
1. Background
CLIP: 이미지와 텍스트의 연결을 학습하는 모델
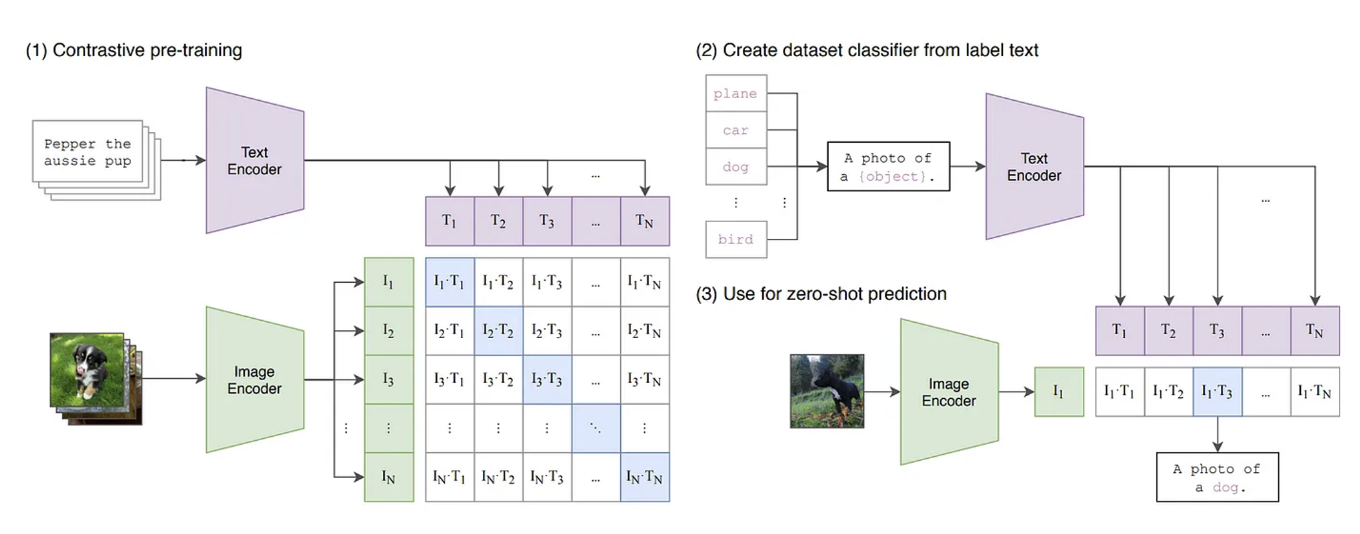
CLIP (Contrastive Language-Image Pretraining)은 이미지와 텍스트를 함께 학습시켜 두 가지를 연결하는 능력을 가진 모델입니다. 이 모델의 핵심 아이디어는 이미지와 텍스트 간의 대조 학습(Contrastive Learning)을 이용하는 것입니다. CLIP은 두 가지 인코더를 사용합니다. 이미지를 처리하는 이미지 인코더로는 Vision Transformer (ViT)을 사용하고, 텍스트를 처리하는 텍스트 인코더로는 Transformer 모델을 사용합니다.
대조 학습 (Contrastive Learning)
대조 학습은 이미지와 텍스트 쌍을 학습하는 과정에서, 같은 쌍의 경우 벡터 간의 거리를 가깝게 하고, 다른 쌍의 경우 거리를 멀게 만드는 방식입니다. 이때, 이미지와 텍스트 쌍의 벡터 간의 유사도를 측정하는 지표로 코사인 유사도(Cosine Similarity)를 사용합니다.
참고: 코사인 유사도는 두 벡터 간의 각도를 이용해 유사성을 측정하는 방법입니다. 1에 가까울수록 두 벡터의 방향이 유사하고, -1에 가까울수록 방향이 다릅니다.
이러한 방법으로 CLIP은 이미지와 텍스트 간의 관계를 학습합니다. 이 과정에서 두 인코더는 처음부터 함께 학습되며, 이를 통해 이미지와 텍스트를 효과적으로 연결하는 능력을 갖추게 됩니다.
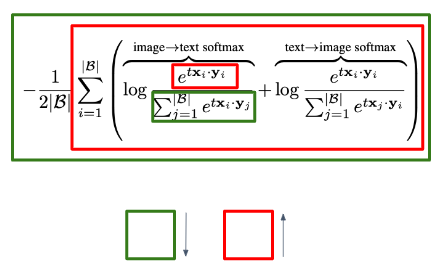
위의 수식과 같이 CLIP은 큰 배치사이즈를 가지면서 Positive Pair의 유사도는 커지고 Negative Pair의 유사도는 작아지도록 학습합니다. CLIP은 대조 학습을 통해 관련 있는 이미지와 텍스트를 같은 벡터 공간에 가깝게 배치합니다. 이를 통해 이미지를 텍스트 설명과 연결하여 이해합니다. 이 방식은 학습되지 않은 데이터라도 Zero-Shot 분류에서 뛰어난 성능을 보이는 것이 특징입니다.

하지만 기존 데이터셋은 하나의 이미지에 하나의 텍스트 쌍만 포함하고 있기 때문에 이미지의 다양한 측면을 표현하거나 복잡한 표현을 학습하는 데 한계가 있습니다. 모델이 이미지와 텍스트 간의 복잡한 관계를 충분히 학습하지 못하게 하며, 결과적으로 모델의 성능 저하로 이어질 수 있습니다. 해당 문제를 해결하기 위해, CVPR 2024에서 발표된 MobileCLIP 연구에서는 혁신적인 접근 방식을 제안했습니다. MobileCLIP은 한 이미지에 대해 단일 캡션이 아닌 다수의 합성 캡션을 생성하여 각기 다른 텍스트 표현을 학습할 수 있도록 시도했습니다.
MobileCLIP: 모바일 환경을 위한 경량 멀티모달 모델
CLIP을 모바일 환경에 최적화한 모델입니다. 하나의 이미지당 여러개의 합성 캡션 데이터를 사용하고, distillation을 통해 경령화된 모델에서도 좋은 성능을 보여주도록 학습하는 것이 특징입니다.
