
1. Intro
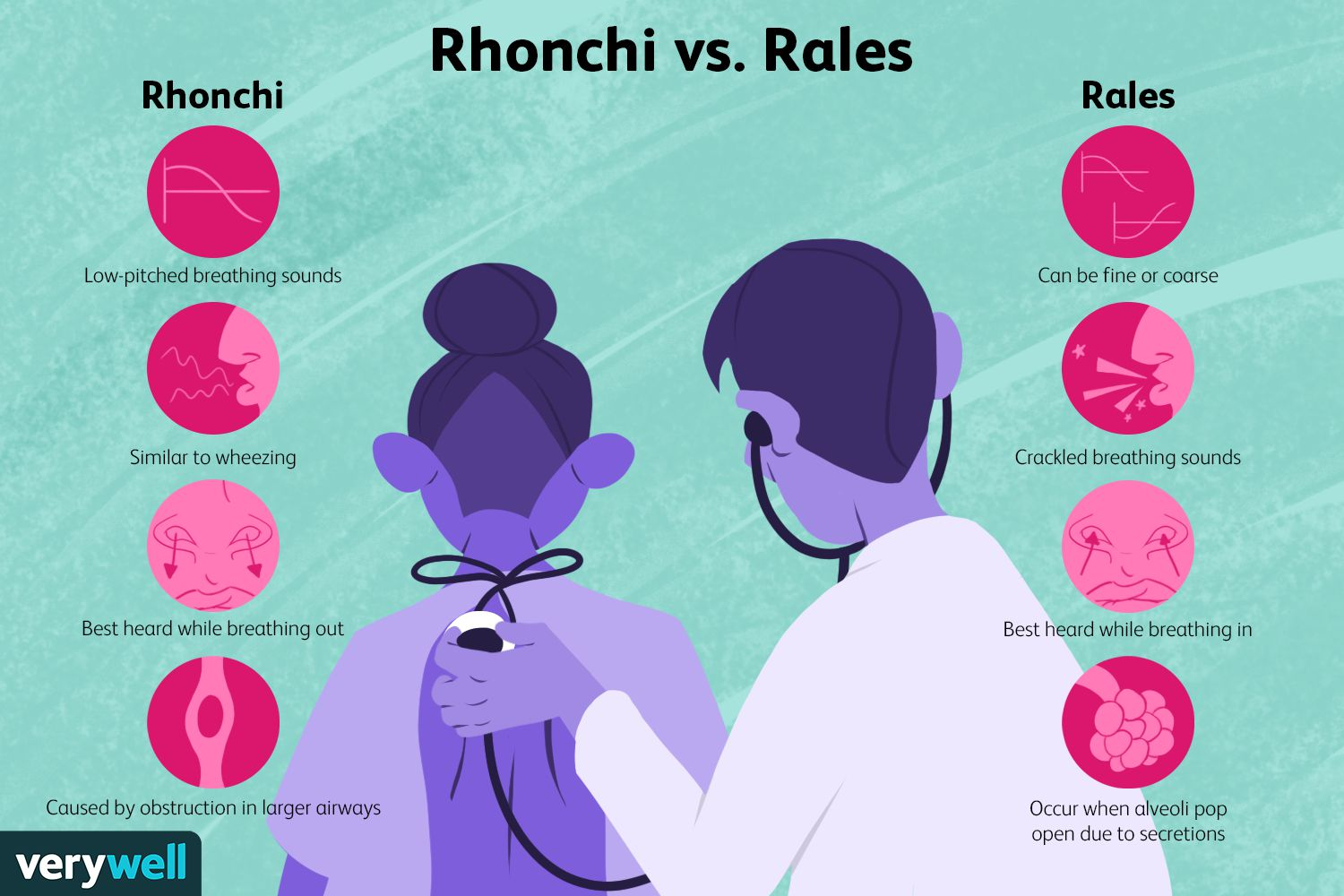
🧑⚕️: “숨 크게 들이 마시고 내쉬어 보세요.”
우리가 흔히 병원에 가면, 의사 선생님들이 청진기를 들고 몸 쪽에 갖다대시면서 하는 말씀입니다. 이 때 의사 선생님들은 뭘 하시는 걸까요? 바로 ‘숨 소리’, 즉 ‘호흡음’을 크게 듣게 됩니다. 이런 청진음을 통해 가래 소리나 천식으로 인해 숨이 찬 증상 등을 확인합니다. 이는 엑스레이를 찍기 전에도 질병을 감별할 수 있는 가장 기본적인 방법입니다. 그렇다면 호흡음 진단은, 어떤 소리를 듣고 어떻게 판단하는 걸까요?
2. 호흡음(Respiratory Sound) 진단이란?
청진하는 과정에서 특히 호기와 흡기 과정을 들으며 정상 호흡음과 비정상 호흡음을 구별해서 듣습니다. 특히 청진음에서는 들리는 ‘비정상 호흡음’으로 의심되는 호흡기 질환을 추리고, 확인합니다.
2.1 비정상 호흡음(Abnormal Respiratory Sound)
비정상 호흡음은 부잡음(Adventitious sound)라고도 불리며, 호흡기 질환을 앓는 환자에게 발생하는 소리를 말합니다. 대표적인 이상 호흡음 종류로는 천명음(Wheeze), 수포음(Crackle) 등이 있으며, 이상 호흡음마다의 소리의 형태, 지속 시간, 발현 주파수와 같은 소리의 특성이 달라 구분이 가능합니다.
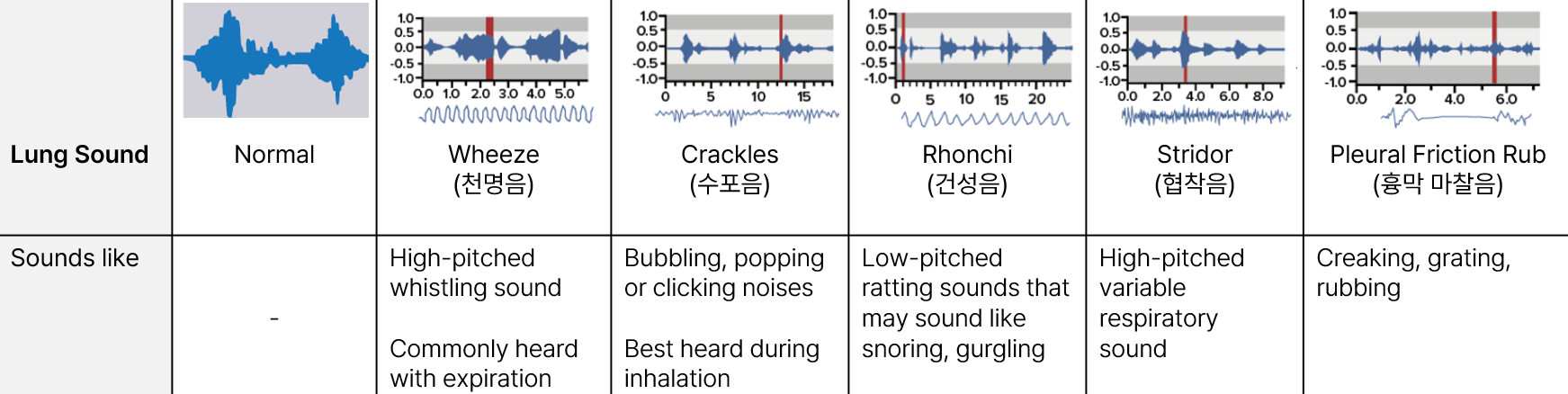
위의 표는 비정상 호흡음의 종류와 음성 특징에 대해 정리한 표입니다. 환자의 청진음 중 해당하는 비정상 호흡음에 따라 예상하는 호흡기 질환이 달라집니다.
비정상 호흡음 오디오 예시
Wheeze(천명음)
Crackles(수포음)
2.1.1 청진을 통한 호흡기 질환 진단
호흡기 질환 진단 과정에서 청진은 비침습적이고 실시간으로 시행 가능하며 저비용으로 할 수 있다는 장점이 있습니다. 따라서, 의사는 청진을 통해 이상 호흡음의 정보를 파악하고, 이를 바탕으로 호흡기 질환을 진단합니다. 이상 호흡음의 소리 특성(크기, 호흡 주기에서의 등장 시기, 주파수 형태 등)에 따라 호흡기 질환 종류가 다르게 진단됩니다. 예를 들어, 위에서 설명한 천명음이 단조성으로 발생할 경우에는 기관지 결핵이나 기도협착증을 의심하며 복조성으로 발생할 경우에는 만성 폐쇄성 폐질환을 추정합니다. 하지만, 청진하는 의사의 경험 및 지식 정도에 따라 이 호흡음이 정상 호흡음인지 비정상 호흡음인지 구별해내는 능력이 상이합니다. 결국 청진에 의한 진단은 의사의 주관적인 요인에 의존하기 때문에 오진이 발생할 가능성이 존재한다는 것이죠.undefined2undefinedundefined3undefined 이러한 문제를 해결하기 위해 호흡음을 디지털화하고 정량적으로 분석하여 의사의 진단을 돕기 위한 AI 연구가 진행되고 있습니다.undefined3undefined
3. 코로나와 호흡음
3.1 코로나의 재유행

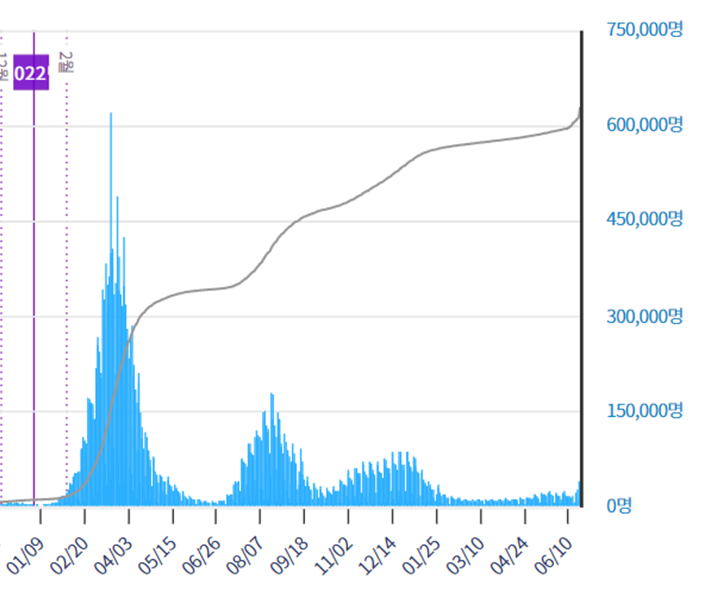
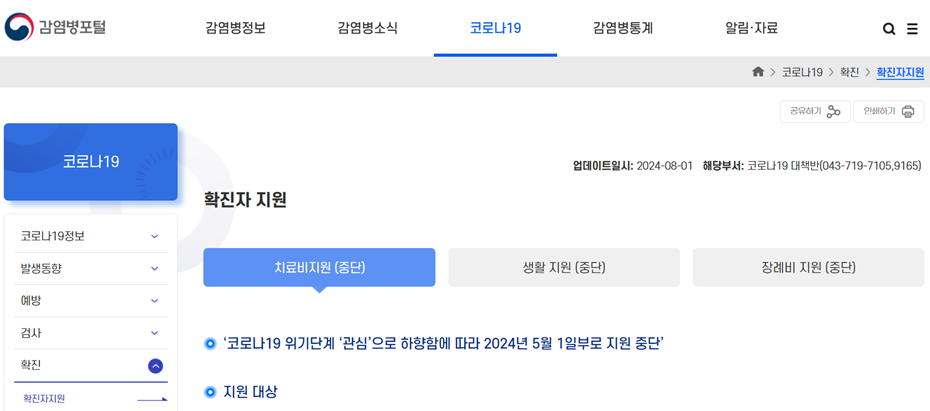
코로나가 재확산되면서, 프로젝트의 주제를 확정짓던 8월 6일 기준 일일 확진자 수는 48,899명, 누적 확진자 수는 33,534,219명으로 증가하였습니다. 하지만 빠르게 증가한 코로나 확진자 수와는 다르게, 코로나 관련한 지원 사업은 중단된 상태입니다. 코로나는 법정 4급 감염병으로 지정된 상태로, 확진 시 보고 의무가 없으며 병원 검사 및 치료에 개인 비용의 부담이 있습니다.
