
Table of Contents
1. Intro

😮 헉, 메뉴판을 읽을 수 없잖아?
해외여행 중 식당에서 메뉴판을 읽지 못해 당황한 경험이 있으신가요? 그나마 읽을 수 있는 영어 메뉴판이 얼마나 반가웠던지요. 하지만 모국어가 아닌 영어로도 메뉴를 보며 진땀을 흘리셨던 경험, 다들 한 번쯤은 있으실 겁니다. 그렇다면 반대로, 한국에 온 외국인들이 메뉴판을 보면 어떤 기분이 들까요? 아마 우리가 해외에서 낯선 문자로 된 메뉴판을 볼 때 느끼는 당혹감과 비슷할 것입니다. 특히 알레르기가 있는 사람이라면 더욱 난감할 수 있겠죠. 음식 이름조차 읽기 힘든 상황에서 알레르기 정보를 찾는 건 마치 모래에서 바늘을 찾는 것만큼 어려울 것입니다.
엔데믹 이후 증가하는 외국인 관광객, 알레르기에 불친절한 한국어 메뉴판
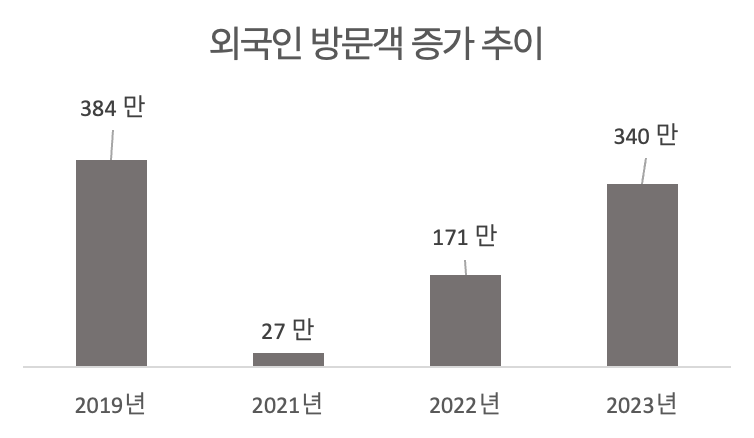
코로나19가 끝난 후, 한국을 찾는 외국인 관광객 수는 꾸준히 증가하고 있는 추세입니다. 통계에 따르면, 2019년에는 약 384만 명의 외국인 관광객이 한국을 방문했으며, 코로나로 인해 2021년에는 급감하여 27만 명으로 크게 줄어들었습니다. 그러나 2022년부터 점차 회복세를 보이며 171만 명으로 증가했고, 2023년에는 340만 명에 달하는 외국인 관광객이 한국을 찾았습니다. 외국인 방문객은 코로나 이전 수준으로 회복되었고, 앞으로도 관광객 수가 지속적으로 증가할 가능성이 큽니다.
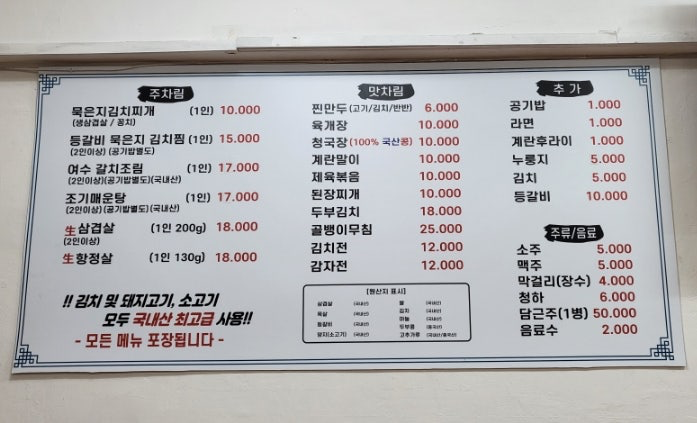
한국을 찾는 외국인 관광객 수가 증가하고 있지만, 한국 식당들이 이러한 외국인, 특히 알레르기가 있는 이들에게 얼마나 친화적일까요? 비록 많은 외국인들이 번역기를 사용해 메뉴를 읽는다 하더라도, 한국 음식의 재료나 요리법이 그들에게는 여전히 생소할 수 있습니다. 문제는 음식의 성분을 제대로 알지 못하는 상황에서, 알레르기에 대한 정보가 메뉴판에 명확하게 표시되지 않는 경우가 많다는 것입니다. 외국인들은 한국인들보다 상대적으로 알레르기에 더 민감할 수 있습니다. 따라서 메뉴에 알레르기 유발 성분이 표시되지 않으면, 외국인들에게 큰 불편 뿐만 아니라 잠재적인 건강 위험까지 초래할 수 있는데요. 예를 들어, 한국 요리에 흔히 들어가는 간장, 고추장, 해산물 등은 외국인에게 알레르기 반응을 일으킬 수 있지만, 이러한 정보가 메뉴에 표시되지 않은 경우는 많지 않습니다. 외국인들이 한국을 여행하며 겪는 문제를 해소하는데 기여하고자 한식 이미지 인식을 통한 알레르기 유발 성분 파악 및 경고 서비스를 고안했습니다.
2. Data Collection
서비스를 제공하기 위해서는 한식에 사용되는 재료, 음식을 분류할 수 있는 학습용 한식 사진, 그리고 알레르기 유발 성분에 대한 데이터가 필수적입니다. 이를 위해 저희는 농식품 빅데이터 거래소에서 제공하는 31만 개의 레시피 데이터를 활용하여 각 음식에 들어가는 재료를 분석했고, AI-Hub에서 제공하는 15만 장의 음식 사진을 이용해 한식 분류 모델을 학습시켰습니다. 또한, 식품안전처와 식품안전정보원이 제공한 알레르기 표시 제도를 참고하여 알레르기 유발 성분을 식별했습니다.
2.1. 레시피 데이터
농식품 빅데이터 거래소 : 12만 개 레시피 데이터
저희는 각 레시피에서 사용된 재료를 파악하기 위해 ‘식품 빅데이터 거래소’에서 제공된 총 31만 개의 레시피 데이터를 활용하였습니다. 아래 예시에서 보시듯이, CKG_NM 열에는 음식의 종류가, CKG_MTRL_CN 열에는 각 음식에 사용된 재료가 명시되어 있습니다.
RCP_SNO RCP_TTL CKG_NM RGTR_ID … CKG_MTRL_CN
128671 어묵김말이 어묵김말이 skfo0701 … [재료] 어묵 2개| 김밥용김 3장| 당면 1움큼| 양파 1/2개| 당근 1/2개| 깻잎 6장| 튀김가루 1컵 | 올리브유 적당량| 간장 1T| 참기름 1T
128892 두부에 꼬리가 달렸어요!!
skfo0701 … [재료] 두부 1/2모| 당근 1/2개| 고추 2개| 브로콜리 1/4개| 새우 4마리| 녹말가루| 계란 1개
128932 입안에서 톡톡톡
skfo0701 … [재료] 밥 1+1/2공기| 당근 1/4개| 치자단무지 1/2개| 신김치 1쪽| 무순 약간| 날치알 6스푼| 김가루 약간| 후리가케(또는밥이랑같은류)| 참기름 약간| 통깨 약간| 계란 노른자 2알
131871 ★현미호두죽 현미호두죽 cds1117 … [재료] 현미 4컵| 찹쌀 2컵| 호두 50g| 물 1/2컵| 소금 약간
2.2 음식사진 데이터
AI-Hub : 15만 장의 음식 사진 이미지
저희는 음식 이미지를 학습시켜 한식을 분류하기 위해 AI-Hub에서 제공하는 데이터를 활용했습니다. AI-Hub에서 제공하는 한식 데이터는 한식재단의 음식분류 및 한국인이 즐겨 먹는 음식통계를 참조하여 선정된 150종의 음식으로 구성되어 있습니다. 위 한식 150종에 대해 각 소분류별로 1,000장씩, 총 15만 장의 이미지를 다운로드하여 모델 학습에 사용했습니다.