1. 강화된 데이터셋과 멀티모달 변형
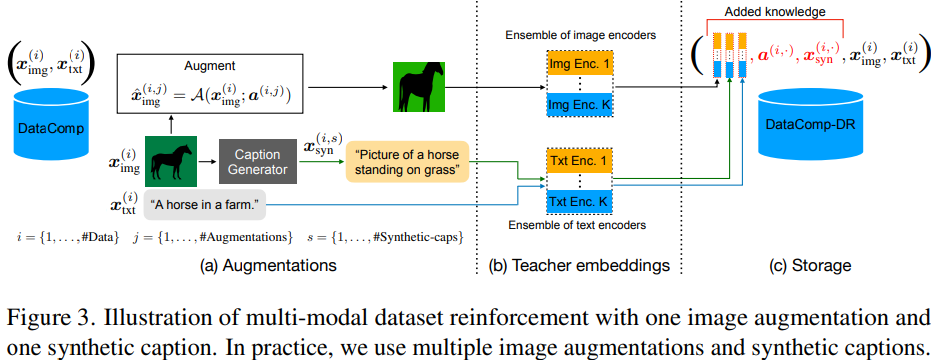
MobileCLIP에서는 CLIP 모델의 성능을 유지하면서 경량화를 위해 데이터셋을 강화했습니다. 이를 위해 CLIP의 이미지-텍스트 데이터셋에 Coca 모델을 활용해 이미지마다 여러 개의 synthetic captions을 생성했습니다. 이로 인해 시각적 설명이 향상됐으며, Real captions과 Synthetic captions을 모두 사용해 제로샷 검색과 분류 성능을 개선했습니다. 또한, 각 이미지에 대해 다양한 증강 이미지를 생성하고, 멀티모달 모델 앙상블을 통해 다양한 피처 임베딩을 얻어냈습니다. 이러한 강화된 데이터셋(DataCompDR-12M)은 증강된 이미지, synthetic captions, CLIP teacher의 피처 임베딩을 원본 이미지와 실제 캡션과 결합해 구성됐습니다.
2. 경량화를 위한 Distillation 기법
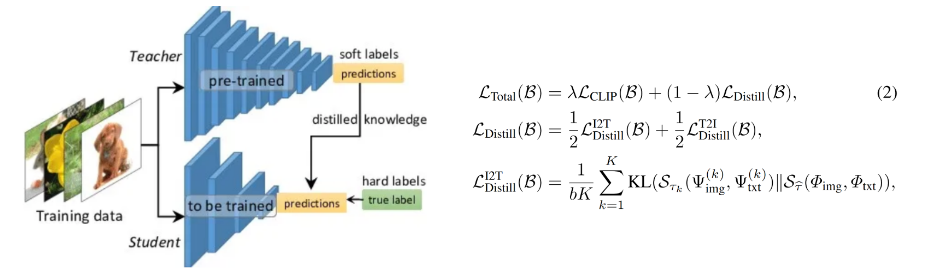
MobileCLIP은 지식 증류(distillation) 기법을 통해 경량화된 모델에서도 높은 성능을 유지할 수 있습니다. Distillation은 큰 모델(teacher)에서 얻은 지식을 자식 모델(student)에 전이시켜, 작은 모델이 teacher 모델과 유사한 성능을 발휘할 수 있도록 하는 학습 방법입니다. MobileCLIP에서는 distillation을 통해 CLIP의 강력한 성능을 유지하면서도 모델의 복잡도와 크기를 줄이는 데 성공했습니다.
1) Teacher 모델 선택 기존 CLIP 모델이 Teacher 역할을 수행합니다. 이 모델은 많은 파라미터와 고성능을 바탕으로 다양한 멀티모달 데이터를 학습할 수 있는 충분한 용량을 가지고 있습니다. 2) 학생 모델(Student) 학습 MobileCLIP의 경량화된 아키텍처는 학생 모델로 사용되며, Teacher 모델이 학습한 이미지-텍스트 관계를 최대한 효율적으로 학습합니다. 이를 위해 Teacher 모델의 출력(임베딩)과 학생 모델의 출력을 비교하며, 이 차이를 최소화하는 방향으로 학습이 진행됩니다. 여기서 사용되는 손실 함수는 일반적으로 Kullback-Leibler Divergence(KL 발산)으로, 두 모델 간의 출력 분포를 정렬하는 데 사용됩니다.
3. 경량화된 모델 아키텍처
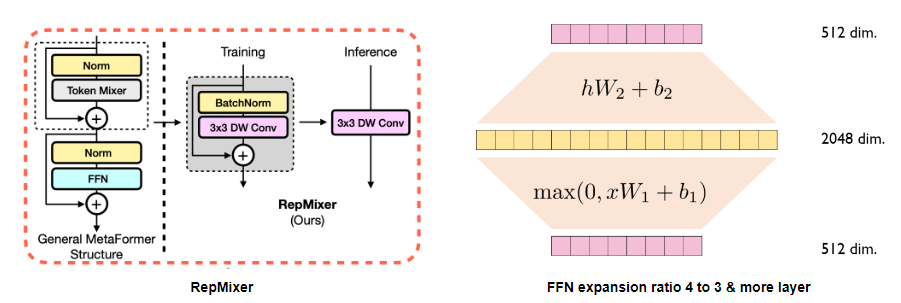
1) 텍스트 인코더 기존 CLIP의 텍스트 인코더는 비전 트랜스포머와 self-attention 레이어로 구성돼 있었으나, 모바일 환경에 적합한 Text-Repmixer로 대체됐습니다. Text-Repmixer는 적은 레이어와 파라미터로도 큰 텍스트 인코더와 유사한 성능을 제공하며, 하이브리드 텍스트 인코더로서 효율성을 높였습니다.
2) 이미지 인코더 이미지 인코더는 CLIP의 ResNet 또는 Vision Transformer 대신, MCi라는 경량화된 하이브리드 비전 트랜스포머를 사용합니다. FastViT 아키텍처를 기반으로 한 MCi는 MLP 확장 비율을 조정해 용량을 줄이고, 레이턴시에는 큰 영향을 주지 않으면서도 성능을 유지합니다. FastViT보다 더 나은 제로샷 성능을 보였으며, 모바일 환경에서 더 적합한 이미지 인코더로 자리 잡았습니다.
