
1. 프로젝트 개요
1.1 주제
인공지능과 자연어 처리(NLP)의 발전은 사람들이 데이터를 처리하고 활용하는 방식에 큰 변화를 주고 있습니다. 특히, 텍스트 요약은 많은 양의 문서를 핵심 내용만으로 압축하여 이해를 돕는 기술로, 시간과 자원을 절약하는 데 중요한 역할을 합니다. 하지만 대부분의 요약 모델은 영어를 중심으로 개발되었으며, 한국어와 같은 다른 언어에 적합하지 않은 경우가 많습니다. 특히, 한국어의 복잡한 문법 구조와 고유한 어휘 체계 때문에 한국어를 위한 대화 요약 모델은 아직 많이 연구되지 않았습니다.
따라서 본 프로젝트의 목표는 한국어 대화 데이터를 효과적으로 요약할 수 있는 PEGASUS 기반 요약 모델을 구축하는 것입니다. 기존의 PEGASUS 모델은 영어에 최적화되어 있어 한국어 대화 데이터를 처리하는 데 한계가 있었습니다. 이를 극복하기 위해 한국어에 적합한 새로운 토크나이저(tokenizer)를 개발하고, 사전 학습과 파인튜닝을 통해 성능을 높이고자 했습니다.
1.2 분석 목적
현재 한국어를 대상으로 하는 요약 모델에는 Ko-GPT2, KoBART, KoBERT 등이 있습니다. 하지만 영어를 기반으로 한 요약 모델들은 다양한 학습 방식과 기법을 활용한 여러 가지 모델들이 존재합니다. 그 중 하나가 바로 PEGASUS(Pre-training with Extracted Gap-sentences for Abstractive Summarization)입니다. 특히 대화, 예를 들어 인터넷 채팅에서는 중요한 대화 내용이 간헐적으로 나타나며, 모든 대화가 요약의 핵심이 되는 것은 아닙니다. 예를 들어, 단체 채팅방에서는 짧은 시간 안에 수백 개의 메시지가 쏟아질 수 있는데, 이러한 모든 메시지의 관계성을 모델이 전부 파악하는 것은 매우 비효율적일 수 있습니다. 이런 문제를 해결하기 위해, 우리는 문장 단위로 중요한 정보를 학습하는 PEGASUS 모델이 한국어 대화 요약에 적합하다고 판단했습니다. 기존의 영어 기반 사전 학습 모델인 PEGASUS를 한국어 대화 데이터에 맞게 변형하여 적용하는 것을 이번 프로젝트의 목표로 삼았습니다.
1.3 텍스트 요약이란?
텍스트 요약은 긴 문서에서 핵심 정보만을 추출하여 간결하게 표현하는 자연어 처리 작업입니다. 이는 수많은 정보를 빠르게 이해하고 분석할 수 있도록 도와줍니다.
텍스트 요약에는 두 가지 주요 방식이 있습니다:
- 추출적 요약(Extractive Summarization): 문서에서 원본 문장을 그대로 가져와 요약하는 방식입니다. 핵심 문장을 선택하는 데 중점을 둡니다.
- 추상적 요약(Abstractive Summarization): 원본 문장을 다시 재구성하여 요약하는 방식입니다. 이 방법은 새롭고 더 간결한 문장을 생성할 수 있어 자연스러운 요약 결과를 제공할 수 있습니다.