대분류 소분류(150종)
구이 갈비구이,갈치구이,고등어구이, 곰장구이,닭갈비,더덕구이,떡갈비,불고기,삼겹살,장어구이,조개구이,황태구이,훈제오리
김치 갓김치,깍두기,나박김치,무생채, 배추김치,백김치,부추김치,열무김치,오이소박이,총각김치,파김치
떡 경단
면 막국수,물냉면,비빔냉면,수제비, 열무국수,잔치국수,짬뽕,칼국수,콩국수,라면,자장면
밥 김밥,김치볶음밥,비빔밥,새우볶음밥,알밥,잡곡밥,주먹밥,유부초밥
쌈 보쌈
국 계란국,떡국/만두국,무국,미역국, 북엇국,소고기무국,시래기국,육개장,콩나물국
나물 가지볶음,고사리나물,미역줄기볶음,숙주나물,시금치나물,애호박볶음
만두 만두
무침 고추된장무침,피리고추무침, 도토리묵,잡채,도라지무침,콩나물무침,홍어무침
볶음 건새우볶음,오징어채볶음, 감자채볶음,고추장진미채볶음, 두부김치,떡볶이, 라볶이, 멸치볶음, 소세지볶음,어묵볶음,제육볶음, 쭈꾸미볶음
음청류 수정과,식혜
찜 갈비찜, 계란찜, 김치찜, 꼬리찜, 닭볶음탕, 수육, 순대, 족발, 찜닭, 해물찜
떡 경단, 꿀떡, 송편
만두 만두
장 간장게장, 양념게장
짱아찌 깻잎장아찌
한과 약과, 약식, 한과
해물 멍게, 산낙지
회 물회, 육회

2-3. 알레르기 데이터
식품안전처, 식품안전정보원 : 알레르기 유발성분
국가 표시대상 알레르기 유발성분
미국 총 8개 품목 1)유(乳), 2)달걀, 3)생선, 4)갑각류, 5)견과류, 6)밀, 7)땅콩, 8)대두
캐나다 총 13개 품목 1)견과류(아몬드 등 9종), 2)땅콩, 3)참깨, 4)밀(라이밀 포함), 5)달걀, 6)유유, 7)대두, 8)갑각류, 9)패류, 10)어류, 11)겨자씨, 12)글루텐, 13)아황산염(10 ppm 이상)
중국 총 8개 품목 1)글루텐 함유 곡류, 2)갑각류, 3)어류, 4)난류, 5)땅콩, 6)대두, 7)유유, 8)견과류
저희는 식품안전처와 식품안전정보원이 발표한 해외 주요 국가의 알레르기 표시 제도를 참고하여, 가장 포괄적인 알레르기 유발 성분 목록을 제공하는 캐나다의 기준을 바탕으로 총 13개의 알레르기 유발 품목을 선정했습니다. 이후 이 13개 품목을 중심으로 딕셔너리 형태의 알레르기 유발 성분 데이터셋을 구축하여, 각 음식에 포함된 성분 중 알레르기를 유발할 수 있는 요소를 효과적으로 파악할 수 있도록 했습니다.
Code - 알레르기 유발요인 딕셔너리
# 알레르기 유발요인 딕셔너리
allergy = {
'견과류' : ['아몬드', '호두', '캐슈넛', '피칸', '헤이즐넛', '브라질너트', '마카다미아', '은행', '잣', '밤'],
'땅콩' : ['땅콩버터', '땅콩기름', '땅콩 가공 제품', '볶음땅콩', '땅콩가루', '땅콩'],
'참깨' : ['참깨오일', '참깨가루', '통깨', '볶음참깨', '검은깨', '참깨', '통깨물'],
'글루텐' : ['밀가루', '통밀', '세몰리나', '호밀', '보리', '귀리', '스펠트밀', '트리티케일', '에머', '파로밀',
'불가', '듀럼밀', '캄트밀', '시타니', '이스트 추출물', '맥아', '맥아 추출물', '맥아', '맥주 효모',
'밀 베이킹 파우더', '빵가루', '쿠스쿠스', '밀 전분', '밀 시럽', '수프 농축액', '양념 믹스', '샐러드 드레싱'
, '라면', '우동', '소면', '스프링롤 시트', '밀라피', '도넛', '파스타', '크래커', '비스킷', '케이크',
'머핀', '와플', '팬케이크', '프레첼', '베이글', '크루아상', '피자 도우', '피타 빵', '납작빵', '빵', '파이 크러스트',
'타르트', '튀김옷', '밀 추출물', '찹쌀가루', '호떡믹스', '부침가루', '튀김가루', '칼국수', '수제비', '냉면',
'메밀가루', '메밀면', '메밀묵', '막국수', '면', '부침가루',
'식빵', '라면', '빵가루', '빵', '부침가루', '찰보리', '보리', '밀가루풀', '밀가루', '라면스프'],
'난류' : ['달걀', '계란가루', '액란', '난백', '난황', '계란말이', '계란찜', '계란후라이'],
'우유' : ['우유', '버터', '크림', '요거트', '치즈', '마스카포네', '연유', '휘핑크림', '마가린'],
'대두' : ['콩', '두부', '된장', '간장', '에다마메', '소이밀크', '두유', '청국장', '순두부', '콩나물', '콩국물', '두부',
'콩기름호박잎', '땅콩', '된장', '콩나물', '대두콩', '두부팩', '동부콩삶은물', '콩', '검은콩', '콩기름멸치',
'간장', '집된장', '순두부', '콩기름', '콩가루'],
'갑각류' : ['새우', '게', '랍스터', '가재', '꽃게', '대하', '소금새우', '민물새우', '성게알', '게살', '멍게', '게맛살'],
'패류' : ['굴', '홍합', '전복', '조개', '바지락', '가리비', '키조개', '대합', '꼬막', '홍합', '물생굴'],
'망고' : ['망고퓨레', '건망고', '망고주스'],
'어류' : ['연어', '참치', '고등어', '대구', '정어리', '멸치', '장어', '갈치', '조기', '명태', '임연수', '우럭', '도미', '광어', '갈치', '참치액', '갈치속젓', '참치액젓'],
'아황산염' : ['건포도', '말린 과일', '와인', '식초', '맥주', '감말랭이', '곶감', '황도', '감식초'],
'겨자씨' : ['겨자소스', '머스타드', '머스타드씨앗', '겨자오일', '겨자'],
}
3. Data Preprocessing
3.1. 레시피 데이터 전처리
저희는 레시피 데이터에서 재료를 추출하기 위해 아래와 같이 전처리 과정을 거쳤습니다.
