
0. Overview
지난 몇 년 간 급속도로 발전한 딥러닝 기술의 패러다임은 우리의 삶을 너무나도 많이 바꿔 놓았습니다. 이제 우리는 인공지능 모델과 자유자재로 대화를 할 수 있고, 인공지능 모델이 우리에게 그림을 그려주기도 합니다. 한편, 인공지능 모델을 개발하고 사용하는 데에 있어 가장 중요하다고 볼 수 있는 요소는 ‘데이터’입니다. 모델은 데이터로부터 만들어지며, 데이터의 특성에 따라 모델의 특징이 달라지기 때문입니다. 인공지능 모델을 학습하기 위해서는 대규모의 데이터가 필요합니다. 모델의 학습 과정의 원리가 데이터의 분포를 차츰차츰 알아가는 것으로 이루어지기 때문에, 소량의 데이터로부터는 데이터의 일반적인 특징을 파악하기 힘들기 때문입니다. 이로부터 알 수 있는 AI 기술의 한계는, 많은 양의 데이터를 확보하기 어려운 경우 모델을 학습하기 어렵다는 점입니다. 또한, ‘학습 데이터가 모델의 특징을 결정한다’라는 관점에서 보았을 때, 모델이 학습 데이터에만 특화 된다는 점도 문제점으로 여겨질 수 있습니다. 학습 데이터로부터 모델의 행동이 결정된다는 것은, 학습 시 사용 되지 않은 데이터에 대해서는 모델이 적절한 대처를 하지 못한다는 의미로 해석될 수 있기 때문입니다. 따라서 저희는 모델이 적은 수의 데이터 만을 활용할 수 있는 동시에 새로운 데이터에 대해 즉각적으로 대응할 수 있는 방법에 대해 고민하게 되었습니다. 이로부터 ‘Fine-tuning 없이 Few-shot visual grounding에 효과적인 architecture research’라는 주제를 선정하게 되었습니다.
1. Background
Few shot learning
Few-shot learning이란?
Few-shot Learning이란 말 그대로 ‘적은 수의 데이터를 가지고 모델을 학습’하는 기법을 의미합니다. 대규모의 데이터로 깊은 구조의 아키텍처로 이루어진 모델을 학습하는 일반적인 딥러닝 프레임워크와는 대척점에 있는 개념이라고 볼 수 있습니다.

인간은 근거 자료로 삼을 수 있는 사진을 한 장씩만 보여주고도 객체를 구분해낼 수 있습니다. 반면 딥러닝의 classification 모델을 이용해서 객체를 구분하고자 한다면 최소 몇천 장, 많게는 수십, 수백만장의 이미지가 필요하게 됩니다. 인간은 적은 양의 데이터를 이용해서 학습할 수 있을 만큼 뛰어난 일반화 능력을 가지고 있습니다. 예를 들어, 어린 아이들도 새로운 동물의 이미지를 한두 장만 보고도 그 동물을 다른 동물과 구분하고, 심지어 다른 환경에서도 동일한 동물을 인식할 수 있습니다. 이는 인간 고유의 인지 능력으로, 데이터의 수와 무관하게 패턴을 빠르게 파악하고 유사한 특성을 일반화하여 적용하는 능력에 기반합니다. AI에서는 이러한 인간의 능력을 모방하고자 하는 시도가 Few-shot Learning입니다. 따라서 대규모의 데이터가 없어도 새로운 상황이나 패턴에 빠르게 적응하고 학습할 수 있도록 모델을 설계하는 것을 목표로 합니다.
Few-shot learning의 이점
Few-shot learning은 학습에 필요한 데이터 양을 크게 줄여줄 수 있는 기술로, 데이터 수집과 레이블링에 대한 부담을 경감시켜 줍니다. 예를 들어, 야생동물의 종류를 구분하는 모델을 학습시키고자 할 때, 모든 종류의 동물 이미지를 대규모로 수집하는 것은 현실적으로 불가능할 수 있습니다. 사자나 호랑이 같은 일반적인 동물은 수천 장의 이미지가 존재할 수 있지만, 희귀종인 ‘검은 표범’이나 ‘빨간 팬더’ 같은 동물들은 그만큼의 이미지를 확보하기가 매우 어렵습니다. 이런 경우, 일반적인 딥러닝 방법은 데이터가 부족한 클래스에 대해 오버피팅되거나 학습이 제대로 이루어지지 않는 경우가 많습니다. 하지만 Few-shot Learning에서는 검은 표범의 이미지가 극소량인 경우에도 모델이 이를 학습하고, 다른 동물들과 차이를 구분할 수 있도록 설계됩니다. Few-shot Learning의 또 다른 장점은 모델의 확장성이 뛰어나다는 점입니다. 예를 들어, 기존의 이미지 분류 모델에 ‘너구리’라는 새로운 동물 클래스를 추가하고자 한다고 가정해봅시다. 일반적인 딥러닝 모델에서는 새로 추가된 클래스를 학습시키기 위해 기존의 전체 데이터셋을 함께 다시 학습시켜야 할 수도 있습니다. 그러나 Few-shot Learning 모델은 기존 데이터셋 전체를 학습할 필요 없이, 너구리의 이미지를 3~5장만 제공해도 새로운 클래스를 기존 모델에 자연스럽게 추가할 수 있습니다. 이처럼 Few-shot Learning은 새로운 클래스가 등장할 때마다 기존 모델의 재학습 없이 빠르게 적응할 수 있도록 해주므로, 모델의 확장성과 유연성이 크게 향상됩니다.
기존 Few-shot learning 방법론의 한계
기존 Few-shot Learning(FSL) 방법론들은 주로 모델의 fine-tuning(미세 조정) 기술에 의존하여, 새로운 클래스나 데이터를 학습할 때 기존 모델의 파라미터를 부분적으로 조정하는 방식으로 접근합니다. 그러나 이러한 접근법에는 몇 가지 중요한 한계가 존재하며, 특히 안정성과 유연성 측면에서 다음과 같은 문제가 발생할 수 있습니다. 1. 모델의 안정성 측면 - Fine-tuning의 한계와 Catastrophic Forgetting 문제 Fine-tuning은 새로운 데이터를 사용해 기존의 모델을 미세 조정하는 방식으로, Few-shot Learning에서도 널리 사용됩니다. 예를 들어, 새로운 클래스에 대한 소수의 샘플을 학습하기 위해 기존 모델의 일부 파라미터를 업데이트하는 방식입니다. 하지만 이러한 방식은 다음과 같은 한계를 지니고 있습니다.