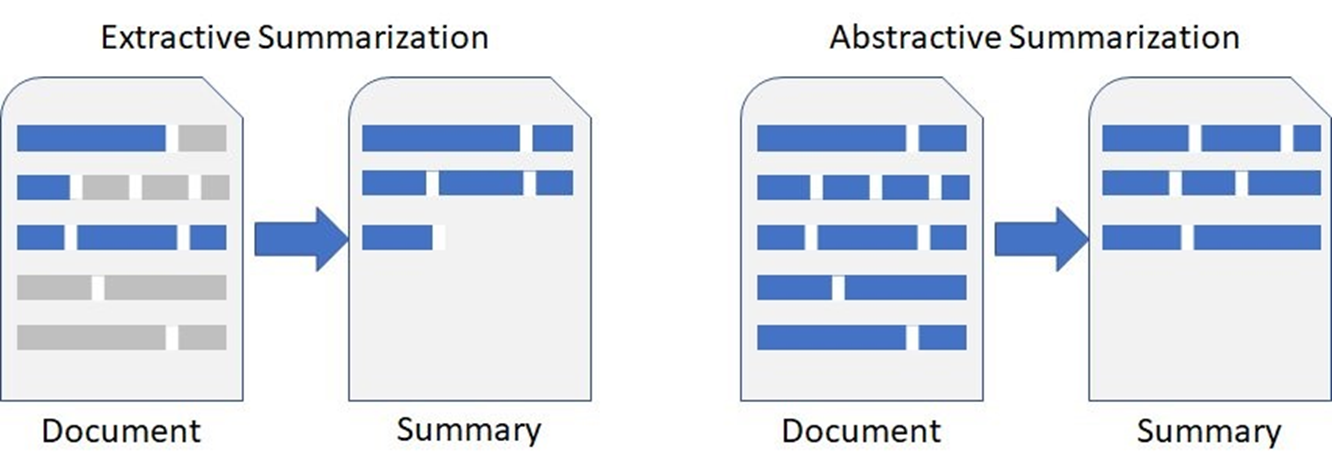
기존 연구는 추출 요약에 집중하였으나, 점차 생성 요약으로 연구가 확산되고 있습니다. 셀프 어텐션 메커니즘을 통해 더 긴 문맥을 효과적으로 처리할 수 있게 된 Transformer 모델은 문서 내에서 다양한 부분 간의 관계를 이해할 수 있게 되었습니다. 그 외에도 전이 학습 기술의 발달, 대규모 언어 모델의 개발은 이전과 달리 생성 요약도 충분히 좋은 성능을 가질 수 있게 되는 계기가 되었습니다.
1.4 PEGASUS 모델 아키텍쳐
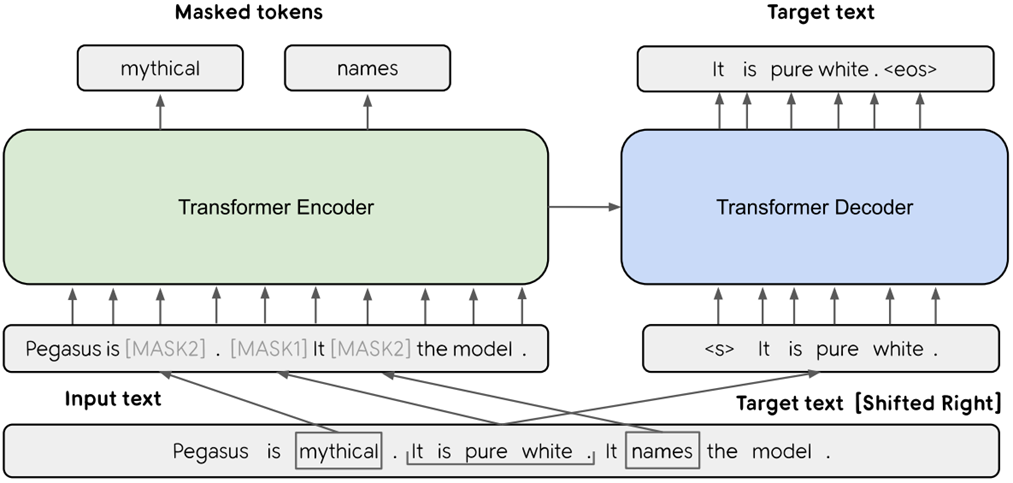
PEGASUS는 문서 요약을 위한 Transformer 기반 모델로, 입력된 텍스트에서 중요한 부분을 자동으로 파악하여 요약을 생성합니다. 모델의 핵심은 Encoder-Decoder 구조입니다.
- 인코더(Encoder) :
입력된 텍스트를 처리하여 문맥을 이해하고, 중요한 부분을 추출할 수 있는 표현을 만듭니다. 일부 중요한 단어나 구절은 마스크(MASK) 처리되어 이후에 복원해야 합니다.
- 디코더(Decoder) :
인코더가 생성한 정보를 기반으로 마스크된 부분을 복원하고, 요약된 문장을 만듭니다. 이 과정에서 요약 문장이 자연스럽고 간결하게 생성됩니다. PEGASUS의 특징은 마스크 기법을 사용하여 중요한 부분을 예측하는 방식으로 학습된다는 점입니다. 먼저 사전 학습을 통해 다양한 문서에서 중요한 문장을 예측하는 방법을 배우고, 이후 특정 요약 작업에 맞춰 파인튜닝됩니다. 이 과정을 통해 PEGASUS는 문서 요약에서 핵심 내용을 정확하고 자연스럽게 요약할 수 있는 능력을 갖추게 됩니다.
