
01 Motivation
오늘 방문할 식당과 카페를 정하는 건 항상 어려운 일이죠. 방문할 장소를 결정할 때 어떤 종류의 음식을 파는지뿐만 아니라 그 가게의 분위기, 청결도 등 다양한 요소를 고려하기 때문입니다. 이렇게 선택지가 너무 많다 보니 어떤 가게에 가야 할지 쉽게 고르지 못합니다. 그래서 저희는 사용자의 공간 선호도에 따라 식당과 카페 조합을 제공하는 추천 알고리즘을 제안하고자 합니다. 한정된 시간 상 지역을 선정하여 가게를 추천하는 게 좋겠다고 판단했고, 여러 상권을 찾아봤습니다. 서울에는 다양한 관광지와 문화 공간이 있지만, 사람들은 특정 지역만 반복해서 찾는 경향이 있습니다. 그러다 보니 인기 있는 몇몇 지역만 계속해서 혼잡해지고, 그 외 지역의 매력은 잘 알려지지 않은 채 묻혀 있는 경우가 많죠. 예를 들어, 영등포구 선유도역 상권은 서울시 로컬브랜드 육성 산업에 선정될 만큼 매력적인 상권임에도 아직 잘 알려지지 않습니다. 홍대, 명동처럼 전통적으로 인기 있는 상권은 아니지만 최근 마케팅에 힘쓰고 있음에 주목하여 타깃 상권으로 결정했습니다. 프로젝트를 통해 사용자들에게 참신한 장소를 추천해 줄 뿐만 아니라 지역 골목상권의 활성화를 돕고자 합니다.
02 Recommender Systems
개요
인스타그램이나 유튜브를 사용하면서 “알고리즘에 점령당했다”라고 느껴본 적 있으신가요? 내가 좋아할 만한 콘텐츠를 추천해 주는 여러 플랫폼들에 나도 모르게 시간을 뺏긴 적이 한 번씩은 있으실 겁니다. 그 외에도 넷플릭스, 멜론, 쿠팡 등 다양한 서비스가 소비자에게 콘텐츠나 제품을 추천하는데요. 