- Catastrophic Forgetting: Fine-tuning 방식의 가장 큰 문제는 새로운 데이터를 학습할 때 이전에 학습했던 정보가 손실될 수 있다는 점입니다. 이를 Catastrophic Forgetting이라 부르는데, 이는 새로운 태스크에 적응하려다 기존 지식을 잃어버리는 현상입니다. 새로운 클래스를 잘 구분하게 되더라도 기존 클래스에 대한 성능이 급격히 저하될 위험이 있습니다.
- 안정성의 문제: Fine-tuning 시 모델의 파라미터가 계속 변경되기 때문에, 새로운 데이터를 추가할 때마다 결과가 불안정해질 수 있습니다. 특히, 초기 학습된 클래스 간의 관계나 패턴이 새로운 클래스의 도입으로 인해 왜곡되면서 모델의 전반적인 성능이 예측할 수 없게 변화할 수 있습니다.
2. 모델의 유연성 측면 - 새로운 데이터가 들어올 때마다 반복 학습의 필요성 Fine-tuning 기반의 Few-shot Learning 방법론은 유연성의 문제에서도 한계를 보입니다. 새로운 클래스나 태스크가 등장할 때마다 모델을 재학습(fine-tuning)해야 하며, 이 과정에서 다음과 같은 문제가 발생할 수 있습니다:
- 학습 시간 및 비용 증가: 새로운 데이터가 추가될 때마다 기존 모델의 파라미터를 새로 학습시키는 것은 많은 연산 자원과 시간이 소요됩니다. 이로 인해 실제 애플리케이션에서 모델을 빠르게 확장하거나 업데이트해야 하는 경우, 이러한 반복 학습이 비효율적으로 작용할 수 있습니다.
- 기존 모델의 활용 불가능성: Fine-tuning 기반의 Few-shot Learning 접근법에서는 새로운 클래스에 적응하기 위해 모델을 학습할 때 기존의 모델을 그대로 사용할 수 없습니다. 즉, 새로운 데이터를 학습하지 않은 기존 모델은 그대로 유지될 수 없으며, 매번 학습이 이루어질 때마다 업데이트된 모델을 사용해야 합니다. 이는 학습된 모델을 여러 환경이나 시스템에서 유연하게 재사용하는 것을 어렵게 만듭니다.
Visual Grounding
Visual Grounding이란?
Visual Grounding은 주어진 텍스트 설명을 바탕으로 이미지 내의 특정 객체나 영역을 식별하는 기법입니다. 이 기법의 목표는 자연어 텍스트를 활용하여 사용자가 찾고자 하는 객체를 이미지 내에서 정확히 위치를 지정해주는 것입니다. 예를 들어, “빨간 모자를 쓴 소년”이라는 문장을 입력하면, 이미지에서 그 소년이 위치한 영역을 정확히 찾아내는 것입니다. Visual Grounding은 Object Detection과 유사하면서도, 몇가지 중요한 차이점이 존재합니다.

- Object Detection은 사전에 정의된 고정된 클래스 레이블을 바탕으로 이미지를 탐지하고, 해당 클래스에 속하는 객체의 위치를 예측합니다. 이는 모델이 특정한 범주에 국한되어 학습되기 때문에, 새로운 클래스나 임의의 설명에 대해서는 대응할 수 없습니다.
- 반면, Visual Grounding은 고정된 클래스 레이블이 아닌, 자연어 문장(예: “빨간색 티셔츠를 입고 있는 남자”)을 입력으로 받아 임의의 객체를 찾을 수 있습니다. 즉, Visual Grounding은 단순히 ‘사람’을 인식하는 것이 아니라, “파란색 셔츠를 입고 있는 사람”, “강아지와 함께 서 있는 사람”처럼 다양한 텍스트 설명을 기반으로 매우 유연하게 이미지를 탐지할 수 있는 자연어 기반 객체 탐지 방식입니다.
이처럼 Visual Grounding은 Object Detection에 비해 텍스트 표현의 자유도와 다양한 클래스 확장을 가능하게 한다는 점에서 본질적인 차이를 가지고 있습니다.
Visual Grounding의 이점
Visual Grounding의 주요 이점은 Open Vocabulary를 바탕으로 탐지할 수 있다는 점입니다. 기존의 Object Detection 모델은 사전에 정의된 클래스 집합에 의존하며, 학습 데이터에 없는 새로운 클래스를 인식하는 데 한계가 있습니다. 예를 들어, Object Detection 모델이 “고양이”, “개”와 같은 일반적인 클래스만 학습되었다면, “펭귄”이나 “이구아나”처럼 학습되지 않은 동물은 탐지할 수 없습니다. 하지만 Visual Grounding은 자연어 문장을 기반으로 객체를 식별하기 때문에, 사전에 정의되지 않은 클래스나 임의의 객체도 탐지할 수 있습니다. 이러한 Open Vocabulary의 특성은 다음과 같은 장점들을 제공합니다:
- 확장성: 사전에 정의된 카테고리에 국한되지 않고, 사용자가 원하는 모든 설명(문장)을 바탕으로 객체를 탐지할 수 있기 때문에 매우 유연하게 새로운 클래스를 탐지할 수 있습니다.
- 유연한 표현: 단순한 클래스 분류가 아니라, 다양한 속성(색깔, 위치, 크기 등)을 포함한 세부적이고 복합적인 설명을 처리할 수 있습니다. 예를 들어, “왼쪽 구석에 있는 작은 강아지”와 같은 구체적인 설명도 처리가 가능하여, 더 정교한 객체 탐지가 가능합니다.
- 사용자 맞춤형 탐지: Object Detection처럼 미리 설정된 클래스 없이도, 사용자가 직접 입력한 문장에 따라 탐지가 이루어지므로 다양한 환경과 상황에 즉각적인 적용이 가능합니다.
따라서 Visual Grounding은 다양한 텍스트 설명을 통해 새로운 객체를 인식하고 탐지할 수 있다는 점에서 기존 Object Detection에 비해 확장성, 유연성 측면에서 큰 장점을 가지고 있습니다.
