
🔮 목차
1. 프로젝트 개요
온라인 쇼핑 소비자들은 다양한 리뷰를 참고하지만 다량의 리뷰로 인해 중요한 정보를 놓치는 경우가 있습니다. 이는 제품의 장단점을 제대로 파악하지 못하게 하여 결국 구매 후 만족도를 낮추는 결과를 초래합니다. 이러한 문제 상황을 바탕으로 저희는 리뷰의 핵심 내용을 간결하게 요약하는 서비스가 필요하다고 판단했습니다. 저희의 리뷰 요약 서비스는 소비자가 복잡한 리뷰를 읽지 않고도 제품의 주요 장단점을 신속하게 이해할 수 있도록 돕고, 판매자에게는 제품 개선과 마케팅 전략 수립에 유용한 인사이트를 제공합니다. 그렇다면 마켓컬리를 분석 대상으로 선택한 이유는 무엇일까요? 마켓컬리는 상품위원회를 통해 고품질 제품을 엄선하고 신선 제품을 새벽에 배송하는 등 식품 분야에 있어 전문성이 있는 기업입니다. 이러한 마켓컬리의 사용자들은 대체로 식품에 대한 높은 관심도를 가지고 있고, 이는 맛과 품질에 대한 구체적인 리뷰를 얻는 데 큰 장점이 됩니다. 그러나 현재 마켓컬리의 리뷰 서비스는 사용자가 리뷰를 자세히 읽어야만 제품을 제대로 이해할 수 있는 구조입니다. 별점 시스템이 없기 때문에 소비자들은 리뷰의 개수, 내용, 사진 등을 참고하여 상품을 판단해야 하며, 리뷰 정렬 방식이 ‘최신순’과 ‘추천순’으로만 제한되어 있어 필요한 정보를 쉽게 찾기 어렵습니다. 이로 인해 대량의 리뷰를 빠르게 파악하기 어렵고 구매 결정을 내리는 데 복잡함을 느껴 많은 시간과 노력을 소모하게 됩니다. 따라서 저희는 사용자가 리뷰를 효율적으로 이해할 수 있도록 감정과 키워드 중심의 마켓컬리 리뷰 요약 서비스를 구현했습니다. 이는 소비자와 판매자 모두에게 구매 과정과 리뷰 분석을 간소화하고 온라인 쇼핑 환경에서의 경험을 향상시킬 것입니다.
2. 데이터 개요
2-1. 데이터 수집
리뷰 데이터 수집 대상으로는 마켓컬리의 ‘국·탕·찌개’ 카테고리의 상품들을 사용했으며, 수집 방법으로는 Selenium을 활용한 웹 크롤링 방법을 선택했습니다. ‘국·탕·찌개’ 카테고리는 상품 수 및 상품별 리뷰 수가 크롤링으로 수집하기에 적절하고, 마켓컬리만의 차별화된 다양한 제품군을 포함하고 있으며, 사용자가 간편하게 조리하여 바로 사용하는 형태의 식품들이 많아 제품 자체의 특성을 설명하는 후기가 많을 것이라 생각해 이 카테고리를 선택했습니다.
2-2. EDA
- **상품별 리뷰 개수
**상품별 리뷰 개수에 대한 히스토그램 분석 결과, 가장 많은 수의 리뷰는 약 17만 개이며, 두 번째로 많은 리뷰 수는 약 5만 개입니다. 또한 리뷰 수가 1000개 이하인 상품들의 히스토그램을 확인한 결과, 리뷰 수가 100개 미만인 상품은 총 18개로 나타났습니다.
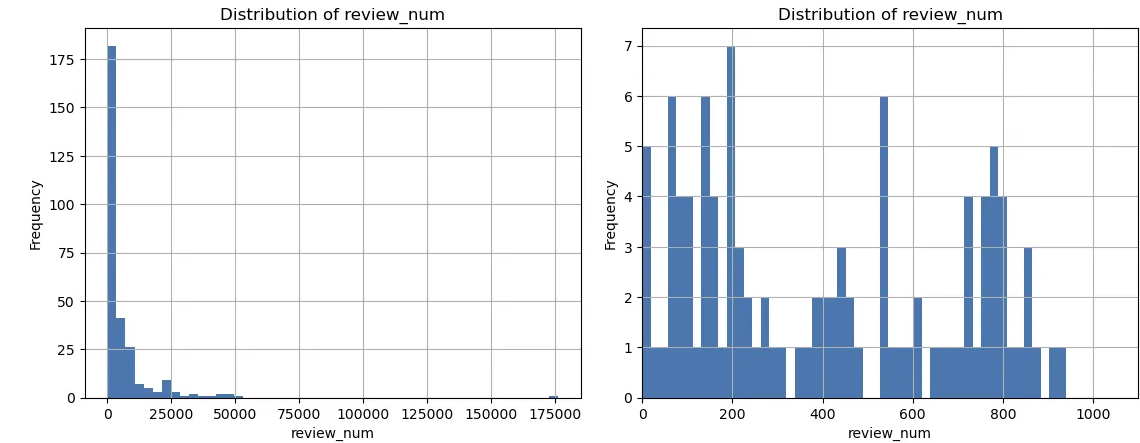
리뷰 수가 17만 개인 상품은 데이터 수집 시간 단축을 위해 최신 리뷰 순으로 두 번째로 많은 리뷰 수인 50,291개만 선택하여 분석 대상으로 사용하였습니다. 데이터 수집 시점을 통일하기 위해 2024년 8월 25일을 기준으로 이전 시점까지 작성된 리뷰만 사용했습니다. 또한 요약 태스크의 성능을 위해 리뷰 수가 너무 적은 100개 미만인 상품을 분석 대상에서 제외하고, 크롤링 과정 중 페이지에 더이상 접근할 수 없었던 2가지 상품도 제외했습니다. 최종적으로 '국·탕·찌개' 카테고리 내 267개의 상품, 약 150만 개의 리뷰를 분석 대상으로 선정했습니다.
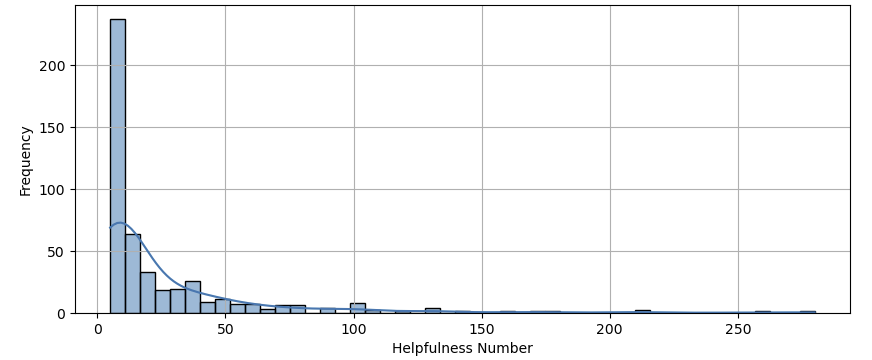
- **리뷰별 ‘도움돼요’ 개수
**'도움돼요'가 0개인 리뷰가 약 150만 개로 가장 많았으며, 1개인 리뷰는 약 4만 7천 개로 나타났습니다. '도움돼요' 개수의 최댓값은 560개였고, 두 번째로 많은 값은 350개였습니다.
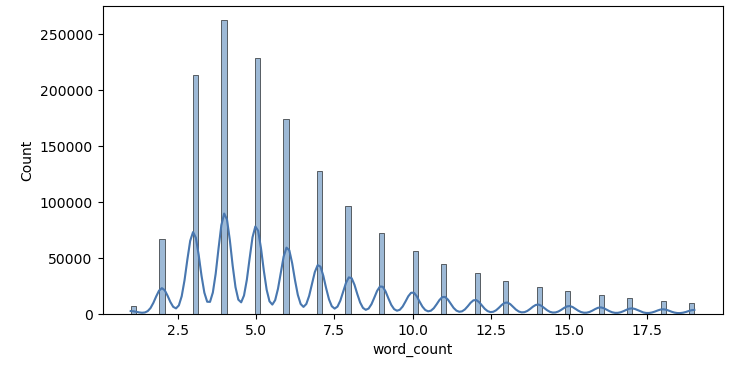
- **리뷰별 단어 개수
전체 리뷰 데이터가 약 150만 개로 방대하므로, 요약문 작성 시 길이가 너무 짧은 리뷰는 제외하기 위해 리뷰 별 단어 수에 대해 분석했습니다. 가장 단어 수가 많은 리뷰는 502개의 단어로 작성되었고, 빈도 수가 가장 높은 리뷰는 4개의 단어로 작성된 경우가 262,505개였습니다. 단어 수가 4 이하인 리뷰를 제거하면 전체 150만 개의 리뷰 중 약 35%가 삭제되며, 단어 수가 3 이하인 리뷰를 제거하면 약 19%가 제거됩니다. 따라서 가장 빈도 수가 높았던 4를 기준으로 단어 수가 4개 이상인 리뷰들만 사용**하기로 결정했습니다.