- 불필요한 공백 제거, ‘|’ 및 ‘[양념] 등 을 기준으로 재료를 분리해 ingredients_list로 저장
\[양념\]|\[향신재료\]|\[부재료\]|\[육수재료\]|\[탕수재료\]|\[양념장\]|\[소스\]|\[토핑\]|\[튀김옷 재료\]|\[녹말물 재료\]
- 숫자 앞의 ’그램’, ‘줌’, ‘마리’ 같은 단위들을 모두 제거
개|숟가락|줌|마리|컵|움큼|스푼|T|tsp|TS|ml|L|g|kg|cc|그램|그람|장|쪽|꼬집|큰술|명|마디|줌|조각|단|줄|포기|톨|스틱|팩|덩이|단위
- 재료는 대부분 한글로 기입되어 있어 숫자와 영어도 함께 제거
- 불용어 리스트 처리
'적당량', '약간', '큰술', '작은크기', '조금','작은술','각종','양념한것','작은캔','(中)','[데코레이션]','으깬것', '적당히', '좋아하는','대략', '이나', '또는','정도', '중간것', '중간크기', '사이즈','그외의','줄줄이비엔나','작은것','큰것','큰거', '썬것', '취향껏', '/', '~','+','()'
Code - 레시피 데이터 전처리
# 숫자와 뒤에 나오는 단위 패턴을 제거하는 함수
def remove_numbers_and_units(text):
# 숫자 뒤에 나오는 단위 패턴
pattern = r'\d+(개|숟가락|줌|마리|컵|움큼|스푼|T|tsp|TS|ml|L|g|kg|cc|그램|그람|장|쪽|꼬집|인분|큰술|모|개씩|명|마디|줌|조각|대|단|줄|포기||줄기|톨|스틱|팩|덩이|단위|㎖)' # ㎖ 추가함
return re.sub(pattern, '', text)
# 숫자와 영문자를 제거하는 함수
def remove_numbers_and_english(text):
return re.sub(r'[0-9a-zA-Z]', '', text)
# 공백 제거 및 '|' 또는 '[양념]'을 기준으로 split
def split_ingredients(ingredient):
# '|' 또는 '[양념]'을 기준으로 split
ingredient = ingredient.replace(" ", "")
return re.split(r'||\[양념\]|\[향신재료\]|\[부재료\]|\[육수재료\]|\[탕수재료\]|\[양념장\]|\[소스\]|\[토핑\]|\[튀김옷 재료\]|\[녹말물 재료\]', ingredient)
###
# 공백 제거 후 '|' 또는 '[양념]' 기준으로 split 적용
recipe['ingredients_cleaned'] = recipe['ingredients'].apply(split_ingredients)
# 각 재료 리스트에서 숫자 뒤 단위 제거 적용
recipe['ingredients_cleaned'] = recipe['ingredients_cleaned'].apply(
lambda ingredients_list: [remove_numbers_and_units(ingredient) for ingredient in ingredients_list]
)
# 각 재료 리스트에서 숫자와 영문 제거 적용
recipe['ingredients_cleaned'] = recipe['ingredients_cleaned'].apply(
lambda ingredients_list: [remove_numbers_and_english(ingredient) for ingredient in ingredients_list]
)
recipe# 불용어 리스트 정의 (제거하고 싶은 단어들)
stopwords = ['적당량', '약간', '큰술', '작은크기', '조금','작은술','각종','양념한것','작은캔','(中)','[데코레이션]','으깬것', '적당히', '좋아하는','대략','넉넉히', '만큼', '숟갈','티스푼',
'이나', '또는','정도', '중간것','아주', '씩', '중간크기', '사이즈','그외의','잘게','각','썬','잘게썬','껍질을깐', '껍질깐', '줄줄이비엔나','작은거', '작은것','큰것','큰거', '썬것', '취향껏', '/','%', '~','+','()','.']
# 함수: 불용어를 제거
def clean_ingredient(ingredient):
# 정규 표현식을 사용하여 [재료]와 관련된 모든 패턴을 제거
ingredient = re.sub(r'\[재료]', '', ingredient)
# 불용어를 제거하기 위해 각 단어를 확인
for word in stopwords:
# 불용어를 단어 경계 기준으로 제거
ingredient = re.sub(re.escape(word), '', ingredient)
# 추가 공백 정리
ingredient = ingredient.strip()
return ingredient
# 리스트 내의 모든 재료에 함수 적용
recipe['ingredients_cleaned'] = recipe['ingredients_cleaned'].apply(
lambda ingredients_list: [clean_ingredient(ingredient) for ingredient in ingredients_list]
)3.2. 일반화된 재료 추출
다양한 이름의 동일한 재료들을 일관된 표현으로 변환했습니다. 예를 들어 다진마늘, 깐마늘,마늘 슬라이스, 마늘 조각 을 마늘로 나타냈습니다. 또한, 재료 변환 규칙을 딕셔너리로 만들어 관리를 용이하게 했습니다.
Code - 재료변환규칙 딕셔너리
# 재료 변환 규칙
replacements = {
r'.*솔트.*': '소금',
r'.*소금.*': '소금',
r'.*설탕.*': '설탕',
r'.*마늘.*': '마늘',
r'.*양파.*': '양파',
r'.*어묵.*': '어묵',
r'.*단무지.*': '단무지',
r'.*간장.*': '간장',
r'.*고추장.*': '고추장',
r'.*고추.*': '고추',
r'.*닭.*': '닭',
r'.*돼지.*': '돼지',
r'.*소고기.*': '소고기',
r'.*파프리카.*':'파프리카',
r'.*버섯.*': '버섯',
r'.*배추.*': '배추',
r'.*시금치.*': '시금치',
r'.*오이.*': '오이',
r'.*고구마.*': '고구마',
r'.*계란.*': '달걀',
r'.*달걀.*': '달걀',
r'.*쌀.*': '쌀',
r'.*굴소스.*': '굴소스',
r'두부모' : '두부',
r'다진파' : '대파',
r'대파.*' : '대파',
r'.*김치.*' : '김치',
r'.*오징어.*' : '오징어',
r'.*치즈.*' : '치즈',
r'.*새우.*' : '새우',
r'.*고등어.*' : '고등어',
r'.*물엿.*' : '물엿',
r'.*참기름.*' : '참기름',
r'.*멍게.*' : '멍게',
r'.*소주.*' : '소주',
r'.*쇠고기.*' : '소고기',
r'.*밥.*' : '밥',
r'.*콩나물.*' : '콩나물',
r'.*파인애플.*' : '파인애플',
r'.*매실.*' : '매실',
r'.*갈치.*': '갈치',
r'.*조기.*': '조기',
r'.*후춧가루.*': '후추',
r'.*후추가루.*': '후추',
r'.*라면.*': '라면',
r'.*쫄면사리.*': '쫄면',
r'.*삼겹살.*': '돼지',
r'.*메밀국수.*': '메밀면',
r'.*막국수.*': '메밀면',
r'.*머스타드.*': '머스타드',
r'.*빵.*': '빵',
r'.*땅콩.*': '땅콩',
r'.*멸치.*': '멸치',
r'.*참깨.*': '참깨',
r'.*통깨.*': '통깨',
r'.*새우.*': '새우',
r'.*우유.*': '우유',
r'.*참치.*': '참치',
r'.*참기름.*': '참기름',
r'.*겨자.*': '겨자',
r'.*메주콩.*': '콩',
r'.*두부.*': '두부',
r'.*간장.*': '간장',
r'다진': '',
r'다진것': '',
r'다진거':'',
r'깐' : '',
r'아무부위나': '',
r'\(선택\)' : '',
r'\(반죽용\)' : '',
r'\(육수용\)' : '',
r'\(차밀풀용\)' : '',
r'\(크기는취향대로\)' : '',
r'\?' : '', # '?' 문자 이스케이프 처리
r'\(생략가능\)' : '', # '()' 문자 이스케이프 처리
r'\[.*\]' : '' # '[]' 문자 이스케이프 처리
}
# 변환 규칙을 적용하는 함수
def replace_patterns(ingredient):
for pattern, replacement in replacements.items():
ingredient = re.sub(pattern, replacement, ingredient)
return ingredient
# 전체 재료에 변환 규칙 적용
recipe['ingredients_cleaned2'] = recipe['ingredients_cleaned'].apply(
lambda ingredients_list: [replace_patterns(ingredient) for ingredient in ingredients_list]
)3.3. 레시피 보완
150종의 한식 이미지에 대응하는 레이블 중, 일부 레시피 데이터에서 누락된 음식 3가지가 있었습니다. 이 음식들은 후라이드 치킨, 꼬리찜, 산낙지로, 일반적으로 활용되는 레시피로 해당 레시피를 추가하여 데이터 보완을 진행했습니다.