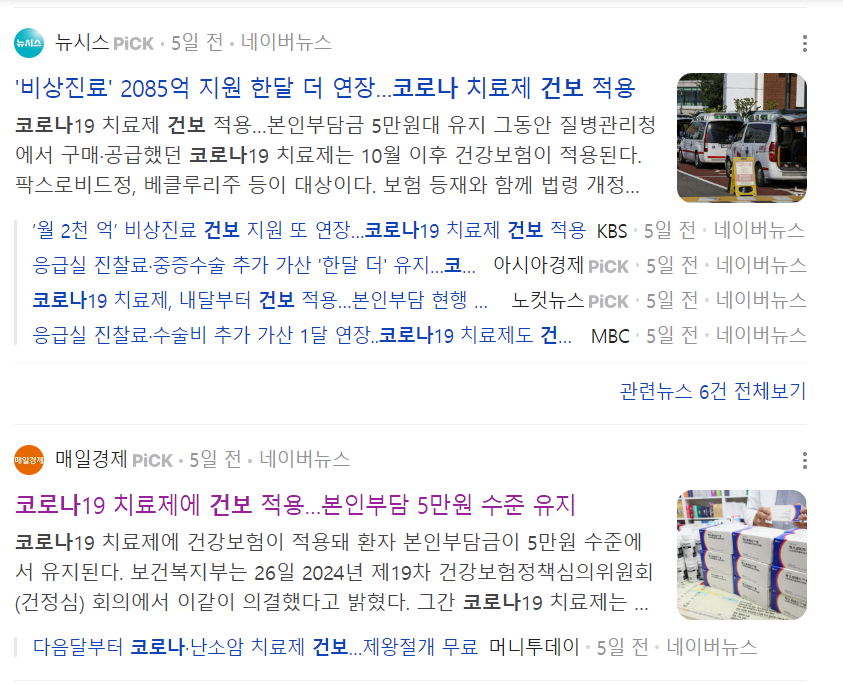
이 개인 비용에 대한 부담으로 인해 치료조차 받지 않는 사례가 점차 증가하자, 최근 9월 26일 보건복지부에서는 코로나19 치료제에 건강보험을 적용하겠다는 의결을 발표했습니다. 따라서 지난 10월 1일부터 코로나19 치료제가 건강보험이 적용돼 치료제가 의료체계 내에서 환자에게 공급되고 있습니다. 이렇듯, 다시 코로나에 대한 논의가 촉발되고 있는 현 시점에서 호흡음 분석을 통해 코로나 진단을 하는 프로젝트가 시의성이 있다고 판단했습니다. 따라서, 저희 음파음파 팀은 코로나 호흡음을 주제로 선정하여 프로젝트를 진행했습니다.
3.2 코로나 진단 검사
유전자 증폭(PCR) 검사 신속 항원 검사
장점 높은 정확성 신속한 판독 가능(30분 이내) 별도의 진단 장비 없이 진단 가능
단점 유전자 증폭 장비 필요 판독까지 시간이 오래 걸림(약 6시간) 정확도 떨어짐 민감도 낮음 위(거짓) 양성률 높음
기본적으로 다들 아시는 코로나 진단 검사는 위에 정리해둔 표에 있는 PCR 검사와 신속 항원 검사가 있습니다. 둘 다 침습적인 검사입니다. PCR은 정확하지만 현재 검사 비용이 5만원이고 직접 병원에 가서 검사를 받아야하는 번거로움이 있습니다. PCR 검사는 면봉을 콧속 깊숙이 넣는 비인두도말 방식이지만, 자가검사키트는 좀 더 앞쪽에서 검체를 채취하는 비강도말 방식입니다. 이 자가검사키트는 면봉을 콧속 1.5cm까지 넣고 10회 이상 문질러야 합니다. 하지만 이를 비의료인이 직접 검사할 경우, '1.5cm가 어느 정도지?'라는 생각이 먼저 들며 실제로 그만큼 찌르지 못해 민감도가 낮은 검사는 위음성(가짜음성)이 나올 확률이 높습니다.
3.3 코로나 증상


코로나에 걸리게 되면, 2~3일에서 최장 2주 정도 잠복기를 거쳤다가 다양한 증상이 나타납니다. 주로 무기력감, 37.5도 이상의 고열, 기침, 인후통, 가래, 근육통, 두통, 호흡곤란, 폐렴 등의 증상이 발생합니다. 폐 손상에 따른 호흡부전으로 심하면 사망에 이를 수도 있습니다. undefined4undefined
3.4 코로나 환자의 호흡음 특징
그렇다면, 저희는 왜 굳이 코로나를 호흡음으로 진단하고자 하는 것일까요? 그 이유는 코로나 환자들에게서 나타나는 호흡음의 특징이 있었고, 호흡음으로 진단하게 된다면 기존 CPR 방법으로의 검사처럼 코에 깊숙이 넣는 방법이 아닌 비침습적인 방법으로 진단할 수 있기 때문에 더 효율적인 방법이 될 것이라고 판단했습니다. 코로나 환자의 호흡음이 주파수와 시간 도메인에서 특징적인 패턴을 보이고 있습니다.
코로나 환자의 호흡음은 시간과 주파수 차원에서 더 강한 강도 분포와 짧은 구간 동안 천명음을 시사하는 저주파에서의 짧은 강도 증가를 보여줍니다. 이러한 특징적인 패턴이 코로나 진단을 위한 자동화된 도구로 사용될 수 있음을 시사합니다.
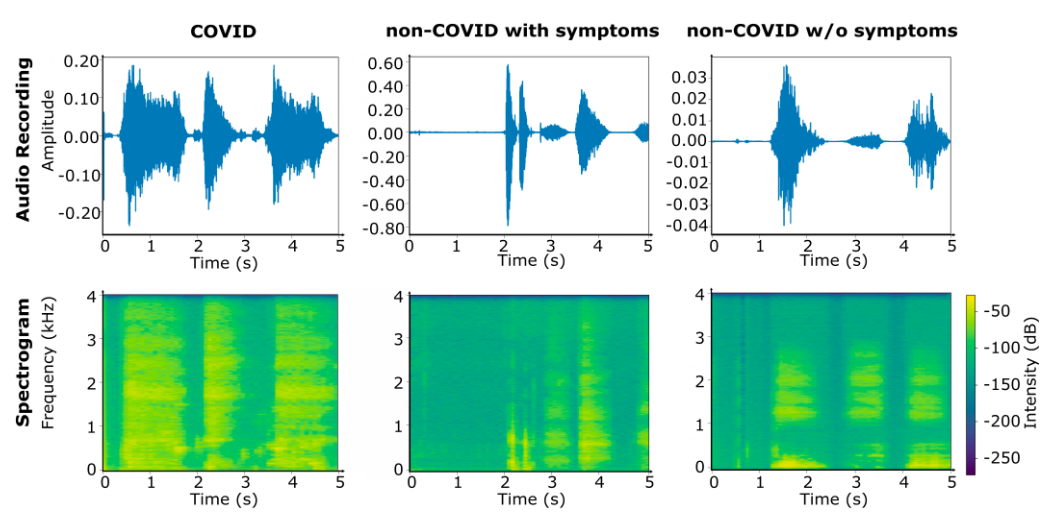
코로나19와 비코로나 환자의 호흡음을 비교하여 시각화한 선행연구의 예시를 들면서 설명하겠습니다. undefined6undefined 앞에서 설명했을 때, 코로나 환자의 호흡이 넓고 길게 사인파로 진행되고 천명음(Wheeze)가 나타난다고 했습니다. 위 그림을 보면, 증상이 없는 비코로나 사례는 중간 정도의 주파수 범위와 비교적 조용한 세그먼트 간격을 가진 주기적 패턴을 따릅니다. 증상이 없는 비코로나 사례는 시간 및 주파수 분포가 어느 정도 불규칙하고 높은 주파수에서 강도가 완만하게 상승하는 모습을 보입니다. 그에 비해 코로나19 사례는 시간과 주파수 차원 모두에서 균일하게 퍼진 강도 분포, 흡기/호기 시 높은 주파수에서 상대적으로 더 강한 강도(거친 호흡/딱딱거림(Crackles)), 구간 간 간격 동안 낮은 주파수에서 짧은 강도 증가(천명음(Wheeze))를 보여줍니다. 이러한 명백하고 세밀한 시간-주파수 특성의 차이로 인해 잠재적인 COVID-19 사례를 식별하기 위한 자동화된 선별 검사의 가능성을 제시하는 다양한 문헌 연구 결과가 뒷받침되고 있어, 코로나를 호흡음으로 판단하는 것도 유의미한 연구 주제라고 생각하게 됐습니다.
3.5 Dataset: Coswara
3.5.1 Dataset Explanation

Coswara 데이터셋은 Indian Institute of Scirnece(IISc) Bangalore에서 구축하였습니다. 공개적으로 사용 가능한 데이터 셋으로 홈페이지 크라우드 소싱(https://coswara.iisc.ac.in/)를 통해 데이터를 수집합니다. 이 때 개인의 호흡, 기침, 말소리 등의 음성 데이터와 함께 성별, 백신 접종 여부와 같은 메타데이터를 같이 수집합니다.