기존 Visual Grounding 방법론의 한계
기존 Visual Grounding 방법론들은 zero-shot prompting방식에 의존합니다. 이러한 zero-shot 접근 방식에는 몇 가지 중요한 한계가 존재합니다. 특히 데이터의 불균형, Zero-shot 기법의 근본적인 한계 등의 측면에서 다음과 같은 문제가 발생할 수 있습니다. 1. 데이터 불균형과 도메인 특화 환경에서의 성능 저하 Visual Grounding은 자연어와 이미지 간의 관계를 대규모의 데이터로 학습해야만 효과적으로 작동합니다. 그러나 대규모 데이터로 학습하더라도 다음과 같은 한계가 존재합니다:
- 데이터 분포의 불균형 문제: Visual Grounding 모델은 다양한 설명을 학습할 때, 자주 등장하는 표현과 드물게 등장하는 표현 사이의 불균형으로 인해 성능 편향이 발생할 수 있습니다. 예를 들어, “파란색 셔츠를 입고 있는 사람”은 흔히 볼 수 있는 설명이지만, “녹색 모자와 보라색 신발을 신은 사람”과 같은 표현은 학습 데이터에서 드물게 등장합니다. 이로 인해 모델이 드문 표현에 대해 정확히 인식하지 못하는 문제가 발생합니다.
- Domain-specific한 데이터에서의 성능 저하: Visual Grounding 모델은 일반적으로 일상적인 이미지나 상황을 대상으로 학습되므로, 특정 도메인(예: 의료, 군사, 산업 환경)에서의 객체 탐지 성능이 급격히 저하될 수 있습니다. 예를 들어, “MRI에서 뇌종양의 위치를 찾아라”와 같은 설명은 일반적인 이미지 데이터로 학습된 모델에서는 인식할 수 없으며, 도메인 특화 데이터를 추가로 학습해야만 적절한 성능을 발휘할 수 있습니다.
2. Zero-shot Prompting의 근본적 한계 Visual Grounding은 주로 Zero-shot Prompting을 통해 새로운 설명에 대해 대응하려 합니다. 그러나 이 접근법에는 다음과 같은 문제가 있습니다:
- 데이터의 한계: 아무리 대규모 데이터로 학습하더라도, 이 세상의 모든 데이터를 포함할 수는 없습니다. 모델이 보지 못한 데이터에 대해서는 성능이 보장되지 않으며, 이는 데이터가 부족하거나 희귀한 상황에서는 치명적인 단점이 될 수 있습니다.
- 사전 지식의 부족: 특정 객체나 상황에 대한 사전 지식이 부족한 경우, 모델이 문장과 이미지 간의 관계를 올바르게 학습하지 못할 수 있습니다. 예를 들어, 드물게 등장하는 “고양이와 참새가 있는 장면”에 대해서는 적절한 학습이 이루어지지 않아, 관련 설명을 제대로 이해하지 못할 가능성이 있습니다.
따라서 Visual Grounding은 다양한 설명을 기반으로 이미지를 탐지할 수 있는 장점을 가지고 있지만, 데이터 분포의 불균형, 도메인 특화 환경, Zero-shot의 근본적 한계 등으로 인해 실제 응용에서 안정성과 성능 보장 측면에서 여러 한계를 가지고 있습니다.
2. Baseline
FS-DETR이란?
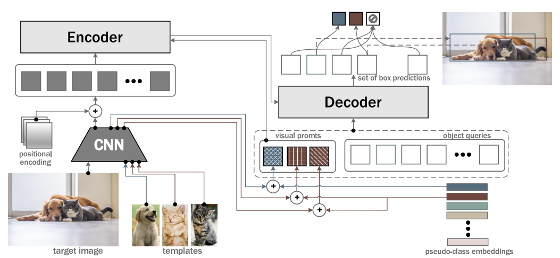
FS-DETR이란 Object detection 모델인 DETR에 기반한 Few-shot Object Detection 모델입니다. 다음과 같은 특징을 가지고 있습니다.
- Template 데이터의 존재 : Few-shot object detection 때문에, target data를 이용해 predict를 할 때 참고 자료로 삼을 데이터가 필요합니다. 따라서 template를 제시합니다.
- Pseudo-class embedding의 도입 : 모델의 아키텍처는 DETR의 구조를 따릅니다. 이 때 template의 데임베딩 값에 learnable한 embedding인 pseudo-embedding을 더한 것을 visual prompt라고 부르고, 이를 object query앞에 붙여주게 됩니다.
Dynamic M-DETR 이란?
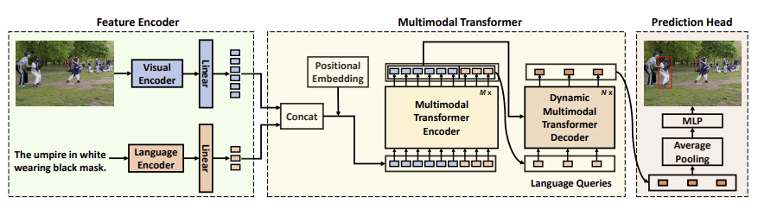
Dynamic DETR이란 Object detection 모델인 DETR에 기반한 Visual Grounding 모델입니다. 다음과 같은 특징을 가지고 있습니다.
- Language Encoder의 도입 : 기존 DETR은 CNN 구조의 Visual encoder만을 사용했다면, 본 모델은 텍스트와 이미지를 종합적으로 이용하는 모델이므로 Language encoder를 도입하였습니다.
- Language Query를 통한 결과 도출 : 기존의 DETR 모델은 무작위로 초기화되는 Object query를 활용한 반면, 본 모델에서는 Encoder의 결과값 중 language에 해당하는 부분을 Language query라고 칭하고, 이를 디코더의 입력값으로 이용하여 결과 예측 시 자연어 정보를 활용할 수 있도록 하였습니다.
- Dynamic Multimodal Transformer Decoder : 결과를 생성하는 디코더 부분에서, 하나의 포인트에 대해 참고할 다른 지점들을 동적으로 샘플링하게 되는 dynamic decoder를 제안하였습니다.
3. Model
Framework
새로운 데이터가 들어올 때 마다 모델 재학습이 필요하다는 few-shot learning의 한계점, zero-shot prompting에 의존하여 데이터 불균형, 특정 도메인에서의 성능 저하, 새로운 상황 에서의 일반화가 어려운 visual grounding의 한계점을 고려하여, visual grounding 모델인 Dynamic M-DETR을 발전시켜 Fine-tuning없이 Few-shot Visual Groudning에 효과적인 모델을 제안합니다.