Code - 레시피 보완
new_recipe = pd.DataFrame(columns=['dish', 'ingredients_cleaned2'])
new_recipe['dish'] = ['후라이드 치킨', '꼬리찜', '산낙지']
new_recipe['ingredients_cleaned2'] = [['닭', '튀김가루','우유','식용유'],['소', '버섯', '당근', '무', '대추', '물', '고추', '간장', '양파', '청양고추',
'청주', '설탕', '참기름', '깨소금', '마늘', '후추' ], ['낙지', '대파', '식용유','고춧가루','설탕','마늘','양파','간장','맛술']]3.4. 최종 레시피 추출
저희는 레시피 데이터에서 음식 재료를 추출하여, 각 음식과 알레르기 유발 성분을 매핑한 데이터셋을 구축하고자 했습니다. 그러나 레시피 데이터는 사용자 개인의 주관적인 요리 방식과 성향이 반영된 경우가 많았고, 동일한 요리라도 재료가 조금씩 다르거나, ‘쌀’을 ‘밥’ 으로 표기하는 등 같은 재료를 다르게 표기하는 경우가 많았습니다. 또한 일부 레시피에서는 전혀 다른 요리의 재료가 혼재된 사례가 발견되었습니다. 예를 들어, 육회 재료에 와인이 들어가거나, 숙주나물 레시피에 해산물이 포함되는 경우가 있었습니다.
이러한 특성으로 인해, 모든 레시피를 통합하는 것이 적절한지 고민하게 되었습니다. 데이터를 검토하면서 각 레시피의 유사성을 분석한 결과, 여러 레시피의 교집합을 추출하기보다는 가장 많이 사용된 재료를 기준으로 선별하고, 이를 수작업으로 보완하는 방식이 더 효율적이라는 결론에 도달했습니다.
처음에는 동일한 음식의 여러 레시피를 통합하는 방식을 시도했지만, 일정 수준 이상의 데이터 전처리 작업을 진행한 이후에는 의미 있는 결과를 도출하기보다는 전처리 과정의 비효율성이 두드러졌습니다. 이에 데이터를 분석하면서 직접 수정을 해야 할 필요성을 깨닫게 되었고, 각 음식에서 가장 많은 재료를 포함한(길이가 가장 긴) 레시피 하나를 선택한 후 이를 기반으로 추가적인 보완 작업을 진행해봤습니다.
음식별 가장 많은 재료를 포함한 레시피를 선택하여 알레르기를 추출해보았지만, 해당 음식에 일반적으로 포함되지 않는 특이한 재료도 다수 포함되어 알레르기 범위가 훨씬 광범위하게 추출되는 문제점을 발견했습니다. 또한 가지고 있는 다양한 레시피 데이터셋을 효과적으로 활용하지 못하는 방법이었습니다.
따라서 저희는 각 음식별 레시피에서 특정 비율 이상으로 들어간 재료만을 추출했습니다. 위 방식을 적용한다면, 주재료는 대부분 추출될 것이며 개인의 취향이 반영된 일반적이지 않은 재료는 자동적으로 필터링될 것으로 예상했습니다. 따라서 저희는 위 비율을 설정하여 레시피를 추출해보는 과정을 거쳤습니다. 그 결과 각 음식별 50% 이상 포함된 재료들만 추출할 시에, 콩국수에 두부와 콩, 파전에 부침가루, 만두국에 만두, 미역국에 미역, 북엇국에 북어, 도토리묵에 도토리가루 등 주재료가 추출되지 않는 문제점이 나타났습니다.
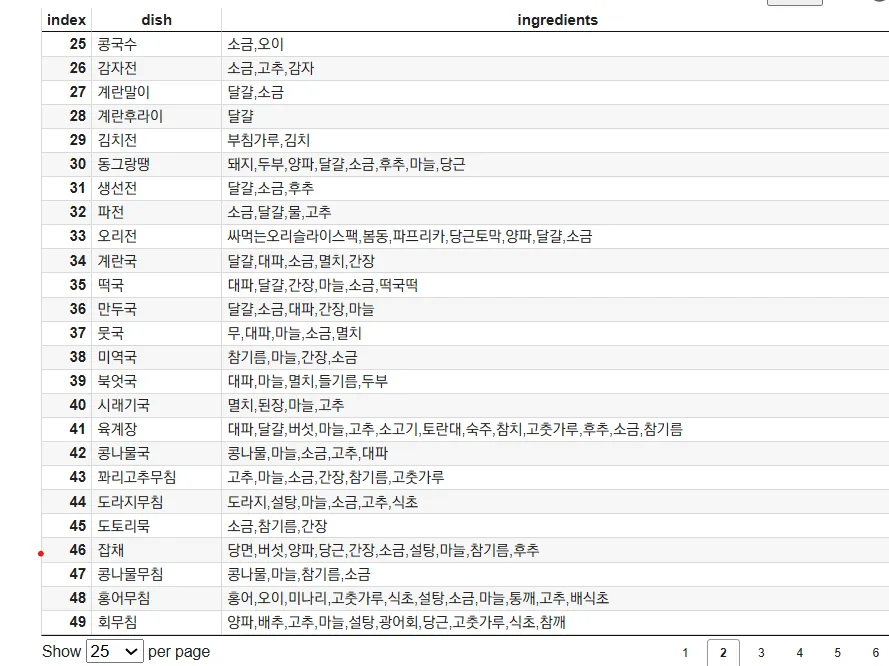
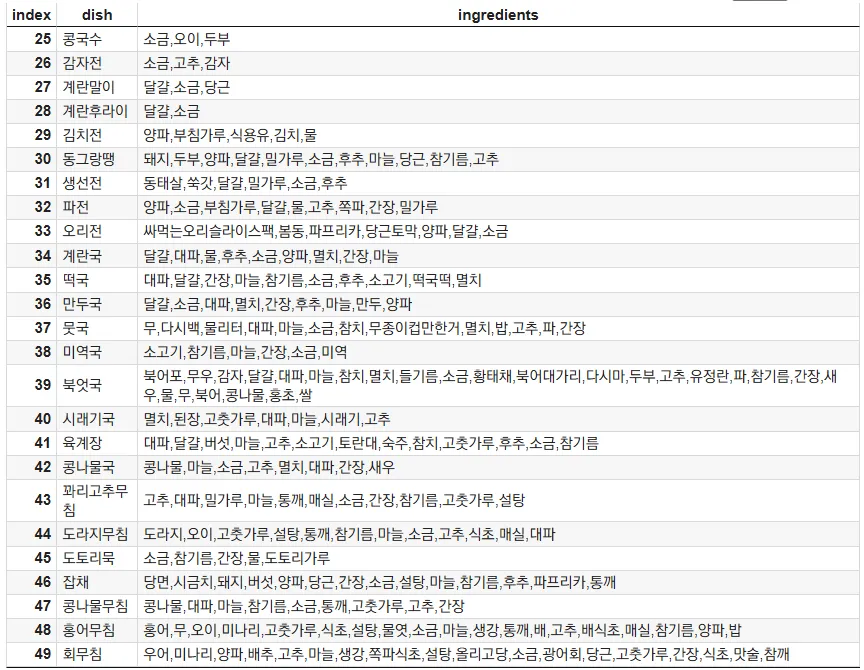
따라서 최종적으로 각 음식별로 레시피의 30% 이상 포함된 재료들만 추출하는 방식을 통해 주재료를 효과적으로 추출하고, 다양한 재료가 충분히 반영되도록 했습니다. 이를 통해 음식별로 중요한 재료가 적절하게 반영되고, 알레르기 유발 요인을 보다 정확하게 판단할 수 있는 기반을 마련했습니다.
