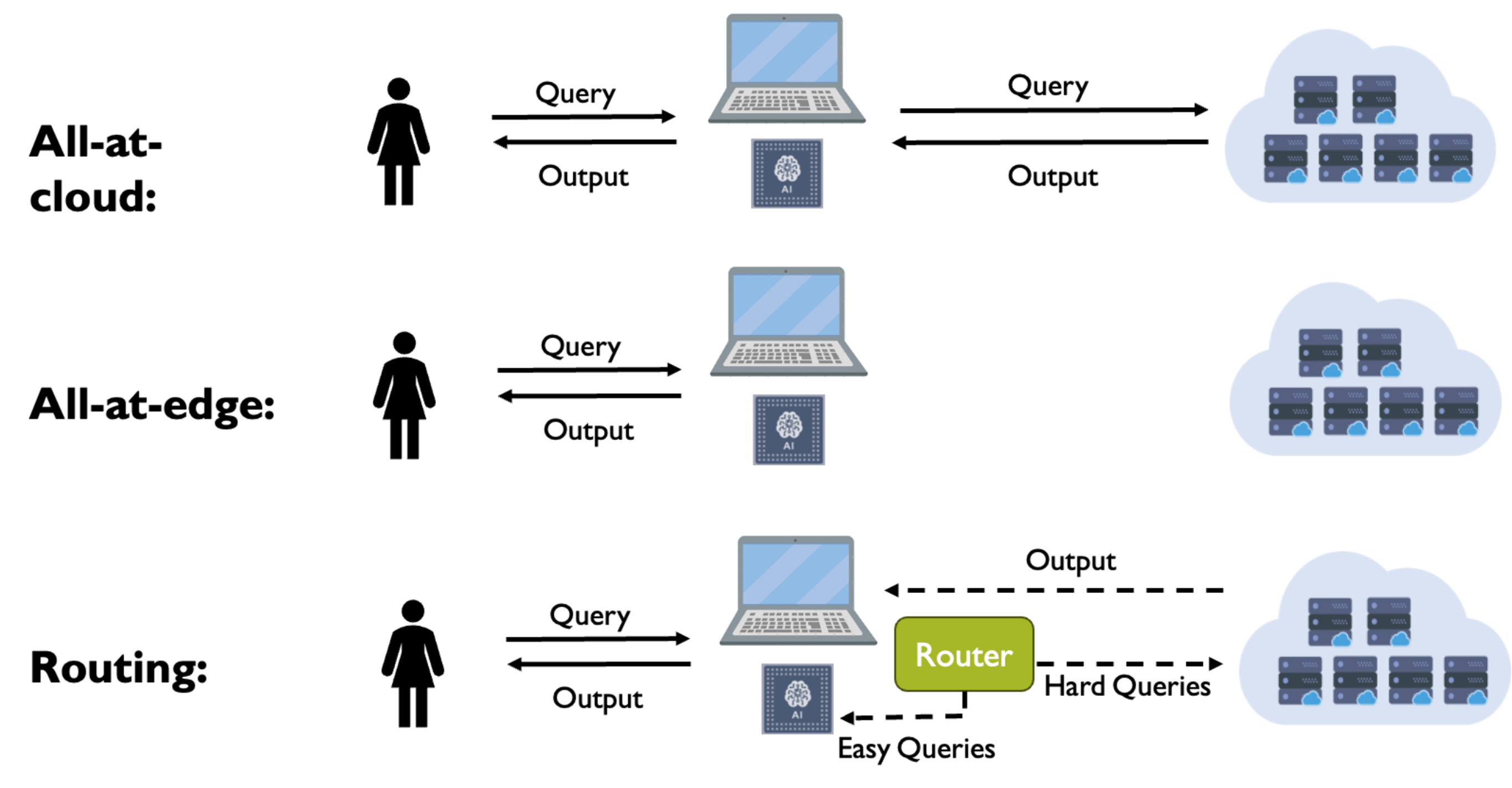
가장 직관적인 방법은 판단만을 위해 학습된 가벼운 모델을 따로 두는 것입니다. 이 모델을 Router(라우터)라고 부릅니다. Router는 최종 답변을 생성하지 않습니다. 대신 사용자의 요청을 보고 “이 요청은 작은 모델로 충분한가, 아니면 큰 모델이 필요한가”를 판단합니다. 여기서 중요한 점은 Router가 원본 언어 모델처럼 답변을 길게 생성하지 않고, 분류만 하면 됩니다.