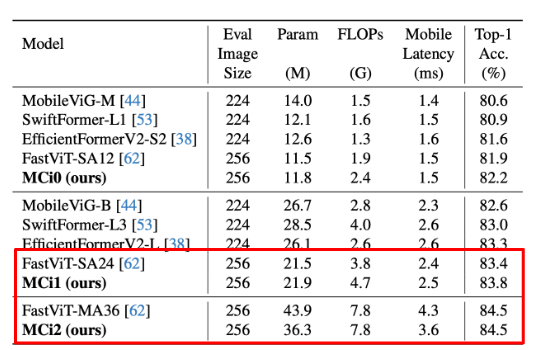
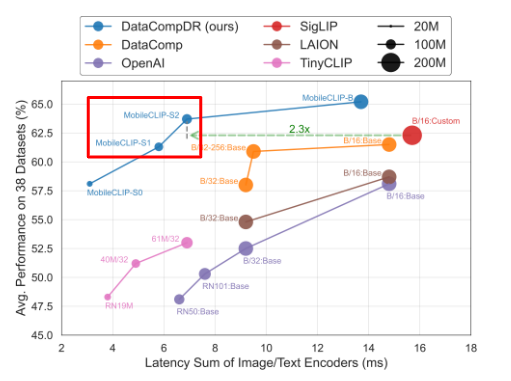
MobileCLIP은 기존 CLIP의 성능을 유지하면서도 모바일 환경에 적합한 경량 모델로 변모하게 됩니다. 결과적으로, 작은 파라미터 수와 낮은 연산량에도 불구하고 멀티모달 작업에서 우수한 성능을 발휘합니다. MobileCLIP 연구는 대규모 CLIP 모델을 경량화하여 빠른 추론 속도를 유지하면서도 우수한 성능을 달성하는 데 중점을 두었습니다. 이 연구를 바탕으로 두 가지 중요한 의문점이 제기됩니다.
2. Our Approach
MobileCLIP보다 빠르고 좋은 성능을 보여주는 모델 만들기
Mamba
Mamba 아키텍처는 이러한 문제를 해결할 수 있는 가능성을 제공합니다. Mamba는 재귀적인 특징을 가진 SSM(Structured State Space Model)을 활용해 Self-Attention 없이도 높은 성능을 유지하면서 더 빠른 연산을 가능하게 합니다. 특히, Mamba2(ICML 2024) 아키텍처는 SSM을 행렬 연산으로 변환해 GPU 최적화와 병렬 처리 효율성을 극대화했습니다. 이를 MobileCLIP에 적용하면, Self-Attention의 복잡성을 피하면서도 성능을 유지하거나 향상시킬 수 있습니다. Mamba는 RNN(Recurrent Neural Network)처럼 hidden state에 정보를 압축해 순차적으로 전달하는 구조를 가지고 있습니다. 이는 시계열 데이터나 긴 시퀀스 데이터 처리에 매우 유리하며, 특히 메모리 사용이 선형적으로 증가하기 때문에 큰 해상도의 이미지나 긴 시퀀스 데이터도 효율적으로 처리할 수 있습니다. 또한, 이러한 재귀적인 구조 덕분에 모델은 더 적은 메모리와 연산량으로도 높은 성능을 발휘할 수 있습니다.