2-3. 데이터 전처리
- **결측치 & 중복값 제거
**‘review’ 열에 존재하는 5개의 결측치와 3,181개의 동일인이 동일한 내용으로 이중 작성한 리뷰를 제거했습니다.
- **특수문자 & 이모티콘 제거
**한국어, 영어, 숫자, 띄어쓰기, 줄바꿈을 제외한 모든 문자를 제거하고, 'ㅋㅋ', 'ㅠㅠ'와 같이 하나의 모음 혹은 자음으로 이루어진 문자를 제거했습니다.
- **한국어 리뷰 필터링
**완성된 한국어 문장이 아닌 826개의 리뷰들을 제거했습니다.
- **'product_type' 통일
**같은 상품이지만 상품명이 변하며 다르게 인식된 'product_type'을 통일했습니다. 예를 들어, id가 1000166234인 상품의 product_type이 ['인삼품은 소꼬리곰탕' ,'인삼품은 꼬리곰탕']인 경우, '인삼품은 꼬리곰탕'으로 통일했습니다.
- **띄어쓰기 교정
kiwipiepy **형태소 분석기를 사용해 띄어쓰기 교정을 진행했습니다.
다양한 띄어쓰기 교정 방법의 시도
첫 번째로, PyKoSpacing을 사용하여 띄어쓰기 교정을 시도했습니다. 이 도구는 한국어 띄어쓰기를 자동으로 교정하는 기능을 제공하지만, 특정 문장에 대해 완벽한 결과를 얻지 못했습니다. 두 번째로, konlpy 형태소 분석기를 활용해 띄어쓰기 문제를 해결하려고 했습니다. 이 분석기는 형태소를 기반으로 언어 처리를 진행했지만, 결과가 만족스럽지 않았습니다. 세 번째 시도에서는 kiwipiepy 형태소 분석기를 적용했습니다. 이 방법은 기존의 두 시도에 비해 띄어쓰기 교정의 정확도가 높아 효과적인 결과를 보여줬습니다. 마지막으로, ETRI-et5 모델을 기반으로 한 맞춤법 교정기도 시도했지만, kiwipiepy만큼의 만족스러운 결과를 얻지 못했습니다. 이에 따라 최종적으로 가장 우수한 성능을 보여준 kiwipiepy 형태소 분석기를 선택하여 띄어쓰기 교정을 진행했습니다.
3. 사용 NLP 기법
3-1. Meta-Llama
Llama(Large Language Model Meta AI)는 Meta사에서 제작한 LLM(Large Language Model)입니다. OpenAI의 GPT 모델과 달리 무료로 사용할 수 있도록 오픈 소스로 공개되어 있는 점이 특징입니다. 최근 Llama 3.2버전이 공개되었는데, 프로젝트를 진행하는 시점에선 3.1 버전이 가장 최신의 버전이었기 때문에 본 프로젝트에선 Llama-3.1- 8B-Instruct를 사용했습니다. 이름 중 8B는 80억 개의 파라미터를 가진 모델이라는 뜻입니다. 모델이 클수록 학습할 수 있는 패턴과 복잡성이 증가하지만, 그만큼 더 많은 계산 자원이 필요합니다. 저희가 사용할 수 있는 리소스 내에서는 8B가 최대였기에 이 모델을 사용했습니다. Instruct는 이 모델이 주로 "Instruction Following"에 최적화되었다는 것을 나타냅니다. 즉, 사용자가 주는 지시나 명령을 따라 특정 작업을 수행하는 데 최적화된 모델입니다. 이를 통해 질문에 답하거나 요약하는 등의 작업에 더 나은 성능을 발휘할 수 있고, 이 부분이 저희 서비스 설계에 적합했습니다. Llama 모델을 사용하면서 파라미터 조정을 통해 출력 결과를 조정하고, 양자화를 적용하여 리소스 사용의 효율성을 높였습니다. 두 개념은 Llama뿐만이 아니라 일반적인 LLM을 사용할 때 적용될 수 있는 개념이며, 각각에 대한 설명은 다음과 같습니다.
파라미터 종류(일부)
파라미터 이름 설명
max_new_tokens 생성할 최대 토큰 수를 설정합니다. 이 값이 클수록 더 긴 텍스트가 생성됩니다.
temperature 생성된 텍스트의 무작위성을 조절합니다. 낮은 값(예: 0.2)은 보다 결정적인 출력을, 높은 값(예: 1.0 이상)은 더 창의적이고 무작위적인 출력을 생성합니다.
top_k 생성할 토큰을 선택할 때 상위 k개만 고려합니다. 예를 들어, top_k=50이면 상위 50개의 후보 중 하나를 무작위로 선택합니다.
top_p 누적 확률이 p 이하인 상위 후보 토큰들만 선택해 샘플링을 진행하는 방법입니다. 예를 들어, top_p=0.9는 후보 토큰들의 확률을 높은 순서대로 정렬한 뒤, 누적 확률이 90% 이상이 될 때까지 선택된 토큰들만 후보로 사용합니다.
repetition_penalty 반복된 단어에 대한 패널티를 부과하는 매개변수입니다. 1보다 큰 값을 설정하면 반복된 문장을 덜 생성하게 됩니다. 보통 1.2 정도를 사용합니다.
3-2. OpenAI GPT API
OpenAI에서는 API형태로 모델을 불러와서 쓸 수 있는 서비스를 제공하고 있습니다. 이 서비스를 활용하면 코드 내에서도 ChatGPT 서비스처럼 질의-응답을 받을 수 있습니다. OpenAI는 다양한 모델의 API를 제공하고 있는데요, 저희는 그 중에서도 Chat 모델 중 GPT-4o-mini를 활용했습니다. GPT-4o-mini는 Chat 모델 중 가장 최신 버전인 GPT 4o의 경량화 버전으로 sLM(Small-scale Language Model)이라고 할 수 있습니다. 일부 기능에서는 성능이 떨어질 수 있지만, 비용이 GPT-4o보다 50%이상 저렴하고 빠르다는 장점이 있습니다.