이렇게 우리의 일상에 이미 자연스레 자리하고 있는 추천시스템은 알고리즘을 통해 유저가 관심을 가질 만한 상품이나 콘텐츠를 제안하는 기술입니다. 유저의 특성을 파악하여 해당 유저가 좋아할 만한 것을 추천하는데, 대표적인 필터링 방법 두 가지를 소개하고자 합니다.
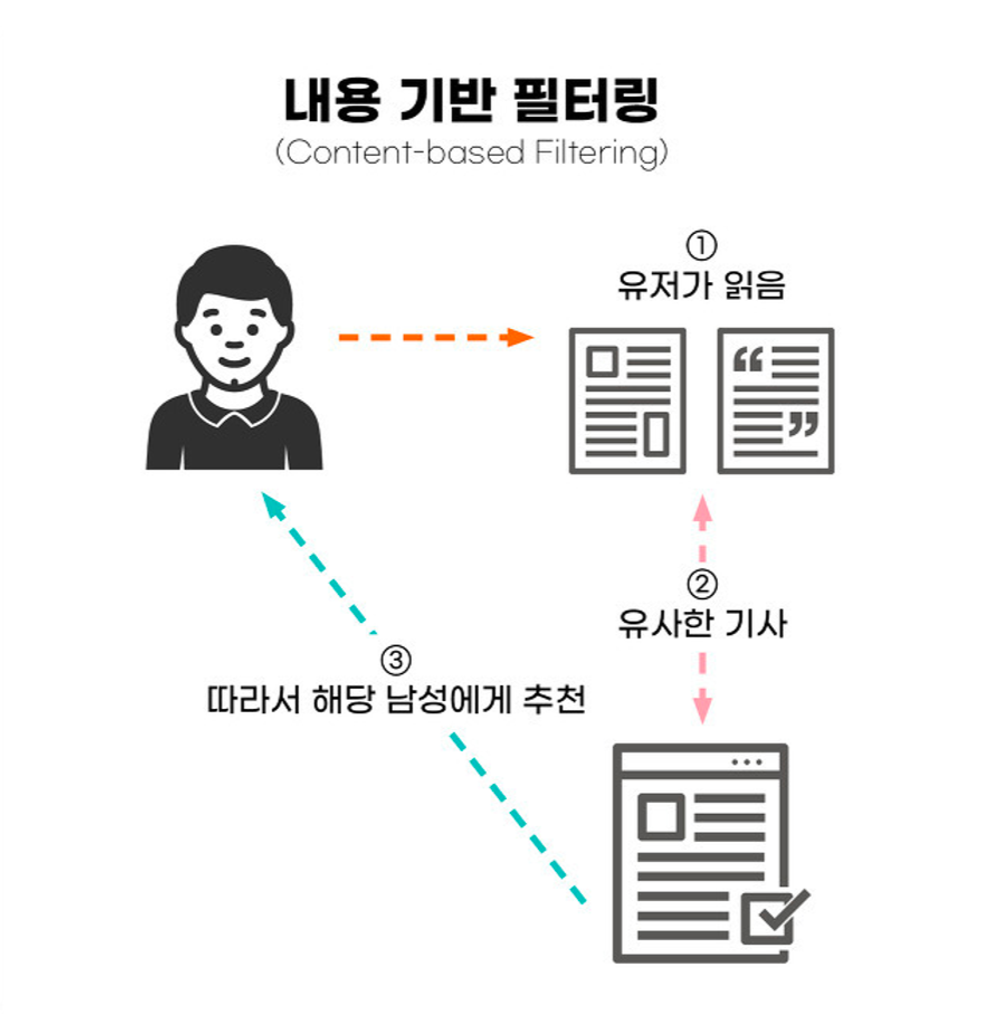
콘텐츠 기반 필터링
유저가 좋아하는 아이템의 특성을 분석하여 그 아이템과 비슷한 아이템을 추천하는 방식입니다. 예를 들어 유저가 액션 영화를 많이 봤다면, 또 다른 액션 영화를 추천하는 겁니다. 그리고 또한 새로운 유저에 관한 정보가 부족해 발생하는 콜드 스타트 문제로부터 어느 정도 자유롭다는 장점을 가집니다. 유저가 한두 개의 아이템만 평가해도 그 아이템의 특성을 기반으로 유사한 아이템을 추천할 수 있기 때문입니다.
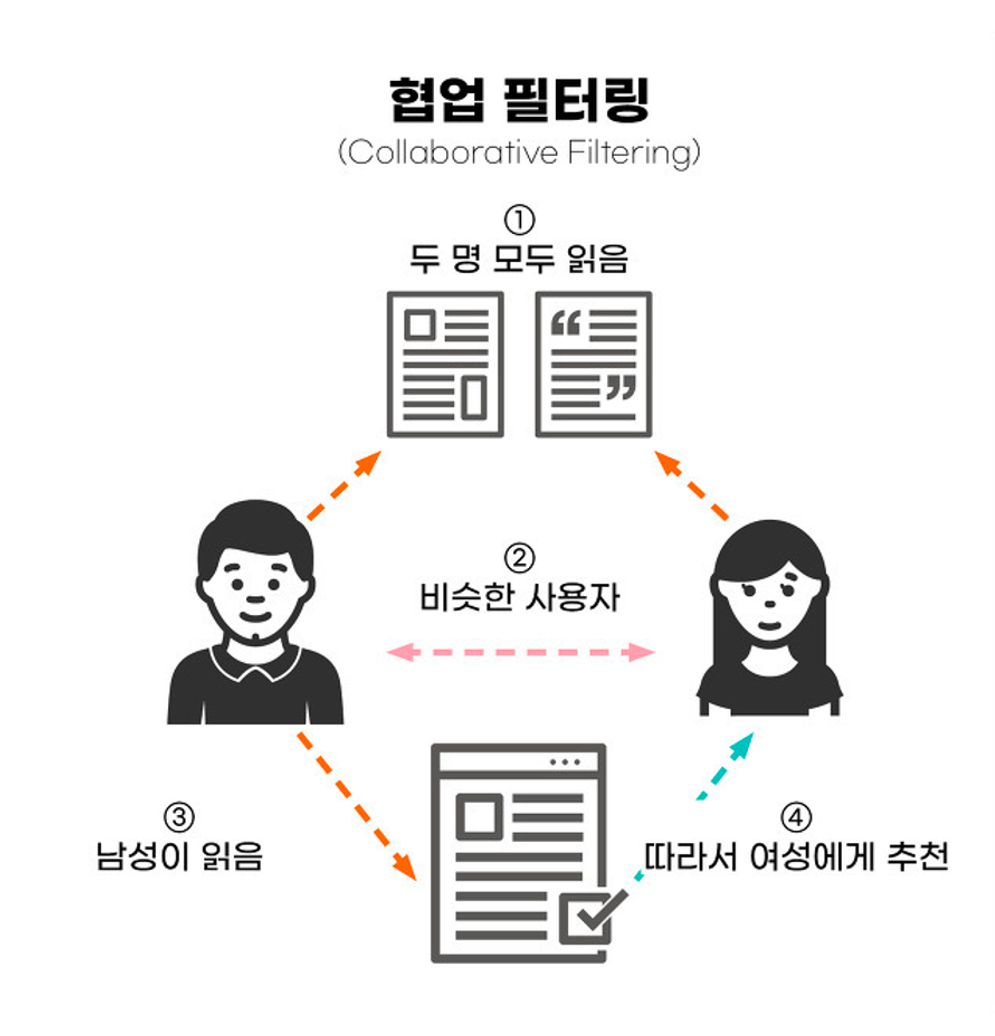
협업 필터링
한 유저와 비슷한 특성을 가진 다른 유저의 행동을 분석해 아이템을 추천하는 방식입니다. 협업 필터링은 비슷한 유저끼리 비슷한 아이템을 좋아할 가능성이 높다고 가정합니다. 대표적인 협업 필터링 방법론 두 가지를 소개해 드리고자 합니다. 유저 기반 협업 필터링 (User-based Collaborative Filtering): 특정 유저가 좋아하는 아이템들을 파악한 후, 비슷한 취향을 가진 다른 유저들이 좋아한 아이템들을 추천합니다. 예를 들어 유저 A가 영화 1에 높은 평점을 주었고 유저 B 역시 영화 1에 높은 평점을 주었다면, 유저 A에게 유저 B가 높게 평가한 영화 2를 추천해줄 수 있는 겁니다. 