Code - 30% 이상 등장하는 재료 추출
import ast
def extract_frequent_ingredients_corrected(recipe_all, threshold=0.3):
dish_ingredients = {}
for dish in recipe_all['dish'].unique():
dish_df = recipe_all[recipe_all['dish'] == dish]
ingredient_counts = {}
total_rows = len(dish_df)
for ingredients_list in dish_df['ingredients_cleaned']:
if isinstance(ingredients_list, str):
ingredients_list = ast.literal_eval(ingredients_list)
for ingredient in ingredients_list:
if ingredient not in ingredient_counts:
ingredient_counts[ingredient] = 0
ingredient_counts[ingredient] += 1
threshold_count = total_rows * threshold
frequent_ingredients = [ingredient for ingredient, count in ingredient_counts.items() if count >= threshold_count]
dish_ingredients[dish] = frequent_ingredients
return dish_ingredients
즉, NLP 기반의 전처리와 직접적인 데이터 수정을 병행하여, 최종적으로 음식과 알레르기 유발 성분이 맵핑된 데이터셋을 완성했습니다. 아래는 음식과 알레르기 유발 성분을 맵핑한 데이터셋의 일부입니다.
음식 알러지원
약과 글루텐
만두 아황산염, 난류, 참깨, 대두
육회 아황산염, 견과류, 참깨, 난류, 대두
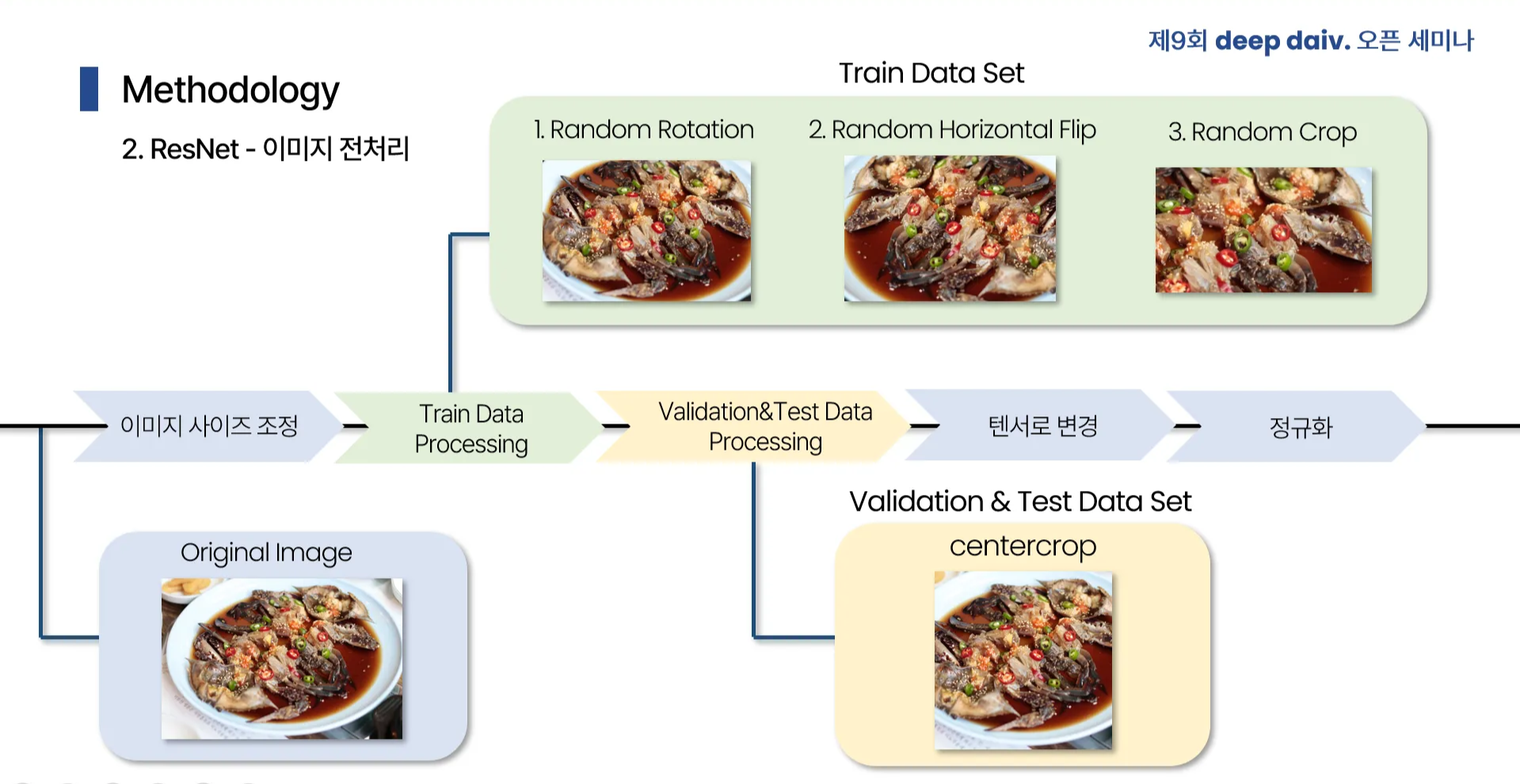
3.5. 음식 사진 데이터 전처리
3.5.1. Data Validation
본격적인 데이터 전처리 이전에 수집한 이미지가 정상적인지 검증하는 과정을 거쳤습니다. 다음의 오류가 있는 이미지를 제거하여 정상적인 이미지만 추려냈습니다.
- IOError: 파일이 손상되었거나, 접근이 불가능한 오류
- SyntaxError: 이미지 파일 형식에 맞지 않는 데이터가 포함된 오류
- UnidentifiedImageError: Pillow 라이브러리가 이미지 파일을 인식할 수 없는 오류
3.5.2. Train/Test/Validation Data Split
Train data와 Test data를 각각 8:2의 비율로 분할하고, Train data의 10%를 Validation data로 따로 분리하여 사용했습니다.
3.5.3. Train Data Preprocessing
Data Augmentation을 포함한 전처리를 진행하여 학습 시 과적합을 방지하고 모델이 다양한 입력 데이터에 잘 대응할 수 있게 했습니다.
- Resize: 모델에 필요한 입력 크기에 맞춰 이미지를 변환합니다.
- RandomRotation: 이미지를 무작위로 회전시킵니다.
- RandomHorizontalFlip: 이미지를 수평으로 무작위로 반전시킵니다.
- RandomCrop: 무작위로 일부분을 잘라냅니다.
- ToTensor: 모델이 데이터를 처리할 수 있도록 이미지를 텐서 형태로 변환합니다.