다양한 Chat 모델 종류 및 토큰 개수
Model Token limits Request and other limits Batch queue limits
Chat
gpt-3.5-turbo 2,000,000 TPM 5,000 RPM 20,000,000 TPD
gpt-3.5-turbo-0125 2,000,000 TPM 5,000 RPM 20,000,000 TPD
gpt-3.5-turbo-1106 2,000,000 TPM 5,000 RPM 20,000,000 TPD
gpt-3.5-turbo-16k 2,000,000 TPM 5,000 RPM 20,000,000 TPD
gpt-3.5-turbo-instruct 90,000 TPM 3,500 RPM 200,000 TPD
gpt-3.5-turbo-instruct-0914 90,000 TPM 3,500 RPM 200,000 TPD
gpt-4 40,000 TPM 5,000 RPM 200,000 TPD
gpt-4-0613 40,000 TPM 5,000 RPM 200,000 TPD
gpt-4-turbo Shared limits:gpt-4-turbogpt-4-turbo-2024-04-09gpt-4-turbo-previewgpt-4-0125-previewgpt-4-1106-preview 450,000 TPM 500 RPM 1,350,000 TPD
gpt-4o Shared limits:gpt-4o-2024-05-13gpt-4o-2024-08-06 450,000 TPM 5,000 RPM 1,350,000 TPD
gpt-4o-mini Shared limits:gpt-4o-mini-2024-07-18 2,000,000 TPM 5,000 RPM 20,000,000 TPD
3-3. 프롬프트 엔지니어링
프롬프트(prompt)는 LLM에게 특정 작업을 지시하는 명령어로, 모델에게 수행해야 할 작업을 알려주는 입력입니다. 모델은 프롬프트에서 주어진 지침에 따라 결과를 생성합니다. 이러한 프롬프트를 효과적으로 설계하는 과정을 프롬프트 엔지니어링이라고 하며, 이는 AI 모델이 보다 정확하고 유용한 응답을 제공하도록 프롬프트를 구성하고 최적화하는 기법입니다. 모델의 특성과 작업 요구에 따라 프롬프트를 조정하여 최상의 결과를 도출하기 위해 프롬프트 엔지니어링에서는 다양한 전략과 방법을 활용합니다. 대표적으로 제로샷(Zero-Shot), 원샷(One-Shot), 퓨샷(Few-Shot)과 같은 기법이 적용됩니다. 여기서 '샷(Shot)'은 프롬프트에 포함된 예시의 개수를 의미합니다. Zero-Shot은 예시 없이 모델이 이미 학습한 지식만으로 작업을 수행하는 방식입니다. One-Shot은 하나의 예시를 제공하고, few-shot은 소량의 예시를 제공하여 모델이 특정 패턴이나 작업의 맥락을 더 정확하게 이해할 수 있도록 합니다. 이 중 본 프로젝트에선 모델이 정확하게 작업을 수행할 수 있도록 여러 예시를 제공하는 few-shot prompting 방식 활용해 프롬프트 엔지니어닝을 수행했습니다.
4. 서비스 설계
4-1. 키워드 추출
키워드를 추출하기 위해 2020년 이후 작성된 리뷰 중 4단어 이상으로 구성된 리뷰에 대하여 ‘도움돼요’ 개수 기준으로 정렬한 후 상위 100개의 리뷰를 선택해 분석 대상으로 사용했습니다. 키워드 추출 작업에는 Llama-3.1-8B-Instruct 모델을 활용하여 few-shot 프롬프팅을 적용했습니다.
system_prompt = '''
예시:
- 구문: '정말 고기가 듬뿍 들었고'
- 키워드: 고기, 양
- 구문: '배송이 너무 느려요'
- 키워드: 배송
- 구문: '양도 많고 간단해서 좋네요'
- 키워드: 양, 간편함
- 구문: '간이 생각보다 쎄서'
- 키워드: 간이 쎔
- 구문: '포장이 꼼꼼하게 왔어요'
- 키워드: 포장
'''최종적으로 493개의 키워드를 추출했습니다. 추출한 키워드들을 바탕으로 ['맛/향/풍미', '보관', '포장/배송', '양', '가격', '활용 방법']의 6가지 카테고리를 선정했습니다.
4-2. 카테고리 태깅
카테고리 태깅 단계는 2023년 이후의 4단어 이상의 리뷰를 기준으로 진행했습니다. 우선, 각 상품의 리뷰를 '도움돼요' 개수가 많은 순, 최신 리뷰 순으로 정렬한 후 상위 50개의 리뷰만을 선택하여 사용했습니다. 카테고리는 앞서 선정한 ['맛/향/풍미', '보관', '포장/배송', '양', '가격', '활용 방법']을 적용했습니다. 카테고리 태깅 작업에는 GPT-4o-mini 모델에 대하여 few-shot 프롬프팅을 적용했습니다.
example = """
review
'''후기 좋아서 사 봤는데 고기가 듬뿍 들었고 팍팍하지 않고 부들부들해요
근데 양 곰탕인데 내장은 몇 개 없어서 아쉬워요
그리고 냉동 제품이지만 제조 일이 오래된 거 아닌가요 재고 세일인 건가라는 생각도 드네요”'''
category_labels
{"고기가 듬뿍 들었고":'양',
"팍팍하지 않고 부들부들해요":'맛/향/풍미',
"내장은 몇 개 없어서 아쉬워요":'양',
"냉동 제품이지만 제조 일이 오래된 거 아닌가요":'포장/배송',
"재고 세일인 건가라는 생각도 드네요":'포장/배송'}
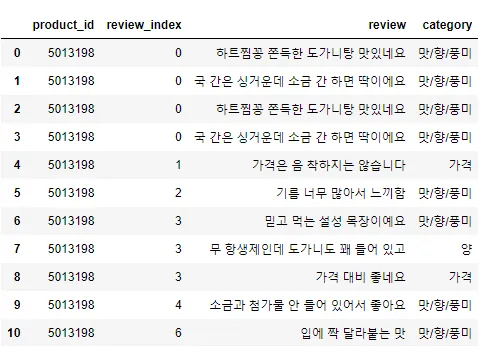
"""위 예시에서 review는 사용자가 작성한 리뷰 텍스트, category_labels는 각 리뷰에서 특정 문장과 그 문장이 속하는 카테고리의 쌍이 포함된 딕셔너리를 의미합니다. 카테고리 태깅 결과의 예시는 다음과 같습니다.
4-3. 감정 분석
서비스에서 상품의 장단점을 드러내기 위해 긍정(positive), 부정(negative)의 감정별로 요약을 제시하기 위해 각 리뷰를 긍부정으로 태깅할 필요가 있었습니다. 다만, 한 리뷰 안에 긍부정이 함께 있거나, ‘그저 그렇다’ 등의 내용을 담은 리뷰도 있었기 때문에 중립(neutral)도 포함했습니다. 다양한 감정 태깅 데이터셋과 모델을 실험해본 결과, 예시를 제시하여 프롬프팅하는 few-shot 프롬프팅이 가장 성능이 좋아 채택했습니다. 최종적으로 작성한 예시와 선정한 프롬프트는 아래와 같습니다.
예시(13개, 직접작성)
example = """
리뷰='''
맛 별로 쟁여템이에요
비상식량으로 비축해 둡니다
'''
positive
리뷰='''
고추장 찌개 평범해요
그냥 먹을 만은합니다
'''
neutral
리뷰='''
갈비는 아주 아주 작은 거 세 개에 갈비탕 맛은 없고
안 매운 고추만을 넣어 삶은 물을 마시는 느낌'
'''
negative
리뷰='''
물을 240ml 더 넣고 끓여서 먹었어요
맛은 너무 좋은데 짜서 물 더 부으니
라면 사리도 넣고 맛있게 먹었습니다
햄은 종류별로 많이 들어 있었어요
''''
positive
"""프롬프트
f"""
당신은 상품에 대한 고객의 리뷰를 감정에 따라 분류하는 소비자 분석가이다.
**지시사항:**
주어진 리뷰에 드러나는 가장 주된 감정을 분석하여
'positive', 'negative', 'neutral' 중 하나의 감정으로 태깅하라.
리뷰의 문맥을 충분히 반영해야하며, 각 리뷰는 한 감정에만 태깅된다.
**출력 방식**
'positive' 혹은 'negative' 혹은 'neutral' 중 하나만 출력한다.
다른 어떠한 추가 설명도 함께 출력해서는 안된다.
**예시**
"""먼저 모델에게 “고객의 리뷰를 감정에 따라 분류하는 소비자 분석가”라는 역할을 부여하고, “지시사항 : ”, “출력방식 : ”, “예시 : ”와 같은 명확한 표현으로 요구사항을 제시했습니다. sentiment에 positive, neutral, negative이외의 단어가 출력되는 문제를 방지하기 위해 “다른 어떠한 추가 설명도 함께 출력해서는 안된다.”라는 내용을 추가하여 성능을 개선했습니다. 리뷰에 대한 감정분석 예시는 아래와 같습니다.
product_type review sentiment
베트남 쌀국수 Pho 4인분 이거 진짜 맛나요\n먹어 본 베트남 쌀국수 팩으로 들어 있는 것 중에 젤 맛있었어요... positive
감정분석 모델 실험 과정
few-shot 프롬프팅 외, KOTE(Korean Online That-gul Emotions) 데이터셋을 이용해 KcELECTRA를 fine-tuning한 한국어 감정분석 모델을 사용해보았습니다.