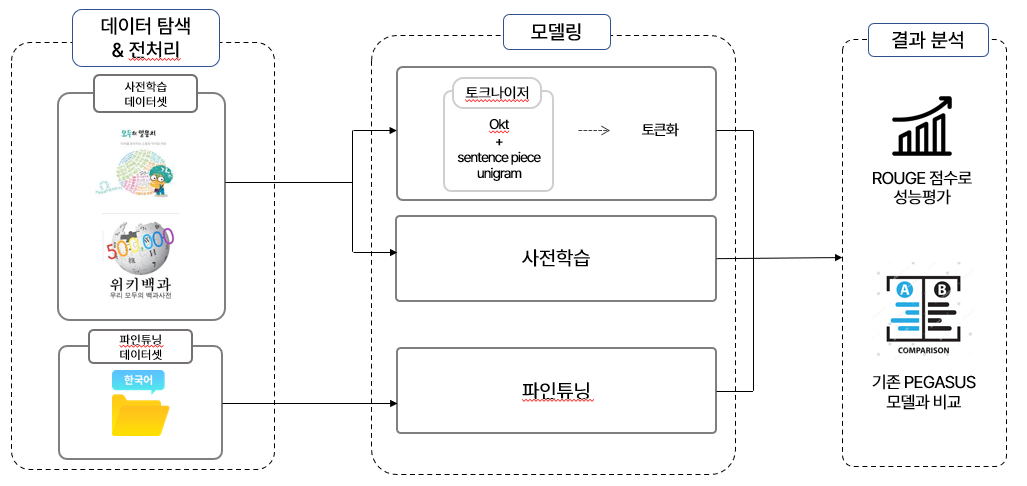
1.5 프로젝트 흐름도
본 프로젝트는 데이터 탐색 및 전처리, 모델링, 그리고 결과 분석의 세 가지 주요 단계로 진행되었습니다.
2. 데이터
2.1 사전학습 데이터
기존 PEGASUS 모델은 영어 데이터를 학습하는 데 C4 웹페이지 데이터와 Huge News 데이터를 사용했습니다. 그러나 한국어 대화 요약을 위해서는 한국어 데이터로 사전 학습을 진행해야 했습니다. 이를 위해 우리는 한국어 데이터를 수집했으며, <모두의 말뭉치> 데이터셋을 사용했습니다. 이 데이터셋에는 일상 대화뿐 아니라 다양한 기사 형식의 텍스트도 포함되어 있어, 모델이 한국어 문법과 표현을 잘 이해할 수 있도록 했습니다.
2.2 Fine-tuning 데이터
파인튜닝은 사전 학습된 모델을 특정 작업에 맞게 더욱 세부적으로 조정하는 과정입니다. 이번 프로젝트에서는 요약 작업에 맞는 모델을 만들기 위해 를 사용했습니다. 이 데이터셋은 한국어 대화와 해당 대화의 요약문으로 구성되어 있으며, 개인 관계, 미용과 건강, 상거래, 시사 교육 등 9가지의 다양한 주제를 포함하고 있습니다. 이를 통해 모델이 다양한 상황에서의 대화를 요약하는 능력을 학습하고자 했습니다.
2.3 데이터 전처리

데이터 전처리는 모델 학습의 중요한 단계로, 불필요한 정보를 제거하고 텍스트를 정제하는 과정입니다. 이 프로젝트에서는 다음과 같은 전처리 작업을 진행했습니다
- 대화 내용 및 요약문 추출:
학습에 필요한 대화 내용과 요약문만을 추출하고, 대화 시간이나 발화자 정보 등 불필요한 부분은 제거했습니다.
- 특수문자, 따옴표, 이모티콘 제거:
대화에는 많은 특수문자, 따옴표, 이모티콘이 포함되는데, 이러한 요소들은 모델 학습에 부정적인 영향을 줄 수 있어 모두 제거했습니다.
- 반복되는 음소 처리:
한국어 대화에는 "ㅋㅋㅋㅋ", "ㅎㅎㅎㅎ"처럼 반복되는 음소가 자주 사용됩니다. 이러한 반복되는 음소는 모델의 혼란을 야기할 수 있으므로, 2개 이상 반복되는 경우에는 2개만 남기고 삭제했습니다.