- Normalize: 입력 데이터의 범위를 표준화하여 모델이 안정적으로 학습할 수 있도록 도와줍니다.
3.5.4. Test/validation data preprocessing
모델에 적합한 형태로 이미지를 변환하여 일관된 결과를 얻도록 돕습니다.
- Resize: 모델에 필요한 입력 크기에 맞춰 이미지를 변환합니다.
- CenterCrop: 정보 손실을 줄이기 위해 중앙 부분을 잘라서 왜곡된 부분을 줄입니다.
- ToTensor: 모델이 데이터를 처리할 수 있도록 이미지를 텐서 형태로 변환합니다.
- Normalize: 입력 데이터의 범위를 표준화하여 모델이 안정적으로 학습할 수 있도록 도와줍니다.
4. ResNet Fine-Tunning
4.1. What is ResNet?
ResNet은 2015년 ILSVRC(Image Large Scale Visual REcognition challenge) 대회에서 우승한 합성곱 신경망(Convolution Layer) 모델입니다. image classification 분야에서 최초로 사람의 이미지 분류 성능을 이겼다는 데에 큰 의미가 있습니다. 모델 구조는 152개의 두터운 계층으로 구성되어 있고 계층 수가 많을 수 있는 이유는 Residual Learning (잔차 학습) Framework 때문입니다. 이는 레이어에 입력값을 그대로 건내주는 연산을 의미하며, 기존의 layer에 입력값을 건내주는 연산이 추가됩니다.
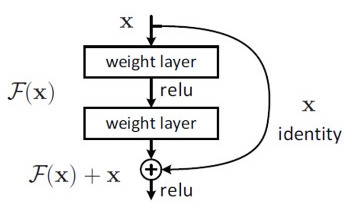
위 그림과 같이 두 개의 Convolution Layer & 한개의 ReLu 함수에 대한 연산()을 하나의 identity()으로 연산하는 과정을 보입니다. 이는 덧셈 연산 이외에는 추가적인 연산 증가가 없습니다. 또한 곱셉이 아닌 덧셈 연산을 통해 foward, backward 연산이 단순화 되며 기울기 소실 문제를 해결합니다. 이처럼 계산이 단순하고 추가적인 parameter를 요하지 않는 계산 방식이 Resnet에 적용되었기에 많은 Layer를 쌓을 수 있습니다.
4.2. Model Training
4.2.1. Learning Rate by Model Layer
Base_LR = 0.001
params = [,,,,,,모델의 각 레이어별로 더 깊은 레이어일수록 Learning rate를 높게 설정합니다. 초기 레이어는 이미지의 얕은 특징을 추출하므로 Learning rate가 낮고, 마지막 레이어로 갈수록 Learning rate를 높여 모델이 더 깊은 특징을 원활하게 학습할 수 있도록 합니다.
FYI.Layers of Resnet50
```plain text ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): Bottleneck( (conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer2): Sequential( (0): Bottleneck( (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer3): Sequential( (0): Bottleneck( (conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (3): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (4): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (5): Bottleneck( (conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (layer4): Sequential( (0): Bottleneck( (conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) (2): Bottleneck( (conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=2048, out_features=1000, bias=True) )
### 4.2.2. Learning scheduler&Optimizer
> **OneCycleLR**
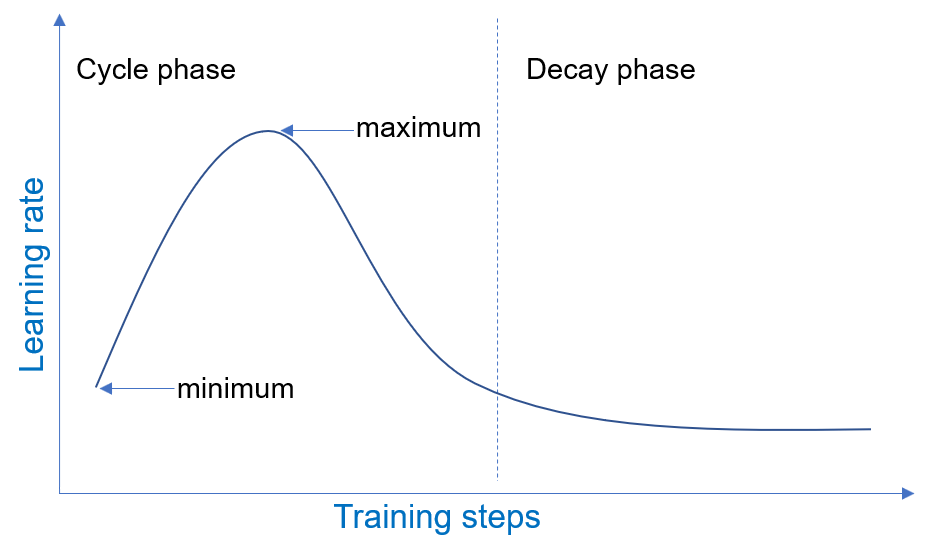
학습 초기에는 Learning rate를 작은 값에서 시작하여 점차적으로 증가시켜 모델이 안정적으로 훈련을 시작할 수 있도록 합니다. 학습 중반 이후에는 학습률을 감소시켜 과도한 학습률로 인해 발산을 방지합니다.
> **Adam **
$$
\begin
m_t &= \beta_1 m_ + (1 - \beta_1) g_t \\
v_t &= \beta_2 v_ + (1 - \beta_2) g_t^2
\end
$$
모멘텀과 적응형 학습률을 결합하여, 각 파라미터마다 적절한 Learning rate를 자동으로 조정합니다.
Adam이 각 파라미터의 업데이트를 적응형으로 조정하는 동안, OneCycleLR은 전체 Learning rate의 주기적 변화를 통해 학습의 초기 탐색과 후반부 세밀한 조정을 돕습니다.
초기 단계에서 OneCycleLR은 Learning rate를 증가시켜 빠른 탐색을 가능하게 하고, 후반부에서 Learning rate를 감소시키면서 Adam의 적응형 특성을 활용해 정확하게 수렴하도록 만듭니다.