감정종류(43개) 및 postiive/neutral/negative로 분류한 결과
dissatisfaction 불평/불만
fed up 지긋지긋
sadness 슬픔
anger 화남/분노
disappointment 안타까움/실망
distrust 의심/불신
shame 부끄러움
fear 공포/무서움
despair 절망
pathetic 한심함
disgust 역겨움/징그러움
irritation 짜증
preposterous 어이없음
gessepany 패배/자기혐오
laziness 귀찮음
exhaustion 힘듦/지침
guilt 죄책감
contempt 증오/혐오
embarrassment 당황/난처
shock 경악
reluctant 부담/안_내킴
sorrow 서러움
boredom 재미없음
compassion 불쌍함/연민
anxiety 불안/걱정
welcome 환영/호의
admiration 감동/감탄
gratitude 고마움
respect 존경
expectancy 기대감
pride 뿌듯함
comfort 편안/쾌적
interest 신기하마/관심
care 아껴주는
excitement 즐거움/신남
attracted 흐뭇함(귀여움/예쁨)
happiness 행복
joy 기쁨
relief 안심/신뢰
arrogance 우쭐댐/무시함
surprise 놀람
realization 깨달음
resolute 비장함
NO EMOTION 없음
P_N_dict = {'불평/불만':'negative', '지긋지긋':'negative', '슬픔':'negative', '화남/분노':'negative', '안타까움/실망':'negative',
'의심/불신':'negative', '부끄러움':'negative', '공포/무서움':'negative', '절망':'negative', '한심함':'negative',
'역겨움/징그러움':'negative', '짜증':'negative', '어이없음':'negative', '패배/자기혐오':'negative', '귀찮음':'negative', '힘듦/지침':'negative',
'죄책감':'negative', '증오/혐오':'negative', '당황/난처':'negative', '경악':'negative', '부담/안_내킴':'negative', '서러움':'negative',
'재미없음':'negative','불쌍함/연민':'negative', '불안/걱정':'negative',
'환영/호의':'positive', '감동/감탄':'positive', '고마움':'positive', '존경':'positive', '기대감':'positive',
'뿌듯함':'positive', '편안/쾌적':'positive', '신기함/관심':'positive', '아껴주는':'positive', '즐거움/신남':'positive',
'흐뭇함(귀여움/예쁨)':'positive', '행복':'positive', '기쁨':'positive', '안심/신뢰':'positive',
'우쭐댐/무시함':'neutral', '놀람':'neutral', '깨달음':'neutral', '비장함':'neutral', '없음':'neutral'
}- KOTE를 사용해 fine-tuning한 감정 분석 모델
- pre-trained 모델로 KcELECTRA를 사용
- pre-trained 모델의 마지막 hidden layer [CLS] 토큰에 1개의 linear layer를 삽입한 multi-label classification 구조
- GoEmotions(영어 데이터셋)을 기계번역한 데이터셋으로 훈련시킨 경우보다 더 좋은 성능을 보임
이 모델에서는 한 리뷰에 여러가지 감정이 태깅되기 때문에, 한 가지의 감정을 선택하기 위해 3가지 분류 기준을 시도해봤습니다.
sentiment_ver1: 확률이 최대인 감정이 속한 sentiment로 분류sentiment_ver2: 긍정/부정/중립 평균 확률을 계산하고 최대 확률인 sentiment로 분류sentiment_ver3: 확률이 0.4가 넘는 감정들의 voting 결과 선정된 sentiment로 분류
sentiment_ver1과 sentiment_ver3 에서 어느 정도 정확도를 보였으나, 아래와 같이 특정 문장들에 대해선 감정을 잘못 분류하는 경우가 많았습니다. 따라서 최종 감정분석 모델로는 KOTE보다 더 정확도가 높았던 Llama 프롬프팅을 선택했습니다.
KOTE 기반 모델이 잘못 분류한 리뷰 예시

4-4. 요약 모델
저희 서비스에서 제공하는 요약의 종류는 감정별 요약, 카테고리별 요약, 활용 방법(레시피) 요약 3가지입니다. 감정별, 카테고리별 요약은 Llama 모델을 사용하고, 활용 방법(레시피) 요약은 GPT 모델을 사용했습니다. 활용 방법(레시피) 요약에 GPT모델을 사용한 이유는 Llama 모델보다 GPT 모델의 성능이 더 좋았기 때문입니다. 또한 요약 대상 리뷰의 길이가 너무 짧으면 제대로 요약이 되지 않으므로 모든 리뷰들을 합쳤을 때 10단어 이상인 리뷰들만 사용했습니다. 각 요약 모델별 프롬프트를 작성 과정은 아래와 같습니다.
- 감정별/카테고리별 요약 프롬프트 작성과정 : Llama-3.1-8B-Instruct 모델 사용
감정별 요약 시 neutral의 경우 태깅된 문장의 내용이 비슷했으므로 제외하고 positive, negative대상으로만 진행했습니다. 최종적으로 작성한 프롬프트와 예시(few-shot), 파라미터 조정값, 출력 결과는 다음과 같습니다. 특징적인 점은 정제된 결과값을 얻기 위해 모델을 두 번 호출한다는 점, 감정에 따라 프롬프트가 달라진다는 점 등이 있습니다.
outputs = model.generate(**tokenizer(inputs,
return_tensors="pt").to(device),
max_new_tokens=200,
pad_token_id=tokenizer.eos_token_id,
top_p=0.90,
temperature=0.2
)예시(5개, 출처: SSG.COM)
example = """
'''
이 제품은 가격대비 가성비가 좋고, 토핑도 풍부해서 맛있다는 소비자들의 평이 많아요. 집에서 간편하게 끓여 먹을 수 있어서 편리하고, 양도 푸짐해서 가족 모두에게 적합해요. 다만, 유통기한이 짧아서 버리는 경우가 있었다는 의견도 있어요.
'''
"""
감정별 프롬프트
if sentiment == 'positive':
sentiment_instructions = "장점과 좋은 점에 집중해서 요약해주세요."
elif sentiment == 'negative':
sentiment_instructions = "불만 사항과 문제점에 집중해서 요약해주세요."
첫번째 프롬프트
f"""
당신은 상품에 대한 고객의 리뷰를 요약해서 소비자에게 정보를 제공하는 소비자 분석가입니다.
**지시사항:**
리뷰:\n
이 리뷰들을
많이 나오는 내용을 중심으로 요약해주세요.
요약한 문장을 한 번 더 매끄러운 문장으로 만들어 주세요.
**제한사항:**
브랜드 이름은 넣지 마세요.
'소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.
**예시:**
**요약:**
"""
두번째 프롬프트
f"""
당신은 문장을 간결하게 만드는 요약 전문가입니다.
**지시사항:**
initial summary :
위 문장을 요약해주세요.
'소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.:
말투는 존댓말이어야 합니다.
**요약:**
"""sentiment summary
negative 이 제품은 가격이 비싼 편이고 기름이 많아 느끼한 맛이 있다는 의견이 많아요. 일부러 내용물이 들어 있는 제품을 구입한 고객분들이 있어요. 도가니보다 부속물이 많고 기름이 심한 제품을 받은 고객분들이 있어요. 일부러 뜯어 놓은 제품을 받은 고객분도 있어요. 기름이 많아 지방을 먹지 않는 고객분들이 있어요. 누린내가 심한 제품을 받은 고객분들이 있어요. 제품의 맛이 갑자기 묽어졌다는 의견도 있어요.
positive 이 제품은 가격 대비 가성비가 좋고, 도가니가 풍부해서 맛있다는 평이 많아요. 편리하고 양도 푸짐해서 가족 모두에게 적합합니다. 도가니탕 중에서 국물이 진하고 맛있다는 의견이 많아요.
실험 과정
- 먼저 지시사항을 명확하게 작성했습니다.
(49초 소요)
f"""
당신은 상품에 대한 고객의 리뷰를 요약하는 소비자 분석가입니다.
**지시사항:**
리뷰:\n
이 리뷰들을 한 문장으로 요약해주세요.
빈도 수가 높은 내용들을 중심으로 요약해주세요.
