
당신은 ‘이’ 상한 사람입니까?
1. 들어가며
안녕하세요! 저희는 Medical AI의 📷 찰칵찰칵 팀입니다.
***여러분의 치아 다들 건강하신가요? *🔎 🦷**
저희는 ‘치아 X-ray 이미지를 분석하여 4가지의 치아 질환 진단’을 주제로 프로젝트를 진행하였습니다.
2. Motivation
a. 치아 질환 진단 모델이 왜 필요할까?
여러분은 치과 의사 마다 ‘충치’에 대한 진단 기준이 다르다는 것을 아시나요? 치과를 찾을 때마다 진단 받는 충치의 개수가 다른 경우도 종종 발생합니다. ‘충치’가 가지고 있는 특성 상 치료가 필요한 치아와 치료가 필요하지 않는 치아로 나누어 진단할 수 있습니다. 충치 발생 시기와 환자의 나이 등에 따라 충치 치료의 필요 여부가 달라지기 때문에 충치에 대한 진단이 의사마다 다르다고 합니다. 하지만 충치 치료가 필요하지 않다고 판단 되더라도 지속적인 관심과 관리를 통해 충치 진행을 막아야 합니다. 이에 인공지능을 활용한 치아 질환 진단 모델로 치료가 필요한 충치와 함께 육안으로 검진할 때 눈에 잘 띄지 않는 충치 까지도 진단할 수 있습니다. 충치 이외에도 치과 의사의 기준에 따른 상이한 진료 보다도 더 일관성 있고 섬세한 진단을 통해 서로 다른 여러 질환을 예방할 수 있습니다.
b. 상대적으로 부족한 치아 질환 연구
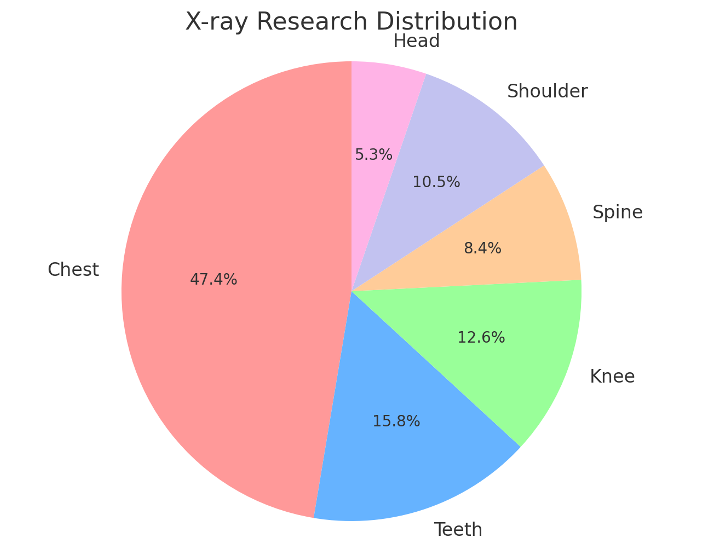
오늘날 X-ray 이미지를 입력으로 인공지능 모델을 통해 질환을 진단하는 방식은 다양한 신체 부위에 적용되고 있습니다. 아래의 X-ray 연구 분포 현황을 보았을 때 47.4%는 모두 흉부에 집중이 되어 있습니다. 반면에 치아는 흉부 다음으로 큰 수치를 가지고 있지만, 전체에 15.8%에 불과합니다. 즉, 흉부를 제외한 모든 부위에 대해서 X-ray 연구가 부족하다는 사실을 알 수 있습니다.
c. 이진 분류에 국한되어 있는 기존의 모델
질환에 대해 진단하는 모델은 크게 이진 분류와 다중 분류로 나눌 수 있습니다. DeNTNet과 같은 이진 분류 모델은 특정 질환에 대해 있다, 없다 만을 판단합니다. 다시 말해 충치를 진단하는 이진 분류 모델은 치아가 충치인지 정상 치아인지로만 구분합니다. 지금까지 선행 연구된 치아 질환 진단 모델은 대부분 이진 분류에 국한되어 있습니다. 치과 의사들이 참고할 만한 모델을 개발하기 위해서는 이진 분류만으로는 불충분합니다. 진단을 하는 과정에서 놓치고 있던 치아 질환을 알아내기 위해서 여러 질환에 대해 분류할 수 있는 다중 분류 모델이 필요합니다.
3. Methodology
a. VLM
- VLM(Vision Language Model)이란?
VLM(Vision Language Model)은 컴퓨터 비전과 자연어 처리를 결합하여 이미지와 텍스트 데이터를 동시에 처리하는 모델을 의미합니다. 이미지를 입력을 받아 이미지 내의 객체를 탐지하거나 이미지의 특징을 추출하는 등의 역할을 수행합니다. 이에 더하여 자연어 처리를 통해 이미지에 대한 설명 혹은 질의 응답을 생성하기도 합니다. 저희는 “GeoChat : Grounded Large Vision-Language Model for Remote Sensing”에서 소개한 VLM 모델을 파인 튜닝하여 치아 X-ray 이미지에서 질환 별로 Bounding Box를 생성하고자 합니다.
- GeoChat
GeoChat은 이미지와 텍스트를 동시에 처리할 수 있는 멀티 모달 대화형 AI 모델입니다. GeoChat은 Remote sensing 이미지에 특화되어 이미지를 분석하며 다음과 같은 기능을 수행할 수 있습니다.