아이템 기반 협업 필터링 (Item-based Collaborative Filtering): 사용자가 평가한 아이템 간의 유사성을 계산하여, 유사한 아이템들을 추천합니다. 예를 들어 사용자 A가 상품 1을 구매했을 때, 상품 1과 유사한 상품 2, 3을 추천해줄 수 있는 것입니다. 이 유사성은 사용자와 아이템 간의 상호작용 데이터를 바탕으로 계산됩니다.
03 Method
데이터 수집 - 웹 크롤링
저희 팀은 네이버 지도(모바일 버전)에서 데이터를 수집하기로 결정했습니다. 다른 지도 앱에 비해 한국어 리뷰 수가 압도적으로 많고, 리뷰 태그가 구체적으로 잘 정리되어 있기 때문입니다.
📌 지역에 따른 가게 이름과 리뷰 URL 크롤링 먼저, 가게의 리뷰 데이터를 수집하기 위해서 가게 이름과 리뷰 URL이 필요합니다. 데이터 수집은 선유도역 / 양평2동 / 당산2동과 같은 지역명에 맛집 / 식당 / 카페 등의 키워드를 조합하여 검색했을 때 결과로 나온 가게에 관해 진행했습니다.
📌 가게에 따른 리뷰 데이터 크롤링

위 크롤링을 통해 얻은 엑셀 파일에서 가게 이름과 URL을 읽어 각 가게의 리뷰를 수집했습니다. 모든 리뷰를 로드하기 위해 '더보기 버튼’을 클릭하고, 리뷰 태그가 2개 이상인 경우에는 '+n 버튼'을 눌러 모든 태그가 표시되게 했는데요. 수집한 데이터는 가게 이름, 닉네임, 리뷰 내용, 리뷰 날짜, 재방문 여부, 리뷰 태그, 리뷰 개수, 그리고 리뷰 작성자의 프로필로 이동하는 URL입니다. 대량의 데이터를 다루기 때문에 중간에 오류가 발생하더라도 데이터를 실시간으로 저장하여 유실되지 않도록 했습니다.