이러한 Mamba의 특성은 MobileCLIP과 같은 경량화된 모델 아키텍처에 적용될 경우 매우 유용할 수 있습니다. Self-Attention의 복잡성과 메모리 소모 문제를 해결하면서도 높은 성능을 유지하거나 향상시킬 수 있기 때문입니다. MobileCLIP의 경우, 이미지당 여러 개의 synthetic captions을 생성하고 멀티모달 데이터를 학습하는 과정에서 발생하는 연산량을 줄이면서도 정확도를 유지해야 하는데, Mamba 아키텍처를 도입하면 이러한 연산 효율성과 메모리 관리 문제를 극복할 수 있습니다.
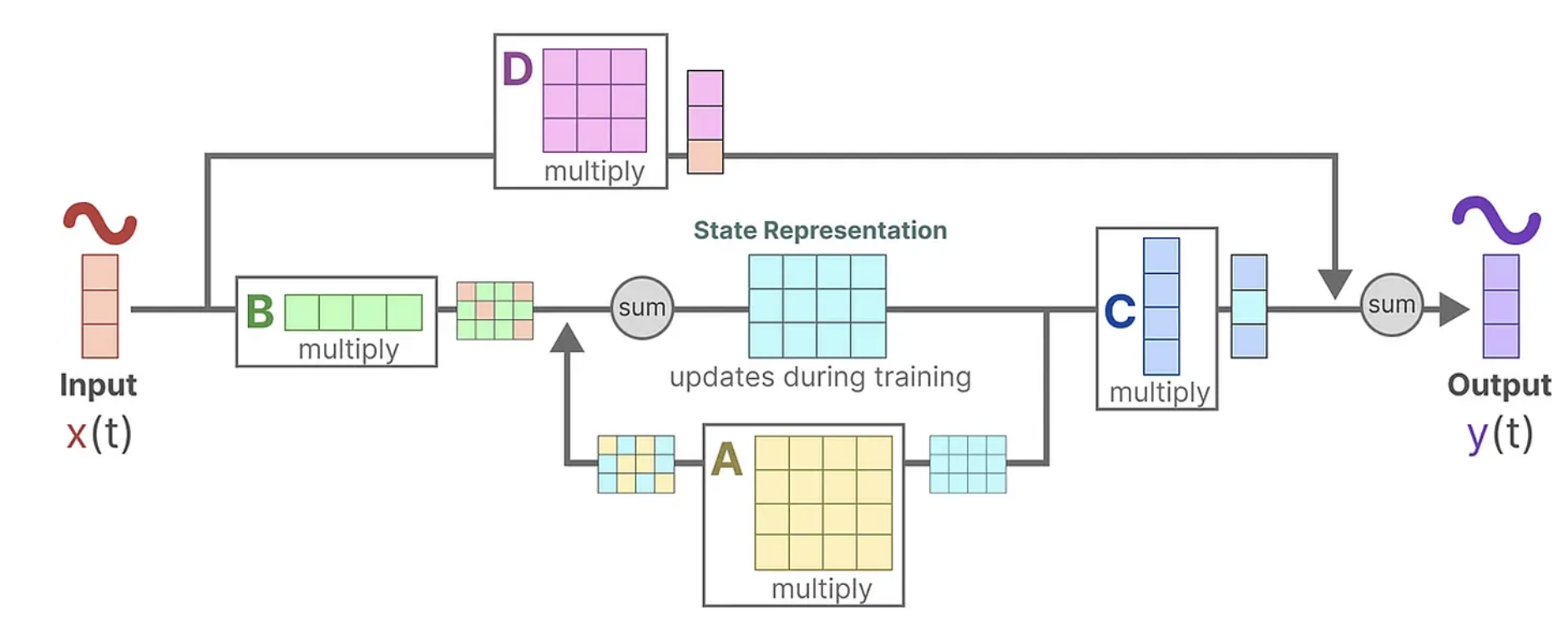
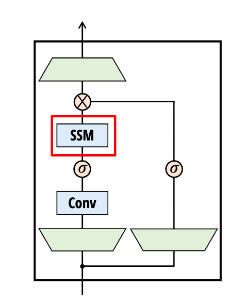
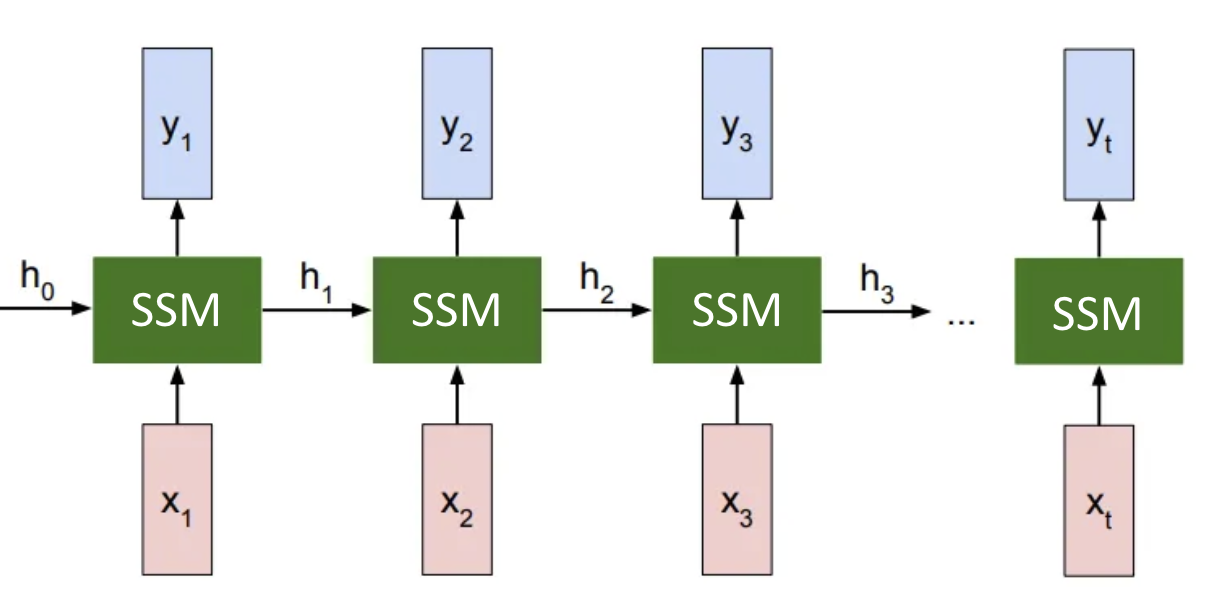
Vision Mamba
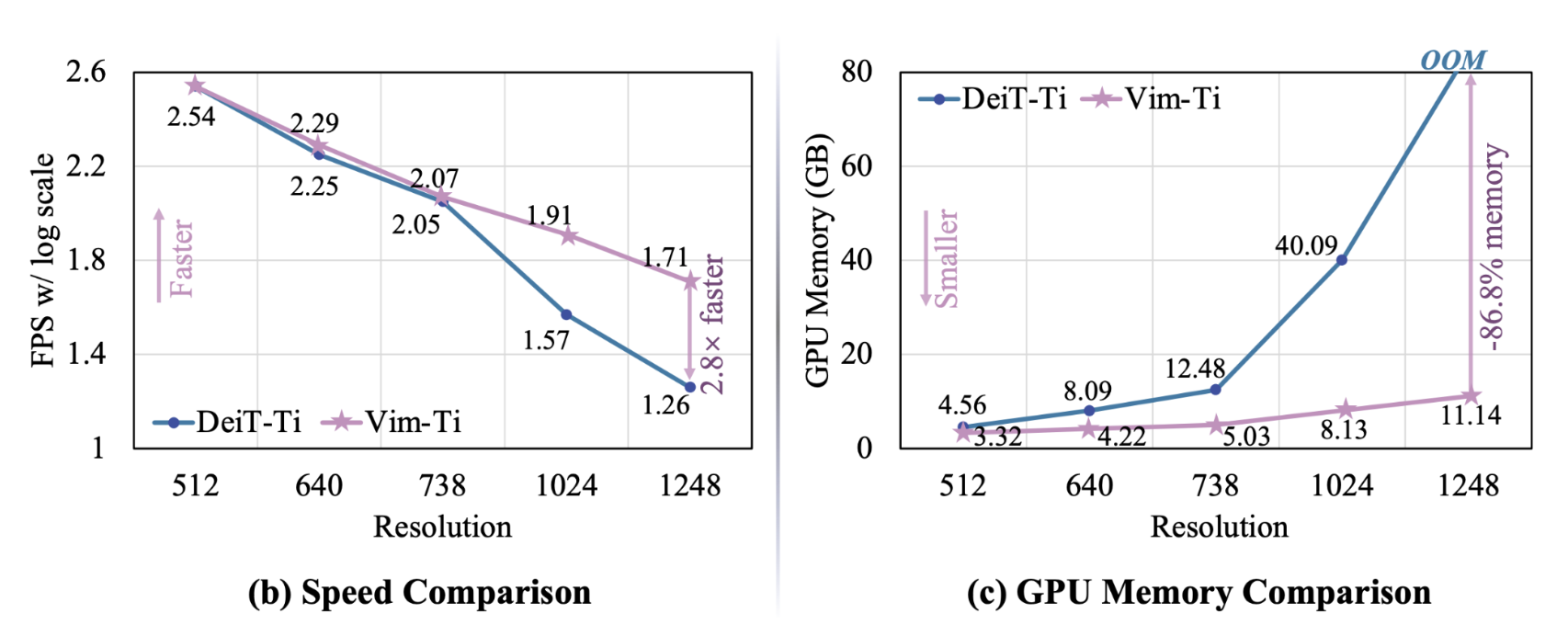
고해상도 이미지는 시퀀스 길이가 매우 길어질 수밖에 없는데, Vision Mamba는 이러한 이미지들을 효율적으로 처리할 수 있습니다. 이는 특히 고해상도 이미지 분류, 물체 인식, 세그멘테이션 등의 작업에서 중요한 이점을 제공합니다. 고해상도 이미지는 더 많은 픽셀 정보를 포함하고 있기 때문에, 이 정보를 효과적으로 처리할 수 있는 메모리 관리가 필수적입니다. Vision Mamba는 이러한 작업을 원활하게 처리할 수 있도록 최적화된 구조를 제공하며, 더 적은 메모리로도 고해상도 이미지를 효율적으로 처리할 수 있게 합니다.