- Image-Level Conversation Tasks
: Visual Question Answering(VQA), Scene Classification
- Region-Level Conversation Tasks
: Region-Level Captioning, Region-Specific VQA
- Grounded Conversation Tasks
: Grounded Image Captioning, Referring Expression Detection 저희 팀은 GeoChat의 여러 기능 중에서도 Referring Expression Dectection을 이용하였습니다. 사용자는 “Where are Deep Caries Teeth?”라고 질문하였을 때 ‘Deep Caries(깊은 충치)’에 해당하는 치아만을 찾아 이미지 내의 Bounding Box로 찾아내는 방식입니다. Remote Sensing 이미지** : 물체나 환경에 직접 접촉하지 않고 위성, 항공기, 또는 드론과 같은 원격 장치를 통해 수집한 이미지*
GeoChat은 어떻게 만들어졌을까요? GeoChat 모델의 전반적인 구조에 대해 알아 봅시다. GeoChat 모델은 크게 Visual Backbone, MLP Adaptor, LLM 3가지로 이루어집니다.
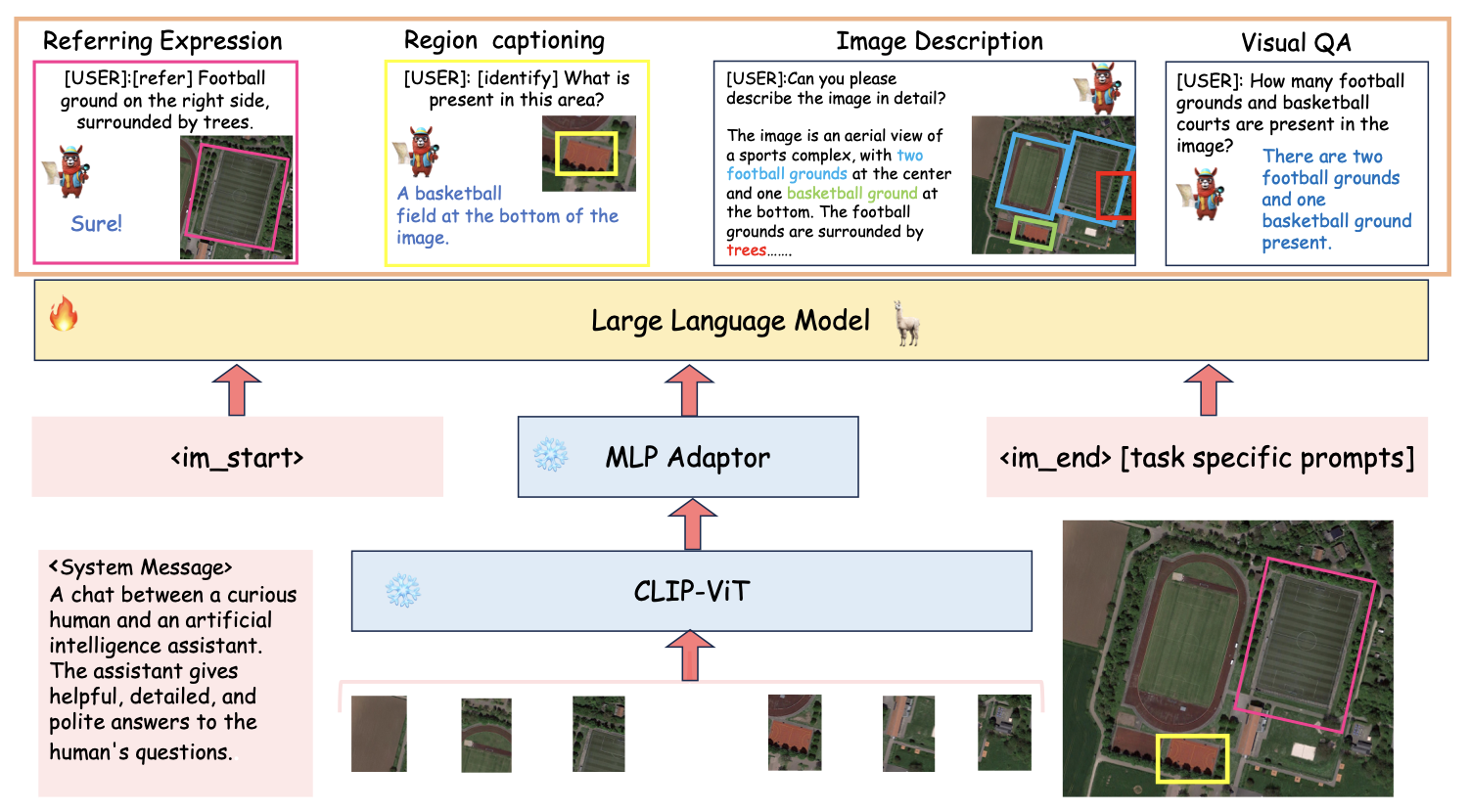
- Visual Backbone
CLIP-ViT 모델을 기반으로 패치 단위의 이미지 정보를 인코딩하는 역할을 담당합니다. 여기서 Remote Sensing 이미지에 있는 더 작은 객체나 세부 사항을 파악하기 위해 위치 인코딩을 보간하여 더 높은 해상도를 처리할 수 있도록 하였습니다. 이를 통해 입력 이미지 해상도를 336x336에서 504x504로 확장하여 더 작은 객체나 고해상도 정보를 보다 더 정확하게 분석할 수 있습니다.