브랜드 이름은 넣지 마세요.
중복되는 말을 삭제하는 등 요약한 문장을 한 번 더 매끄러운 문장으로 만들어 주세요.
"""sentiment summary
negative 리뷰를 요약한 문장은 다음과 같습니다\.제품은 기름이 너무 많아 느끼하고 부속물이 많아 기름이 심해 맛이 묽어졌다고 하며, 일부러 뜯어 놔서 일부 제품이 맛이 나지 않아 재구매는 하지 않을 것 같다고 말합니다\.
positive 요약한 문장: 도가니탕은 맛있지만 고기 살이 까매요\. 국물이 진하고 맛있다\. 설성 목장은 소금과 첨가물이 들어있지 않아 좋아요\. 도가니는 양이 적어도 맛있다\. 가격이 비싸지만 품질이 좋은 이유는 육수가 맑고 구수하다는 것입니다\.
- 예시를 추가하여 few-shot 프롬프팅을 하고, 2단계 프롬프트를 사용(모델을 2번 호출)하는 방식을 시도했습니다.
→ 그 결과, 더 일관되고 정제된 표현이 사용되었지만, 처리 시간이 늘어났습니다.
(1분42초 소요)
예시(5개, 출처: SSG.COM)
example = """
'''
이 제품은 가격대비 가성비가 좋고, 토핑도 풍부해서 맛있다는 소비자들의 평이 많아요. 집에서 간편하게 끓여 먹을 수 있어서 편리하고, 양도 푸짐해서 가족 모두에게 적합해요. 다만, 유통기한이 짧아서 버리는 경우가 있었다는 의견도 있어요.
'''
"""
첫번째 프롬프트
f"""
당신은 상품에 대한 고객의 리뷰를 요약해서 소비자에게 정보를 제공하는 소비자 분석가입니다.
**지시사항:**
리뷰:\n
이 리뷰들을 요약해주세요.
많이 나오는 내용을 중심으로 요약해주세요.
요약한 문장을 한 번 더 매끄러운 문장으로 만들어 주세요.
**제한사항:**
브랜드 이름은 넣지 마세요.
중복되는 말과 리뷰, 요약이라는 단어를 삭제해 주세요.
**예시:**
"""
두번째 프롬프트
f"""
당신은 문장을 간결하게 만드는 전문가입니다.
**지시사항:**
다음 문장을 100~150자 사이로 요약해주세요.
말투는 존댓말이어야 합니다.
리뷰, 요약이라는 단어를 삭제해 주세요.:
"""sentiment summary
negative 기름이 많은 도가니탕을 주문했더니 기름이 너무 많아 버렸다고 말했습니다. 기존보다 부속물이 많고 기름이 심해서 놀랐다고 하며, 일부러 뜯어 놔선 것처럼 보였고 고기가 까맣게되어있는 것에 대해 의아함을 표출했습니다. 기름이 물컹거리는 부분은 먹지 않으며 냄새도 심하여 기존 제품과 맛이 달라졌다고 말했습니다.
positive 이 제품은 맛있는 도가니탕 중에서 최고로 평가되는 제품입니다. 도가니와 국물이 맛있으며, 소금으로 간해주면 딱한 맛이 좋습니다. 가격은 비싼 편이지만, 신선한 재료로 만든다는 장점이 있습니다. 또한, 무 항생제로 안전하고, 소금과 첨가물이 들어있지 않아 좋습니다.
- 파라미터 조정 및 감정별 프롬프트를 추가했습니다.
- 다양한 파라미터 조합과 조정을 시도 후에 가장 최적화된 조합을 찾았습니다.
- 감정별 특징이 극대화 되도록 감정별로 프롬프트를 다르게 작성했습니다.
- 프롬프트에 이어서 출력해야 한다는 것을 명확히 하기 위해 “요약:” 지시사항을 추가했습니다.
→ 그 결과, 이전보다 길이와 형식의 일관성이 높아져 최종적으로 이 버전을 선택했습니다.
outputs = model.generate(**tokenizer(inputs,
return_tensors="pt").to(device),
max_new_tokens=200,
pad_token_id=tokenizer.eos_token_id,
top_p=0.90,
temperature=0.2
)예시(5개, 출처: SSG.COM)
example = """
'''
이 제품은 가격대비 가성비가 좋고, 토핑도 풍부해서 맛있다는 소비자들의 평이 많아요. 집에서 간편하게 끓여 먹을 수 있어서 편리하고, 양도 푸짐해서 가족 모두에게 적합해요. 다만, 유통기한이 짧아서 버리는 경우가 있었다는 의견도 있어요.
'''
"""
감정별 프롬프트
if sentiment == 'positive':
sentiment_instructions = "장점과 좋은 점에 집중해서 요약해주세요."
elif sentiment == 'negative':
sentiment_instructions = "불만 사항과 문제점에 집중해서 요약해주세요."
첫번째 프롬프트
f"""
당신은 상품에 대한 고객의 리뷰를 요약해서 소비자에게 정보를 제공하는 소비자 분석가입니다.
**지시사항:**
리뷰:\n
이 리뷰들을
많이 나오는 내용을 중심으로 요약해주세요.
요약한 문장을 한 번 더 매끄러운 문장으로 만들어 주세요.
**제한사항:**
브랜드 이름은 넣지 마세요.
'소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.
**예시:**
**요약:**
"""
두번째 프롬프트
f"""
당신은 문장을 간결하게 만드는 요약 전문가입니다.
**지시사항:**
initial summary :
위 문장을 요약해주세요.
'소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.:
말투는 존댓말이어야 합니다.
**요약:**
"""sentiment summary
negative 이 제품은 가격이 비싼 편이고 기름이 많아 느끼한 맛이 있다는 의견이 많아요. 일부러 내용물이 들어 있는 제품을 구입한 고객분들이 있어요. 도가니보다 부속물이 많고 기름이 심한 제품을 받은 고객분들이 있어요. 일부러 뜯어 놓은 제품을 받은 고객분도 있어요. 기름이 많아 지방을 먹지 않는 고객분들이 있어요. 누린내가 심한 제품을 받은 고객분들이 있어요. 제품의 맛이 갑자기 묽어졌다는 의견도 있어요.
positive 이 제품은 가격 대비 가성비가 좋고, 도가니가 풍부해서 맛있다는 평이 많아요. 편리하고 양도 푸짐해서 가족 모두에게 적합합니다. 도가니탕 중에서 국물이 진하고 맛있다는 의견이 많아요.
위의 방법들을 바탕으로 카테고리별 요약 생성 시, 카테고리에 따른 프롬프트를 다르게 작성하는 등의 방법으로 고도화했습니다.
카테고리별 프롬프트
category_instructions = {
'가격': "가격에 대한 구체적인 장점과 단점을 간결하게 요약해 주세요. 가격 대비 품질, 비슷한 제품과의 비교 등을 포함하세요.",
'맛/향/풍미': "맛과 향에 대한 장점과 단점을 간결하고 명확하게 요약해 주세요. 맛의 특징과 문제점을 자연스럽게 설명하세요.",
'양': "제공된 양에 대한 장단점을 간결한 문장으로 요약해 주세요. 양에 대한 만족도나 불만을 구체적으로 설명하세요.",
'포장/배송': "포장 상태와 배송 과정에 대한 고객의 경험을 간결하게 요약해 주세요. 문제가 있었던 경우 그 이유도 설명해 주세요.",
'보관': "제품의 보관 방법에 대한 고객의 의견을 요약해 주세요. 보관 방법의 장단점과 주의 사항을 간단하게 설명해 주세요."
}
첫번째 프롬프트
f"""
당신은 상품에 대한 고객의 리뷰를 간결하고 자연스럽게 요약하는 전문가입니다.
**지시사항:**
리뷰:
- 리뷰를 읽고, 각 리뷰의 핵심 내용만 간결하게 요약하세요.
- 리뷰를 읽고, 문맥을 고려하여 요약하세요.
- 사용자의 실제 경험을 반영하여 자연스러운 문장으로 작성하세요.
- 동일한 내용이 반복되지 않도록 중복된 정보는 하나의 문장으로 통합하세요.