이와 관련된 연구로는 Hybrid-LLM (Ding et al., 2024)이 있습니다. 이 연구는 작은 모델과 큰 모델의 응답 품질 차이, 즉 Quality Gap(품질 격차)를 예측합니다. 작은 모델이 큰 모델과 비슷한 품질을 낼 수 있는 요청은 작은 모델로 보내고, 차이가 클 것으로 보이는 요청은 큰 모델로 보내는 방식입니다. 연구진은 이 구조로 큰 모델 호출을 최대 40% 줄이면서 응답 품질 저하를 막을 수 있었다고 설명합니다.
비슷한 방향의 연구로 RouteLLM (Ong et al., 2024)도 있습니다. RouteLLM은 강한 모델과 약한 모델 사이에서 요청을 동적으로 나누는 Router를 학습합니다. 이때 연구진은 사람의 선호 데이터를 활용했습니다. 같은 질문에 대해 강한 모델과 약한 모델이 각각 답했을 때, 사람이 어느 쪽 답변을 더 선호했는지를 학습해 “이런 요청은 강한 모델이 더 유리하다” 또는 “이 정도 요청은 약한 모델도 충분하다”를 예측하는 방식입니다. 연구진은 일부 실험에서 응답 품질을 유지하면서 비용을 2배 이상 줄일 수 있었다고 밝혔습니다.
여기서 Router의 성능만큼 중요한 것이 얼마나 Router를 가볍게 만드느냐는 것인데요. Router 자체가 너무 무거우면, 작은 모델(sLM)을 아끼려고 또 다른 모델(Router 모델)을 실행하는 셈이 됩니다. 우리가 익히 아는 언어 모델은 토큰을 하나씩 생성하는데요. Router는 최종적으로 서버에 요청을 보낼지 / 말지 분류하는 토큰 하나만 필요합니다. 때문에 자연어 문장을 이해하고 분류할 수 있는 가벼운 언어 모델만으로도 충분합니다.
Hybrid-LLM 연구에서도 DeBERTa 기반 인코더를 Router로 사용했는데, 이 Router가 한 번의 Forward Pass만 수행하기 때문에, 계속 새롭게 토큰을 생성하는 Autoregressive Decoding 언어 모델보다 오버헤드가 작다고 설명합니다.
- Deferral
두 번째 방법은 Deferral(디퍼럴)입니다. Deferral은 작은 모델이 먼저 답변을 만들어본 뒤, 품질이 낮다고 판단하면 큰 모델로 넘기는 방식입니다. Router가 답변하기 전에 길을 정한다면, Deferral은 답변한 후에 서버에 작업을 넘길지 결정합니다. 이 구조는 LLM Cascade 계열 연구와 연결되는데요. Cascade는 말 그대로 폭포처럼 여러 모델을 단계적으로 통과시키는 구조입니다.