- MLP Adaptor
MLP Adaptor는 Visual BackBone에서 출력된 토큰을 LLM의 입력 크기로 변환합니다. 활성화 함수로 GeLU를 사용하여 비선형성을 추가하여 Visual Backbone의 출력인 1024차원을 LLM의 입력인 4096 차원으로 조정합니다.
- LLM
LLM은 이미지 데이터를 텍스트와 결합하여 자연어 응답을 생성합니다. GeoChat에서는 사전 학습된 Vicuna-v1.5을 사용하였습니다. LoRA 기법을 통해 모든 가중치가 아닌 작은 행렬을 조정하여 더 높은 훈련 속도와 함께 기존의 지식을 유지하면서 모델을 파인튜닝하였습니다.
b. 데이터 전처리
- Dentex 2023 데이터셋
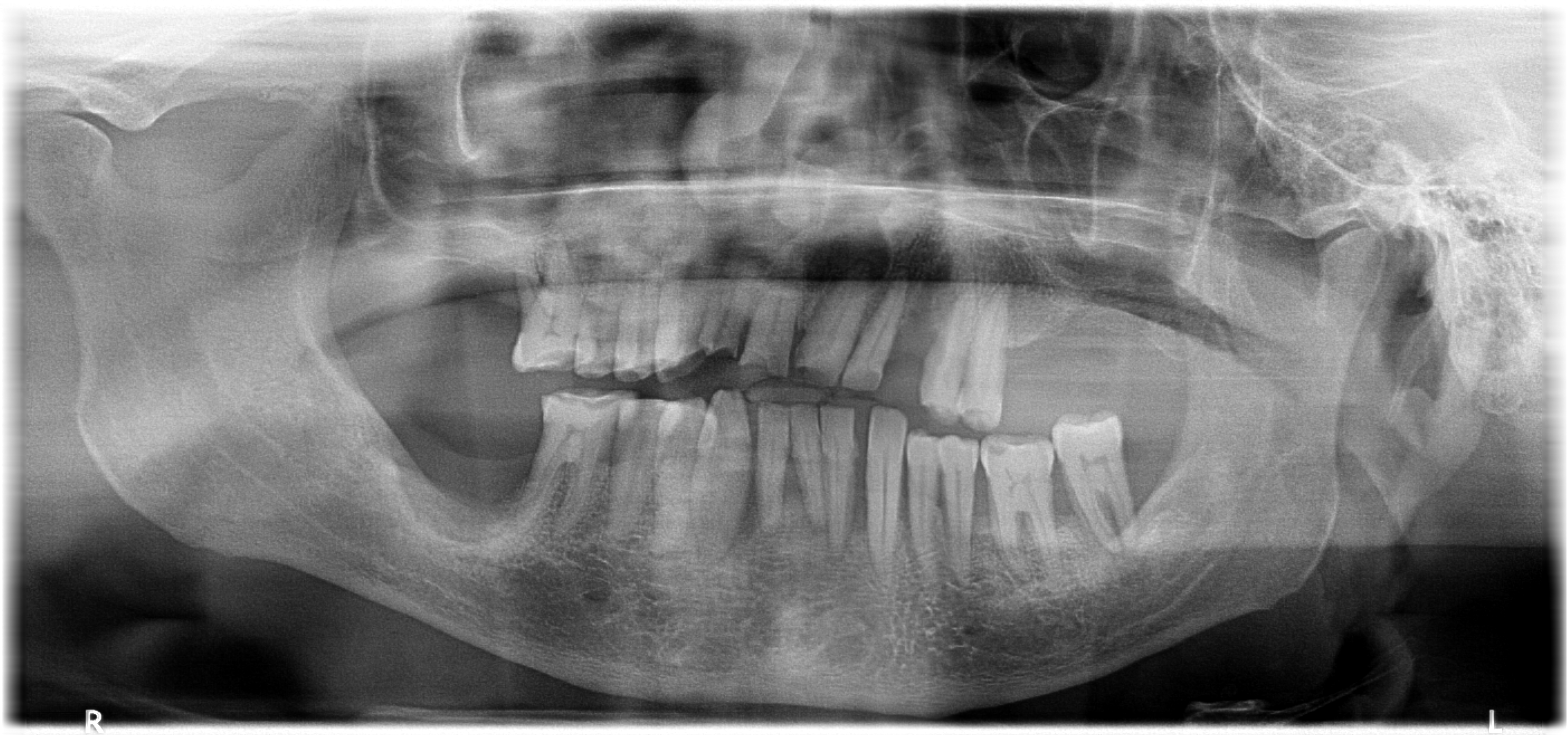
저희는 여러 치아 질환에 대해 분류하기 위해 Dentex에서 2023년에 제공한 파노라마 치과 X-ray 이미지 기반의 데이터셋을 사용하였습니다. 해당 데이터셋은 FDI 치아 번호 체계를 활용해 치아 번호, 사분면으로 위치를 표현하면서 해당 질환이 존재하는 치아에 대한 Bounding box에 대한 주석도 포함되어 있습니다. 또한, Impacted Teeth(매복 치아), Periapical Leisons(치근단 병변), Deep Caries(깊은 충치), Caries(충치)로 4가지의 치아 질환에 대해 각각 0, 1, 2, 3으로 라벨링이 되어 있어 여러 개의 치아 질환에 대해 학습하고 이를 진단할 수 있습니다.