- 토큰 추가:
각 문서의 끝에 (End Of Document) 특수 토큰을 추가해 문서가 종료되는 지점을 명확히 표시했습니다. 이는 이후 GSG(Gap Sentence Generation) 기법을 적용할 때 문서 단위를 구분하는 데 사용됩니다.
3. 토크나이저
3.1 한국어 토크나이저가 필요한 이유
자연어 처리 모델을 구축할 때는 토크나이저 학습이 선행됩니다. 언어에 관계없이 많이 쓰이는 알고리즘으로 구글에서 만든 Sentencepiece의 BPE 알고리즘과 Unigram 알고리즘을 많이 사용합니다. 이는 언어에 관계 없이 글자를 음소 단위로 쪼갠 후, 빈도수를 기준으로 연속해서 많이 나오는 것들을 하나로 합치면서 서브워드를 만듭니다.
기존 PEGASUS의 토크나이저는 Sentencepiece의 Unigram 알고리즘을 이용해 토크나이저를 제작해 사용했습니다. 이는 영어를 대상으로 만든 토크나이저로 한국어 데이터셋에는 적용하기 어렵습니다. 서브워드에 있는 100번째 단어와 201번째 단어의 관계성을 모델이 학습하는데, 영어 대상이었던 것을 한국어에 적용하면 전혀 다른 결과가 나오기 때문입니다. 이는 향후 모델이 학습됐을 때 아예 한국어 토큰 자체를 인식하지 못하거나 요약 대상의 문맥을 전혀 고려하지 않은 결과가 나오는 원인이 될 수 있습니다. 실제로 기존 PEGASUS의 토큰나이저를 이용해 요약 결과를 얻으면 다음과 같은 요약이 출력됩니다.
input_text = "회의록 몇 시까지 넘겨줘야 돼? 4시까지. 앗...나 다른 일 때문에 좀 어려울 것 같은데"
tokens = tokenizer(input_text, return_tensors="pt", max_length=1024, truncation=True)
print(tokens)
summary_ids = model.generate(tokens['input_ids'], num_beams=5, max_length=50)
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print("summary_ids", summary_ids)
print("요약:",summary){'input_ids': tensor([[ 2061, 7852, 222, 209, 5161, 43044, 647, 184, 1452, 1130,
5161, 3115, 960, 12639, 449, 193, 93, 243, 799, 77,
9114, 35, 267, 77, 1736, 9771, 2886, 1452, 1877, 224,
24622, 838, 7]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1]])}
summary_ids tensor([[ 0, 47, 799, 410, 410, 541, 541, 541, 541, 541, 3115, 7,
3115, 7, 3115, 7, 3115, 7, 3115, 7, 3115, 7, 3115, 7,
3115, 7, 3115, 7, 3115, 7, 3115, 7, 3115, 7, 3115, 7,
3115, 7, 24, 3115, 7, 3115, 7, 3115, 3115, 3115, 7, 3115,
7, 1]])
요약: '?' '.', '.', '.' "모델이 토큰이 어떤 의미를 가졌는지 전혀 알지 못한 채로 출력을 하고 있습니다.
3.2 한국어 대화에 적합한 토크나이저
PEGASUS 모델과 동일하게 한국어를 대상으로 Sentencepiece의 Unigram 알고리즘을 사용하는 방법을 고려할 수 있지만, 이는 한국어가 교착어라는 특성을 고려할 때 좋은 결과를 기대하기 어렵습니다. 교착어는 하나의 어절이 여러 형태소로 돼 있는 언어를 말합니다. 이는 표면상 같은 형태소가 문맥마다 다른 형태소가 되기도 하고, 다른 의미를 가지게 되기도 하는 특성을 가지고 있습니다. Senetencepiece처럼 빈도수만을 기준으로 하면 이를 고려하지 않게 되므로 품사 태깅을 할 수 있는 방법을 고려해야 합니다.

이를 해결하기 위해 KoNLPy의 Okt를 이용하는 방법을 생각했습니다. KoNLPy는 한국어 대상 자연어 처리를 할 때 많은 사람들이 사용하는 라이브러리로, 여러 가지 형태소 분석기를 제공합니다. 다음과 같은 사항을 고려해 Okt 형태소 분석기를 선택했습니다.