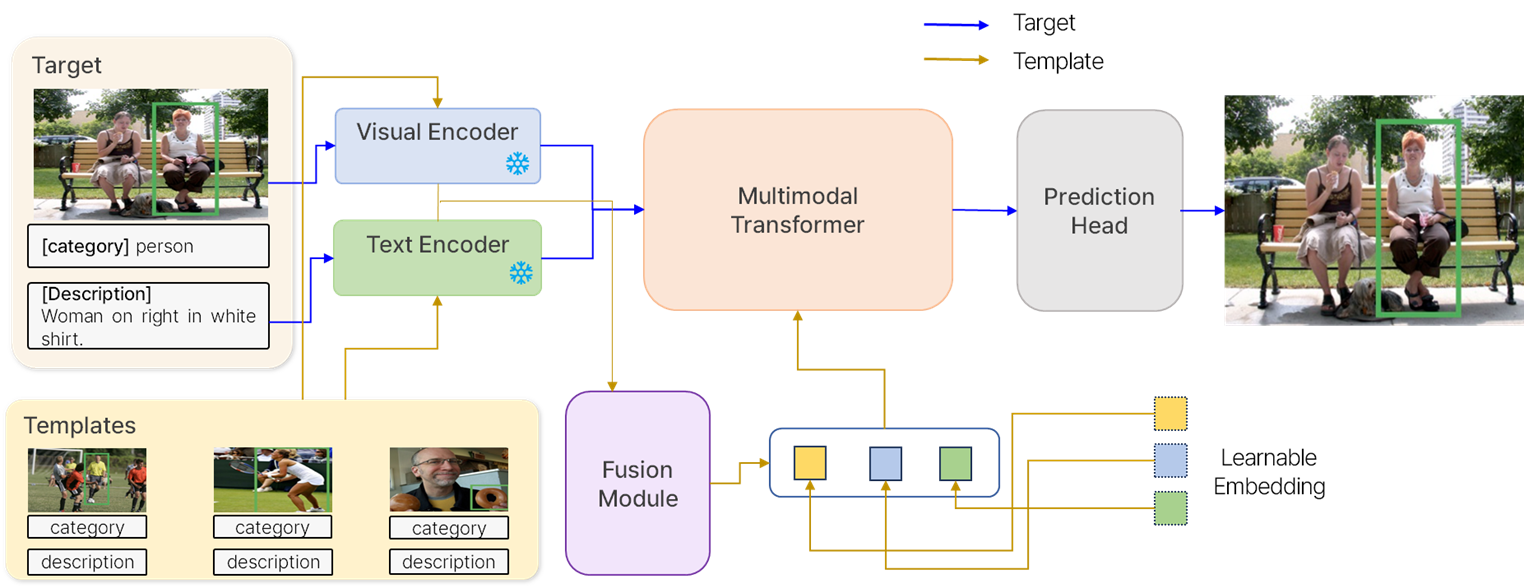
전체적인 흐름은 위와 같습니다.
Feature Encoder
- Target data의 이미지와 텍스트를 각각 Visual Encoder와 Text Encoder를 통과시켜 visual feature 와 text feature를 추출합니다.
- Template의 이미지 와 텍스트를 각각 Visual Encoder와 Text Encoder를 통과시켜 template visual feature와 template text feature를 추출합니다.
Multimodal Prompt 생성
- Template의 visual feature와 text feature 의 상호 cross attention을 한 후 이를 합친 fusion module 을 만듭니다.
- Template의 정보를 학습하는 learnable embedding과 fusion module을 결합하여 multimodal prompt를 생성합니다.
Multimodal Tranformer Encoder
- Target data의 visual feature와 text feature를 결합하여 Encoder에 입력 값으로 넣어줍니다.
Dynamic Multimodal Transformer Decoder
- Multimodal Transformer Encoder의 출력값으로 나온 language query와 multimodal prompt를 입력값으로 넣어주어 새로운 query를 생성합니다.
- Language query와 multimodal prompt를 활용하여 target data에 대하여 2D adaption sampling 을 진행하여 language를 활용하여 집중해야 할 target data의 image의 부분을 sampling 합니다.
- 2d adaptive smapling의 출력값과 새로운 query를 사용하여 Decoding 을 수행합니다.
Prediction Head
- Dynamic Multimodal Transformer Decoder의 출력을 활용하여 MLP로 구성된 prediction head를 사용하여 bounding box를 예측합니다.
Methodology
Template 기반 Multimodal Prompt
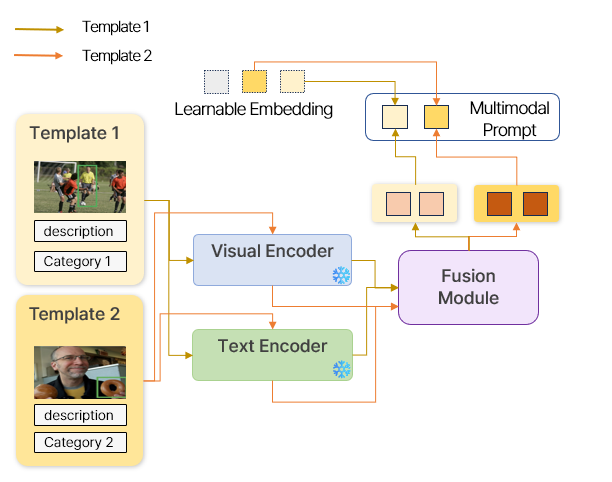
Target 데이터를 가지고 예측을 수행할 때, template이 같이 들어가게 됩니다. Template은 image , description, category로 구성되어 있습니다. Template 별로 이미지에 대한 description도 함께 제공해줌으로써 text 기반으로 더 나은 시각적 이해를 수행할 수 있도록 돕습니다. Template data는 해당 description 에 맞는 bounding box를 활용하여 crop한 이미지와 이에 맞는 간단한 텍스트 표현 "A photo of a \"를 사용하였습니다.