> **Training sequence**
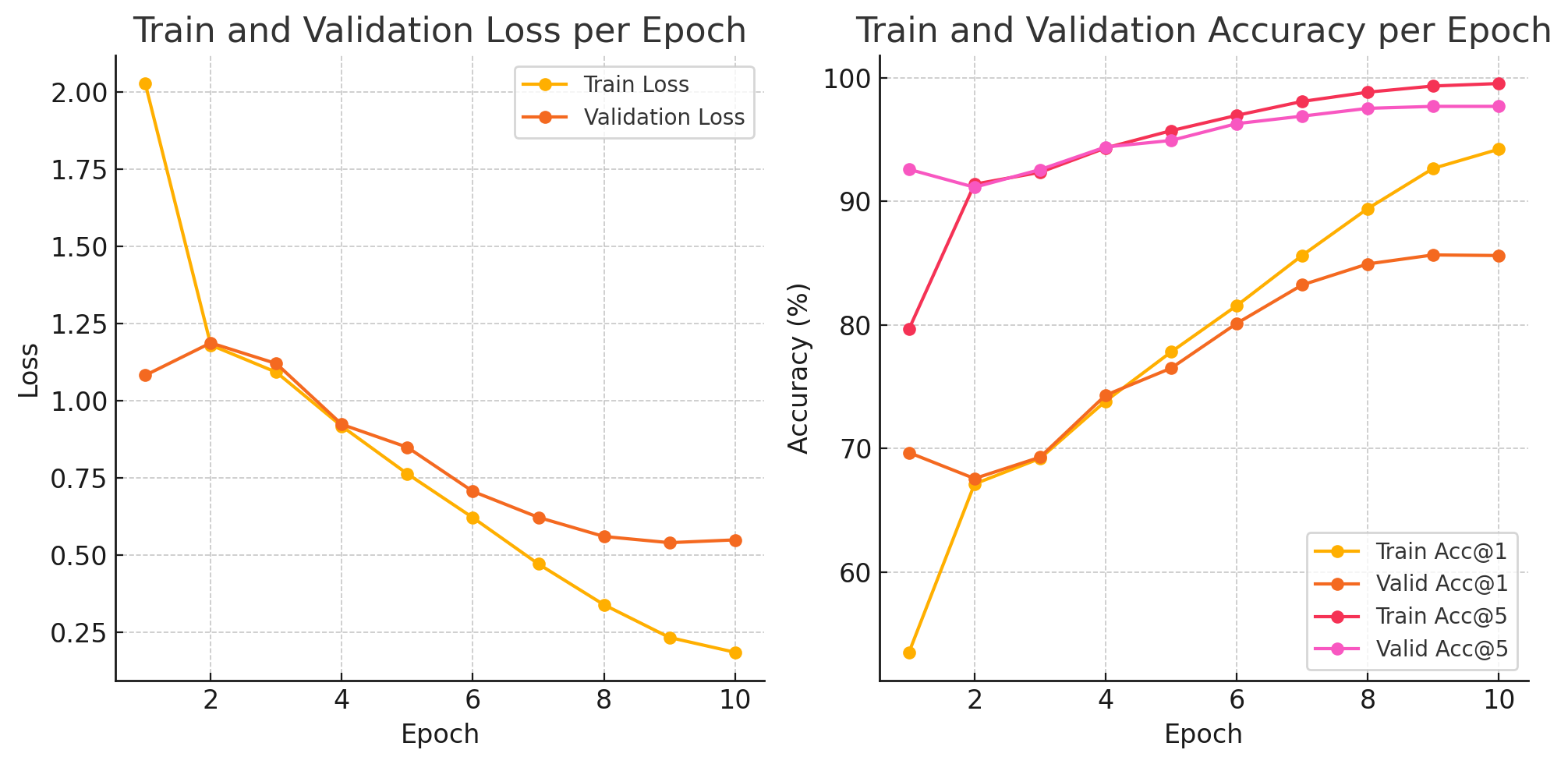
배치 사이즈를 64로, CrossEntropyLoss를 사용하여 학습을 진행합니다.
훈련이 진행되는 동안 Train data와 Validation data 각각의 Accuracy를 확인하며 Train Accuracy는 높아지면서 Validation Accuracy가 낮아지는 순간에 학습을 종료하여 Overfitting을 방지합니다.
## 4.3. Result
---
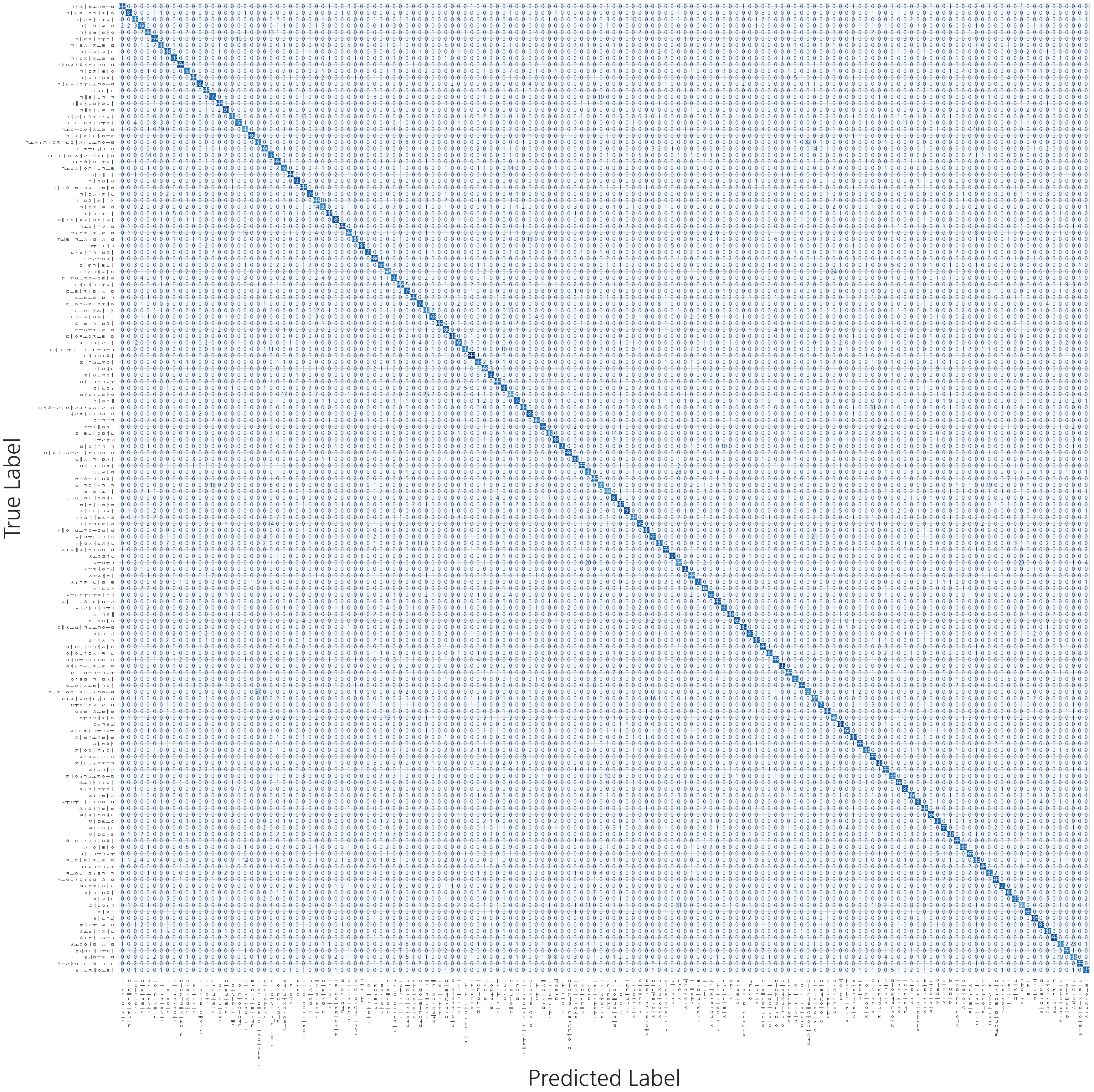
> **Test Loss: 0.500 | Test Acc top1: 86.79% | Test Acc top5: 97.86%**
# 5. Model application
## What is Gradio?
Gradio란, Python 코드와 머신러닝 모델을 사용자가 직관적으로 사용할 수 있는 웹 애플리케이션 형태로 제공할 수 있습니다. 간단하게 웹 인터페이스를 생성하거나 모델을 실시간으로 테스트하고, 특히 서버에 호스팅하여 다른 사람들과 쉽게 배포할 수 있습니다.

Gradio는 상위 클래스 `Interface`로 구성되며, 클래스 `Interface`를 이용해 python 함수와 모델에 대한 GUI를 생성합니다. 클래스`Interface`의 필수매개변수는 `fn`, `inputs`, `outputs` 3가지 매개변수로 구성됩니다.