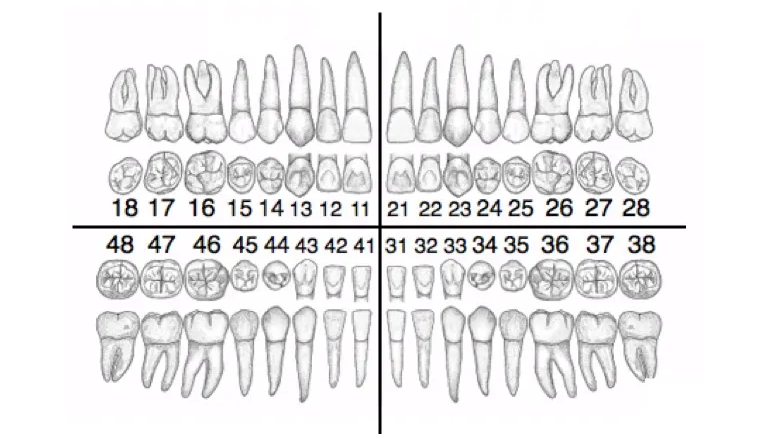
FDI 치아 번호 체계란❓ FDI 치아 번호 체계는 세계 치과 연맹(Federation Dentaire Internationale, FDI)에서 제정한 방식으로 치아의 위치를 사분면과 치아 번호로 정의합니다. 각각 좌측 상부는 1, 우측 상부는 2, 우측 하부는 3, 좌측 하부는 4로 사분면을 지정합니다. 치아 번호는 앞니에서 어금니 쪽으로 가면서 1~8번까지 치아 번호로 정하는 방식입니다.
Data EDA
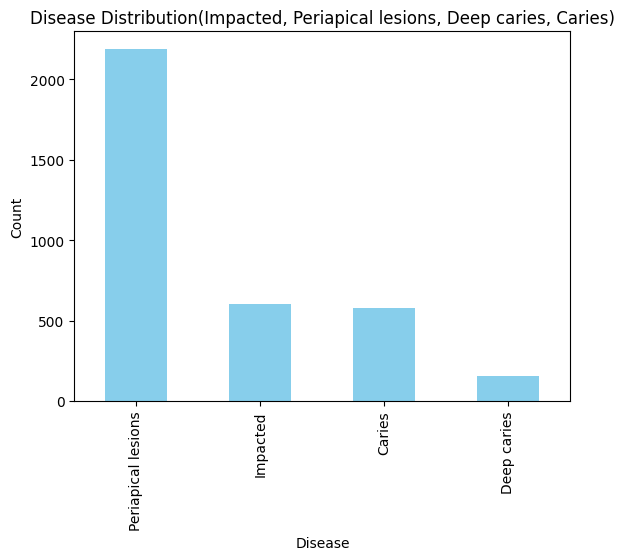
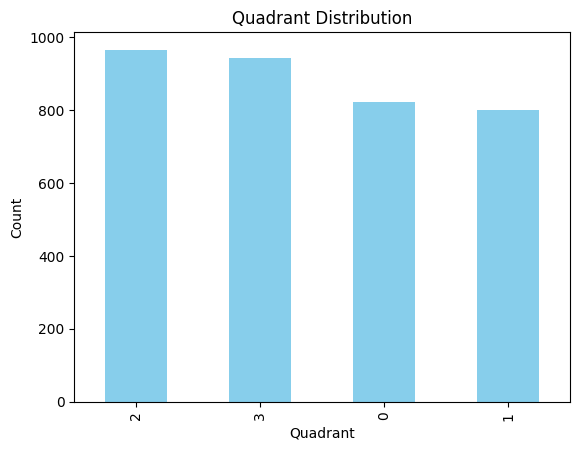
Dentex 데이터셋 중에서 질병이 라벨링 된 이미지만을 사용하여 Train과 Valid로 나누어 사용하였습니다. 총 705개의 이미지로 구성되어 있으며, 이미지 당 질환이 있는 치아 개수의 평균은 약 5.0056개입니다. 아래의 그림은 데이터셋의 (a) 질환 별 분포와 (b) 사분면 별 분포를 나타낸 그래프입니다. 아래의 그림을 통해 Periapical Lesions (2189) > Impacted (604) > Caries (578) > Deep Caries (158)로 Deep Caries와 Periapical Lesions가 10배 이상 차이나는 것을 보아 질환 별 데이터가 상당히 불균등하다는 것을 볼 수 있습니다.
(a) 질환 별 분포
(b) 사분면 별 분포
(c) 질환 별 분포 개수
Periapical lesions (치근단 병변) 2189
Impacted (매복치) 604
Caries (충치) 578
Deep caries (깊은 충치) 158
Data Split
Train과 Valid는 Dentex 데이터셋에서 Train 데이터셋 705개의 이미지, Test는 Dentex 데이터셋에서 Valid 데이터셋 46개의 이미지를 사용하였습니다. Train과 Valid는 705개의 이미지 중에서 각각 605개, 100개로 나누었습니다.
Train 605개
Valid 100개
Test 46개
- Data 전처리
아래의 이미지는 Dentex 데이터셋에서 볼 수 있는 json 데이터의 형식입니다.