Vision Transformer(ViT)
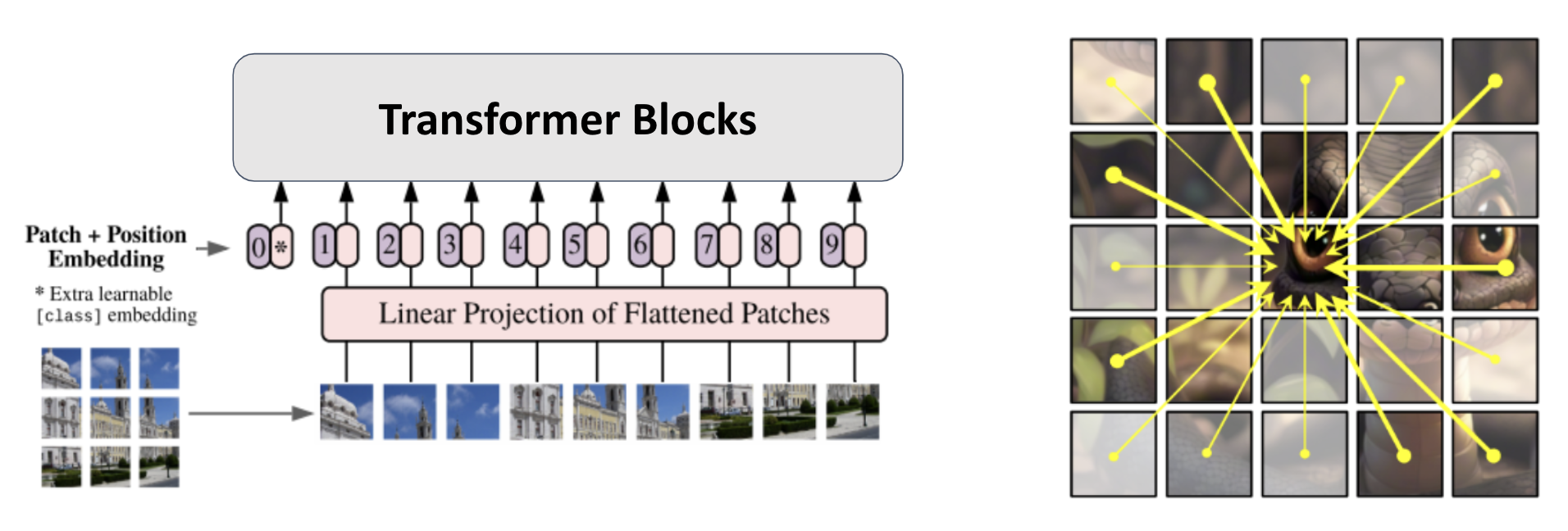
Transformer를 Vision 작업에 적용하려면, 먼저 이미지를 패치 단위로 분할한 뒤, 이를 시퀀스 형태로 변환하여 연산을 진행합니다. 각 Transformer 블록을 통과할 때마다 모든 패치 간의 유사도를 계산하고, 그 결과로 패치들 간의 관계 정보를 결합합니다. 이러한 방식은 높은 성능을 제공하지만, 이미지의 해상도가 높아지거나 패치 수가 증가하면 연산량이 기하급수적으로 늘어나는 문제가 발생할 수 있습니다.
Mamba to Vision
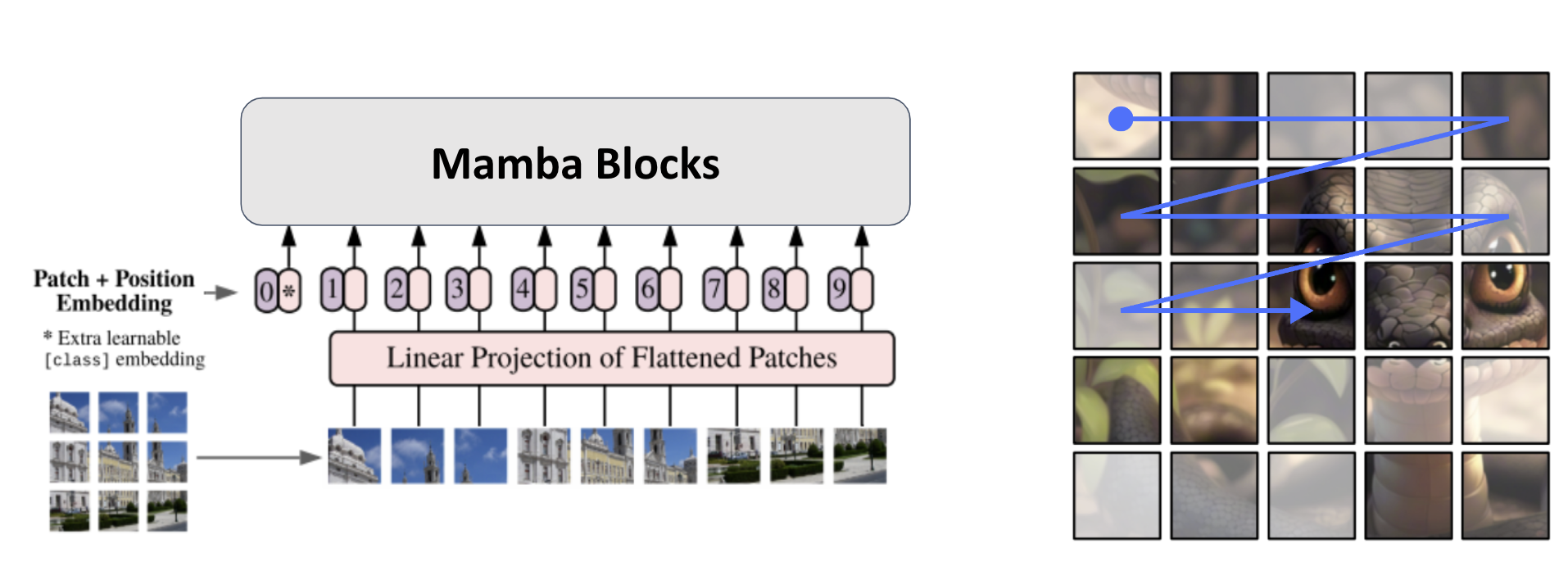
Mamba 블록은 오른쪽 그림과 같이 순차적으로 패치 간 정보를 교환하는 방식으로, 매우 빠르게 연산할 수 있습니다. 그러나 이 방식은 정보가 고르게 전달되지 않을 가능성이 있어, Transformer 기반 모델에 비해 성능이 부족할 수 있는 단점이 존재합니다.