- 매개변수1 : `fn` : Gradio 인터페이스로 래핑한 임의의 함수 또는 모델
- 매개변수2 : `inputs` : 입력 구성 요소의 유형 ex) text, image, mic, …
- 매개변수3 : `outputs` : 출력 구성 요소의 유형 ex) text, image, mic, …app = gr.Interface(fn=user_greeting, inputs="text", outputs="text") app.launch()
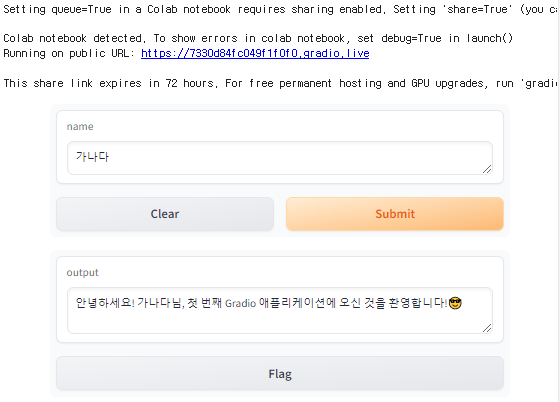
아래와 같이, python 코드를 시각화하여 서비스를 배포하는 목적에서 Gradio를 이용했습니다.

### Code - Gradio 실행 코드 <내가 주문한 음식, 안심하고 먹어도 괜찮을까>allergy_list = ['갑각류', '겨자씨', '견과류', '글루텐', '난류', '대두', '땅콩', '망고', '아황산염', '어류', '우유', '참깨', '패류']
def normalize_unicode(s): # 유니코드 정규화를 사용해 문자열을 표준화 return unicodedata.normalize('NFC', s)
알레르기 이미지를 보여주는 함수
def get_allergy_images(allergy_info): image_paths = [] image_folder = "/content/drive/MyDrive/daiv./_사각김밥/image" # 이미지가 저장된 폴더 경로
# 모든 알레르기에 대해 이미지를 선택 for allergy in allergy_list: # 알레르기 성분이 포함된 경우 컬러 이미지, 그렇지 않으면 흑백 이미지 선택 if allergy in allergy_info: img_path = os.path.join(image_folder, f"_color.png") else: img_path = os.path.join(image_folder, f"_uncolor.png")
# 이미지가 존재하는지 확인 후 리스트에 추가 if os.path.exists(img_path): image_paths.append(img_path)
return image_paths
def predict(image): try: # 입력 이미지가 None인지 확인 if image is None: print(f"Image type:") print(f"Predicted class:")
return "Error: No image captured from webcam.", []
# Gradio 웹캠 이미지가 numpy array로 올 수 있으므로 PIL 이미지로 변환 if isinstance(image, np.ndarray): image = Image.fromarray(image)
# 이미지 전처리 img_tensor = preprocess(image).unsqueeze(0) img_tensor = img_tensor.to(device)
# 이미지 분류 with torch.no_grad(): outputs = model(img_tensor)
# 예측된 클래스 인덱스 _, predicted = outputs.max(1) class_idx = predicted.item()
# 클래스 이름 매핑 및 유니코드 정규화 predicted_class_name = classes[class_idx].strip().lower() predicted_class_name = normalize_unicode(predicted_class_name)
# 알러지 정보 조회 df_allergy['dish'] = df_allergy['dish'].apply(normalize_unicode) allergy_info = df_allergy[df_allergy['dish'] == predicted_class_name]['allergy'].values
if len(allergy_info) > 0: allergy_info = allergy_info[0] else: allergy_info = "No allergy"
# 알레르기 정보에 따라 이미지를 선택 allergy_images = get_allergy_images(allergy_info)
return f"Predicted Class:\nAllergy Info:", allergy_images
except Exception as e: return f"Error:", []
interface = gr.Interface( fn=predict, # 예측 함수 inputs=gr.Image(type='pil'), # PIL 이미지 입력 outputs=[gr.Textbox(label="Prediction and Allergy Info"), gr .Gallery(label="Allergy Images")], # 텍스트 및 이미지 출력 title="내가 주문한 음식, 안심하고 먹어도 괜찮을까" # UI 제목 )
interface.launch(share=True)
# 6. Conclusion
## 6.1. Conclusion
---
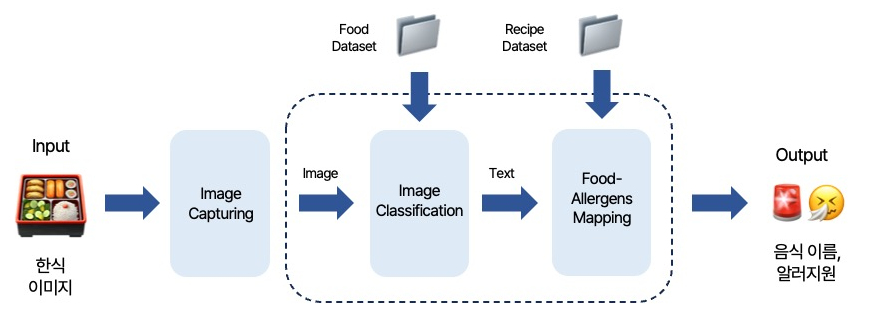
저희는 한식 이미지를 입력받으면, 이를 기반으로 **3단계의 과정**을 거쳐 알레르기 정보를 제공하는 서비스를 구축했습니다. 먼저, 1) 입력된 **이미지 캡처**(Image Capture)한 후, 2) 사전 학습된 ResNet 모델을 기반으로 **이미지 분류**(Image Classification)를 진행합니다. 이미지 분류를 통해 음식의 레이블이 결정되면, 3) **음식과 알레르기 유발 성분이 매핑**(Food-Allergens Mapping)된 데이터를 바탕으로 해당 음식에 포함된 알레르기 유발 성분을 출력하는 서비스를 제공합니다. 이 과정을 통해 사용자는 자신이 먹고자 하는 음식에 어떤 알레르기 유발 성분이 있는지 쉽게 확인할 수 있으며, 보다 안전한 식사를 할 수 있게 됩니다.
## 6.2. Limitation
---
- 하나의 음식만 분류 가능
현재 모델은 하나의 음식만 분류할 수 있기 때문에, 여러 종류의 음식이 있을 경우 각 음식을 하나씩 따로 촬영해 알레르기 유발 성분을 검출해야 하는 한계가 있습니다. 이를 개선하기 위해, Image Classification 대신 Object Detection 모델을 활용한다면 하나의 사진에서 여러 음식을 탐지하고, 각 음식에 대한 알레르기 정보를 동시에 검출할 수 있을 것입니다.
- 데이터 편향
데이터셋에서 음식별 레시피 수가 상이하여 데이터 불균형이 존재했습니다. 또한, 데이터 특성 상 개인이 등록한 레시피이다 보니 동일한 재료를 다르게 표기하거나 오탈자가 발생한 경우가 많았습니다. 이러한 오류를 최소화하기 위해 데이터 전처리 과정을 다르게 하거나 보완된 데이터를 다룬다면 레시피 추출이 더 효율적으로 이루어질 것입니다.
- 컴퓨팅 자원 부족
AIhub 한식이미지 1.5TB, 16GB 두가지 데이터셋 중 더적은 용량의 16GB의 데이터셋을 사용했습니다. 만약 GPU 성능과 학습시간이 충분했다면, 1.5TB의 데이터를 사용해 더 많은 한식 레이블과 이미지를 학습시켜 보다 정교한 모델을 구현할 수 있으리라 생각합니다.
---