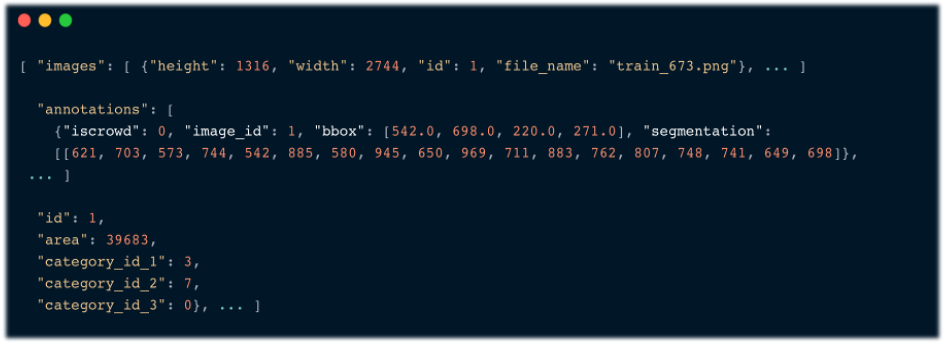
저희가 전처리 과정에서 사용한 데이터 정보는 다음과 같습니다.
의미 예
file_name 이미지 파일명 train_673.png
height 이미지의 높이 1316
width 이미지의 너비 2744
bbox 바운딩 박스에 대한 정보
category_id_1 사분면 (Quadrant) 3 (4분면)
category_id_2 치아 번호 (Enumeration) 7 (8번)
category_id_3 질병 (Disease) 0 (Impaceted Teeth)
Dentex 데이터셋의 정보를 활용해서 GeoChat에 데이터 형식에 맞게끔 변환하였습니다. id와 image는 이미지 파일명으로 통일하여 저장하였고 conversations에 해당하는 항목에는 각 질환 별로 질의응답을 생성하였습니다.
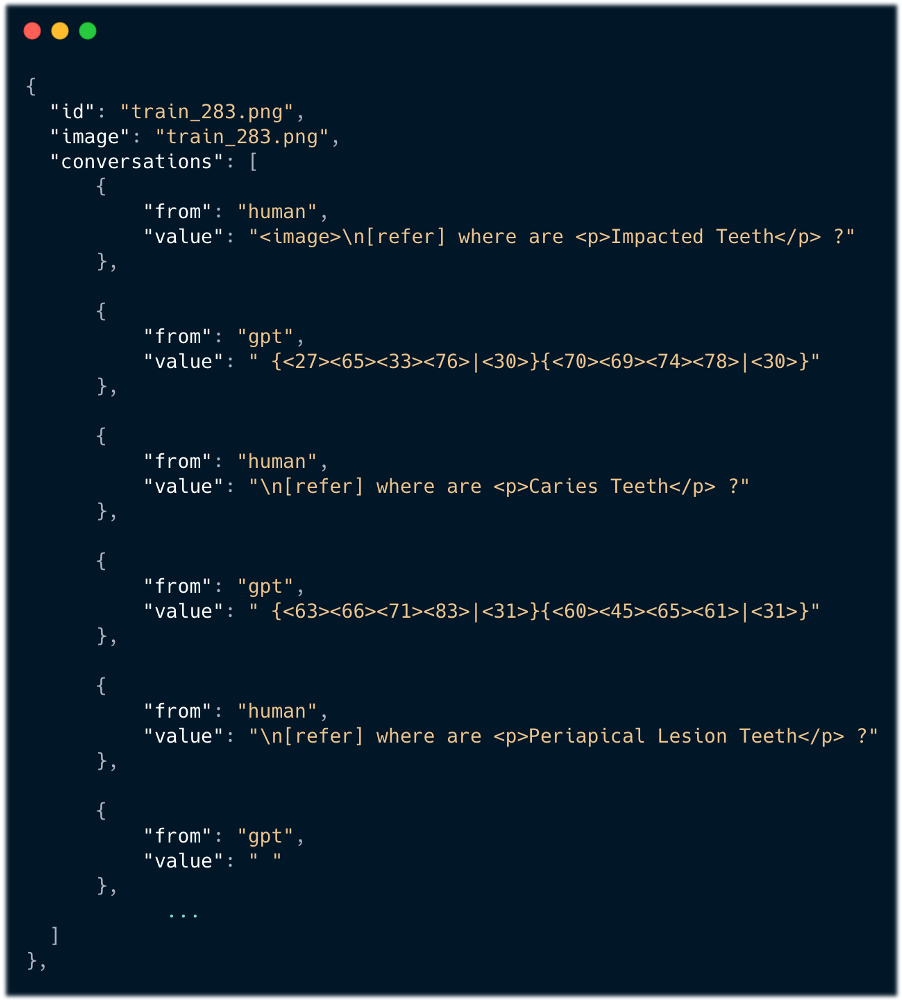
질의 응답이 어떻게 구성되어 있는지 자세히 확인해볼까요? 먼저, 질의는 간단하게 사용자가 모델에게 입력하는 말입니다. from : “human” 이라는 데이터로 질의임을 알 수 있습니다. 질의는 아래에 나와있듯이 같은 형식의 질문에 질환 명만 바꾸어서 질문을 하였습니다. 다음으로, 응답은 사용자의 질문에 모델의 대답입니다. 이도 마찬가지로 from : “gpt” 로 응답임을 알 수 있습니다. 응답에는 질문한 질환에 해당하는 치아의 위치 정보를 바운딩 박스를 통해 나타냅니다. 아래의 응답에서 <숫자>는 차례대로 바운딩 박스의 좌측 상단의 (x, y) 좌표와 우측 하단의 (x, y) 좌표로 나타내며 마지막에는 각 질환 별로 지정된 라벨이 출력됩니다.
- 질의
\\n[refer] where are 질환 명 ?