MambaVision
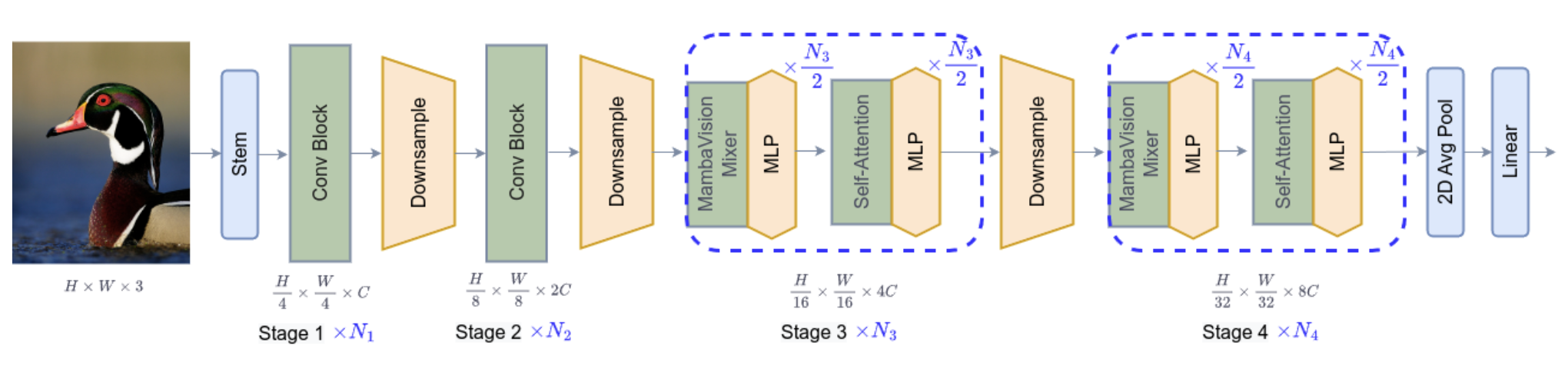
MambaVision 아키텍처에서는 Stage 1과 Stage 2에서 Convolution 연산을 통해 저수준 특징을 추출합니다. Convolution 연산은 이러한 로컬 정보를 효율적으로 추출하는 데 적합합니다. 그다음 Stage 3와 Stage 4에서는 Mamba 블록과 Transformer 블록이 결합되어 고수준 특징을 추출합니다. Mamba 블록은 순차적으로 패치 간 정보를 교환하여 빠르고 효율적인 연산을 가능하게 합니다. 이를 통해 연산량을 줄이면서도 시퀀스 간의 관계를 학습할 수 있습니다.
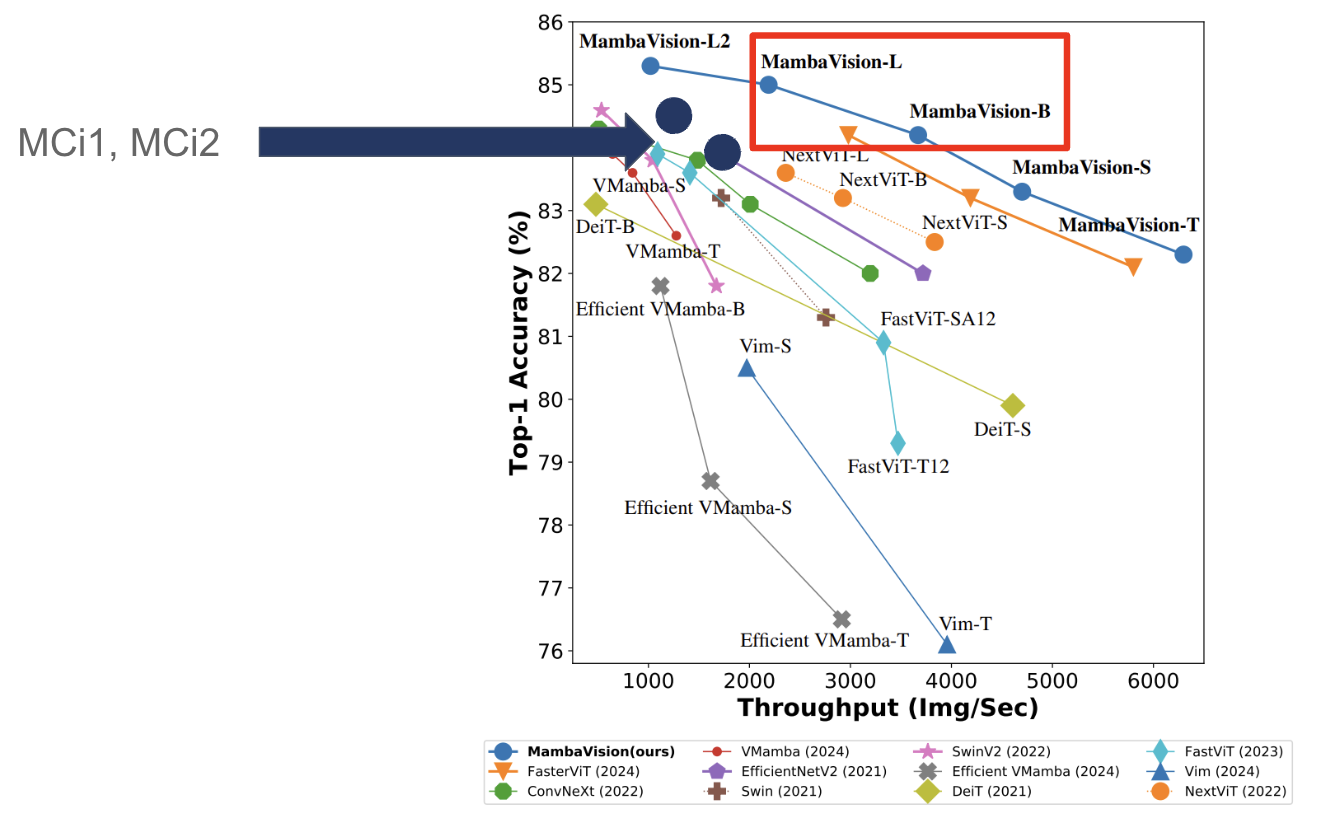
Mamba를 활용한 이 아키텍처는 매우 빠른 연산 속도를 제공하면서도, 일부 Transformer 연산을 통해 우수한 성능을 보여주는 것이 특징입니다. 이는 MobileCLIP의 경량화된 이미지 인코더와 비교해도 월등히 빠른 속도와 뛰어난 성능을 동시에 제공합니다.