📌리뷰자의 다른 리뷰 데이터 크롤링
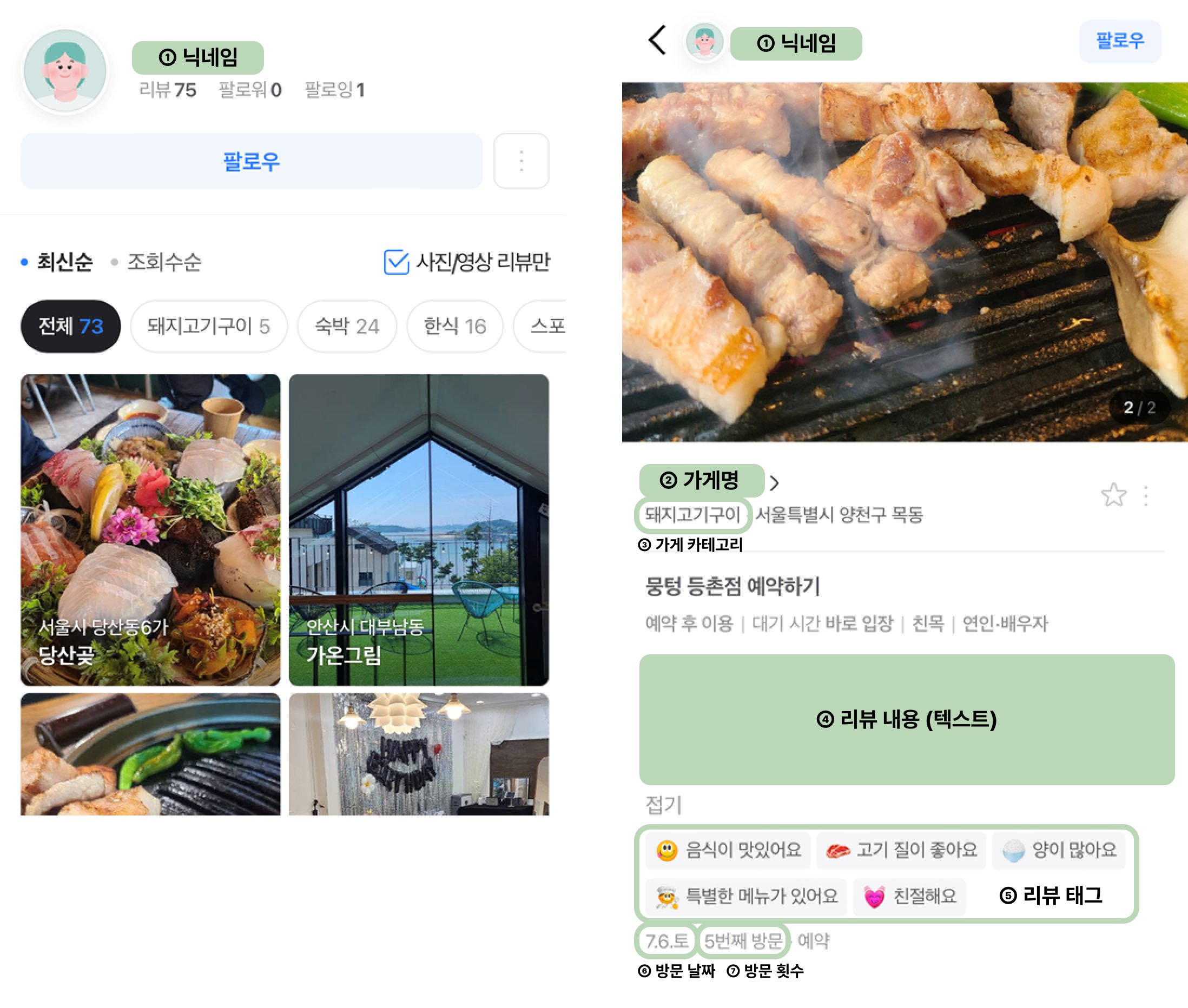
유저 간의 유사도를 이용하여 유저의 특징을 분석하고자 크롤링을 진행했습니다. 프로필에서 리뷰를 로드할 때는 자동 스크롤을 사용했으며, 최근 작성된 리뷰의 중요도가 더 높을 것으로 판단하여 스크롤 횟수를 30번으로 제한했습니다. 수집한 데이터는 닉네임, 가게 이름, 카테고리, 리뷰 내용, 날짜, 리뷰 태그이고, 총 337개의 가게 데이터와 90,000여 개의 리뷰 데이터, 52,000여 명의 유저 데이터를 수집했습니다.