- 응답
{<좌측상단 x좌표><좌측상단 y좌표><우측하단 x좌표><우측하단 y좌표>|<질환 별 라벨>} …
🔎 질환 별 라벨 30: Impacted, 31: Caries, 32 Periapical Lesions, 33: Deep Caries
4. Experiments
a. 모델 학습 및 성능 평가
이미지와 전처리한 Json 데이터셋을 모델에 학습시키고, 이를 Gradio를 이용해 Test data를 집어넣어 결과를 수집했습니다. Gradio는 머신러닝 모델을 웹 앱 형태로 build하고 배포할 수 있도록 돕는 파이썬 라이브러리인데요, Gradio를 활용하면 모델의 performance를 쉽게 눈으로 볼 수 있습니다.
Gradio에게 질문을 하고 대답을 얻는 과정
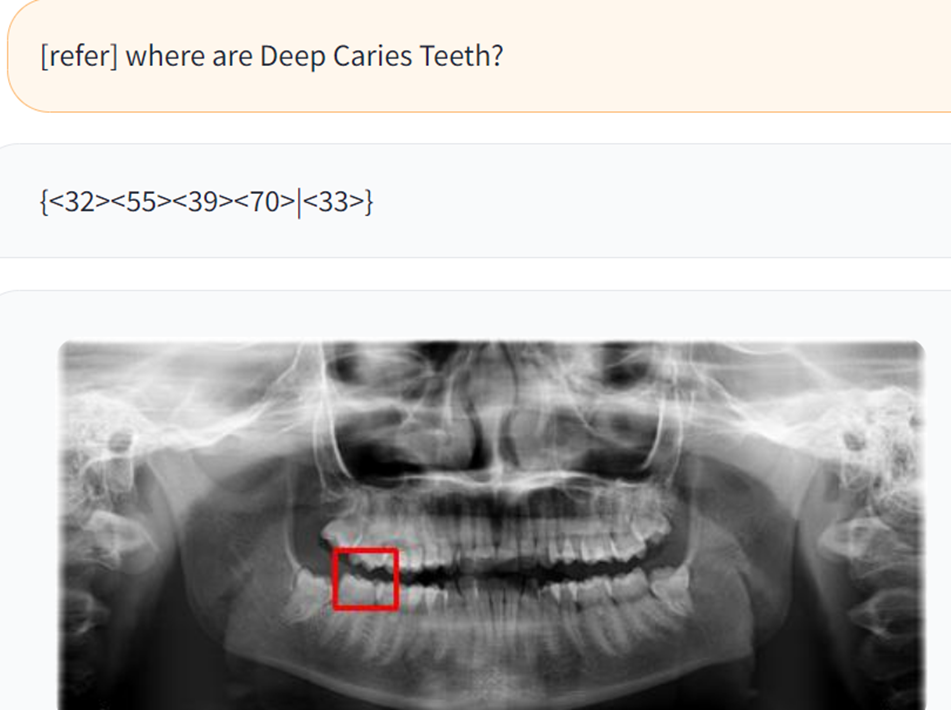
[refer]을 문두에 기입하고 우리가 얻고자 하는 정보에 대한 질문을 모델에게 던집니다. 물론 이 때 해당 치아의 X-ray 이미지도 같이 입력해줍니다.
약 10초 정도 후에 모델이 Bounding Box의 좌표
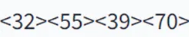
와 함께 질환의 클래스
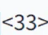
를 출력하는데요, 이 때 30은 Impacted, 31은 Caries, 32는 Peripical Lesion, 33은 Deep Caries를 의미합니다. 입력받은 이미지에 질환이 있는 치아를 Bounding Box로 출력을 해줍니다.
b. 모델 성능 평가 지표 산출 및 해석
성능 평가 지표
분류 모델의 평가 지표로는 보통 아래 5가지의 지표를 사용하는데요, 그 종류는 아래와 같습니다.
- Specificity
- Accuracy
- Precision
- Sensitivity(Recall)
- F1 score
위 다섯 지표는 혼동 행렬(Confusion Matrix)의 요소의 조합으로 산출되는데요, 해당 요소들은 모델의 예측 결과에 따라 True Positive, False Positive, True Negative, False Negative로 나누어집니다.
예측 클래스 예측 클래스
Positive Negative
실제 클래스 Positive True Positive(TP) False Negative(FN) Sensitivity \frac
실제 클래스 Negative False Positive(FP) True Negative(TN) Specificity \frac
Precision
Accuracy
\frac
\frac
먼저 Accuracy부터 살펴볼까요? Accuracy는 모든 Case 중 정확하게 맞춘 Case의 비율로, 모델이 전체적으로 얼마나 잘 맞추었는지를 보여주는 지표입니다. 하지만 Accuracy를 모델의 성능 지표로 활용할 때는 유의해야 할 것이 있는데요! 희귀한 질병의 경우에는 대부분 질병에 걸리지 않은 상태이기 때문에 높은 정확도의 의미가 없을 수 있겠죠?
다음은 Sensitivity입니다. Recall이라고도 부르는 Sensitivity는 실제 질병을 가진 환자를 모델이 얼마나 잘 찾아내는지 평가합니다. 수식을 보시면 알 수 있듯이 실제 양성 중에서 모델이 양성으로 옳게 예측한 case의 비율인데요, 양성 환자를 놓치지 않는 것에 집중합니다.
Specificity는 실제로 질병이 없는 사람을 음성으로 얼마나 잘 예측하는 지를 나타내는 지표로, 불필요한 치료나 검사를 줄이는데 도움이 될 수 있습니다.
Precision은 모델이 양성이라고 예측한 case 중 실제로 양성인 case의 비율입니다. 따라서 Precision이 높다면 양성 예측의 정확도가 높다고 할 수 있겠죠? 이 역시 Specificity와 마찬가지로 위양성을 줄이는 데 중요한 지표 입니다.