- 각 카테고리와 관련된 정보만 포함하고, 필요 없는 정보는 생략하세요.
- 읽는 사람이 바로 이해할 수 있도록 단순하고 직관적인 문장을 사용하세요.
- '소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.
**카테고리별 요약 지침:**
-
**제한사항:**
- 브랜드 이름은 언급하지 마세요.
- '소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.
- 요약을 할 때 복잡한 문장보다는 자연스럽고 간결한 문장을 사용하세요.
"""
두번째 프롬프트
f"""
당신은 문장을 간결하게 만드는 요약 전문가입니다.
**지시사항:**
initial summary:
위 내용을 명확하고 간결하게 1-2문장으로 요약해 주세요.
'소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.
일관된 문장 형식을 유지해주세요.
존댓말로 자연스럽게 작성해 주세요.
**요약:**
"""product_type category summary
맑은 순대국 가격 이 제품은 칼로리가 낮고 가격이 저렴합니다.
맛/향/풍미 순대 국물이 깔끔하고 맛있으며, 담백한 맛과 적당한 향이 특징입니다.
보관 이 제품은 가성비가 뛰어나고, 냉동 후에도 유지하기 좋습니다.
양 1인분은 양이 적지만 2인분으로 충분히 먹을 수 있는 양입니다.
포장/배송 제품은 깔끔하게 패킹되어 배송이 빠르며, 급할 때 주문하기 적합합니다. 제품은 주문 후 다음날 도착하여 냉동 상태로 잘 도착했습니다.
- 활용 방법(레시피) 프롬프트 작성과정 : GPT-4o-mini 모델 사용
활용 방법(레시피)의 경우도 마찬가지로 예시(few-shot)을 활용하여 프롬프트를 작성했습니다. 최종적으로 작성한 프롬프트와 예시(few-shot), 출력 결과는 다음과 같습니다.
프롬프트
f"""
지시사항:
아래 주어진 '문제'는 특정 상품의 리뷰에서 소비자들이 제시한 상품의 활용 방법에 대해서만 추출한 내용입니다.
새로운 소비자 이 상품을 어떻게 사용하면 좋을지 예시와 같이 적절히 요약해주세요.
예시:
"라면사리, 각종 야채를 추가하여 부대찌개로 먹으면 맛있습니다.
냄비에 한 번에 넣고 끓이면 돼서 간편합니다. 어른들 해장용으로도 좋고, 아이들 입맛에도 잘 맞습니다."
"송이버섯, 애호박, 대파 등 집에 있는 야채를 듬뿍 넣어 만둣국으로 끓여 먹기 좋습니다.
다 먹고 남은 국물에 칼국수면을 넣어서 끓여 드세요. 추운 겨울에 몸보신하기 딱입니다."
"전자레인지에 돌리기만 하면 손쉽게 든든한 한 끼를 먹을 수 있습니다.
자취생들이 간편하게 먹을 수 있습니다. 김치랑 같이 먹으면 잘 어울립니다."
제한사항:
브랜드 이름은 넣지 마세요.
'소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.
"""product_type summary
돼지고기 김치찌개 참치 캔을 기름기 빼고 넣어 아이들과 함께 즐기기 좋습니다. 두부와 찌개 채소를 추가해 끓이면 든든한 한 끼가 됩니다. 물을 조금 더 넣고 마늘을 듬뿍 넣어 끓이면 더욱 맛있습니다. 갓 지은 밥과 함께 먹으면 최고의 조합입니다. 자취생들에게도 간편하고 맛있는 선택이 될 것입니다.
실험 과정
- 처음에는 GPT가 아닌 Llama로 시도했습니다.
예시로 출력 템플릿을 만들어 제공했으나 일관성이 떨어지고 성능이 잘 나오지 않았습니다.
예시(4개, 직접 작성)
example_recipe = """
'''
이렇게 활용하면 좋아요 : 만둣국, 갈비탕
추가하면 좋아요 : 물, 대파, 기름 적은 소고기, 밥
조리 방법 : 물을 먼저 넣고 팔팔 끓이다가 소고기를 넣어주세요. 마지막에 밥을 말아 드세요.
편리함 : 냄비에 한 번에 넣고 끓이면 끝
'''
"""
다음 프롬프트는 위의 감정별 요약 프롬프트와 동일하게 작성- 다음은 GPT로 시도해보았습니다.
GPT로도 출력 형식이 일관적이지 않아 일반적인 줄글로 출력하도록 변경했고, 감정별/카테고리별 요약처럼 2단계로 하지 않아도 성능이 일관적이라 1단계만 사용했습니다.
프롬프트
f"""
지시사항:
아래 주어진 '문제'는 특정 상품의 리뷰에서 소비자들이 제시한 상품의 활용 방법에 대해서만 추출한 내용입니다.
새로운 소비자 이 상품을 어떻게 사용하면 좋을지 예시와 같이 적절히 요약해주세요.
예시:
"라면사리, 각종 야채를 추가하여 부대찌개로 먹으면 맛있습니다.
냄비에 한 번에 넣고 끓이면 돼서 간편합니다. 어른들 해장용으로도 좋고, 아이들 입맛에도 잘 맞습니다."
"송이버섯, 애호박, 대파 등 집에 있는 야채를 듬뿍 넣어 만둣국으로 끓여 먹기 좋습니다.
다 먹고 남은 국물에 칼국수면을 넣어서 끓여 드세요. 추운 겨울에 몸보신하기 딱입니다."
"전자레인지에 돌리기만 하면 손쉽게 든든한 한 끼를 먹을 수 있습니다.
자취생들이 간편하게 먹을 수 있습니다. 김치랑 같이 먹으면 잘 어울립니다."
제한사항:
브랜드 이름은 넣지 마세요.
'소비자', '리뷰', '요약'이라는 단어는 사용하지 마세요.
"""product_type summary
돼지고기 김치찌개 참치 캔을 기름기 빼고 넣어 아이들과 함께 즐기기 좋습니다. 두부와 찌개 채소를 추가해 끓이면 든든한 한 끼가 됩니다. 물을 조금 더 넣고 마늘을 듬뿍 넣어 끓이면 더욱 맛있습니다. 갓 지은 밥과 함께 먹으면 최고의 조합입니다. 자취생들에게도 간편하고 맛있는 선택이 될 것입니다.
5. 결과
5-1. 서비스 프로토타입
최종 요약 결과를 마켓컬리 사용자가 확인할 수 있도록 아래와 같이 웹페이지로 구현했습니다. 웹페이지 구현에는 Streamlit을 활용했습니다.