유저-아이템 매트릭스
이렇게 수집한 데이터를 바탕으로 유저-아이템 매트릭스(User-Item Matrix)를 제작했습니다. 이때 유저-아이템 매트릭스란 협업 필터링 알고리즘을 통해 추천 항목을 생성하는 데 사용하는 행렬로, 추천 시스템에서 매우 중요한 역할을 하는 데이터 구조입니다. 이 행렬은 유저와 아이템 간의 상호작용을 나타내며, 각 행렬의 셀 값은 특정 유저가 특정 아이템과 어떻게 상호작용했는지 나타냅니다. 예를 들어, 영화 추천 시스템의 경우 행렬의 값은 사용자가 영화에 매긴 평점이 됩니다. 이 행렬을 분석하여 유저 간의 유사성을 찾거나, 유저와 아이템 간의 관계를 파악하여 새로운 항목을 추천합니다.
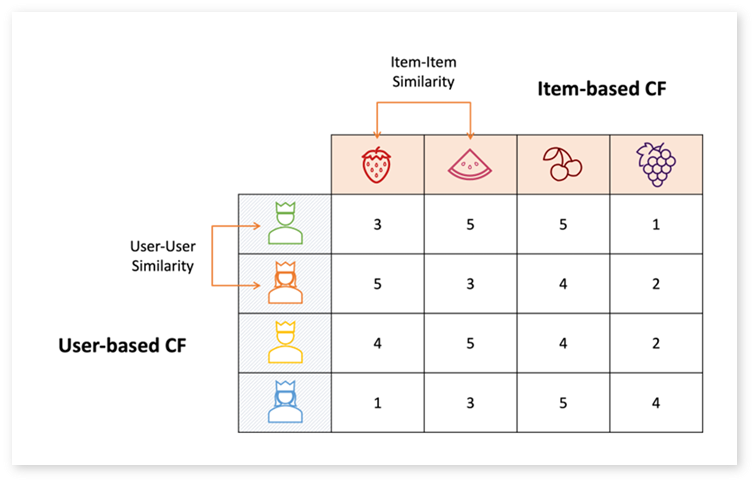
이 프로젝트에서 유저는 가게를 방문하고 리뷰를 작성한 사람, 아이템은 선유도역 부근의 가게를 의미합니다. 따라서 가게를 방문한 사람들이 해당 가게에 남긴 평가, 즉 평점 데이터가 필요한데요. 2021년 10월부터 네이버 지도 리뷰에서 별점 입력 기능이 종료되어 모을 수 있는 평점 데이터가 없어 아래 두 가지 방법으로 평점 데이터를 추출하고자 했습니다.
위 방법으로 생성된 평점 데이터를 바탕으로 유저-아이템 매트릭스를 구성했습니다. 수집한 데이터가 다른 데이터셋보다 특성을 나타내는 다양한 태그를 가지고 있다는 점에 주목했습니다. 가게 별 평가 태그와 카테고리를 활용하여 가게 간, 즉 아이템 간의 유사도를 도출하고자 했는데요. 이를 위해 한국어 식당 리뷰 데이터를 활용하여 Word2Vec 모델을 직접 학습시켰고, 해당 모델을 평가 태그와 카테고리를 embedding하는 데에 활용했습니다. 이렇게 embedding된 카테고리 벡터와 평가 태그 벡터를 토대로 각각 코사인 유사도를 계산하고 이를 병합하여 최종적인 아이템 간 유사도를 도출했습니다. 아이템 간 유사도 매트릭스
결측치 보강
협업 필터링을 진행할 때는 유저들이 다양한 가게에 방문하고 리뷰를 남겨 평점 데이터가 기록되어 있어야 유의미한 추천이 가능합니다. 그런데 위 데이터셋의 경우 1개의 가게에 리뷰를 남긴 유저가 전체의 75.6%, 2개의 가게에 리뷰를 남긴 유저가 전체의 12.7%로, 유저 - 아이템 매트릭스가 너무 희소해지는 문제 상황이 발생했습니다. 이를 보완하기 위해 결측치 보강, 즉 Imputation을 진행했는데요. 앞서 계산한 아이템 간 유사도를 바탕으로 한 데이터를 보강하였고, 각각의 유저가 평가한 아이템이 충분히 많아져 유의미한 추천이 가능해졌습니다.