Audio Schema
Sound Category Collected Sound Sample Description
Breathing Breathing-shallow (사용하는 데이터) 폐에 힘을 거의 주지 않은 상태로, 호기와 흡기의 주기가 몇 있는 상태
Breathing-deep (사용하는 데이터) 폐에 힘을 준 상태로, 호기와 흡기의 주기가 몇 있는 상태
Cough Cough-shallow 폐에 힘을 거의 주지 않은 상태로, 기침을 몇 번 하는 상태
Cough-heavy 폐에 힘을 준 상태로, 기침을 몇 번 하는 상태
Vowel Phonation Vowel-[u] vowel-[u]의 지속적인 음소화 (as in the word boot)
Vowel-[i] vowel-[i]의 지속적인 음소화 (as in the word beet)
Vowel-[æ] vowel-[æ]의 지속적인 음소화 (as in the word bat)
Speech Counting-normal 정상 속도로 1에서 20까지의 숫자 세기
Counting-fast 빠른 속도로 1에서 20까지의 숫자 세기
Metadata Schema
Metadata Type Field name Description Allowed values
Demographic (인구통계학적) id 참여자 식별자 고유한 랜덤 코드 생성기를 사용하여 할당됨
record_data 데이터가 기록된 날짜 dd-mm-yy
a 참여자의 나이(age) 숫자
g 참여자의 성별(gender) male/female/other
l_c 참여자의 나라(country) 217개국 목록 중 하나
l_s 참여자의 거주 지역(state) l_c 와 관련된 주(state; province) 목록 중 하나
vacc 코로나 백신 접종 상태 y (두 번 이상) / p (한 번) / n (백신 맞지 않음)
ep 영어에 능숙한지에 대한 여부 True/False
smoker 흡연자인지에 대한 여부 True/False
rU 참여한 적 있는지에 대한 여부 (returning participant) True/False
um 마스크를 쓰고 있는지 True/False
COVID-19-like symptoms cough 기침이 있었는지 True/False
(코로나 증상) cold 감기가 있었는지 True/False
diarrhoea 설사 증상이 있었는지 True/False
bd 호흡에 어려움이 있었는지 (has breath difficulties) True/False
st 인후통이 있었는지 (has sore throat) True/False
fever 열이 있었는지 True/False
ftg 피로로 고통받고 있는지 (suffering from fatigue) True/False
mp 근육통을 겪었는지 (has muscle pain) True/False
has loss_of_smell 미각이나 후각을 잃었는지 loss of smell and/or taste True/False
Respiratory ailments asthma 천식 관련 문제가 있는지 yes/no
(호흡기 질환) cld 만성 폐질환이 있는지 (has chronic lung disease) True/False
pneumonia 폐렴이 있는지 True/False
others_resp 그밖의 다른 호흡기 질환이 있는지 True/False
Comorbidity (동반성 질환) ht 고혈압이 있는지 (has hypertension) True/False
diabetes 당뇨가 있는지 True/False
ihd 허혈성 심장 질환이 있는지 (has ischemic heart disease) True/False
others_preexist 그밖의 다른 Comorbidity가 있는지 True/False
COVID-19 health test_status 코로나 검사 결과 p (positive) /n (negative) / na (not taken a test)
covid_status 코로나에 대한 건강 상태 (양성이지만 증상이 심하지 않거나, 건강하거나, 코로나에 노출은 되었거나 등) positive_mild, healthy, positive_moderate, positive_asymptomatic, exposed
testType 받은 코로나 검사의 종류 RAT/RT-PCR
test_date 코로나 검사한 날짜 dd/mm/yy
ctDate CT-scan 받은 날짜 dd/mm/yy
ctScore CT value number
ctScan CT-scan을 받았는지 True/False
3.5.2 Data Visualization - EDA
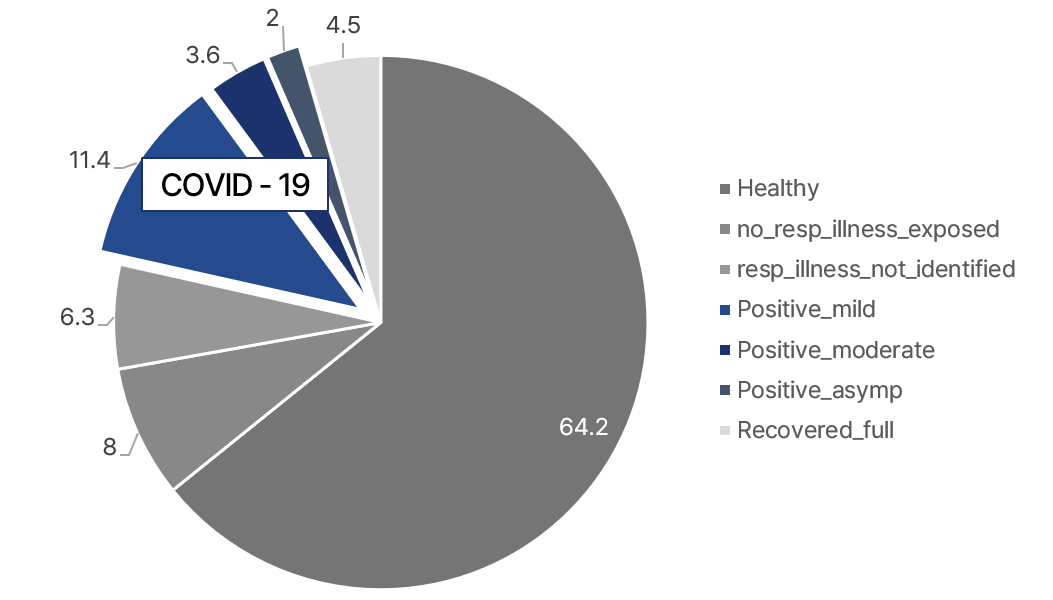
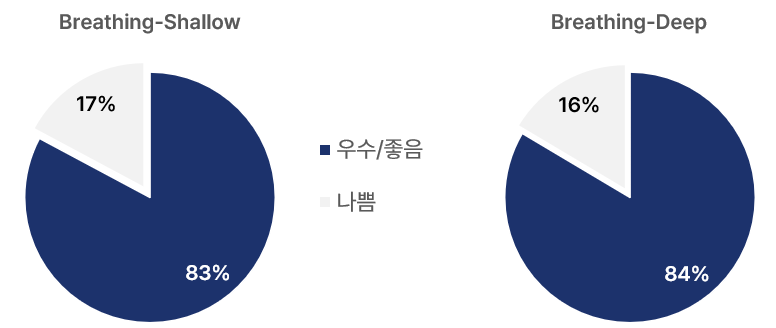
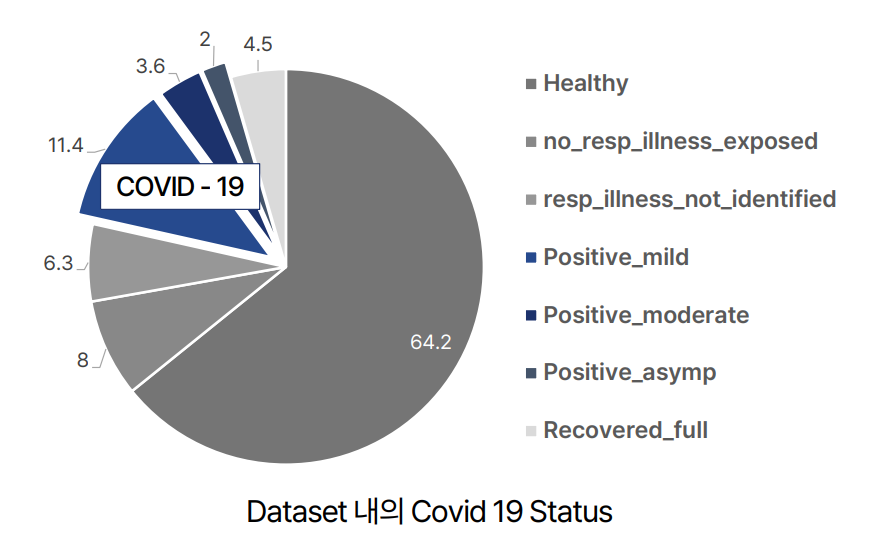
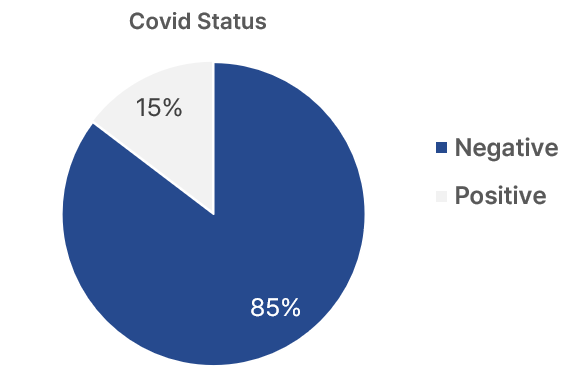
Coswara 데이터 셋 중 코로나 양음성을 나타내는 Status 항목을 확인해보면, 위의 그래프와 같이 17%의 데이터가 코로나 양성인 응답자가 업로드했습니다. 해당 데이터 셋의 코로나 환자와 비코로나 환자의 비율이 약 정도 됩니다.
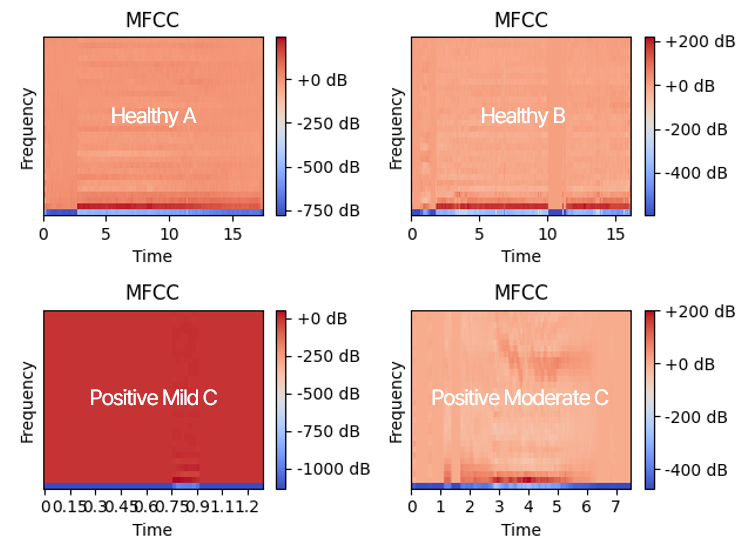
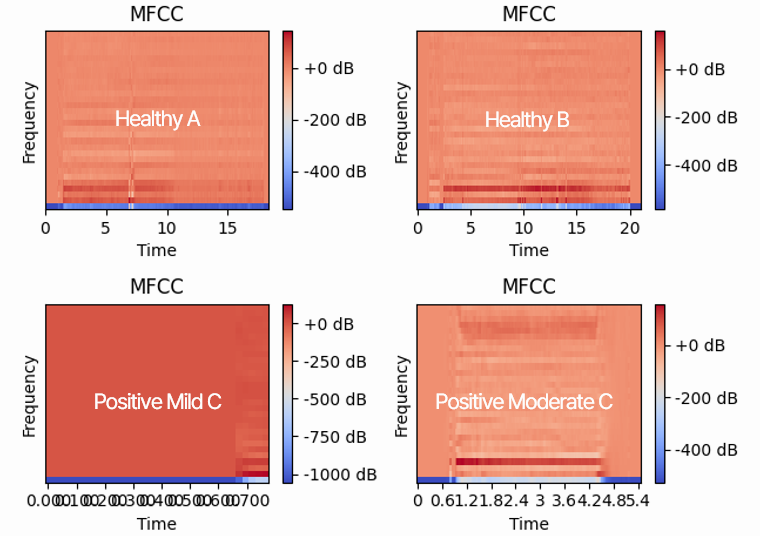
이 데이터셋으로 코로나 양음성 환자 간의 음성 데이터의 특징을 확인해보기 위해, vowel ‘o’와 vowel ‘e’ 음성 데이터를 시각화해 비교해보겠습니다. 각각 ‘o’와 ‘e’ 를 발음하는 음성으로, 상단의 A와 B는 건강한 상태로 녹음하였으며 하단의 C와 D는 코로나 확진인 상태로 녹음하였습니다. A와 B에 비해 C와 D는 그 주파수가 높고 변화가 급격한 것을 통해 호흡음을 통한 코로나 진단이 유의미하고, 해당 데이터셋으로 진행해도 유의미한 결과 도출이 가능할 것이다라는 판단을 했습니다.
4. Self-Supervised Learning (SSL)
Supervised Learning을 위해 대량의 Labeled Data, 특히 높은 품질의 Labeled Data를 얻는 것은 많은 비용이 필요합니다. 별도의 라벨링 작업이 필요하니까요. Unlabeled Dataset 만으로 데이터를 잘 표현하는 ‘좋은 Representation’을 얻을 수 있다면, 많은 비용을 아낄 수 있습니다. 그래서 Self-Supervised Learning은 Unsupervised Learning을 통해 좋은 Representation을 얻는다면 다양한 Downstream Task에 빠르게 적응할 수 있으며, 더 나아가서 Supervised Learning 보다 좋은 성능을 낼 수 있을 것이라는 생각에서 시작되었습니다.