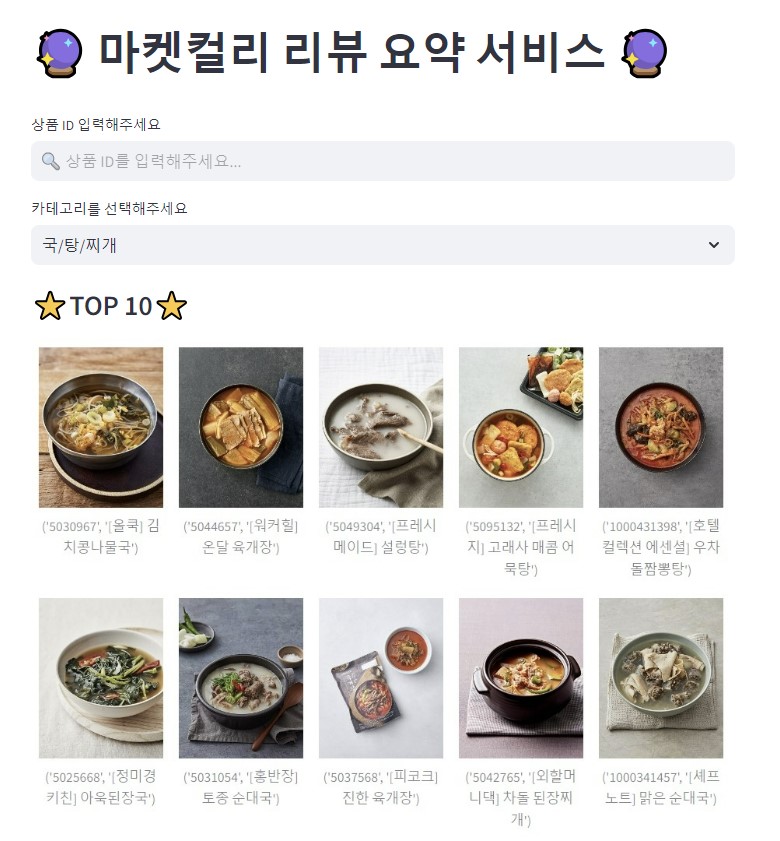
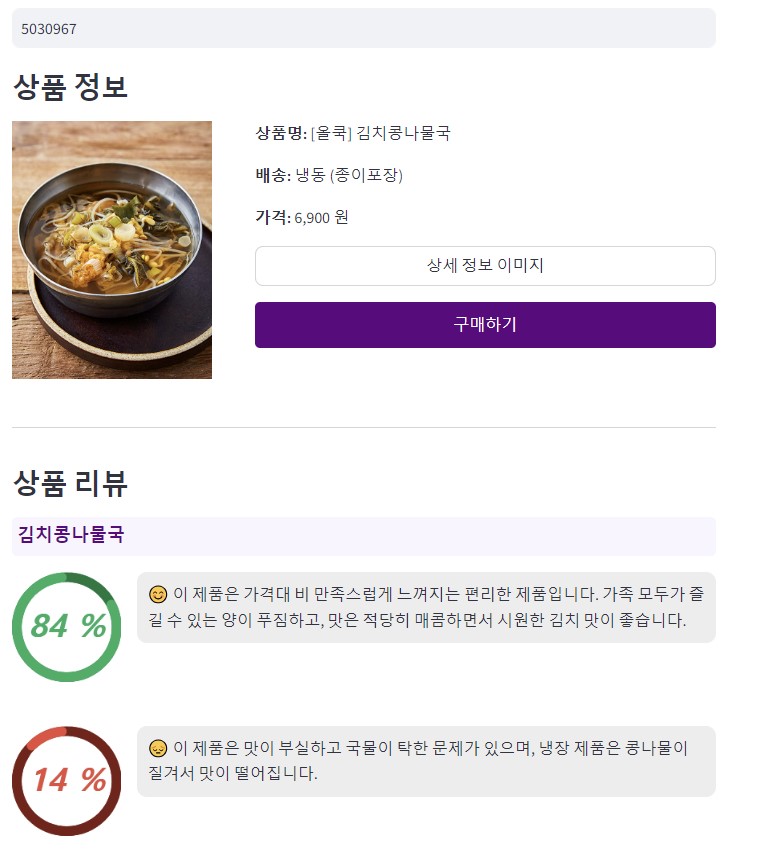
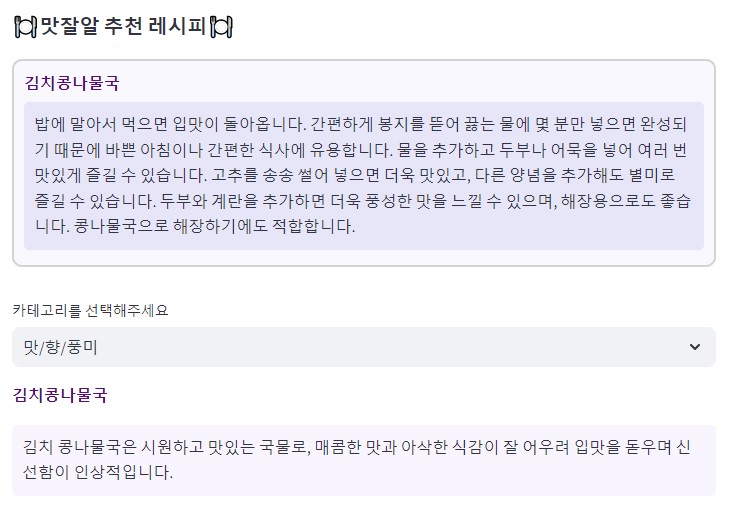
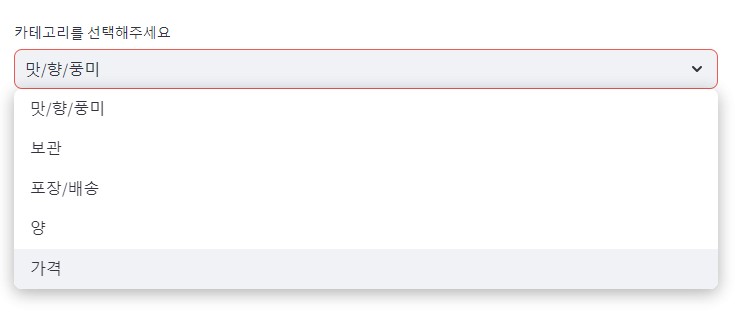
6. 결론
6-1. 네이버, SSG 서비스 비교 분석 및 본 서비스의 차별점
- 네이버
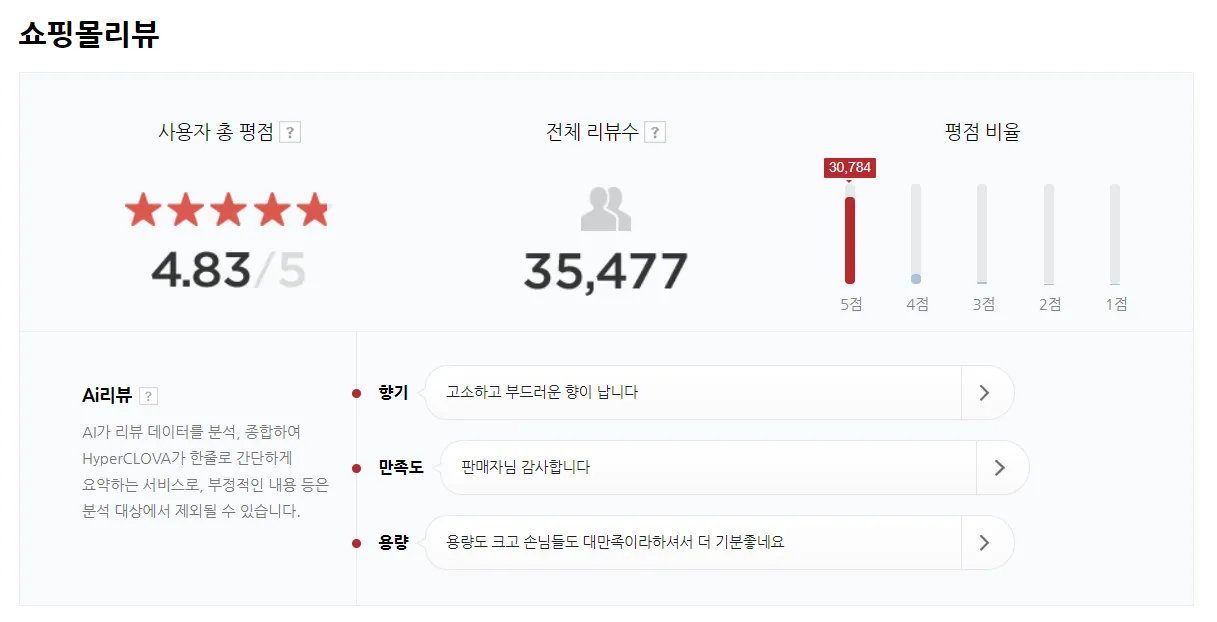
네이버는 HyperCLOVA 모델을 활용한 리뷰 요약을 제공하며, 만족도/품질/신선도/맛/가격 등 상품 속성에 따라 관련된 정보를 포함하는 리뷰만 선택적으로 볼 수 있습니다. 또한 속성 선택 시, 해당하는 부분이 하이라이트 되어 나타나는 기능을 제공합니다. 요약 생성은 리뷰 주요 키워드 분석 → 속성별 분류 → 너무 짧거나 무의미한 단어 반복 등을 필터링 → 유사 내용 리뷰 클러스터링 → HyperCLOVA로 요약문 생성 → ‘AI클린봇’ 등의 자동화 모듈로 비속어 검수 및 문장 교정 의 순서로 진행됩니다.