Template의 image 와 text의 상호 cross-attention(Fusion Module)
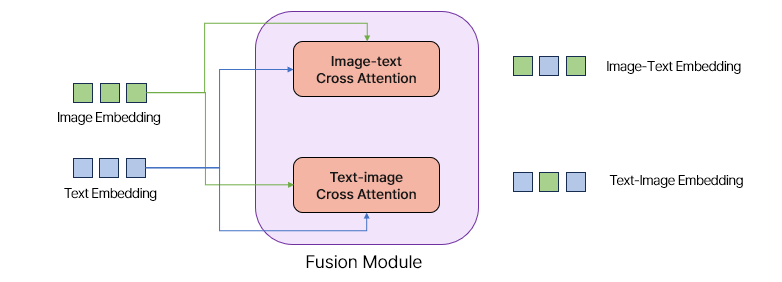
Template data는 target data와 다르게 Visual Encoder와 Text Encoder 각각 한 가지 모달리티만을 활용한 결과이기 때문에, visual feature와 language feature 간의 상호작용이 부족합니다. 따라서 visual feature와 language feature간의 cross attention을 통하여 상호작용을 강화하고자 하였습니다. (1) Text feature를 query로, visual feature를 key와 value로 사용하여 visual feature에 attention을 연산을 진행하고, (2) visual feature를 query로, text feature를 key와 value로 사용하여 text feature와 attention 연산을 수행합니다. 이로부터 기대할 수 있는 바는, (1)은 text feature로부터 image feature와 관계성이 높은 부분을 강조하게 되며, (2)는 반대로 image feature에서 text feature와 관계성이 높은 부분을 강조한 결과가 나오게 됩니다. ### Learnable Embedding 추가
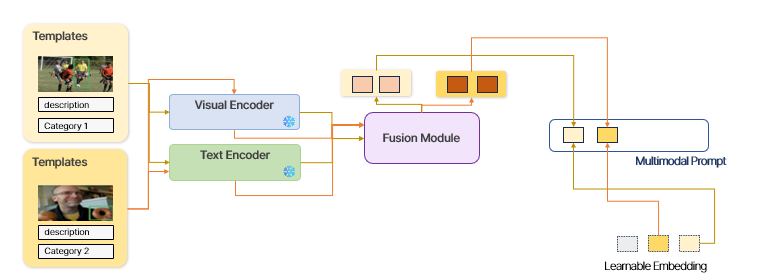
Few-shot learning이 가능하게 하기 위해 learnable embedding을 도입합니다. 제안한 learnable embedding의 작동 원리는, 카테고리 별로 하나의 임베딩이 매핑되는 방식입니다. 동시에, 어떤 카테고리에 어떤 임베딩 값이 매핑되는지는 매번 달라지게 됩니다. 이로부터 기대할 수 있는 효과는, learnable embedding이 카테고리 간의 구분을 도와주는 역할을 하게 되는 동시에, 어떤 카테고리를 어떤 임베딩 값이 도와주는지가 정해져 있지 않기 때문에 클래스와 무관하게 처리할 수 있도록 도와주는 역할을 하기를 기대할 수 있습니다. 만약 템플릿에 처음 보는 카테고리들이 들어온다면, 카테고리 간의 구분은 해줄 수 있어야 하지만, 카테고리의 종류와는 무관하게 이를 처리할 수 있어야 합니다. 저희가 제안한 learnable embedding이 그러한 역할을 하기를 기대하였습니다.
Contrastive loss를 통해 template간 유사성과 차별성을 강조
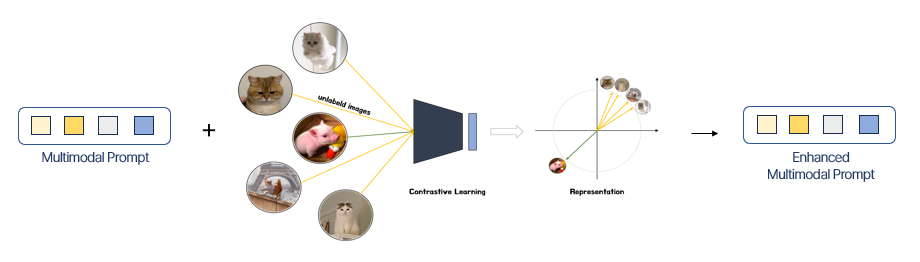
이 때 Template에는 target 데이터와 같은 클래스도 포함되는 동시에, 다른 클래스도 포함하도록 하였습니다. 그 이유는 정보에서 공통점을 활용하는 것보다, 차이점을 활용하는 것이 물체의 식별에 더 효과적일 것이라고 판단하였기 때문입니다. 만약 이미지 내에서 다람쥐를 모두 찾아야 하는 상황에 놓였다고 하고, 참고할 수 있는 이미지를 선택할 수 있다고 가정해봅시다. 그러면 참고 자료에 다람쥐만을 이용하는 것보다, 청설모를 비롯하여 헷갈릴 만한 다른 객체들을 참고자료에 포함시키는 것이 효과적일 것입니다. 다람쥐 정보만을 가지고 객체를 구분한다면 청설모를 보고도 다람쥐와 비슷해보여 다람쥐라고 하는 오인의 가능성이 있지만, 다람쥐와 청설모 사진을 전부 보고 있다면 객체 간의 차이점을 통해 오인의 가능성이 줄어드는 효과를 불러오기 때문입니다. 따라서 템플릿을 불러오게 될 때 다른 카테고리도 같이 불러오도록 구성 하였으며, 이 때 같은 카테고리는 가깝게, 다른 카테고리는 멀게 만들어주는 방법이 필요하다고 판단하여 학습 시 contrastive loss를 추가해 주었습니다.