CLIP-Mamba
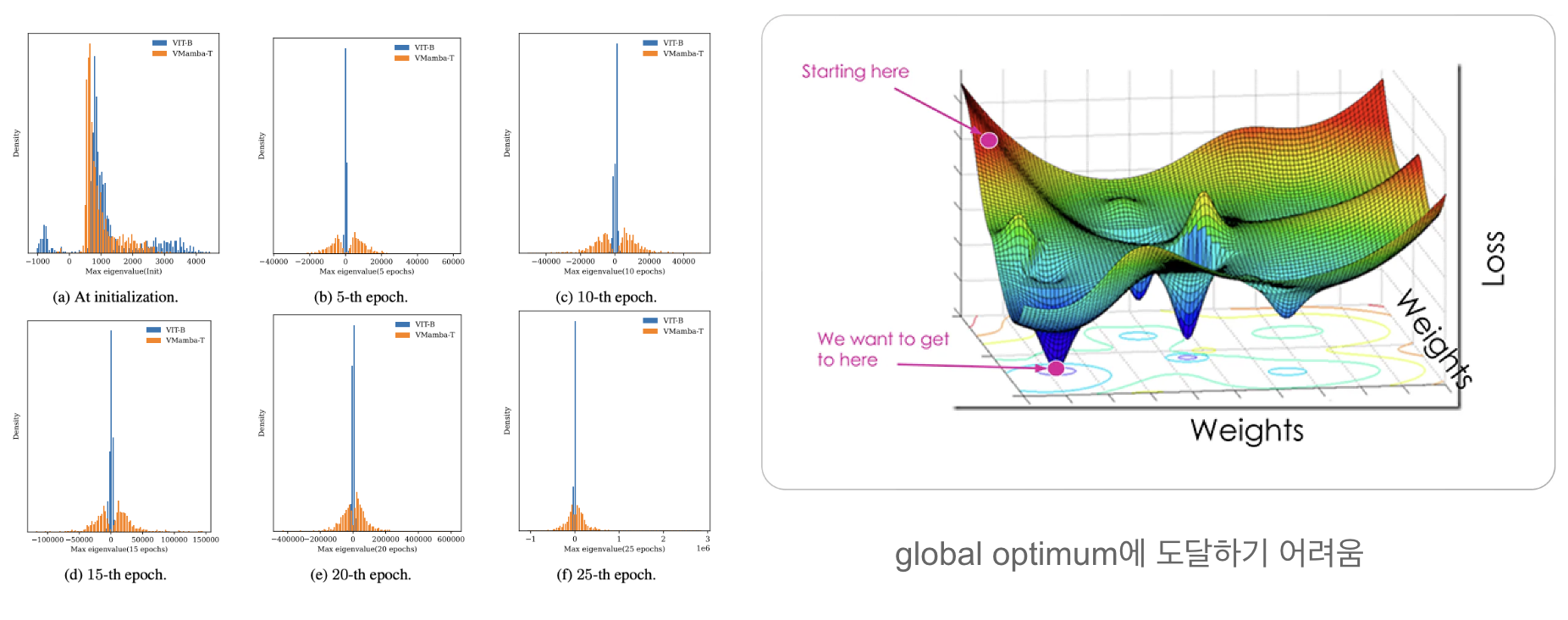
이러한 Mamba 모델을 CLIP에 활용하려는 연구가 있었습니다. 그러나 Hessian Evaluation 결과에 따르면, Mamba의 학습 곡률은 매우 비볼록성(non-convexity)을 띄고 있어 global optimum에 도달하기 어렵다는 문제가 존재합니다. 이에 따라 단순히 이미지-텍스트 쌍(pair)만을 학습하는 방식으로는 한계가 있었습니다. 따라서 더 효과적인 학습을 위해 다양한 접근 방식이 필요합니다.
Our Model
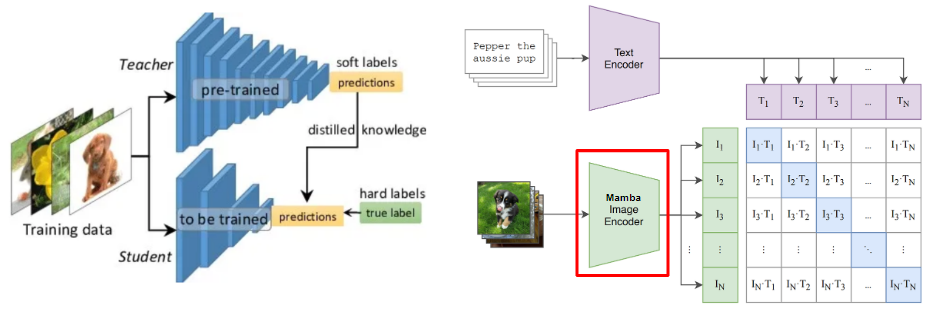
따라서 저희는 빠른 속도와 우수한 성능을 자랑하는 MambaVision 이미지 인코더를 사용하여, teacher embedding을 모방하는 방식으로 학습하는 distillation 기법을 적용하였습니다. 이를 통해 MobileCLIP보다 더 뛰어난 성능을 발휘하는 모델을 개발했습니다.
3. Experiments
Setting
저희는 기존 MobileCLIP의 학습 방법에서 몇 가지 변화를 주어 실험을 진행했습니다. 실험 환경은 NVIDIA A100 GPU 1개를 사용하였으며, 데이터셋은 DataCompDR의 일부분인 5백만 개 샘플을 활용했습니다. 특히, teacher embedding을 강하게 학습하는 것이 핵심 목표였기 때문에, 기존 CLIP loss의 가중치는 0.25으로 설정하고, distill loss의 가중치는 0.75로 두었습니다. 같은 환경에서 MobileCLIP_S1 모델과 MobileMCLIP_S1(Ours)을 학습시켜 점수를 비교합니다.
항목 설정
GPU A100 80GB (1개)
데이터셋 DataCompDR-5M
Seen Sample 3M
Batch Size 256
Learning Rate 1e-4
Zero-Shot Classification
CLIP Benchmark라는 오픈소스를 활용하여 모델을 평가합니다.