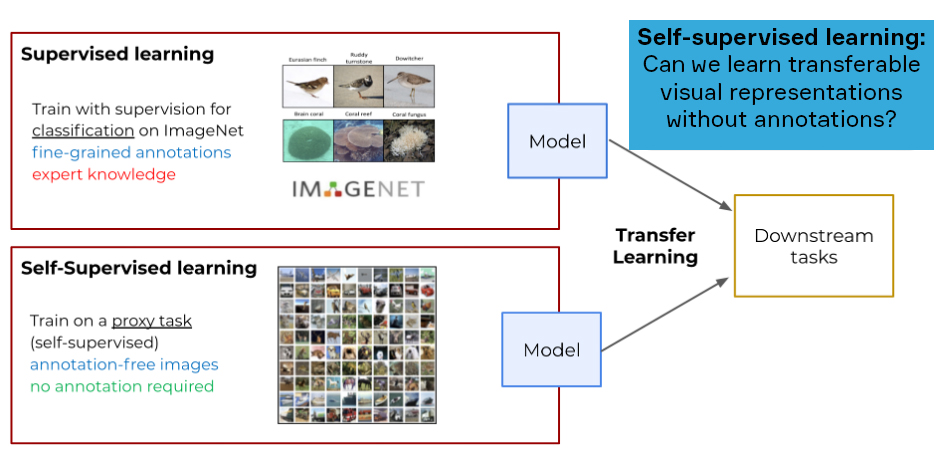
4.1 Self-Supervised Learning(SSL)이란?
Self-Supervised Learning은 Unlabeled Dataset으로부터 좋은 Representation을 얻고자 하는 Representation Learning의 일종입니다. Unsupervised Learning으로 볼 수 있지만, Self-Supervised Learning이라고 말하는 이유는 Label(y) 없이 Input(x) 내에서 Target으로 쓰일만 한 것을 정하는, 즉 Self로 Task를 정해서 모델을 학습하기 때문입니다.
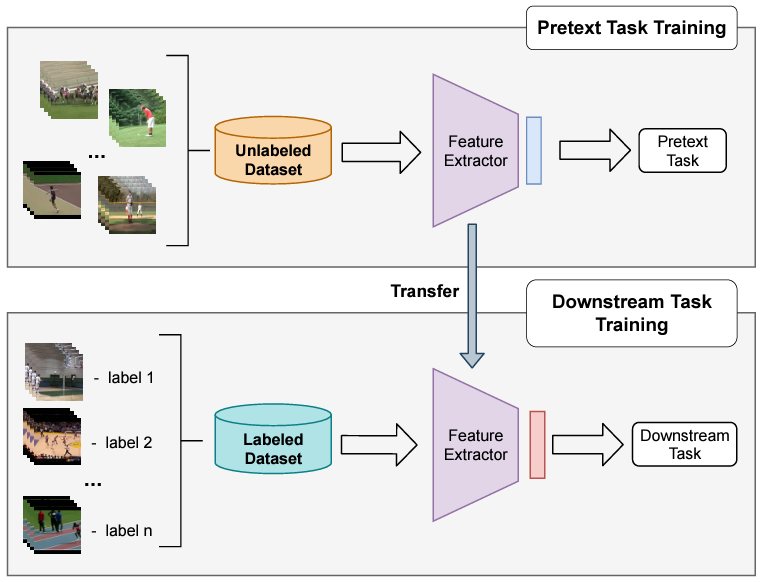
그래서 Self-Supervised Learning의 Task를 Pretext Task(일부로 어떤 구실을 만들어서 푸는 문제)라고 부릅니다. Pretext Task를 학습한 모델은 Downstream Task에도 Transfer하여 사용할 수 있습니다. Self-Supervised Learning의 목적은 Downstream Task를 잘 푸는 것이기 때문에 기존의 Unsupervised Learning과 다르게 Downstream Task의 성능으로 모델을 평가합니다.
다양한 Self-Supervised Learning 방법
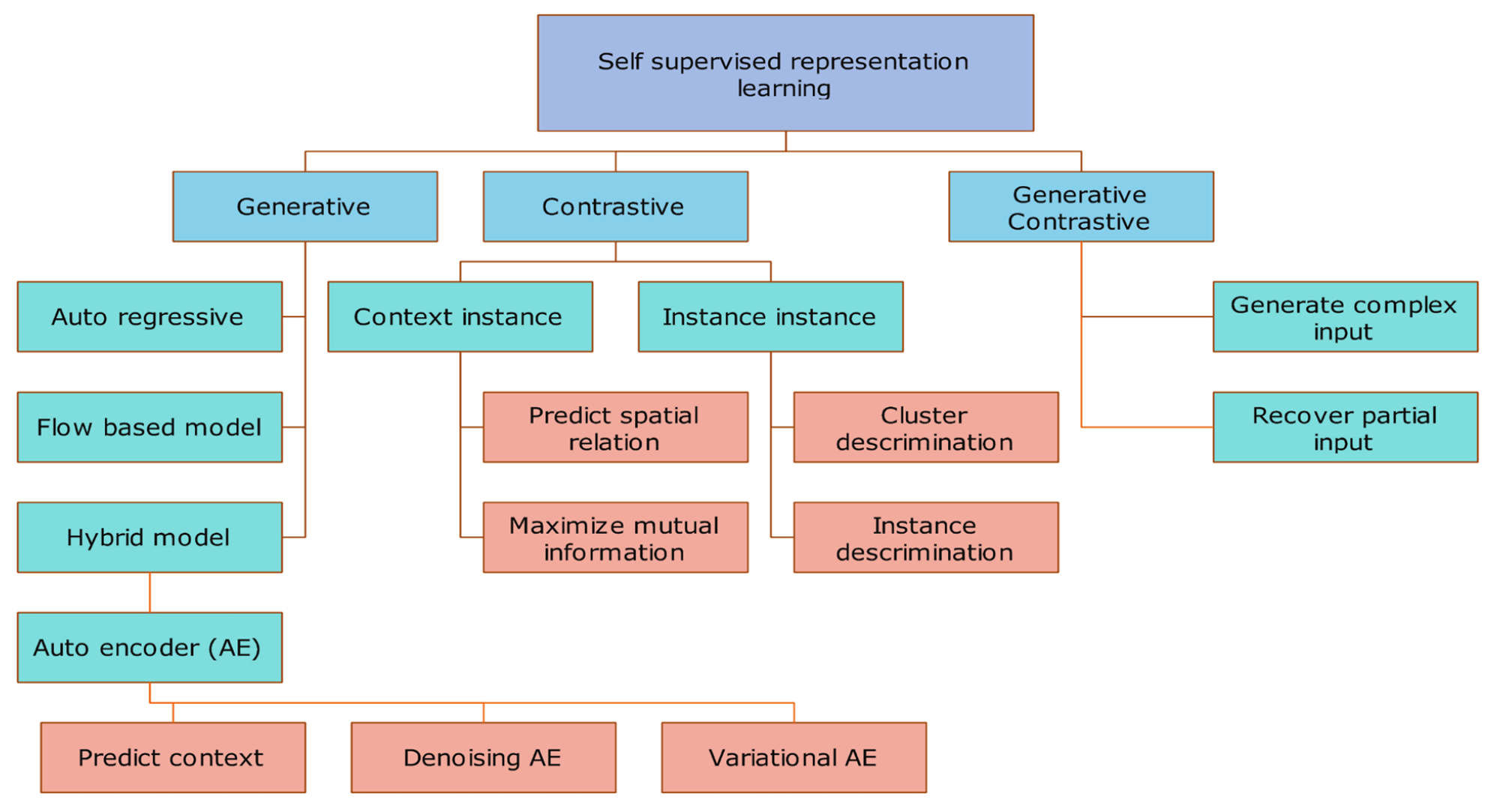
Self-Supervised Learning은 여러 가지의 방법이 존재합니다. 그 중에서 널리 사용되는 방법으로는 Variational Autoencoder(VAE)와 Generative Adversarial Networks(GANs)가 있습니다. VAE와 GANs 방법 모두 학습된 저차원 Representation을 원래의 이미지로 다시 변환할 수 있는 Decoder가 있으며, 이것은 앞으로 이야기할 Contrastive Learning과의 차이점입니다.
5. Contrastive Learning
Contrastive Learning(대조 학습)은 Self-Supervised Learning의 대표적인 방법으로, 유사한 이미지가 저차원 공간에서 서로 가깝고 다른 이미지는 서로 멀리 위치하도록 저차원 공간에서 이미지를 인코딩하는 방법을 모델이 학습하는 것입니다.
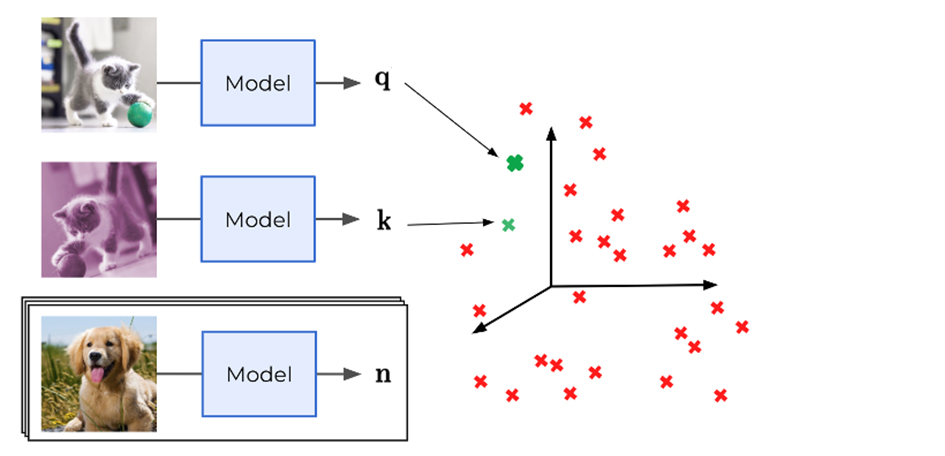
즉, Contrastive Learning은 Self-supervised visual representation learning으로, 1️⃣유사한 양수 쌍 또는 샘플들의 표현 사이의 거리를 최소화하고 2️⃣다른 음수쌍 또는 샘플의 표현 사이의 거리를 최대화하여 특징을 추출 학습하는 방법입니다.