- Twitter의 한국어 텍스트를 대상으로 학습을 이어나갔던 모델로, SNS나 채팅 텍스트 분석에 적합합니다.
- 표제어(어간) 추출이 가능해 교착어의 특성을 일정 수준 극복 가능합니다.
- 많은 사람들이 실시간으로 업데이트하고 있는 형태소 분석기로, 빠르게 변화하는 채팅 언어에 대응이 가능합니다.
하지만, 여전히 정밀한 형태소 분석은 어렵다는 한계를 고려해 Sentencepiece Unigram 알고리즘과 결합하는 방식을 선택했습니다. 이를 통해 토크나이저를 만드는 방법은 아래와 같습니다.

- 전처리를 거친 한국어 대화 요약 데이터셋을 KoNLPy의 Okt를 이용해 품사 태깅한 텍스트 파일을 생성합니다.
- 텍스트 파일에 대해 확률 기반의 Unigram 알고리즘을 이용하여 96000개의 단어를 가진 서브워드 집합을 형성합니다.
- PEGASUS 모델에 필요한 스페셜 토큰인 ( )를 삽입합니다.
4. Pre-train & Fine-tuning
4.1 Pre-train
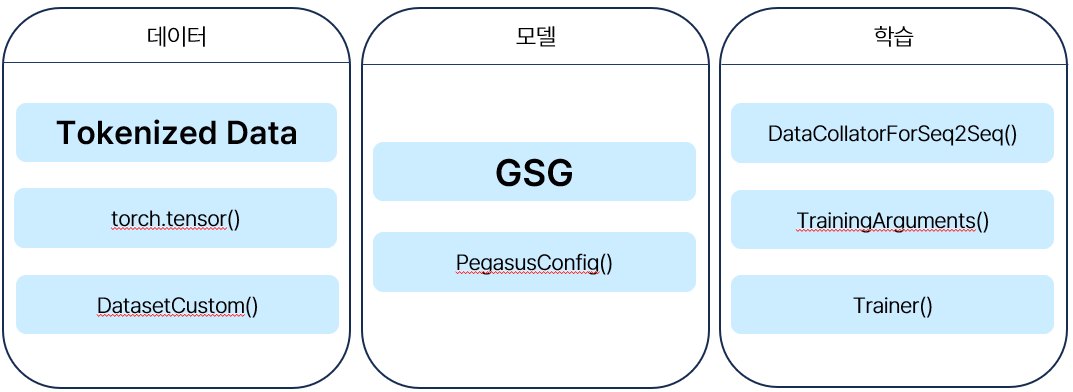
모델이 한국어를 이해할 수 있도록 하는 사전학습 과정입니다. 구현 내용은 크게 데이터, 모델, 학습의 세 부분으로 구분됩니다. 먼저 자체 학습한 토크나이저를 사용하여 토큰화 한 학습 데이터를, 모델에 입력할 수 있는 텐서 형식으로 변환합니다. 변환된 텐서는 다음의 세 종류의 데이터 쌍으로 모델에 입력됩니다.
- input_ids : 모델 입력 문장의 텐서
- attention_mask : 입력의 전체 인덱스에서, 실제 토큰 부분과 0으로 패딩된 부분을 구분하는 텐서
- labels : 모델이 예측할 타겟 문장의 텐서
모델의 경우 페가수스 모델의 핵심이 되는 GSG(Gap Sentence Generation)을 직접 구현하고, PegasusConfig()를 사용해 PEGASUS 모델의 아키텍처는 가져오되, 가중치는 초기화하여 사용합니다. 이후 DataCollatorForSeq2Seq(), TrainingArguments(), Trainer() 등의 모듈을 사용하여 학습을 진행합니다.
4.2 Fine-tuning
사전학습을 통해 한국어 학습을 마친 후, 특정 작업에 특화된 모델을 만들기 위한 Fine tuning 작업을 수행합니다. 본 프로젝트에서는 요약에 특화된 모델을 생성하기 위해, 앞서 언급한 요약 데이터를 사용하여 학습합니다. 먼저 데이터 로드 후 발화 및 요약문을 추출하고, 토큰화를 진행합니다. 이후 한국어 데이터로 사전학습한 모델을 Fine tuning 데이터로 학습합니다.