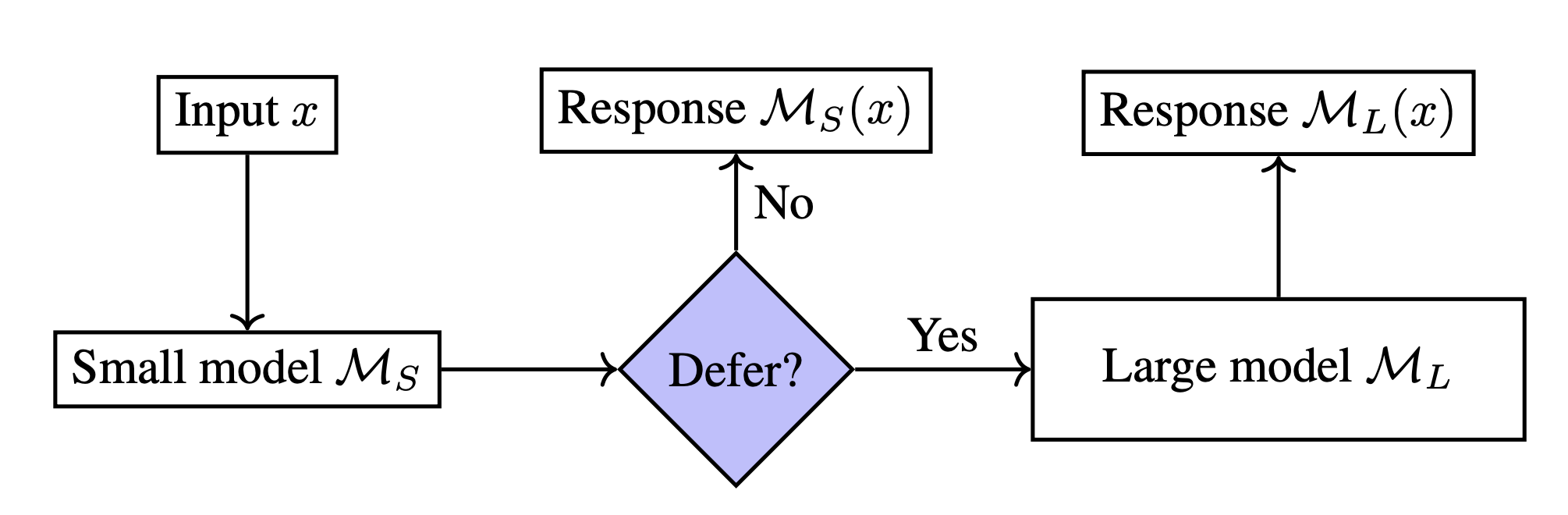
여기서 핵심은 Deferral Rule(디퍼럴 규칙)입니다. 작은 모델의 답변을 그대로 쓸지, 서버 모델로 넘길지 정하는 기준이 필요하기 때문입니다. 가장 단순한 방법은 Confidence Score(신뢰도 점수)를 보는 것입니다. 모델이 높은 신뢰도를 보이면 답변을 채택하고, 그렇지 않으면 큰 모델로 넘기는 방식입니다. 하지만 언어 모델에서는 신뢰도를 계산하는 일이 생각보다 어렵습니다. 분류 모델은 “고양이 0.9, 강아지 0.1”처럼 하나의 확률 분포를 보면 되지만, 언어 모델은 답변을 여러 토큰으로 길게 생성합니다. 답변 길이가 달라지면 전체 확률을 어떻게 합칠지도 문제가 됩니다.
이 문제를 정리한 연구가 Google Research의 <Language Model Cascades: Token-Level Uncertainty And Beyond> (Gupta et al., 2024)입니다. 이 논문은 생성형 언어 모델에서 단순한 시퀀스 수준 불확실성을 사용하면 답변 길이에 따라 판단이 왜곡될 수 있다고 지적합니다. 긴 답변은 확률을 누적하는 방식에 따라 과도하게 불리해질 수 있고, 반대로 평균을 내면 중요한 토큰의 불확실성이 묻힐 수 있습니다. 그래서 연구진은 답변 전체를 하나의 점수로 보는 대신, Token-Level Uncertainty(토큰 수준 불확실성)를 활용한 Post-Hoc Deferral Rule이 더 나은 비용-품질 균형을 만든다고 설명합니다.
쉽게 말하면 이런 차이입니다. 작은 모델이 “정답은 서울입니다”라고 답했다고 해봅시다. 이때 “정답은” 같은 표현은 매우 높은 확률로 생성할 수 있습니다. 하지만 실제로 중요한 것은 “서울”이라는 핵심 토큰입니다. 문장 전체의 평균 확률만 보면 답변이 안정적으로 보일 수 있지만, 정작 핵심 단어에서 모델이 흔들렸다면 서버 모델로 넘기는 편이 안전합니다. 그래서 Deferral 연구에서는 어떤 부분에서 신뢰도가 떨어지는지 더 중요하게 봅니다.