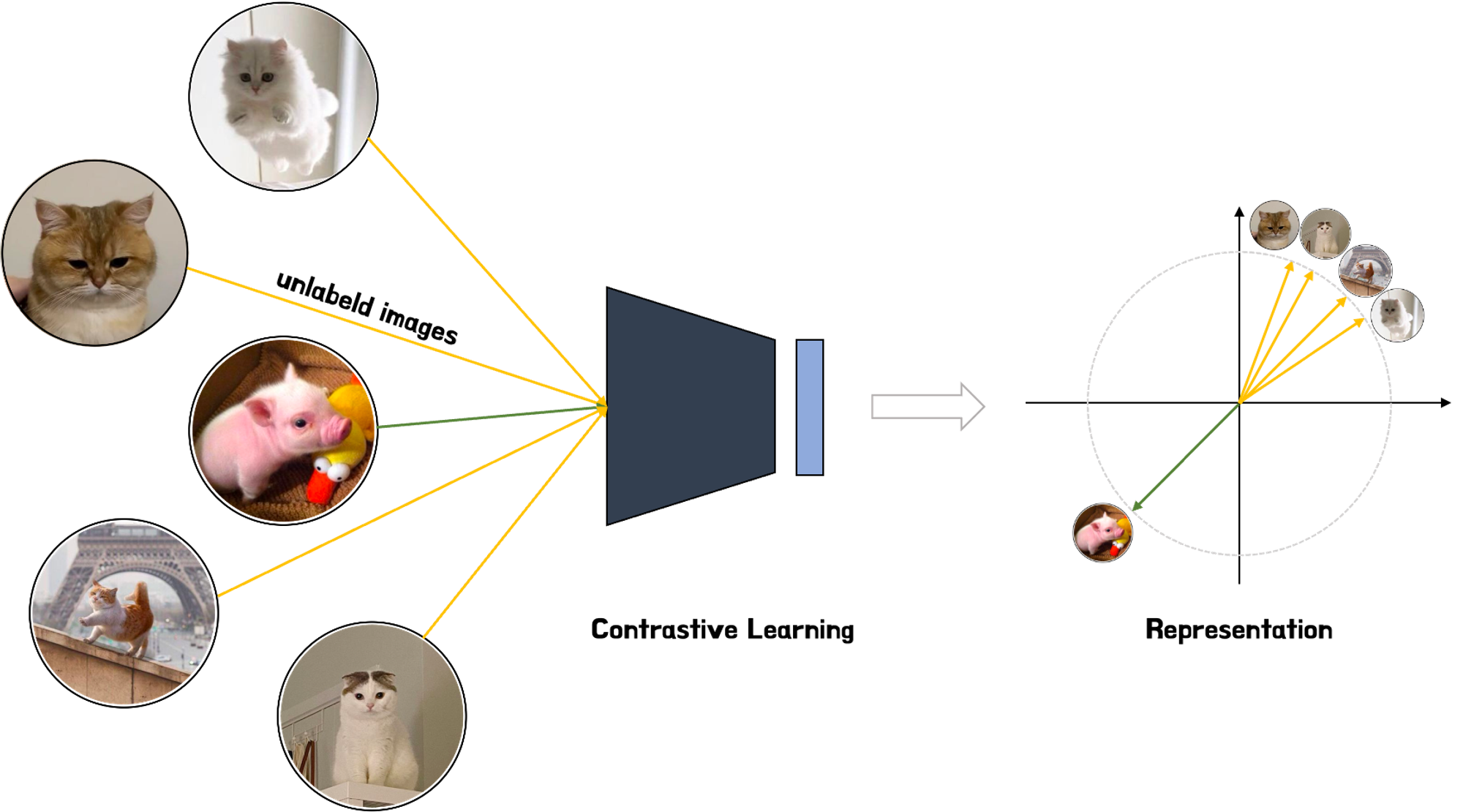
모식도를 통해 방법을 살펴보면, 고양이 사진 4장과 돼지 사진 1장이 입력으로 주어졌을 때, Contrastive Learning은 Labeling 없이 유사한 입력들을 가깝게 위치시키는 것을 확인할 수 있습니다. 이때 주의해야 할 것은 Contrastive Learning의 목표가 특정 예측을 생성하기 위해 모델을 최적화하는 것이 아니라 Representation 자체가 의미 있는 것인지 확인하는 것이라는 점입니다. 이와 같은 방법이 효과적인 이유는 대부분의 실제 상황에서 각 이미지에 대한 Label이 존재하지 않기 때문입니다. 따라서 레이블을 생성하려면 전문가가 이미지를 수작업으로 분류하고 Segmentation 하는 등 시간을 들여야 하는 어려움이 존재합니다. 하지만, Contrastive Learning을 사용하면 이러한 어려움 없이 데이터에 대해 학습하도록 훈련할 수 있습니다.
5.1 MoCo v2(Momentum Contrast for Unsupervised Visual Representation Learning)
Momentum Contrast(MoCo)undefined10undefined는 Contrastive Learning의 방법론 중 하나로, Dynamic Dictionary를 사용한다고 생각하면 됩니다. Queue와 Moving-Averaged Encoder(= Momentum Encoder)를 사용하여 거대하고 일관성있는 Dictionary를 만들 수 있게 했습니다. 여기에서 Dictionary는 이미지들을 Encoder에 통과시켜서 얻은 Representation들을 말합니다. 그렇다면, 왜 거대하고 일관성있는 Dictionary를 만들고자 했을까요? Self Supervised Learning을 먼저 적용한 것은 NLP(자연어 처리) 분야였습니다. Self Supervised Learning이 NLP에서 좋은 성능을 보이자, 이를 이미지 처리에 적용하고자 하였습니다. 하지만, 이미지의 특성이 자연어와는 달라 성능이 낮게 나오자, 이를 해결하기 위해 NLP를 진행할 때의 특징이었던 “거대하고 일관성있는 Dictionary”를 만들고자 하였습니다. 이러한 Dictionary를 제작하기 위해 먼저 제작한 데이터를 내보내는 Queue 방식의 Dictionary를 적용했습니다. 그리고 Moving Average를 이미지 특성을 추출하는 Encoder에 적용하여 일관성 있는 Momentum Encoder를 제작하였습니다.
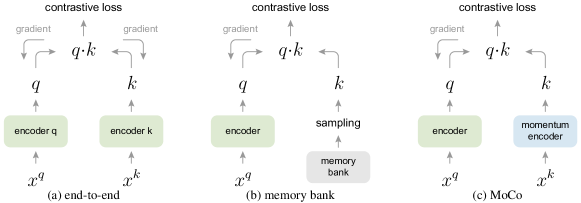
(b): Memory Bank에서 Sampling되는 방식을 통해 queue가 업데이트 됨. / (c): MoCo: Momentum Encoder를 적용하여 새로운 key를 즉성에서 Encoding하고 Key 대기열(Queue)을 유지함. Queue를 사용하여 Dictionary를 만드는 방법을 선택하면, Dictionary가 Mini Batch로 설정한 사이즈 보다 커져, 거대한 Dictionary의 구현이 가능케합니다. 또한, MoCo v2에서는 Key Encoder를 천천히 업데이트 하여 일관성을 유지하였습니다. 이렇게 MoCo v2는 목표로 하던 “거대하고 일관성 있는 Dictionary 제작”을 이루어냅니다.
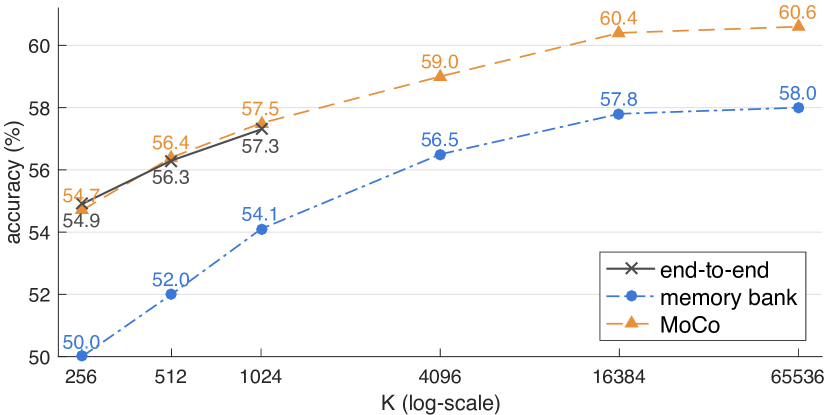
- 다른 대조학습 방법이 아닌 MoCo를 사용한 이유
모델 SimCLR MoCo BYOL
특징 양성/음성 샘플 기반 대조적 학습 모멘텀 네트워크와 큐를 사용한 효율적인 음성 샘플 관리 음성 샘플 없이 양성 샘플만을 사용한 대조적 학습
장점 간단하고 구현이 쉬움, 대규모 데이터셋에 효과적 음성 샘플 효율적 관리, 대규모 데이터셋에서 성능 우수 음성 샘플 필요 없음, 작은 배치 크기와 적은 데이터에서 우수
단점 음성 샘플 수와 배치 크기 의존성, 메모리 소모 큼 구조가 복잡하고 구현 어려움, 하이퍼파라미터 설정에 민감 타겟 네트워크 의존성, 모멘텀 업데이트 하이퍼파라미터 민감
기존의 연구 결과에 따르면 호흡음을 사용해서 대조학습을 하는 경우에 Index의 값이 서로 다른 Negative Pair를 적용하는 것이 좋은 성능을 가져올 수 있습니다. 그렇기 때문에 Negative Pair의 효율적인 관리가 가능하다고 하는 MoCo 모델을 적용하기로 하였습니다.
6. Project
6.1 Project Framework
6.1.1 Experimental Framework
저희는 효율적인 진단을 위해 코로나 호흡음 데이터를 분석하는데 Metadata를 활용하여 Contrastive Learning을 하려고 합니다. 저희가 ‘환자의 메타데이터를 사용해 대조학습할 때 데이터들의 Pair를 선정하자!’라고 아이디어를 얻은 논문은 바로, ‘Contrastive Learning of Heart and Lung Sounds for Label-Efficient Diagnosis’undefined11undefined 라는 논문이었습니다.

이 논문에서 진행한 폐음의 실험 결과가 연령과 성별이 다르다는 기준을 적용하였을 때 (Neg. Sim. Age + Sex) 유의미한 결과가 있었는데, 실제로 폐 질환이 연령과 성별에 상관 관계가 존재한다는 임상적 결과와 일치한다고 합니다. 그래서 저희는 이 점에서 흥미를 얻었고, 저희가 활용할 코로나 호흡음 데이터인 Coswara 데이터셋도 각 환자에 대한 상세한 Metadata를 제공하고 있기 때문에 이 점을 충분히 활용할 수 있을 것이라고 생각했습니다. 코로나 호흡음 데이터도 여기서와 마찬가지로 임상적 상관관계가 존재하는 Metadata를 활용하게 된다면, 대조학습에서 학습한 표현을 더욱 개선할 수 있을 것이라고 생각하게 되었습니다.
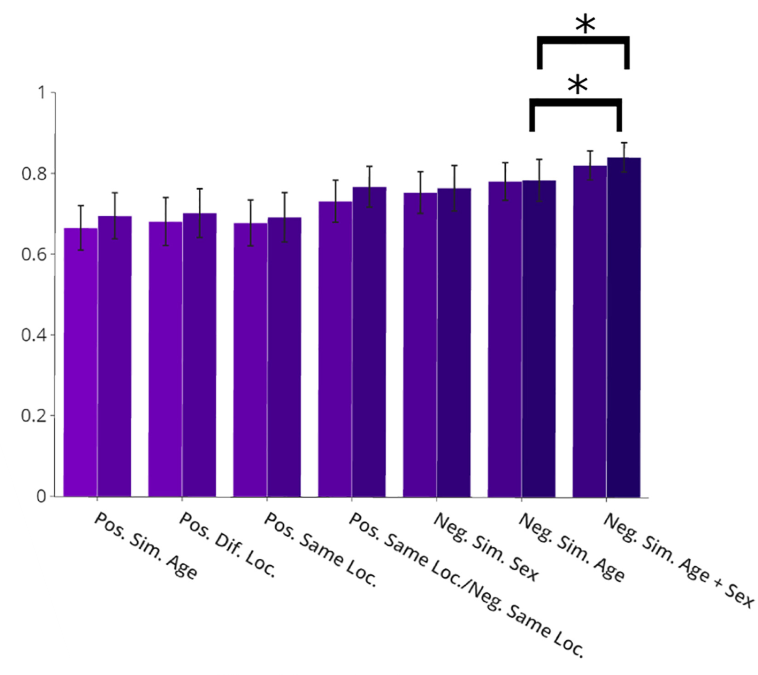
코로나 초기 연구에 따르면, 실제로 코로나는 성별, 연령, 백신 접종의 여부, 호흡기 질환에 따라 중증으로 발병될 가능성이 쉽다고 합니다. 성별undefined12undefined에서는 실제로 남성이 여성보다 중증으로의 발현과 사망률이 훨씬 높았고, 연령이 높을 수록 중증으로 발전될 가능성이 높으며 기존에 호흡기 질환이 갖고있을 경우 중증이 될 가능성이 크다고 합니다.undefined13undefined 따라서 메타데이터에서 해당 칼럼들을 제공하고 있기 때문에, 코로나와 임상적 상관관계가 있는 Metadata 칼럼과 호흡음 데이터를 활용해 대조 학습(Contrastive Learning) 실험을 계획했습니다.