유저 별 아이템 수 Imputation 전 Imputation 후
1 41768 0
2 5620 0
3 1847 0
4 864 0
5 444 42212
모델 제작
기존 모델
- PopRec
PopRec이란, 전체 유저 사이에서 가장 인기 있는 아이템을 추천하는 방식을 말합니다. PopRec은 추천시스템에서 가장 기본적인 BaseLine 모델이라고 할 수 있습니다. PopRec 모델을 실행했을 때, 추천 결과는 다음과 같습니다.
PopRec 추천 결과
1순위 뭉텅 오목교점
2순위 뭉텅 선유도점
3순위 우장관
4순위 우든박스커피
5순위 이자카야 베이비
- Matrix Factorization
Matrix Factorization(MF)은 행렬분해로, 유저 - 아이템 매트릭스를 작은 행렬로 분해하여 잠재요인을 파악함으로써 사용자의 선호도와 아이템의 특성을 학습하는 방식을 말합니다. MF는 협업 필터링의 대표적인 방법으로 알려져 있습니다.
제작 모델
- MF 기반 필터링 모델
MF 기반 필터링이란, mf model과 content-based-filter 추천 방식을 결합한 하이브리드 추천 모델입니다. 먼저, Matrix Factorization (MF) 기법을 사용하여 사용자와 가게(아이템)를 각각 벡터로 변환한 후, 이 벡터들의 곱을 통해 사용자가 선호할 만한 가게를 예측합니다. 이후, Content-Based Filtering (CBF)을 적용하여 MF로 추천된 가게들 중에서 사용자의 취향에 더 맞는 가게를 선택합니다. 이를 위해 사용자와 가게의 태그나 카테고리 벡터 간의 유사도를 계산해 최종적으로 상위 몇 개의 가게를 추천하는 방식입니다.
- CBF 기반 필터링 모델
CBF 기반 필터링이란, MF 기반 필터링과 마찬가지로 mf model과 content-based-filter 추천방식을 합한 하이브리드 추천 모델입니다. 하지만 MF 기반 필터링 모델과 달리, Content-Based Filtering (CBF)을 통해 사용자와 가게의 태그나 카테고리 벡터 간의 유사도를 계산하여 사용자의 취향에 맞는 가게를 찾습니다. 이후, Matrix Factorization (MF) 기법을 사용해 예측된 선호도를 기반으로 최종 추천을 제공합니다.