4. Experiments
본 연구에서는 제안한 few-shot visual grounding 모델의 성능을 보다 구체적으로 입증하기 위해 두 가지 주요 실험을 설계하고 수행하였습니다. 첫 번째 실험에서는 다양한 기존의 비주얼 그라운딩 모델과 비교하여, 제안된 FS-learnable embedding을 포함한 Dynamic MDETR 모델의 성능을 평가하는 것을 목표로 하였습니다. 이 실험에서는 지원 세트(Support Set)를 제공하는 템플릿이 모델의 성능에 미치는 구체적인 영향을 분석하였습니다. 구체적으로, 템플릿 없이 수행된 기본 모델의 성능과 템플릿을 활용한 모델의 성능을 비교함으로써, 템플릿의 사용이 얼마나 성능 향상에 기여하는지 확인하였습니다. 또한, 러너블 임베딩(FS-learnable embedding)을 도입하여 그 자체가 모델의 학습 능력을 어떻게 증대시키는지 구체적으로 분석하였습니다. 이를 통해 템플릿과 러너블 임베딩이 함께 적용된 모델이 경쟁 모델 대비 유의미한 성능 향상을 보였음을 입증하였습니다. 두 번째 실험은 학습되지 않은(Unseen) 클래스에 대한 모델의 일반화 성능을 평가하는 데 중점을 두었습니다. 이 실험에서는 Fusion 모듈과 Contrastive Loss가 unseen 데이터에 대해 어떻게 모델의 성능을 향상시키는지 분석하였습니다. 먼저, unseen 클래스에서 기본 모델의 성능을 측정한 후, 제안된 Fusion 모듈과 Contrastive Loss를 결합하여 적용한 결과를 비교하였습니다. 결과적으로, 두 모듈을 적용한 모델이 unseen 클래스에서도 높은 성능을 유지함으로써, 제안된 방법이 일반화 성능을 효과적으로 향상시키는 것을 확인할 수 있었습니다. 두 실험을 통해 템플릿의 사용과 러너블 임베딩의 도입이 모델의 학습과 일반화 성능에 미치는 긍정적인 영향을 다각도로 검토하였으며, 이러한 분석 결과는 제안된 모델이 기존의 few-shot visual grounding 문제에서 실질적인 성능 향상을 달성했음을 보여줍니다.
Dataset
Pretrain
RefCOCO 데이터셋

RefCOCO는 COCO 이미지 내의 객체를 자연어로 설명한 대규모 데이터셋으로, 총 19,994개의 이미지와 142,209개의 참조 표현이 포함되어 있습니다. 이 데이터셋의 주요 목표는 COCO 이미지에서 지정된 객체를 정확하게 찾는 것입니다. 템플릿 기반 모델에서 템플릿의 유무가 성능 향상에 중요한 영향을 미친다는 점을 확인할 수 있었습니다. Flickr30k 데이터셋
Flickr30k는 Flickr 이미지에 대한 자연어 설명을 제공하는 데이터셋으로, 총 31,000개의 이미지가 있으며 각 이미지에는 5개의 참조 문장이 제공됩니다. 이 데이터셋은 unseen 데이터에 대한 few-shot visual grounding 문제를 해결하는 데 매우 중요한 역할을 합니다. 기존에 학습되지 않은 새로운 클래스에 대해 적은 수의 샘플만을 사용하여도 성능을 평가할 수 있도록 설계되었습니다.
Finetuning
RefCOCOg 데이터셋

RefCOCOg는 RefCOCO 데이터셋을 기반으로 더 복잡한 설명을 추가한 데이터셋입니다. 총 25,799개의 이미지와 142,209개의 참조 표현이 있으며, 70개의 클래스를 학습에 사용하고, 10개의 클래스를 평가에 사용하여 성능을 확인합니다. RefCOCOg 데이터셋은 더욱 복잡한 문장 구조와 다양한 객체 관계를 포함하고 있어 모델이 다양한 시나리오에서의 성능을 검증하는 데 유리합니다.
Eval (RefCOCOg)
Template의 유무가 성능 향상에 미치는 영향
Methods Backbone Support set Accuracy
TransVG ResNet-101
67.02%
TransVG ResNet-50
66.56%
TransVG++ ResNet-50
73.86%
GroundVLP Vin-VL
74.73%
Dynamic MDETR ResNet-50
69.43%
Dynamic MDETR + FS-learnable embedding (ours) ResNet-50 ✔ 83.6%
첫 번째 실험에서는 Dynamic MDETR + FS-learnable embedding (ours) 모델이 기존의 다른 비주얼 그라운딩 모델들(TransVG, TransVG++, GroundVLP 등)과 비교되었습니다. ResNet-50을 백본으로 사용한 모델들 간 비교에서 제안된 모델은 83.6%의 정확도를 기록하며, 가장 높은 성능을 나타냅니다. 특히 TransVG 모델(ResNet-50)의 66.56%와 비교했을 때, 약 17%의 성능 향상이 있었음을 확인할 수 있습니다. 이는 템플릿 기반 지원 세트가 모델 성능에 큰 영향을 미쳤음을 시사하며, 특히 유사한 클래스 간 혼동을 줄이고 러너블 임베딩을 통해 더 세밀한 특징 학습이 이루어졌기 때문입니다. 즉, 템플릿의 도입은 모델이 다양한 시각적 정보를 더 풍부하게 학습할 수 있게 하여 클래스 간 차이를 명확하게 구분하게 만들었습니다. 따라서 기존의 모델 대비 더 높은 성능을 보여줄 수 있었습니다. 해당 실험을 통해 템플릿의 유무가 성능 향상에 크게 기여하였으며, 템플릿을 효과적으로 학습하는 것이 모델 성능을 강화하는 데 중요함을 확인하였습니다.
Unseen data에 대한 few-shot visual grounding (*Fu: Fusion Module, **CI: Contrastive Loss)
Methods Backbone Accuracy AP
Ours ResNet-50 0.30 0.53
Ours + Fu* ResNet-50 0.39 (+0.09) 0.58 (+0.05)
Ours + CI** ResNet-50 0.38 (+0.08) 0.60 (+0.07)
Ours + Fu* + CI ResNet-50 0.39 (+0.09) 0.60** (+0.07)
두 번째 실험은 학습하지 않은 데이터에 대한 few-shot visual grounding 성능을 평가하는 데 초점을 맞춥니다. 단순히 FS-learnable embedding만을 도입한 Ours 모델은 정확도 0.30, AP(Average Precision) 0.53을 기록하였습니다. 그러나 Fusion 모듈(Fu)을 추가하였을 때 정확도는 0.39로 9% 상승하였고, AP는 0.58으로 5% 증가하였습니다. 이는 Fusion 모듈이 템플릿 간 상호작용을 더욱 효과적으로 통합하며, 서로 다른 템플릿 간 정보의 상호 교류를 통해 성능을 향상시켰음을 보여줍니다. 또한, Contrastive Loss(CI)를 추가한 경우에도 유사한 성능 향상이 나타났습니다. Contrastive Loss는 템플릿 간 유사성과 차이점을 명확하게 학습하게 하여 학습되지 않은 클래스에서도 모델이 템플릿의 차별적 특징을 더 잘 파악할 수 있도록 돕습니다. 최종적으로 두 방법을 모두 적용한 경우 0.39로 최고의 성능을 보였으며, 이는 unseen 클래스에 대해 모델이 더 나은 일반화 성능을 발휘할 수 있음을 시사합니다. 이러한 학습 메커니즘 덕분에 unseen 클래스에 대한 모델의 일반화 능력이 크게 향상된 것을 확인할 수 있었습니다. 해당 실험을 근거로 템플릿의 유무 및 상호작용을 강화한 Fusion 모듈과 템플릿 간 차별성을 학습한 Contrastive Loss가 제안된 모델의 성능 향상에 중요한 기여를 했다고 볼 수 있습니다.