6.1.2 Graphical Project Framework
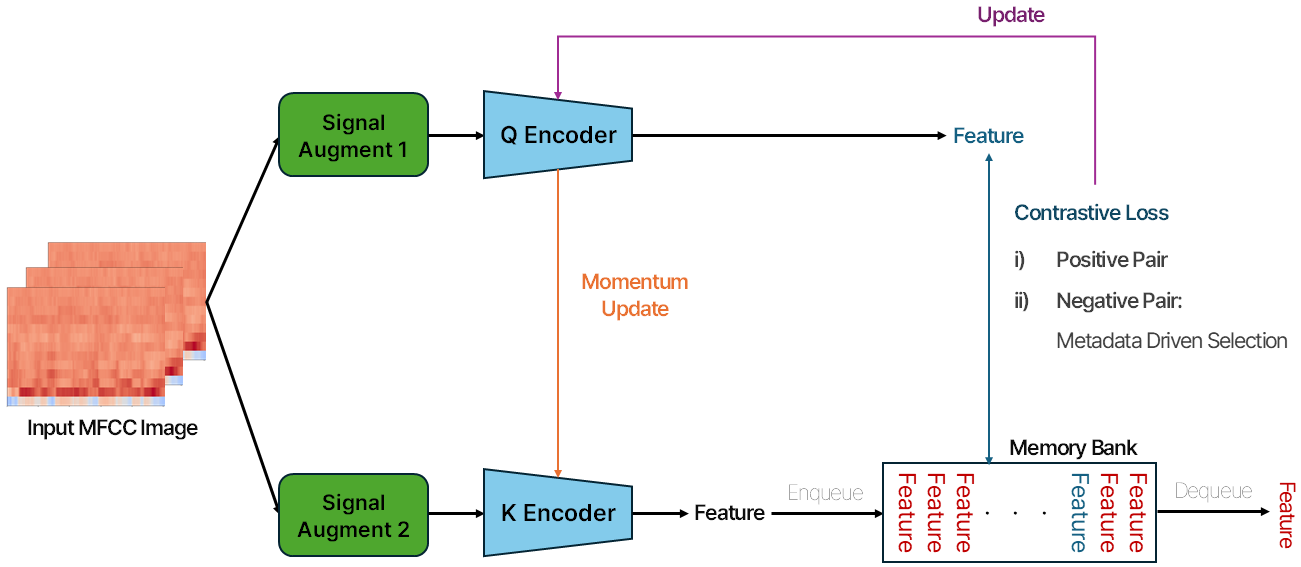
해당 프레임워크는 기본적으로 MoCo 프레임워크를 따르고 있습니다. 하지만, 저희 프로젝트에서는 코로나와 임상적 상관관계가 있는 것으로 나타난 환자의 메타데이터를 활용해 Pair를 선택하고 있기 때문에, 해당 부분을 추가하여 새롭게 프레임워크를 그려 보았습니다. 또한, Augmentation의 방법도 이미지 증강 방식이 아닌, 원신호에서 변화시켜 데이터를 증강시킬 수 있는 다양한 방법들을 시도했기 때문에 이를 추가하여 다음과 같은 프레임워크를 그렸습니다.
6.2 Data Preprocessing
Data Preprocessing 과정
음성 품질에 따른 Filtering → 음성의 크기를 동일하게 볼륨 조절 → Data Augmentation → MFCC 적용하여 음성 이미지화 Filtering Coswara Dataset을 사용해서 받은 음성 데이터에서 호흡음은 두 개의 Class[Breathing-Shallow, Breathing-Deep]가 존재합니다. Breathing Deep은 평소에 숨을 쉬는 소리와 같다면, Breathing Deep은 크게 숨을 쉬는 소리와 비슷합니다.
Breathing-Shallow 예시
Breathing-Deep 예시
위 데이터는 뒤에 배경음으로, 아이의 소리가 크게 들어가 품질이 ‘나쁨’을 받은 음성 데이터입니다. Coswara Dataset은 Dataset을 제공할 때, 인간 청취자가 녹음을 듣고 그 품질을 Labeling 하여 제공합니다. 품질의 클래스는 총 3가지로, ‘우수’, ‘좋음’, ‘나쁨’이 있습니다. 저희는 데이터를 학습하는데 있어 원활한 학습을 위해 데이터 품질이 ‘나쁨’인 데이터를 제외하였습니다.
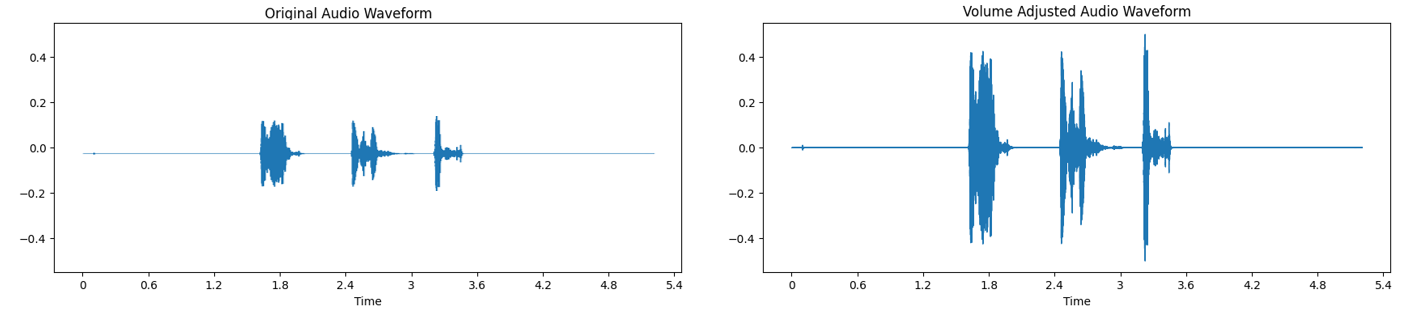
볼륨 조절 또한, Breathing-Shallow Class와 Breathing-Deep Class의 오디오 파일이 음성의 볼륨을 제외하고는 큰 차이가 존재하지 않는다고 판단하였습니다. Dataset의 양을 늘려 더 정확한 모델을 제작하기 위해 Breathing-Shallow와 Breathing-Deep 음성의 최대 볼륨을 일정하게 만드는 전처리 과정을 거쳐 학습하는데 사용하였습니다.
레이블 병합 Coswara Dataset은 응답자의 Covid-19 Status를 다양하게 응답받습니다. 하지만, 효과적인 대조학습을 위해서는 해당 레이블을 단순화하는 것이 중요하다고 생각하였습니다.
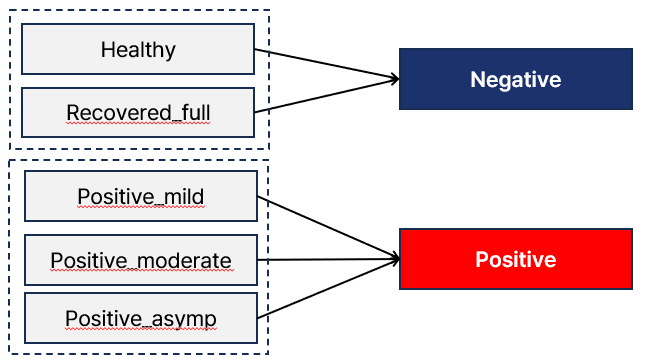
따라서 [Healthy, Recovered_full]은 음성(Negative)로, [Positive_mild, Positive_moderate, Positive_asymp]는 양성(Positive)로 단순화하여 적용하였습니다.
6.2.1 Data Augmentation
Data Augmentation은 데이터 양을 늘리기 위해 Original Data에 여러가지 변환 방식을 적용하여 데이터 개수를 증강시키는 기법입니다. 모델을 학습시키는데에는 많은 데이터가 필요합니다. 하지만, 이 모든 데이터를 수집하는 일은 어려운 일입니다. 이런 경우에 Original Data를 변형시킨 Modified Data를 흭득하여 모델이 학습하는데 충분한 양의 데이터를 얻는 것은 좋은 방법이 될 수 있습니다. 또한 데이터가 하나의 클래스의 데이터가 다른 클래스에 비해 더 많은 양을 가진 경우, 모델은 정확도를 높이기 위해 데이터 양이 더 많은 라벨을 답으로 제출하는 잘못된 학습을 할 수 있습니다. 그렇기 때문에 Data Augmentation을 통해 데이터 불균형을 해소하기도 합니다. Medical AI 분야에서는 정상 데이터에 비해 질환을 가진 데이터를 얻는 것이 어렵기 때문에 더 중요합니다.
프로젝트에서 이미지 기반 학습된 모델인 ResNet을 사용하고자 하였기에, 음성 데이터를 Image 화하는 방식을 선택하였기에 Image Augmentation과 Audio Augmenatation을 비교하고자 합니다. Image Image Augmentation의 방법으로는 Crop, Resize, Masking, Blur, Flip, Rotation 등이 존재합니다. 여러 가지 방법을 이야기했지만, 크게 Pixel 단위의 변화를 일으키는 Pixel Level Transform과 이미지의 공간적(크기, 방향 등)으로 변화시키는 Spiratial Level Transform이 이 있습니다.


Image Augmentation은 데이터 특성에 따라 적절하게 사용하는 것이 중요합니다. 하지만, 저희가 사용하는 Image Data는 Audio에 MFCC를 적용하여 이미지로 변환한 형태의 데이터이기 때문에 Pixel Level Transform을 적용하기 어려웠습니다. 그렇기에 Audio에 변형을 주는 Audio Augmentation 방법을 선택하게 되었습니다. Audio Audio Augmentation은 Add Noise, Pitch Shift, Time Stretch, Random Crop, Random Mask 등의 방법이 존재하며, 모두 호흡음 데이터에 적용할 수 있었습니다.