Apple은 어떻게 하이브리드 모델을 구성했나
이번 Apple Foundation Models 3세대에서는 지난해 5월 Apple 연구진이 제안한 <Instruction-Following Pruning(IFP)> (Hou et al., 2025)이 온디바이스 모델 방법론으로 채택됐습니다. 이 구조는 온디바이스 모델 내부에서, 요청에 따라 필요한 파라미터만 골라 사용합니다. 모델의 파라미터 크기는 20B이지만, 실질적으로 추론에 사용하는 파라미터는 3B인 것입니다.
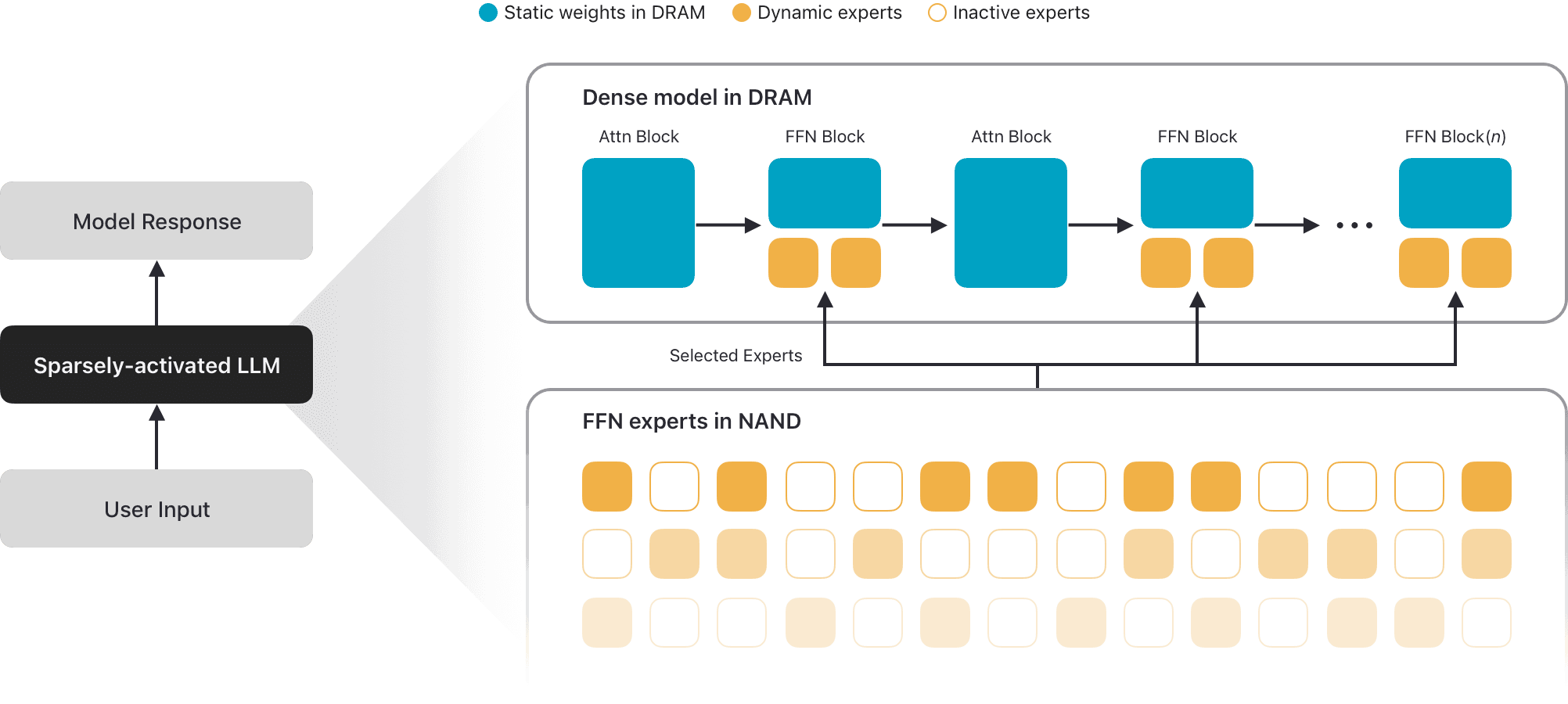
출처: Apple Machine Learning Research, Introducing the Third Generation of Apple’s Foundation Models
Apple은 AFM 3 Core Advanced가 이 구조를 사용한다고 밝혔습니다. 기존 대형 언어 모델처럼 전체 가중치를 모두 DRAM에 올리는 대신, 전체 모델은 Flash에 저장하고 요청에 필요한 일부 파라미터만 DRAM에 올립니다. 또한 NAND에서 DRAM으로 가중치를 토큰마다 바꿔 올리는 방식은 대역폭 문제 때문에 어렵기 때문에, AFM 3 Core Advanced는 토큰 단위가 아닌 Prompt 단위로 Routing Decision을 내립니다.