- SSG
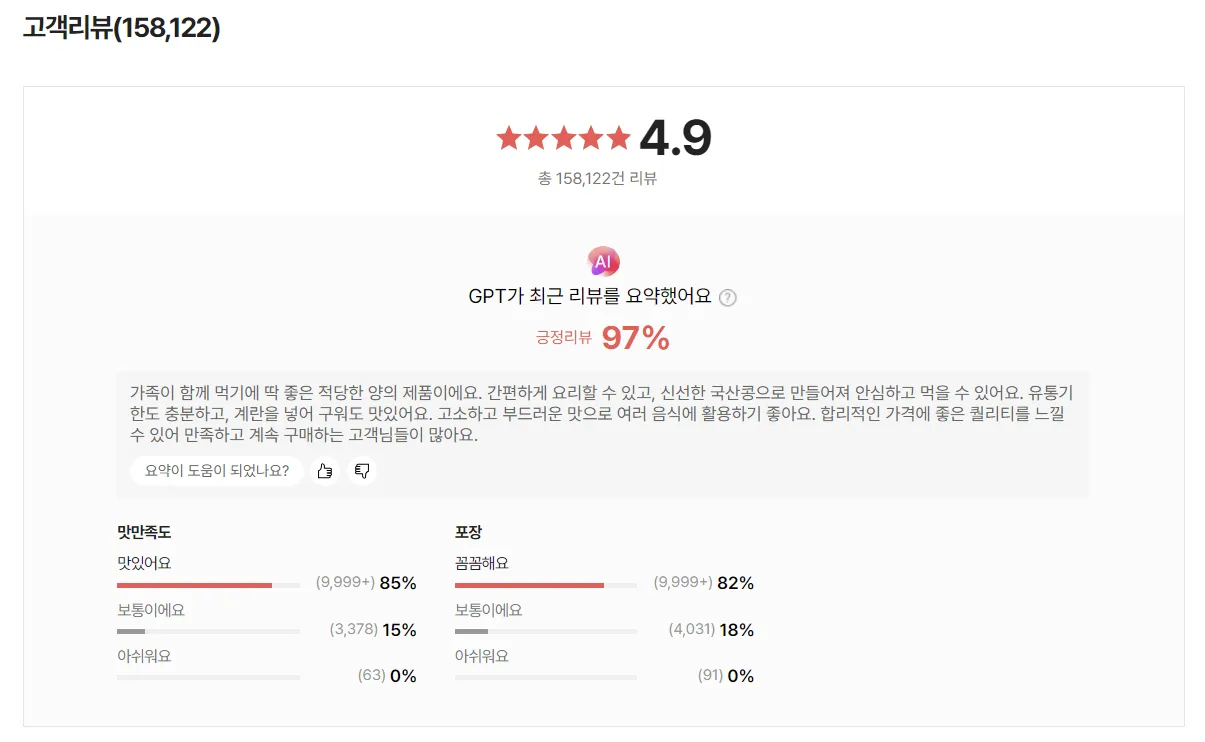
SSG는 GPT 모델을 활용한 리뷰 요약을 제공하며, 판매량과 누적 리뷰 수가 많은 식품 상품군에 우선적용하고 있습니다. 네이버와 같이 속성과 관련된 정보를 포함하는 리뷰를 필터링으로 보여주며, 해당 부분이 하이라이트 되어 나타납니다. 속성별 요약만 제공하는 네이버와 달리, SSG에서는 전체 리뷰에 대한 요약과 속성별 평점도 제공하고 있으며, 요약문의 길이가 비교적 긴 것도 특징입니다. 요약 생성은 리뷰 주요 키워드 분석 → 속성별 분류, 주요 표현 추출 → GPT로 요약문 생성 등 의 순서로 진행됩니다. 이때 자체 개발한 ‘NER(Named Entity Recognition) 기반 속성 분류’와 ‘토픽 모델링’을 추가로 적용해 구체적인 표현 중심의 요약문을 생성하고자 시도하고 있습니다.
- ‘마켓컬리 리뷰 요약 서비스’의 차별점 및 의의
- 리뷰 평점을 제공하지 않는 마켓컬리에서 긍부정별 리뷰 요약문, 긍부정 비율 등 리뷰를 한번에 파악할 수 있도록 기능을 개선했다는 점
- 마켓컬리 리뷰의 특성인 레시피나 활용 방법에 대한 요약을 별도로 제공해준다는 점
- LLM 오픈소스 모델과 프롬프트 엔지니어링만을 활용해 적은 비용으로도 SSG 및 네이버와 비슷한 서비스를 구축했다는 점 (네이버, SSG에서 서비스를 구현하는 방식과 비슷하게 키워드 추출, 리뷰 부분별 태깅, 요약 생성, 요약 내용 정교화의 과정을 거쳤습니다.)
6-2. 한계점, 아쉬운 점
- GPU 용량 부족으로 한 번에 처리할 수 있는 데이터의 양에 한계가 있어 상품 당 50개라는 적은 수의 리뷰만을 선택했다는 점
- 이로 인해 카테고리별 요약 성능이 리뷰 수가 적어서 잘 나오지 않는 문제가 있었습니다.
- 기존 기획에서는 카테고리 안에서도 감정별 요약을 제공하려고 했으나, 리뷰 수의 부족으로 불가능해졌습니다.
→ 데이터가 충분히 확보되고 처리할 수 있는 용량이 있다면, 카테고리 안에서도 감정별 요약이 가능하여 상품별 특징을 레이더 차트로 시각화까지 가능해질 것으로 예상합니다.
- Llama 모델을 사용하면서 모델 자체의 성능에서 아쉬운 점
- 같은 태스크도 GPT를 이용하면 성능이 더 좋게 나왔지만, 비용 문제로 인해 Llama를 조정해서 사용하는 경우가 많았습니다.
- Llama가 발생시키는 특징적인 오류로는 프롬프트의 예제 출력, 사전에 없는 단어를 출력, 문맥에 어긋난 표현 등을 출력하는 경우가 있었습니다.
→ 시간이 더 주어졌다면 모델 자체를 더 fine-tuning하거나 정교한 프롬프트 엔지니어링, 파라미터 조정을 통해서 해결했을 수 있었을 것이라 생각했습니다. 또한 작업 효율성을 고려할 때 GPT 모델을 사용하는 것도 좋은 방법이 될 수 있습니다.
- 레시피(활용 방법)을 추출하는 모델을 따로 구현하지 못한 점
- BERT를 이용하여 레시피(활용 방법)만을 추출하는 모델을 구현하려고 했으나, 모델 학습이 제대로 이루어지지 않았습니다.
- 또한 하나의 리뷰에서 레시피가 여러 부분에 등장하는 경우도 많아, 여러 부분을 한 번에 추출하는 모델을 찾는 것에도 어려움이 있었습니다.
→ 레시피나 활용 방법을 태깅하는 별도의 모델을 구현할 수 있다면, 더 정교한 서비스를 설계할 수 있었을 것으로 기대합니다.
- 요약 결과 평가가 human evaluation에만 의존한 점
6-3. 서비스 발전 방향
현재 서비스는 ‘국·탕·찌개’ 카테고리에 한정되어 있지만, 유사한 과정 다른 카테고리에도 확장할 수 있을 것으로 기대됩니다. 또한 본 프로젝트와 같이 크롤링을 이용해 정보를 수집하는 것이 아닌 기업의 자체 DB를 활용하여 더 빠른 시간 안에 서비스를 구현할 수 있을 것입니다. 사용자의 ‘도움돼요’ 클릭 내역 정보를 결합한다면, 이전에 사용자가 도움이 된다고 생각했던 리뷰들의 특성을 파악하여 유사한 리뷰들을 우선적으로 표출하거나 요약하는 서비스로 확장할 가능성도 고려할 수 있습니다.
참고자료
https://www.4th.kr/news/articleView.html?idxno=2061539 https://news.mt.co.kr/mtview.php?no=2021073008512733637 http://lb-openads-center-1527185881.ap-northeast-2.elb.amazonaws.com/content/contentDetail?contsId=10792 클로드 프롬프트 엔지니어링 가이드 북