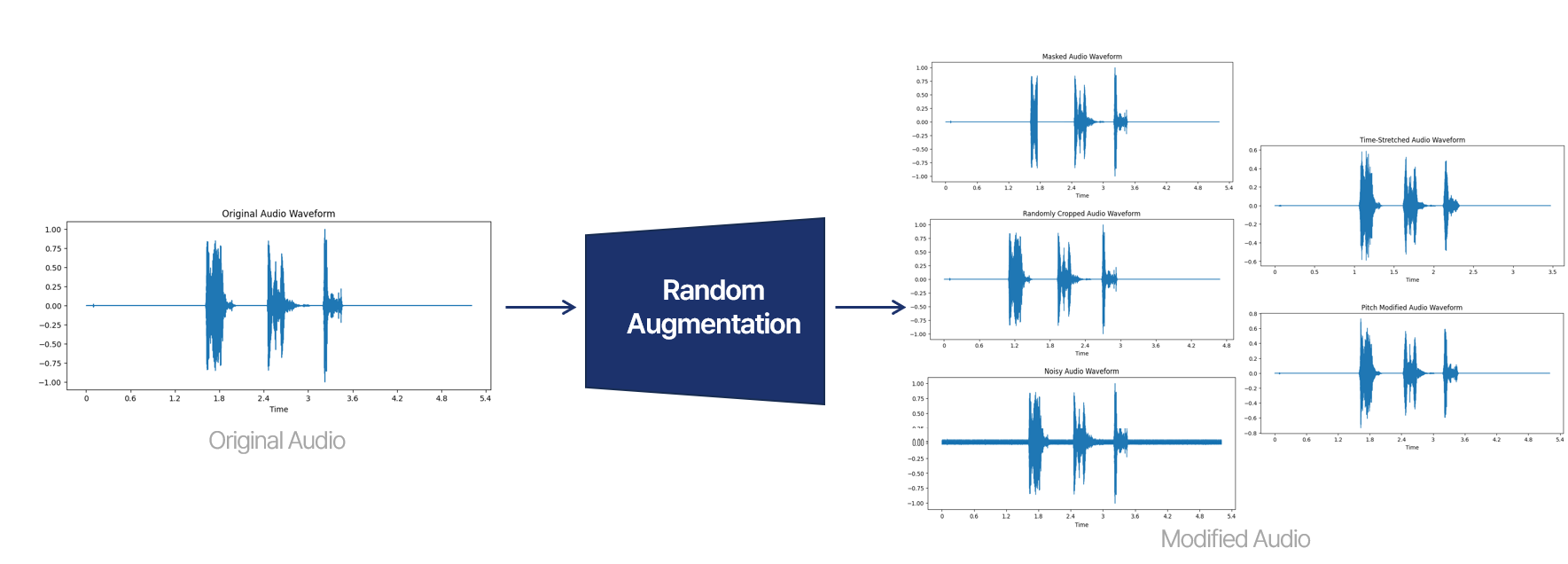
양성(Positive Class) 데이터의 양이 음성(Negative Class) 데이터에 비해 적기 때문에 데이터 불균형을 해소하는데 Data Augmentation이 필요했습니다. 그렇기 때문에 각각의 Class를 Augmentation 하는 양이 달랐습니다. 음성 데이터는 5가지의 Augmentation 방식과 원본 데이터를 그대로 적용하는 방식이 Random 함수를 통해 적용되어 개수가 유지되게 하였습니다. 또한, 양성 데이터의 경우에는 데이터 양을 늘리기 위해 원본 데이터가 적용하는 방식과 5가지의 Augmentation 방식 중 Random으로 3개의 방식을 더 적용해 데이터 양을 4배 증가시켰습니다. 아래의 음성 파일은 이미지 증강을 적용한 예입니다. Random으로 일부분을 변형시키거나 변환하였습니다.
Original Sound
Time Stretch
Add Noise
Random Crop
Pitch Shift
Random Masking
6.2.2 MFCC (Mel-Frequency Cepstral Coefficient)
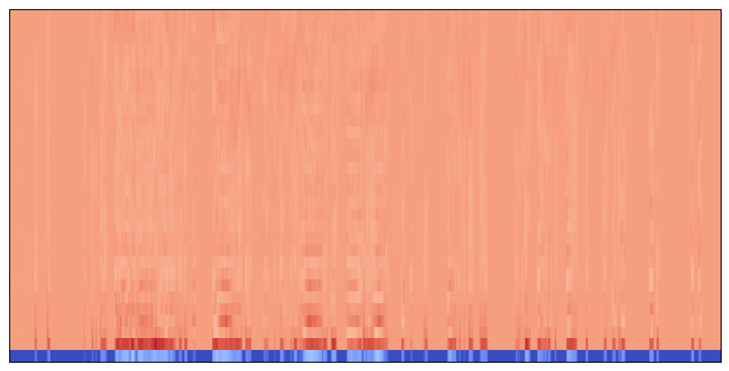
Mel-Frequency Cepstral Coefficient(MFCC)는 음성 데이터를 특징 벡터로 Feature화 해주는 알고리즘입니다. 데이터를 벡터화 한다는 것은 곧 학습이 가능하다는 의미이기 때문에, 이를 잘 하는 것이 학습을 잘 할 수 있는 요인이 됩니다. MFCC를 알기 위해서, 우선은 Mel Spectrum에 대해 알아야 합니다. 사람의 청각기관은 고주파수(High Frequency) 보다 저주파수(Low Frequency) 대역에서 더 민감합니다. 이런 청각 기관의 특성을 반영하여 물리적인 주파수와 실제 사람이 인식하는 주파수 관계를 표현한 것이 Mel Scale이고, 이를 기반으로 Filter Bank에 적용해 Spectrum을 도출한 것이 Mel Spectrum입니다.
- MFCC는 아래의 과정을 통해 도출됩니다.
- STFT(Short Time Fourier Transform)에 의해 주어진 음성 신호를 작은 프레임 단위로 나누어서 주파수 영역의 데이터로 변환합니다.
- Mel Filter Bank로 멜 스펙트럼을 계산합니다.
- 로그 스케일링하고 DCT(Discrete Cosine Transfrom)을 수행합니다.
- 이를 이용하여 해당 프레임의 특징을 추출합니다.
호흡음의 경우, 청진을 통해 질병을 진단하기 때문에, 인간의 청각 기관과 유사한 벡터화 방식을 적용하기 위해 MFCC를 적용하였습니다.
6.3 Data Modeling
6.3.1 Pair Selection
대조학습을 위해서는 2개의 데이터를 하나의 조합으로 만들어, 이 조합이 Positive Pair인지 Negative Pair인지에 따라 두 데이터를 가깝게 위치할지, 멀게 위치할 지를 결정합니다. 저희가 실험을 위해 새롭게 적용한 한 로직은 다음과 같습니다. 이 때의 Positive Pair, Negative Pair는 두 데이터의 라벨(성별, 코로나 증상 유무 등)이 일치하는지 일치하지 않는지에 따라 결정됩니다. 자세한 내용은 아래 콜아웃에서 구성을 설명하겠습니다.
6.4 Experiment
6.4.1 Experiment Setting
최종적으로 저희가 진행한 실험 세팅을 정리해 보겠습니다.
- Problem Setting
- : COVID-19 Status (Positive/Negative)
- : Contrastive Learning (MoCov2) w/ Metadata Driven Pair Selection
- : Metadata, Respiratory Sound Images
- Environment Setting
- Colab Pro+ 결제
- GPU: A100 사용
6.4.2 Contrastive Learning Evaluation Method
대조학습(Contrastive Learning)에서 주로 사용되는 평가 방식은 모델의 표현 학습 성능을 측정하는 데 중점을 둡니다. 학습 과정에서 직접적으로 태스크 목표를 사용하는 것이 아니라, 모델이 데이터의 유용한 표현을 얼마나 잘 학습했는지를 평가합니다.
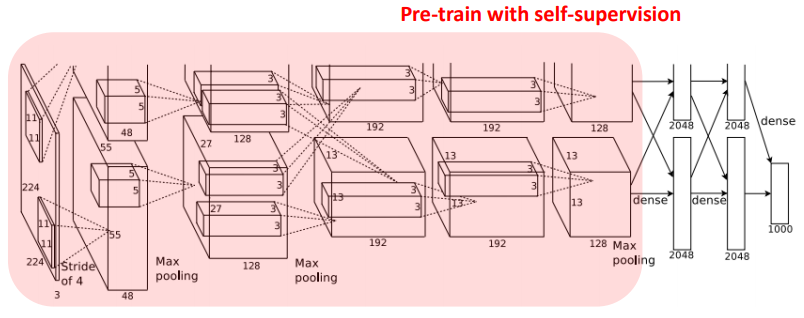
빨간 상자는 Pre-Training을 Self-Supervised로 얻은 Feature Extractor를 의미함. 대조학습에서 사용하는 주요 평가 방식은 크게 두 가지로, 태스크 일반화(Task Generalization)와 데이터셋 일반화(Dataset Generalization)로 모델의 표현 학습 성능을 평가합니다. 두 개념은 모두 모델이 얼마나 일반화된 유용한 표현을 학습했는지 확인하려는 목적을 가지고 있지만, 평가 방법은 다릅니다.
- 태스크 일반화(Task Generalization)
- 평가 목표:
- 모델이 다양한 태스크에 대해 얼마나 일반화된 표현을 학습했는지 확인하는 것
- 방법:
- 대조학습을 통해 학습한 모델을 고정(frozen)한 상태에서, 이미 학습된 표현에 간단한 선형 분류기를 붙여서 지도 학습 방식으로 Downstream Task를 학습 및 평가
- 평가 의미:
- 피처 추출기(Feature Extractor)가 얼마나 효과적으로 유용한 특징을 학습했는지를 평가함
- 모델이 학습한 표현이 단순한 선형 레이어만으로도 높은 성능을 낼 수 있다면, 이는 모델이 높은 품질의 특징을 잘 학습했다는 것을 의미함
- 데이터셋 일반화(Dataset Generalization)
- 평가 목표:
- 대조학습을 통해 학습한 표현이 다른 데이터셋에서도 얼마나 일반화된 성능을 보이는지 평가하는 것
- 방법:
- 대규모 데이터셋에서 pre-training을 수행하고, 다른 다운스트림 데이터셋에서 다양한 태스크를 전이하여 파인튜닝을 수행함.
- 이 때 모든 가중치는 업데이트가 가능하고, fine-tuning을 통해 전체 모델을 다시 학습함
- 평가 의미:
- 피처 추출기의 품질 자체를 평가하는 것이 아니라, 모델이 pre-training된 후 다른 데이터셋과 태스크로 전이되어 얼마나 잘 적응하는지 확인함
- 모델이 새로운 데이터셋이나 태스크에 얼마나 유연하게 적응할 수 있는지 평가함
- 즉, 대조학습을 통해 얻은 표현이 다른 도메인에서도 효과적인지를 확인하는 방식
1) 태스크 일반화(Task Generalization)는 피처 추출기의 성능을 확인하는데 초점을 맞추며, 학습된 표현이 다양한 태스크에서 얼마나 일반화된 특징을 잘 잡아내는지 확인하는 방법입니다. 이 과정에서는 모델 가중치를 고정하고, 간단한 분류기만 사용하여 성능을 측정합니다. 2) 데이터셋 일반화(Dataset Generalization)는 모델이 다양한 데이터셋에 대해 얼마나 잘 적응하는지, 즉 fine-tuning 후 성능이 얼마나 좋은지를 평가하는 방법입니다. 이 방법은 대조학습을 통해 학습한 표현이 다른 도메인에서도 유용한지 확인하는 데 목적이 있습니다. 저희는 그 중에서도 ’Feature Extractor가 얼마나 표현을 잘 학습했는가‘를 평가하기 위해, 선형 평가(간단한 분류기 사용)로 성능을 확인했습니다.
6.4.3 Result - Linear Evaluation
선형 평가의 경우, 기존 Feature Extractor를 사용하며 뒤에 선형 레이어를 추가하여 기존에 존재하는 Status(코로나 양음성)에 대한 Accuracy, Precision, Recall, F1 Score를 평가했습니다. Accuracy, Precision, Recall, F1 Score는 Classification에서 사용되는 Metric입니다. 해당 Metric들은 실제 데이터의 정답값과 모델이 분류해낸 결과의 관계가 어떻냐에 따라 정할 수 있습니다. 진행한 실험에 대한 결과는 환자의 메타데이터를 기준으로 하나씩 나열하면 다음과 같습니다.