여기서 한 가지 구분이 필요합니다. AFM 3 Core Advanced의 IFP는 온디바이스와 서버 사이에서 요청을 나누는 Router가 아닙니다. IFP는 온디바이스 모델 내부에서 이번 요청에 필요한 Expert를 고르는 내부 라우팅 기술입니다. 반면 온디바이스 모델을 사용할지, Private Cloud Compute 모델을 사용할지는 더 상위 계층에서 결정됩니다.
다만 Apple은 이 시스템 라우터의 구체적인 판단 알고리즘을 공개하지 않았습니다. 개발자 앱에서는 Foundation Models Framework의 Dynamic Profiles와 앱 로직이 이 역할을 맡습니다. Apple Intelligence처럼 시스템 전반에서 동작하는 기능에서는 App Intents, App Toolbox, Spotlight Semantic Index, System Orchestrator가 함께 요청을 조율한다고 설명합니다. 하이브리드로 구현되는 것은 확실하지만 어떤 원리로 구현되는지 현재로서는 알 수 없습니다.
그렇다면 Apple의 서버 모델은 어떨까요? Apple이 말하는 서버 모델은 크게 두 종류로 나눠볼 수 있습니다. 첫 번째는 Apple이 직접 운영하는 Private Cloud Compute(PCC) 위의 Apple Foundation Models입니다. 두 번째는 Anthropic의 Claude, Google의 Gemini처럼 외부 기업이 운영하는 서버 기반 모델입니다. Apple은 이 둘을 모두 Foundation Models Framework 안에서 사용할 수 있도록 만들고자 합니다.
다만 여기서 개인정보와 실행 위치는 구분해서 봐야 합니다. PCC는 Apple이 개인정보 보호를 위해 설계한 전용 클라우드 실행 환경입니다. 이 기능을 요약하자면, Apple 서버에 제공된 정보는 사용자를 제외한 누구도 접근할 수 없다는 것입니다. 반면 Claude나 Gemini를 사용하는 경우, 요청은 해당 모델 제공자의 서버로 전달됩니다. 따라서 PCC와 동일한 개인정보 보호 보장이 자동으로 적용된다고 보기는 어렵습니다.
저는 이번 프랑스 파리에서 열린 VivaTech에 참석했습니다. 프랑스 현지의 모든 AI 스타트업들이 얘기하는 것이 개인 데이터 정책 규제를 준수해야 하는 상황에 대한 어려움을 토로했는데요. 우리나라와 달리 유럽에서는 AI 산업과 관련된 규제가 강하게 작동하고 있다는 것을 느꼈습니다.
이런 상황에서 온디바이스 모델은 훌륭한 대안이 될 수 있습니다. 개인 데이터를 기업의 서버에서 관리할 필요 없이 사용자의 디바이스에서 자체적으로 처리할 수 있으니까요. 그러나 아직은 온디바이스 모델로 모든 것을 추론하기 시기상조인 만큼 하이브리드는 구조는 필연적이라고 보입니다. Apple, 삼성 모두 계속 하이브리드 구조를 노리고 있는 이유일 것입니다.
하지만 서비스 레벨과 맞닿아 있는 만큼 충분한 연구가 이뤄지지 않고 있습니다. 실제로는 AI가 판단하여 Routing이 이뤄지고 있는 것이 아니라 규칙 기반으로 작동될 가능성도 높습니다. Apple이 통합된 하이브리드 시스템을 사용하며 사용자 경험을 높이려는 시도를 하고 있지만 실제로는 아직 Routing 성능에 자신이 없는 것일지도 모릅니다. 과연 이 시스템은 우리 삶을 어떻게 바꿔나가게 될까요?