Visualization
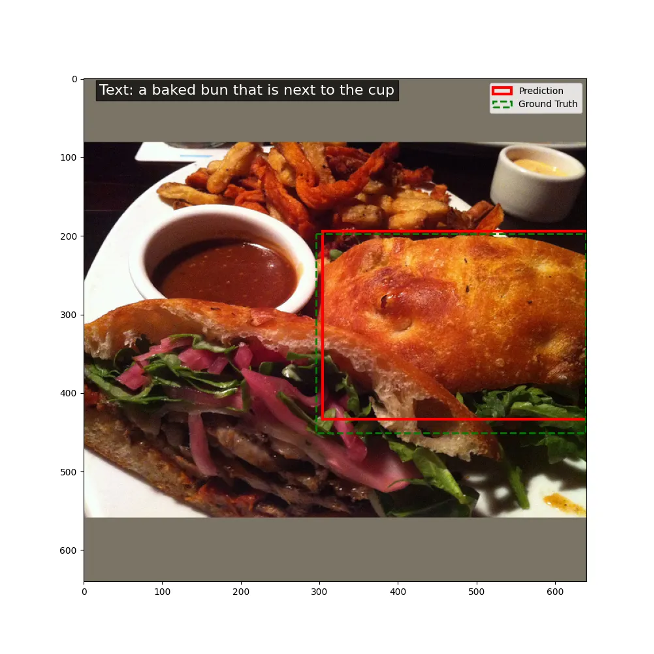


위 시각화 결과는 제안된 모델이 텍스트와 이미지를 얼마나 정확하게 일치시키는지를 보여줍니다. 세 가지 예시를 통해 시각적으로 평가할 수 있습니다:
- 첫 번째 이미지: "컵 옆에 있는 구운 번"이라는 텍스트와 함께 제공된 이미지는 정확하게 번을 찾아냅니다. 모델이 컵 옆의 구운 번을 제대로 예측한 것을 확인할 수 있습니다.
- 두 번째 이미지: "거울에 반사된 것이 아닌 흰색 실제 세면대"라는 텍스트와 일치하는 이미지는, 거울의 반사물과 실제 세면대 간의 차이를 구분하며, 실제 세면대를 정확하게 찾습니다. 이는 모델이 복잡한 장면에서도 세부적인 차이를 구별할 수 있음을 보여줍니다.
- 세 번째 이미지: "빨간색 수프가 담긴 컵"이라는 텍스트에 대해 모델은 정확하게 수프가 담긴 컵을 식별해냈습니다. 모델이 명확하게 해당 물체를 인식할 수 있음을 보여줍니다.
이 시각화는 모델이 다양한 상황에서 텍스트의 의미를 정확하게 해석하고, 그에 맞는 이미지를 성공적으로 찾을 수 있음을 시사합니다.
Inference (Hachuping)
티니핑 캐릭터를 활용한 few-shot grounding 테스트에서 평가한 성능은 모델의 일반화 능력입니다. 이는 모델이 새로운 데이터셋이나 이전에 학습되지 않은 캐릭터에 대해서도 적절한 시각적 객체를 텍스트 설명과 매칭하여 인식할 수 있는지를 평가하는 데 중점을 둡니다. 이러한 성능은 특히 few-shot 학습에서 중요한데, 적은 수의 샘플만을 사용하여도 모델이 새로운 상황에 적응하고 정확하게 예측할 수 있는지를 확인하는 것입니다. 이번 실험에서는 티니핑이라는 이전에 학습하지 않은 캐릭터 데이터셋을 활용하여 모델의 적응력을 평가했습니다. 모델이 다양한 텍스트 설명에 대해 해당 캐릭터를 정확하게 찾아내는 능력을 기반으로, 모델의 성능이 새로운 데이터에 대해 얼마나 효과적으로 일반화될 수 있는지를 검증한 것입니다. Few-shot grounding 테스트는 이러한 일반화 능력을 명확하게 드러내며, 티니핑 같은 새로운 데이터셋에서도 우리 모델이 효과적으로 동작한다는 것을 확인하게 됩니다.