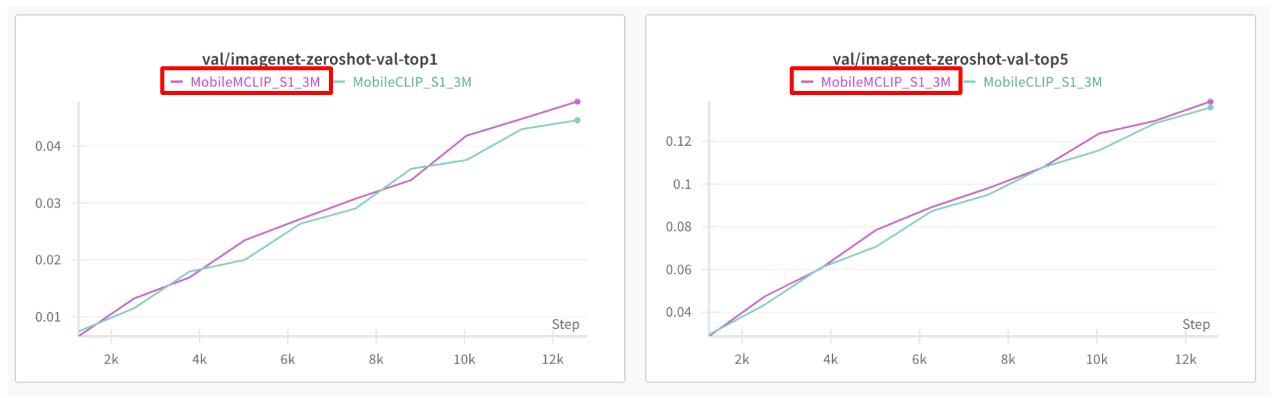
Validation Accuracy
학습 과정에서는 MobileMCLIP_S1(Ours) 모델이 조금 더 높은 Validation 정확도를 보여줍니다.
Zero-Shot Classification
CLIP Benchmark
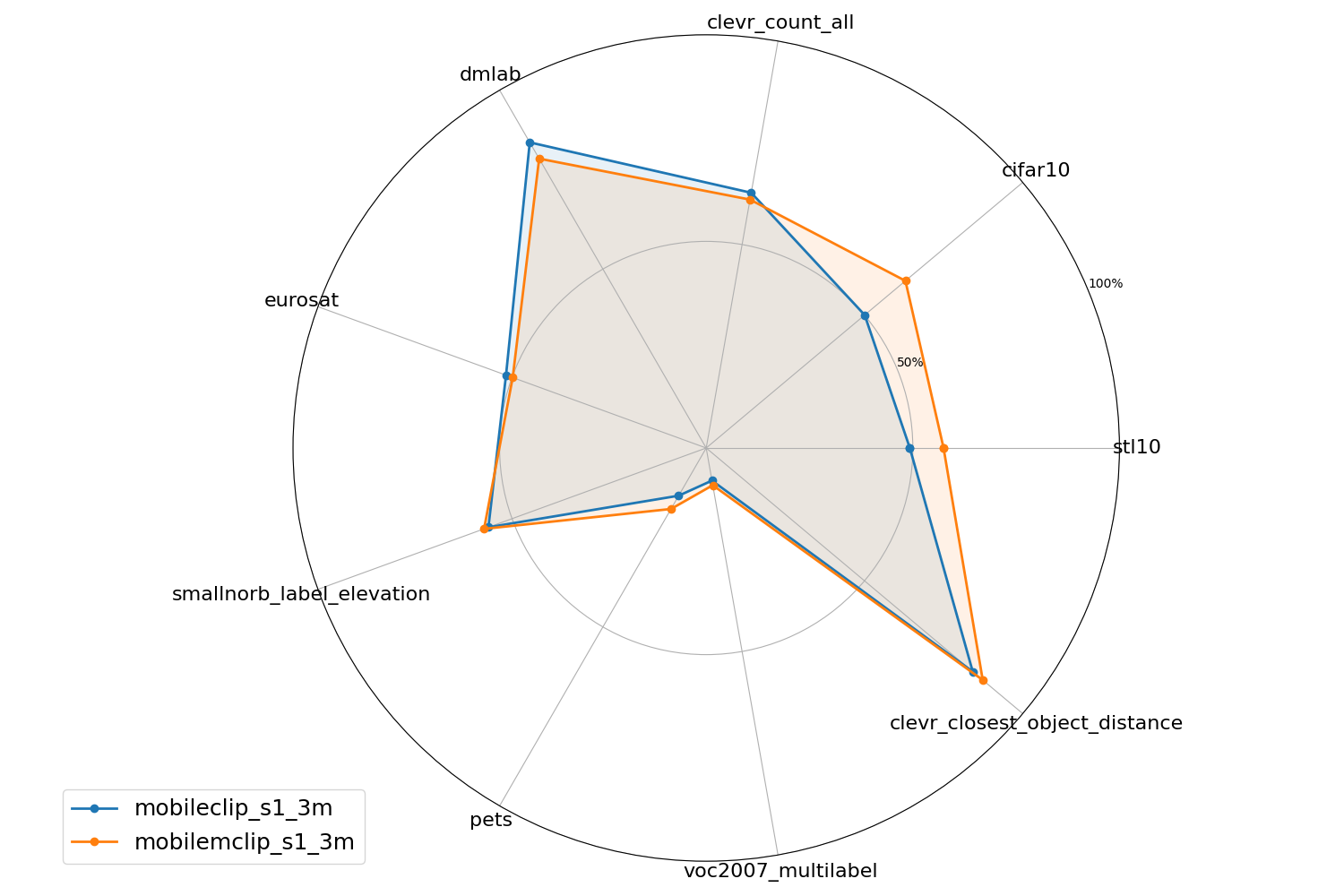
acc 5(41 avg)
MobileCLIP_S1_3M 0.5943
MobileMCLIP_S1_3M(Ours) 0.6935(+16.69%)
STL-10
고해상도 이미지 (기존 모델 대비 10.21% 개선했습니다.)

KITTI Closest Vehicle Distance
공간 정보 이미지 (기존 모델 대비 15.92% 개선했습니다.)

4. Results
- Distillation: Transformer 아키텍처의 정보를 Mamba 기반 이미지 인코더로 distillation하여 우수한 성능을 달성했습니다.
- Faster & Stronger: Mamba를 활용해 기존 모델보다 더 빠르고 높은 성능을 자랑하는 CLIP 인코더를 구현했습니다.
- 고해상도 이미지 처리: 특히 고해상도 이미지에서 많은 패치 연산이 필요한 경우에도 성능이 크게 향상되었습니다.
Reference
- https://arxiv.org/abs/2303.14189
- https://arxiv.org/abs/2103.00020
- https://arxiv.org/abs/2311.17049
- https://www.youtube.com/watch?v=o3UEbQ24zhQ
- https://radical.vc/neurips-2022-and-whats-next-in-generative-ai/
- https://arxiv.org/abs/2407.08083
- https://arxiv.org/abs/2401.09417
- https://arxiv.org/abs/2312.00752
- https://www.v7labs.com/blog/cross-entropy-loss-guide