Accuracy
- 올바르게 예측된 데이터의 수를 전체 데이터의 수로 나눈 값
Precision
- 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
Recall (a.k.a Sensitivity)
- 실제 True인 것 중에서 모델이 True라고 분류한 것의 비율
F1 Score
- Precision 과 Recall의 조화 평균
다른 분야들도 지표가 중요하지만, 특히나 Medical 분야에서는 지표가 미치는 영향이 커서 각 지표가 뭘 의미하는지 명확히 이해하고 있어야 합니다. Medical에서는 다른 지표들 중에서도 민감도와 특이도를 더 크게 살펴봅니다. 민감도는 실제값이 참인 관측값(FP+FN) 중에서 참이라고 바르게 예측(TP)한 정도를 의미하고, 특이도는 실제값이 거짓인 관측값(FP+TN) 중 거짓으로 바르게 예측(TN)한 정도를 의미합니다. 즉, 실제 음성인데, 양성으로 분류된 비율을 의미합니다. 예시를 들면서 설명해보겠습니다.
폐렴을 찾는 예시
- 민감도 특이도:
- 특이도가 1이 되면, 모델이 폐렴이라고 하는건 실제 폐렴이지만 모든 폐렴을 찾지 못함
- 민감도 특이도:
- 민감도가 1이면, 모델이 폐렴이라고 하는 것 중에 폐렴이 아닐 수 있지만 모든 폐렴을 찾을 수 있음
예시를 보면 알 수 있겠지만, 특히나 의료 분야에서는, 실제 질병 환자를 놓치는게 더 위험해서 민감도, 즉 Recall이 더 높은 것을 선호합니다. 그렇다면 Recall을 중심으로 지표들을 보겠습니다. 발표 자료에 첨부되어 있는 모델 학습 결과는 아래와 같습니다.
Metadata \ Metric Accuracy Precision Recall F1 Score Validation Loss
COVID-19 Symptoms 0.6921 0.7359 0.6921 0.6533 4.4033
Gender 0.5799 0.3362 0.5799 0.4257 4.5557
Respiratory Aliment 0.4201 0.1765 0.4201 0.2486 2.4686
이후에 진행된 모델 학습에서 더 나은 결과 값을 보였습니다.
Metadata Accuracy Precision Recall F1 Score
COVID-19 Symptoms 0.8259 0.8254 0.8259 0.8249
이에 대한 해석은 밑의 Conclusion에 작성하겠습니다.
6.5 Project Demo Page
모델 학습이 제일 잘됐던 ‘COVID-19 Symptoms’ 파일을 기준으로, 오픈세미나에 참여하신 분들이 직접 체험해보실 수 있는 데모 페이지를 구축했습니다. 데모 시간 때 ‘A-2. 당신의 호흡음은 코로나를 알고 있다‘ 테이블로 오신다면, 직접 체험이 가능합니다!
6.5.1 Used Model
발표 자료 최종 제작 이후 완성된 데모 페이지기 때문에, 사용한 모델의 성능이 다소 높아져 먼저 여기서 사용한 모델의 성능을 공유합니다.
Metadata Accuracy Precision Recall F1 Score
COVID-19 Symptoms 0.8259 0.8254 0.8259 0.8249
앞서서 공유드린 실험 결과보다도, 모델의 성능이 다양한 지표에서 안정화되고 높아져 더 믿을 수 있는 데모 페이지가 되었을 것이라고 예상합니다.
6.5.2 데모 시연 영상
동영상1. Demo Page 모습.
[데모 페이지 설명서]- 사용자의 호흡음 녹음
- 사용자의 호흡음을 직접 녹음하고, 이를 저장합니다.
- STOP 버튼을 클릭해 녹음을 종료하고, 녹음 종료 버튼을 클릭해 녹음된 오디오를 저장합니다.
- 녹음된 호흡음 확인 및 분석
- 저장된 오디오를 직접 재생하여 제대로 녹음되었는지 확인 가능합니다.
- 녹음 분석 버튼을 클릭해 MFCC로 호흡음을 시각화 해줍니다.
- 코로나 증상 선택 및 양/음성 예측
- 코로나 관련 증상이 있다면 선택합니다.
- 호흡음 코로나 상태 예측 버튼을 눌러 모델 예측 결과를 확인합니다.
- 초기화
- 예측 결과 확인 후, 처음부터 다시 시작을 눌러 모든 데이터를 초기화하고 처음부터 다시 시작할 수 있습니다.
데모 결과는 참고용으로만 활용해 주시길 바랍니다. 어디까지나 데모일 뿐입니다.
7. Conclusion
7.1 Linear Evaluation Insight
7.1.1. Recall 값에 대한 Insight
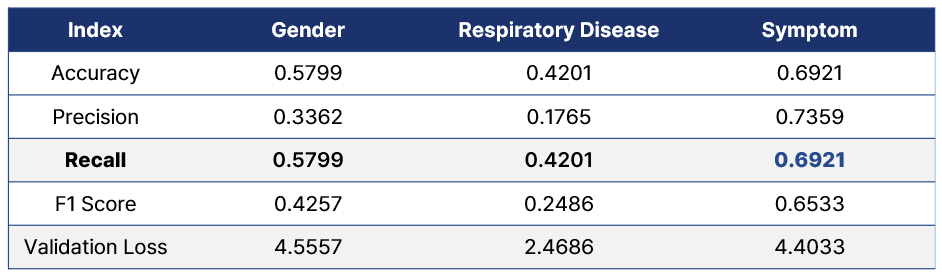
대조학습에 여러 Index를 적용한 결과 Symptom을 적용한 Model의 정확도가 가장 높은 것으로 나타났습니다. 각각의 Index가 모두 임상적으로 COVID-19과 관련이 있다고 알려진 요인이지만, 하나의 Index만 좋은 성능을 가지는 것은 다른 Index와는 차별되는 특징이 있다고 생각했습니다. 이를 다른 Index(Gender, Respiratory Disease)는 COVID-19 발병 시 중증도와 연관 관계가 있다고 알려진 요인이지만, Symptom은 COVID-19의 양음성과 상관관계가 있기 때문이라 결론내렸습니다.
7.1.2. Loss 값과 Recall 값 사이의 상관 관계
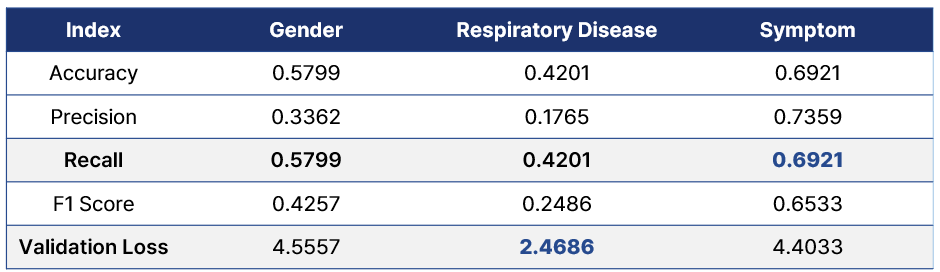
학습 과정과 테스트 과정에서 모두 좋은 성능을 보였던 호흡기 질환 여부(Respiratory Disease)는 정확도를 측정하는 모든 평가 기준에서 좋지 못한 결과를 보였습니다. 저희는 이런 결과의 이유로 MoCo 모델이 호흡기 질환 여부를 기반으로 특성을 효과적으로 학습했지만, COVID-19의 양음성 진단에는 효과적이지 않았다고 추측하였습니다. 표현 학습에는 효과적이었던 만큼, 하이퍼 파라미터(Learning Rate, Batch Size 등)를 조절하면 더 좋은 성능을 낼 수 있으리라 예상합니다.
7.2 후속 연구
Index(Gender, Respiratory Disease)는 COVID-19 발병 시 중증도와 연관 관계가 있다고 알려진 요인인 만큼, 추후 실험으로 코로나 중증도 예측 대조학습 실험도 진행해볼 예정입니다. 데이터가 다양한 음성 데이터를 제공함에도 불구하고, 호흡음과 관련된 데이터만 사용한 점이 아쉬움으로 남습니다. 다이브 발표가 끝난 이후, 호흡음을 포함하여 다른 음성 데이터(기침, 모음소리)를 더 활용하여 진행해볼 계획입니다. 저희가 아이디어를 얻었던 논문undefined9undefined에서는 심장음과 폐음으로 진행했는데, 다른 음성 데이터를 사용할 때마다 유효한 증강방식 및 메타데이터가 달랐으므로, 저희도 그 점에서 추가적인 인사이트를 얻을 수 있을 것이라고 생각합니다.
Reference
undefined1undefined Kristin Hayes, "Rhonchi and Rales: What's the Difference?", verywellhealth, Dec 20, 2023, https://www.verywellhealth.com/rhonchi-and-rales-5084515 [2] Hafke-Dys, H., Bręborowicz, A., Kleka, P., Kociński, J., & Biniakowski, A. (2019). The accuracy of lung auscultation in the practice of physicians and medical students. PLoS One, 14(8), e0220606. [3] 세종충남대학교병원, “AI 자동 호흡음 분석 알고리즘 개발,정확한 분석과 신속한 진료로 이어지다”, 2022년, https://www.cnush.co.kr/html/webzine/202406/vol15/sub06.html undefined4undefined 서울아산병원, “질환백과 - 코로나-19(COVID-19)”, https://cancer.amc.seoul.kr/asan/healthinfo/disease/diseaseDetail.do?contentId=33922 undefined5undefined B. Wang, et al., “Characteristics of pulmonary auscultation in patients with 2019 novel coronavirus in china,” SSRN Electronic Journal, 01 2020. undefined6undefined Aytekin, I., Dalmaz, O., Gonc, K., Ankishan, H., Saritas, E. U., Bagci, U., ... & Çukur, T. (2023). Covid-19 detection from respiratory sounds with hierarchical spectrogram transformers. IEEE Journal of Biomedical and Health Informatics. undefined7undefined Bhattacharya, D., Sharma, N. K., Dutta, D., Chetupalli, S. R., Mote, P., Ganapathy, S., ... & Alagesan, M. (2023). Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection. Scientific Data, 10(1), 397. undefined8undefined NAVER LABS Europe, “Improving self-supervised representation learning by synthesizing challenging negatives”, 2020년, https://europe.naverlabs.com/blog/improving-self-supervised-representation-learning-by-synthesizing-challenging-negatives/ undefined9undefined Vu, D. Q., Le, N., & Wang, J. C. (2024, July). Self-supervised learning via multi-transformation classification for action recognition. In 2024 IEEE International Conference on Multimedia and Expo Workshops (ICMEW) (pp. 1-6). IEEE. undefined10undefined He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9729-9738). undefined11undefined Soni, P. N., Shi, S., Sriram, P. R., Ng, A. Y., & Rajpurkar, P. (2022). Contrastive learning of heart and lung sounds for label-efficient diagnosis. Patterns, 3(1). undefined12undefined 김윤미, "코로나19, 왜 여성보다 남성에게 치명적일까?", 청년의사, 2022, https://www.docdocdoc.co.kr/news/articleView.html?idxno=2025909 undefined13undefined Jordan, R. E., Adab, P., & Cheng, K. (2020). Covid-19: risk factors for severe disease and death. Bmj, 368. undefined14undefined Yusnita, M. A., Paulraj, M. P., Sazali Yaacob, R. Y., & Shahriman, A. B. (2013). Analysis of accent-sensitive words in multi-resolution mel-frequency cepstral coefficients for classification of accents in Malaysian English. International Journal of Automotive and Mechanical Engineering, 7, 1053-1073.