어라. 그런데 위 표에는 F1 score에 대한 내용이 없네요. F1 score는 정밀도와 민감도의 조화평균으로 수식으로 표현하면 다음과 같습니다. F 1 \text=2 \times \frac{\text \times \text}{\text+ \text} F1 score는 Sensitivity와 Precision 간의 균형을 맞춰야 하는 의료 분야에서 중요하게 다루는 지표입니다. 이를 적용하여 저희 모델이 Test data를 분류한 결과는 아래 표와 같습니다.
File_name Disease Caries Deep Caries Periapical Lesions Impacted
Test_0.png
TP FP FP FN
Test_1.png
TN TN FN FN
Test_2.png
TP TN FN TN
… … … … … …
Test_45.png
FP TN FN FP
아래는 분류 결과를 바탕으로 산출한 질환 별 모델의 분류 성능 지표입니다.
Caries Deep Caries Periapical Lesions Impacted
Accuracy 0.43 0.57 0.28 0.63
Specificity 0.04 0.66 0.67 0.78
Precision 0.42 0.07 0.7 0.54
Sensitivity 1 0.13 0.19 0.39
F1 score 0.59 0.09 0.30 0.45
음.. 지나치게 낮거나 높은 수치들이 보이네요. 먼저 Caries에 대한 Specificity가 0.04로 매우 낮게 나왔는데, 확인 결과 TN이 1, FP가 26으로, 음성인 치아를 양성으로 잘못 분류한 결과가 훨씬 많아 위와 같은 결과가 나왔습니다. 쉽게 말하자면 모델이 대부분의 치아에 대해 무분별하게 Caries가 있다고 판단했다는 것이겠죠? ㅠㅠ
Deep Caries의 Precision의 경우 TP가 1, FP가 13으로 모델이 양성으로 분류한 것 중 13개가 잘못 분류된 것이었음을 확인했습니다.
F1 score의 경우 Precision과 Sensitivity가 모두 낮아 F1 score 역시 낮게 나온 것입니다.
그렇다면 Caries의 Sensitivity가 1이 나왔으니 긍정적으로 볼 수 있는 걸까요? 안타깝게도 정답은 ‘아니오’입니다..ㅠㅠ
Sensitivity는 위에서 보았듯이 TP를 TP와 FN의 합으로 나눈 것인데요, Caries의 경우 TP는 19, FN은 0으로, 양성인 case에 대해 모델이 잘못 분류한 경우가 한 건도 없다는 뜻입니다. 여기서 의문이 들 수 있을텐데, 모델이 잘못 분류한 경우가 없으면 좋은 것 아닐까요? 물론 모델이 해당 case에 대해 좋은 성능을 보였다고 할 수도 있겠습니다. 하지만 저희가 앞서 살펴보았듯이 모델이 Caries에 대해 무분별하게 양성 판정을 내렸기 때문에 TP가 많고, FN이 적은 것입니다. 따라서 이 역시 모델의 성능이 좋다고 판단할 수 있는 근거가 되긴 어렵습니다.
5. Results
a. Contribution
비록 모델의 성능이 그다지 좋게 나오지는 않았지만, 분명히 고무적인 측면도 있었습니다.
여러 구강 질환에 대한 분류
먼저 하나의 치아 이미지에서 4가지의 구강질환을 탐지했다는 점입니다. 일반적으로 치과를 방문하는 이유는 충치를 치료하기 위함이기도 하지만, 충치 외에도 치근단 병변, 매복니, 치주질환 등 생각보다 정말 다양한 구강질환이 있습니다. 이들을 초기에 잘 발견하여 환자가 더 고통스럽게 하지 않는 것이 치과의사의 목표이구요. 따라서 저희는 충치를 포함한 4가지의 구강질환을 탐지할 수 있는 모델을 만들었다는 점에서 자부심.. 은 아니지만! 의미 있는 성과를 냈다고 생각합니다 ㅎㅎ
Bounding Box를 통한 가시성 확보
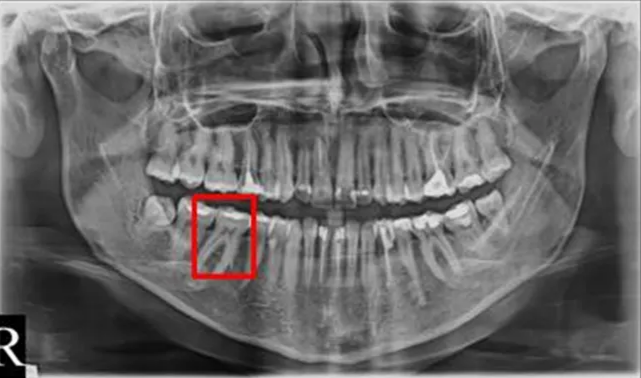
의사가 환자에게 설명을 해준다고 가정을 해봅시다. “우측 상악의 4번 치아가 충치가 심하네요.”라고 했을 때 과연 환자가 직관적으로 이해하고 위치를 파악할 수 있을까요?
저희 모델은 의사와 환자 모두가 이해하기 쉽게 질환이 있는 치아의 위치를 파악하여 Bounding Box로 표현했다는 점에서 의의가 있습니다.
b. Limitation
데이터의 부족
하지만 한계점 또한 많았습니다. 우선 의료 도메인 특성 상 환부의 사진은 환자 개인정보의 일부이다 보니 일반인이 접근할 수 있는 데이터가 많지 않았습니다. 특히 치아, 그 중에서도 질환 class가 labeling 되어있는 데이터가 적어 Train은 물론 Test를 하는 데에도 어려움이 있었습니다.