- CBF + MF 앙상블 모델
CBF와 MF의 앙상블 모델은 위의 모델들과 다르게 각각 모델을 실행하고 나온 점수를 합하여 최종적인 추천을 해줍니다. CBF와 MF 두 모델의 장점을 극대화하고자 앙상블 모델을 구현했습니다.
04 Experiments
추천시스템에서는 Precision@K, Recall@K라는 지표를 활용하여 성능을 평가하는데요. Precision@K는 상위 K개의 추천 결과 중에서 사용자가 실제로 선호한 아이템의 비율을 의미하고, Recall@K는 사용자가 실제로 선호한 아이템 중 상위 K개의 추천 결과로 포착한 아이템의 비율을 의미합니다. 앞서 정리한 기존 모델과 제작 모델에 관하여 성능을 평가한 결과는 다음과 같습니다. 기존 모델
PopRec MF
Precision@5 0.0477 0.0365
Recall@5 0.0459 0.1759
제작 모델
MF 기반 필터링 CBF 기반 필터링 CBF + MF 앙상블 모델
Precision@5 0.0365 0.0354 0.0405
Recall@5 0.1750 0.1702 0.1953
05 Conclusion
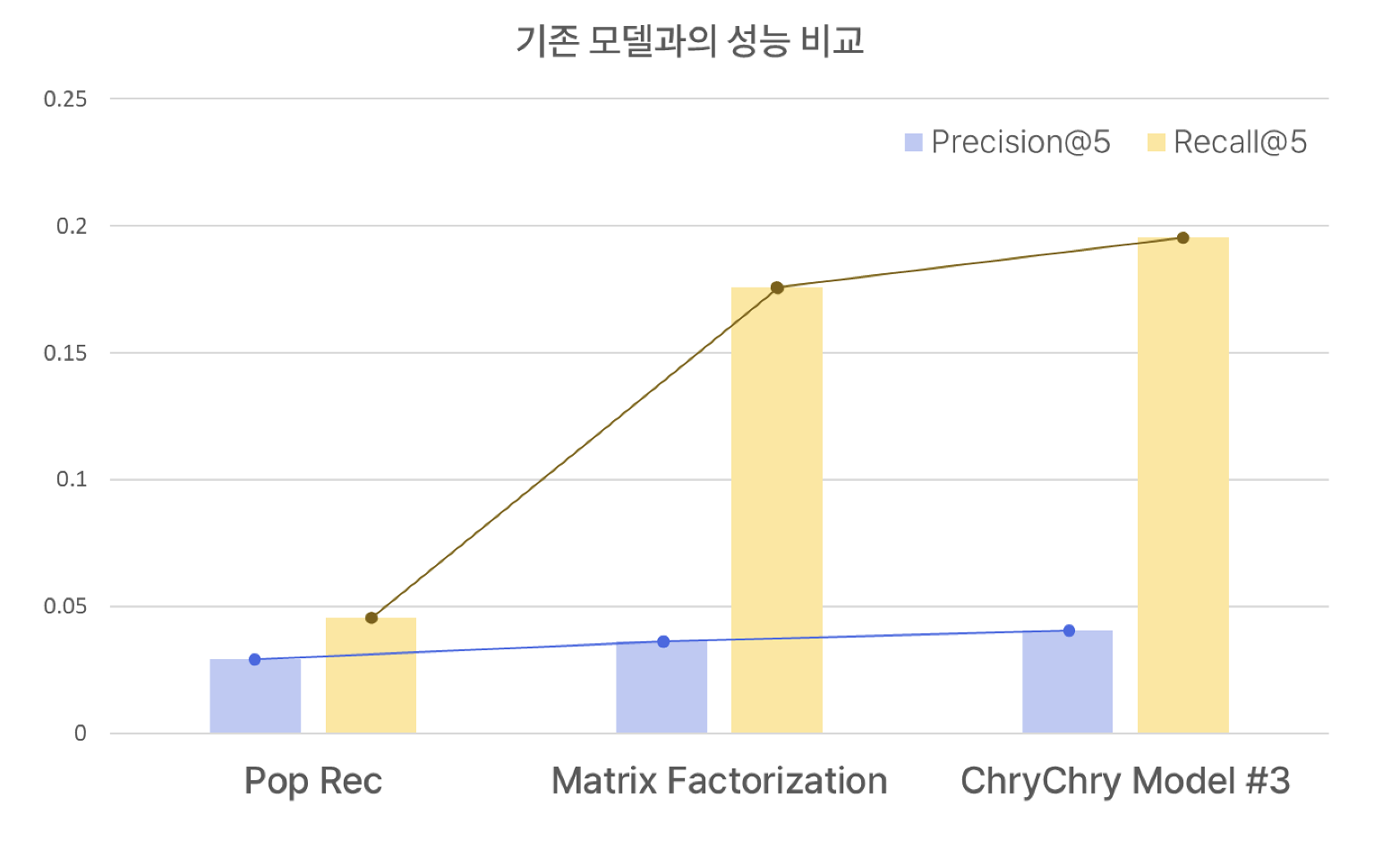
제작한 3개의 모델 중 앙상블 모델이 성능이 가장 좋았으며, 기존의 MF(Matrix Factorization) 모델보다도 약 11%정도 성능이 향상된 모습을 보였습니다. 3개의 제작한 모델 모두 CBF와 MF를 적절하게 사용했지만, 다른 모델과 달리 앙상블 모델은 각각 CBF와 MF의 점수를 온전히 더해 Pooling하는 방식이 두 모델의 장점을 모두 살렸기 때문에 더 좋은 성능을 보인 것으로 판단했습니다. 직접 웹 크롤링을 통해서 데이터를 얻고, 데이터를 분류해 두 가지 필터링을 모두 사용해 보았고, 데이터의 질을 올리기 위해서 Imputation을 진행했다는 의의가 있습니다. 또한, 모델을 손수 제작해 보면서 기존의 모델보다 성능을 높일 수 있었습니다. 이때 Imputation을 진행한 데이터이기 때문에 실제 데이터와 차이는 있을 수 있다는 한계점이 있지만, 더욱 다양한 모델을 공부해 각각의 장단점을 명확하게 파악하고 가장 적절한 모델을 사용한다면 성능을 더욱 높일 수 있을 것이라 기대합니다.