5. 성능 평가 및 결론
5.1 성능평가
Train Loss 확인 결과, GSG 적용 전 사전학습에서 0.7~0.8에 오래 머무르던 Loss가 GSG 적용 후 큰 폭으로 감소했습니다. 이는 GSG 기법으로 모델의 성능을 향상시키려는 시도가 제대로 적용되었음을 나타냅니다.

아래 표는 Input Text에 대한 사전학습 모델과 파인튜닝 모델의 출력 결과입니다. 사전학습 모델과 파인튜닝 모델 모두 입력 텍스트와 관련이 없는 내용을 출력했지만, 파인튜닝 모델은 비교적 요약문과 같은 문체로 출력되었습니다. 이는 Fine tuning 결과, 모델이 요약 작업에 특화 되도록 맞춰지는 과정에 있음을 알 수 있습니다.

5.2 결론
본 연구는 PEGASUS 모델을 한국어 대화 요약에 맞춰 처음부터 설계하고 구축하였습니다. 특히, GSG(Gap Sentence Generation) 기법을 적용해 모델의 성능을 효과적으로 개선한 것이 주요 성과입니다. GSG 기법을 도입한 결과, 모델 학습 과정에서 LOSS(손실값*가 크게 감소하는 유의미한 성과를 얻을 수 있었으며, 이는 한국어 대화 데이터를 요약하는 데 최적화된 방식으로 모델이 학습되었음을 보여줍니다. 이 연구를 통해 한국어 대화 요약에 특화된 모델을 구축함으로써, 기존 영어 중심 요약 모델이 가지는 한계를 극복했습니다. 파인튜닝 후 생성된 요약문의 문체와 표현이 자연스러웠으며, 이는 모델이 대화 요약의 문맥과 특성을 잘 학습했음을 시사합니다. 이러한 연구 성과는 향후 다양한 산업 분야에서 실질적인 응용 가능성을 보여줍니다.
5.3 한계점 및 향후 개선 방안
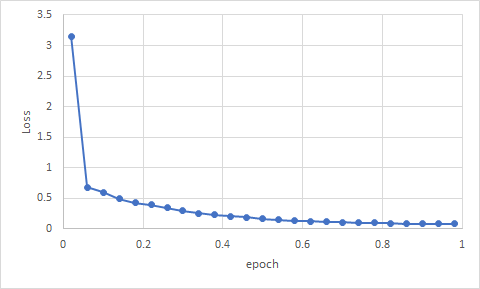
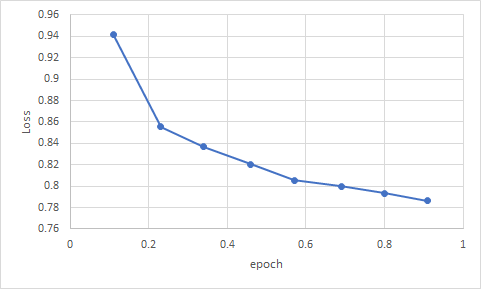
이번 연구는 시간적 제약과 컴퓨팅 자원 부족으로 인해 모델이 충분히 학습되지 못한 상태에서 언더피팅(Underfitting) 문제가 발생했습니다. 위 그래프에서 확인할 수 있듯이, 사전학습과 Fine tuning 모두 Loss가 지속적으로 감소하는 형태를 보이므로 더 오랜 학습을 진행하면 성능이 향상될 것임을 알 수 있습니다. 더 또한, 사전 학습과 파인튜닝 과정에서 다양한 유형의 데이터를 모두 사용하지 못하고, 일부 유형(분야)의 데이터만을 사용할 수밖에 없었습니다. 이로 인해, 모델이 특정 분야에 치우친 요약 결과를 생성하는 경향이 나타났습니다. 이러한 한계는 모델의 일반화 성능을 저해할 수 있습니다. 향후 연구에서는 이러한 한계를 극복하기 위해 더 많은 학습 시간과 고성능 컴퓨팅 자원을 확보할 계획입니다. 이를 통해 더 다양한 한국어 대화 데이터 유형을 학습시켜, 모델이 특정 분야에 치우치지 않고 균형 잡힌 요약 성능을 보일 수 있도록 개선할 것입니다. 또한, GSG 기법의 성능을 더욱 극대화하여, 다양한 산업 분야에 적용 가능한 일반화된 한국어 대화 요약 모델을 개발하는 것을 목표로 하고 있습니다.