시간 부족으로 Fine Tuning과 타 모델과의 성능 비교 실패
SAM, GLaMM, Kosmos-2 등 다양한 모델을 검토하고 최종 Baseline 모델을 결정하는데 시간을 너무 많이 사용해버려 추가적인 Fine Tuning과 타 모델과의 성능 비교를 하지 못한 점도 아쉬운 점 중 하나였습니다. 성능 평가 지표의 절대적인 수치가 낮더라도 현존하는 타 모델과 비교해서 상대적으로 더 높다면 유의미한 성과일 것이고, 비교를 통해 추가적인 개선점을 파악할 수 있었는데 그러지 못한 것에 대해 아쉬움이 남습니다.
c. Future Plans
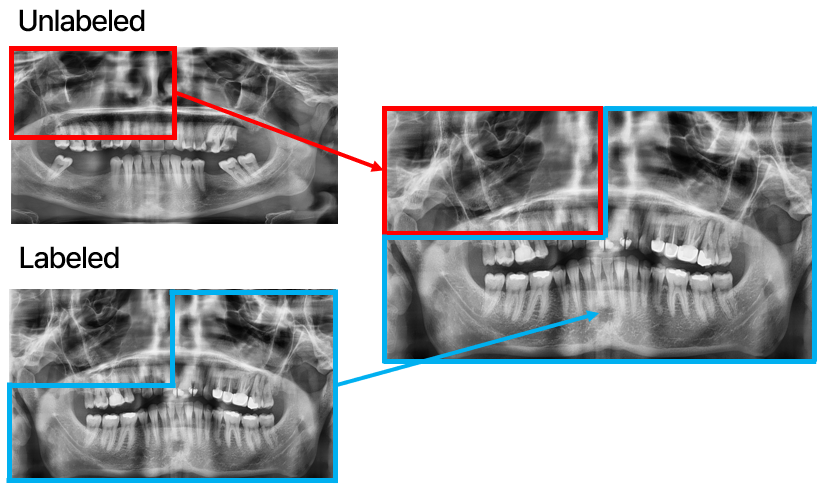
차후에 Unlabeled Data를 사용해 Unsupervised Domain Adaptation으로 데이터를 증강하고 Loss function을 수정하여 클래스 불균형을 해소하여 모델이 다양한 치아 상태에 대해 유연하게 학습할 수 있도록 할 계획입니다. Domain Adaptation은 전이 학습(Transfer Learning)의 일종으로, Train data와 test data의 분포가 다르지만, 같은 task를 적용할 때 사용되는 방법론입니다. 두 다른 도메인 간의 간격을 줄임으로써 분포를 비슷하게 만드는 것이 Domain Adaptation의 목표입니다. Unsupervised Domain Adaptation의 가장 큰 특징은 타겟 도메인의 라벨이 없어도 학습이 가능하고, End-to-End Learning이 가능하다는 것입니다.
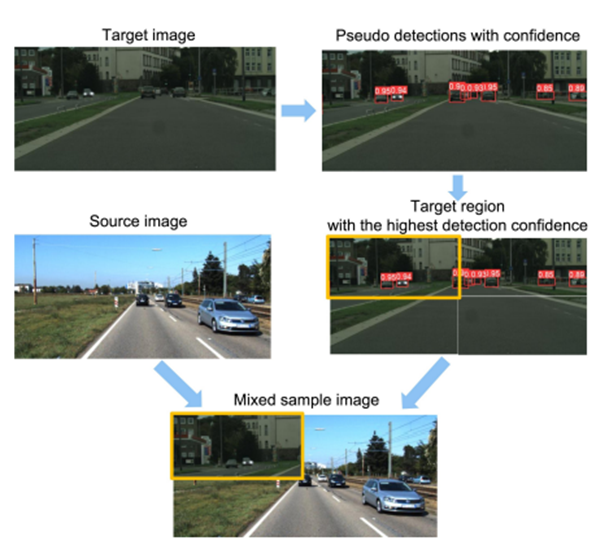
이러한 Unsupervised Domain Adaptation을 적용하면 아래와 같은 새로운 이미지를 얻을 수 있습니다.
앞으로 4개의 구강질환에 대한 분류 성능을 어느 정도 갖추고 나면, 더 다양한 구강질환으로 확장시킬 계획입니다. 저희가 다룬 4개의 질환 외에도 치아 균열, 치아 마모증 등 다양한 질환이 존재합니다. 이러한 질환도 탐지할 수 있는 모델을 만드는 것이 저희 목표입니다. 또한 치아 외에도 아직 연구가 부족한 다른 신체 부위에 대해 해당 모델을 학습 시키고자 합니다. 손, 발, 척추, 골반 등의 부위의 질환도 탐지할 수 있다면 정말 강력한 모델이 되겠죠? 현재는 저희 모델이 이미지와 질문을 입력 받아 질환이 있는 치아의 위치를 알려주는 것까지의 역할만 수행할 수 있는데요, 나아가 온전한 챗봇의 형태로 사용자와 대화를 주고받고, 질환의 정도에 따라 당장 치료 받아야 하는 상태인지, 경과를 지켜보아야 하는 상황인지에 대한 어드바이스도 의사에게 해줄 수 있게 하는 것도 시도해 볼 수 있겠습니다.