06 Demo

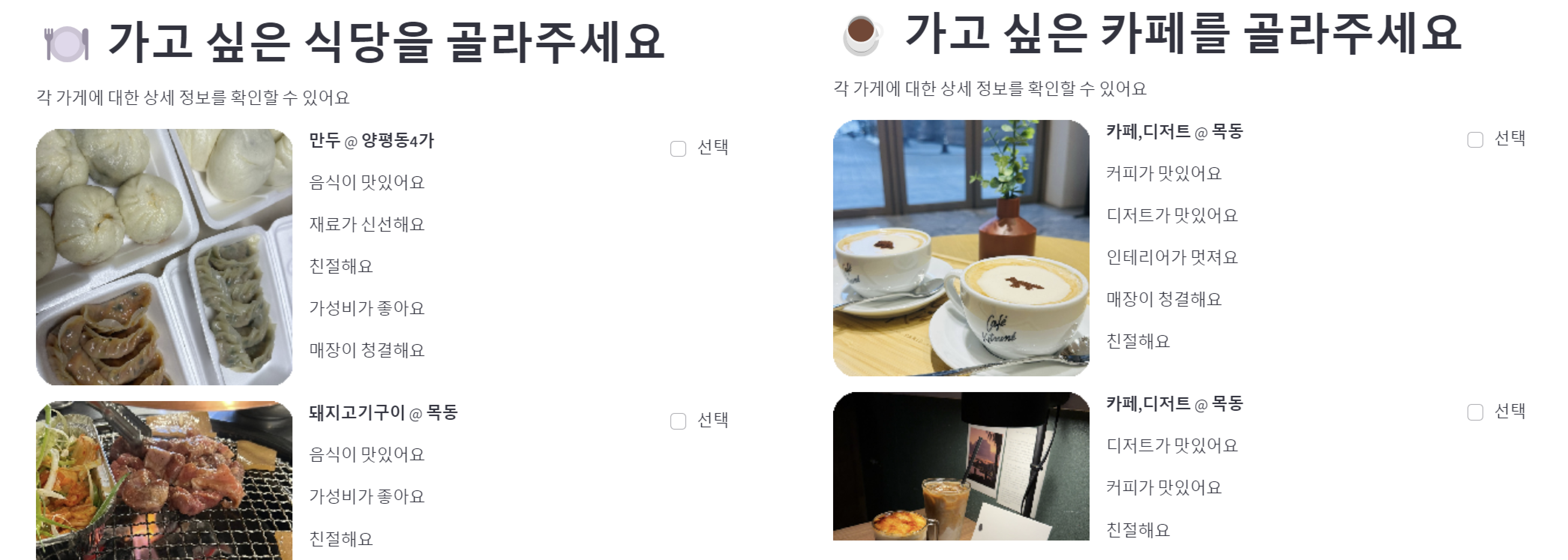
저희는 유저에게 6가지의 음식점 및 카페 예시를 보여주고 이에 대한 평가를 받아서 이를 통해 유저의 특성을 파악하고자 했습니다. 6가지 음식점에 대한 카테고리와 태그를 통해서 rating을 받으면, 유저 - 아이템 매트릭스에서 해당 가게에 점수가 부여됩니다. 이와 동시에 embedding을 통한 코사인 유사도 계산으로 카테고리와 태그에 대한 선호도 역시 파악할 수 있습니다. 이 두 가지 매트릭스를 이용해 유저가 가장 좋아할 만한 식당 네 곳을 추천해 주고, 그 중 한 곳을 고르면 추천 순위가 높은 카페 중 해당 식당과 주소지가 가까운 네 곳을 추천해 줍니다. 이로써 사용자는 6개의 식당에 대해 평가하는 것만으로도 자신의 선호도에 따라 식당과 카페를 선택하여 원하는 조합을 구성할 수 있습니다.