Visualization
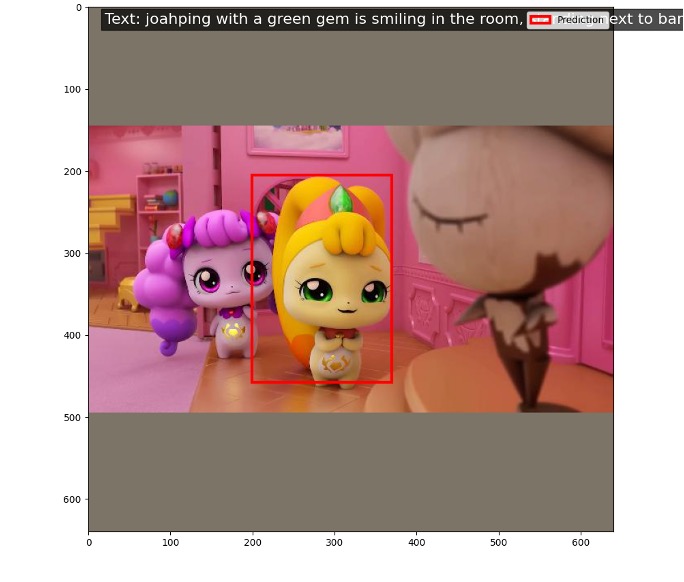
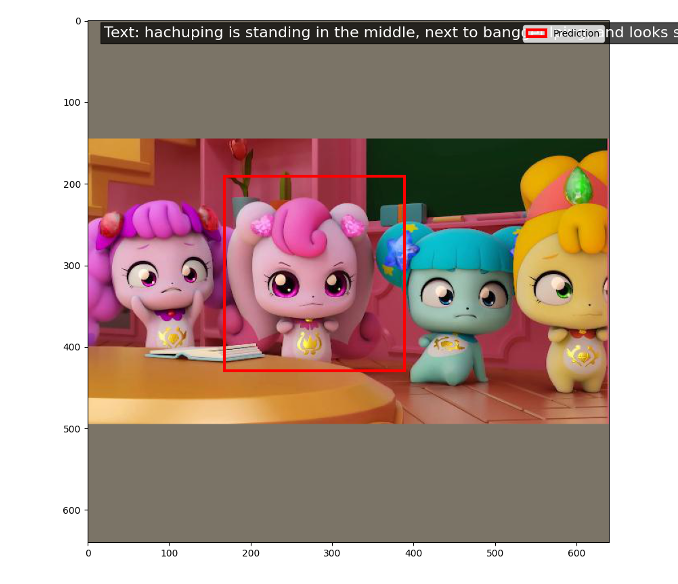
첫 번째 결과는 조아핑(JoahPing)이 방글핑(BanggeulPing) 옆에 서 있고 카메라를 향해 있다는 설명입니다. 모델은 조아핑을 정확하게 찾아내어 예측과 실제 값이 일치하는 것을 볼 수 있습니다. 이는 모델이 주어진 텍스트를 기반으로 올바른 시각적 객체를 효과적으로 인식할 수 있음을 보여줍니다. 두 번째 결과는 하츄핑(HachuPing)이 가운데에 서 있으며 방글핑 옆에서 웃고 있다는 설명입니다. 이 경우에도 모델은 하츄핑을 정확하게 인식하여 텍스트에서 요구한 캐릭터와 위치를 제대로 찾아내었습니다. 이는 모델이 두 개의 서로 다른 텍스트 설명을 기반으로 다양한 객체를 정확하게 매칭할 수 있음을 보여주며, 특히 새로운 캐릭터들에 대해서도 few-shot 학습이 효과적이라는 것을 나타냅니다. 이 결과들은 few-shot grounding 모델이 티니핑과 같은 새로운 데이터셋에서도 높은 수준의 정확도를 보이며, 제시된 시각적 객체를 텍스트 설명에 맞춰 성공적으로 찾아내는 능력이 있음을 확인할 수 있습니다.
5. Conclusion
본 연구는 기존의 few-shot visual grounding 모델들이 가지는 한계를 극복하기 위해 Dynamic MDETR 모델을 기반으로 FS-learnable embedding과 템플릿 기반의 지원 세트(Support Set)를 활용한 새로운 방법론을 제안하였습니다. 제안된 모델은 텍스트와 이미지 간의 상호작용을 극대화하고, 지원 세트를 통해 적은 학습 데이터로도 성능을 향상시키는 것이 핵심입니다. 실험 결과, 다양한 baseline 모델들과 비교했을 때 제안된 모델이 더 높은 성능을 기록하였으며, 특히 Fusion 모듈과 Contrastive Loss를 활용하여 unseen 클래스에서도 우수한 성능을 보였습니다. 이러한 결과는 템플릿과 러너블 임베딩의 조합이 모델의 전반적인 성능에 큰 기여를 한다는 것을 입증하였습니다.
Limitation
본 연구는 많은 성과를 보였지만, 여전히 해결해야 할 몇 가지 한계가 있습니다:
- 템플릿 의존성: 모델의 성능은 제공된 템플릿의 품질과 다양성에 크게 의존합니다. 만약 템플릿이 특정 도메인에 제한적이거나 학습 데이터와 유사하다면 성능이 떨어질 수 있습니다. 미래 연구에서는 템플릿의 다양성을 증가시키고, 자동으로 템플릿을 생성하거나 더 많은 도메인에 적용 가능한 방식으로 템플릿을 확장하는 방법이 필요합니다.
- 모델의 학습 비용: 러너블 임베딩과 Fusion 모듈을 도입하면서 모델의 구조가 복잡해졌고, 그로 인해 학습 비용이 증가했습니다. 이는 학습 시간이 길어지거나 GPU 메모리의 효율성이 떨어지는 문제를 야기할 수 있습니다. 향후 연구에서는 모델의 경량화와 효율적인 학습 방법을 도입하여 학습 비용을 줄이는 방안을 모색해야 합니다.
- Unseen 클래스의 처리 한계: unseen 클래스에 대한 성능은 비교적 우수했으나, 일부 클래스에서는 여전히 제한된 성능을 보였습니다. 특히, 새로운 클래스가 기존 템플릿과 크게 다른 경우에는 성능 저하가 발생할 수 있었습니다. 이를 해결하기 위해서는 unseen 클래스를 더 효과적으로 처리할 수 있는 더 강력한 대안적인 학습 방법, 예를 들어 Zero-shot Learning 기법이나 더 강력한 contrastive 학습 기법을 고려할 필요가 있습니다.
Contribution
- FS-learnable embedding 도입: 제안된 FS-learnable embedding은 템플릿의 시각적 및 언어적 정보를 효과적으로 결합하여 모델의 학습 능력을 크게 향상시켰습니다. 이는 특히 few-shot 상황에서 적은 데이터로도 높은 성능을 보이는 중요한 기여입니다. 이 방법은 템플릿을 활용해 학습 효율성을 크게 높이는 효과를 가져왔습니다.
- 템플릿 기반 지원 세트(Support Set) 활용: 템플릿을 활용하여 지원 세트를 제공함으로써, 모델이 더 효과적으로 시각적 및 텍스트 정보를 결합하여 더 높은 성능을 달성할 수 있도록 했습니다. 이는 기존 모델들이 지원하지 못했던 부분에서 큰 개선을 보여주었습니다. 특히 few-shot 상황에서 다양한 템플릿을 통해 지원되는 학습이 성능 향상에 중요한 역할을 했습니다.
- Unseen 데이터에 대한 일반화 성능 개선: unseen 데이터에서의 성능을 높이기 위해 Fusion 모듈과 Contrastive Loss를 도입하여 클래스 간 차이를 학습하고, 이를 통해 더 높은 일반화 성능을 확보하였습니다. 이로 인해 본 연구는 다양한 클래스에서 모델이 더욱 robust하게 작동하도록 설계되었습니다.
이러한 기여들을 통해 본 연구는 few-shot visual grounding 문제를 해결할 수 있는 새로운 방법을 제시했으며, future works를 통해 더 나은 성능을 보일 가능성을 제시하였습니다.