
1. Intro
별빛이 흐르는 다리를 건너 **으쌰라 으쌰 으쌰라 으쌰 !
바람부는 갈대숲을 지나 으쌰라 으쌰 으쌰라 으쌰 !**
야구 좀 본다 하는 사람들은 모를 수가 없는 응원가, < 🎶아파트 >의 도입부 구절이죠! 승리가 확정되었을 때, 부르면 두 배로 기분 좋아지는 응원가. 야구에서 승리만큼 중요한 것이 바로 📣 응원가입니다. 그런데 이 응원가, 우리 선수들도 부를까요? 생각해보면 우리 관중들만 목놓아 부르지, 선수들의 목소리로 들어본 적은 없던 것 같습니다. ✨ 어디 한 번 우리 선수들도 노래하게 만들어봅시다! ✨
2. Background
2.1. Audio 데이터의 특징
Audio AI는 소리 데이터를 분석하고 활용하는 기술로, 단순한 소리 인식을 넘어, 인간과의 자연스러운 상호작용을 가능하게 하고, 현재는 음성 합성 및 인식, 음악 생성, 이상치 탐색 등 다양한 분야에서의 연구가 활발하게 진행되고 있습니다.
Audio 데이터는 이러한 Audio AI에 활용되는 데이터로써, 시간에 따라 변하는 진폭을 가진 1차원 신호로 표현됩니다. 컴퓨터 비전의 2차원 이미지, 자연어 처리(NLP)의 텍스트와는 다르게 시간에 의해 변하는 독특한 특성을 지니기 때문에 Audio 데이터 처리에는 고유한 기술을 필요로 합니다.
우선, 모든 오디오 데이터는 시간에 따라 달라지는 다양한 주파수, 진폭, 위상을 가진 파형들의 연속적인 합으로 정의됩니다. 하지만, 연속적인 데이터는 무한한 데이터 크기를 가지므로, 딥러닝 학습을 위해서는 이산적인 값으로 변환해야 합니다. 이에 지정된 주기(샘플 레이트, Sample Rate)마다 데이터를 추출해서 이산화 하는 샘플링(Sampling), 추출된 데이터의 값들을 제한된 범위의 이산적인 값으로 변환하는 양자화(Quantization) 절차를 거쳐 이산적인 값으로 변환됩니다.
현재 추출된 오디오 데이터의 분석에는 Mel-Spectrogram, STFT(Short-Time Fourier Transform), MFCC(Mel-Frequency Cepstral Coefficients) 등의 기술이 사용되고 있습니다.
하지만, 오디오 AI를 구현하는 데 있어 여러 문제도 존재합니다. 그 중 가장 대표적인 문제는 데이터 확보의 어려움입니다. 크롤링을 통한 데이터 수집이 가능한 텍스트나 이미지와 달리, 고품질의 오디오 데이터를 수집하는 것은 많은 시간과 비용이 필요합니다. 또한 데이터의 변동성으로 인한 영향을 줄이기 위한 전처리, 보정 기술이 필요하다는 것도 하나의 특징입니다.
2.2. AutoVC
2.2.0 Voice Conversion
Voice Conversion이란 Source speaker의 입력 음성을 텍스트 상의 변화 없이 마치 Target speaker가 말하는 것처럼 만드는 Task입니다.
2.2.1 Model Architecture
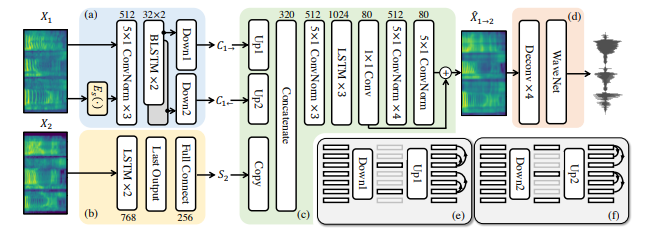
- The Speaker Encoder(=Style Encoder)
Speaker Embedding은 동일 화자의 서로 다른 발화에서 일관된 임베딩을 생성하고, 다른 화자 간에는 다른 임베딩을 생성하도록 설계되었습니다. 이를 위해 LSTM 기반의 구조를 사용하며, zero-shot 변환을 위해 사전 훈련된 임베딩이 필요합니다.
- The Content Encoder
콘텐츠 인코더는 입력 음성의 Mel-Spectrogram과 Speaker Embedding을 결합하여 처리하며, 적절한 다운샘플링을 통해 information bottleneck을 형성합니다. 이 bottleneck은 콘텐츠 정보를 유지하면서 화자 정보를 제거하는 역할을 합니다.
- The Decoder
Decoder는 Content embedding과 Speaker embedding을 결합하여 변환된 음성의 Mel-Spectrogram을 생성합니다. 초기 추정치와 잔차 신호를 결합하여 최종 변환 결과를 얻으며, 이는 높은 품질의 음성 변환을 가능하게 합니다.
- The Spectrogram Inverter(=Vocoder)
변환된 Mel-Spectrogram을 다시 음성 파형으로 변환하기 위해 WaveNet vocoder를 사용합니다. 이는 사전에 훈련된 모델로, 고품질의 음성 생성을 지원합니다.
2.2.2 Experiments / Conclusion
- AutoVC는 VCTK 코퍼스에서 Non-parallel many-to-many 음성 변환 작업에 대해 평가되었습니다. 실험 결과, AUTOVC는 전통적인 방법론들에 비해 우수한 성능을 보였으며, zero-shot 음성 변환에서도 효과적인 성능을 입증하였습니다.
- Traditional Many-to-Many Conversion
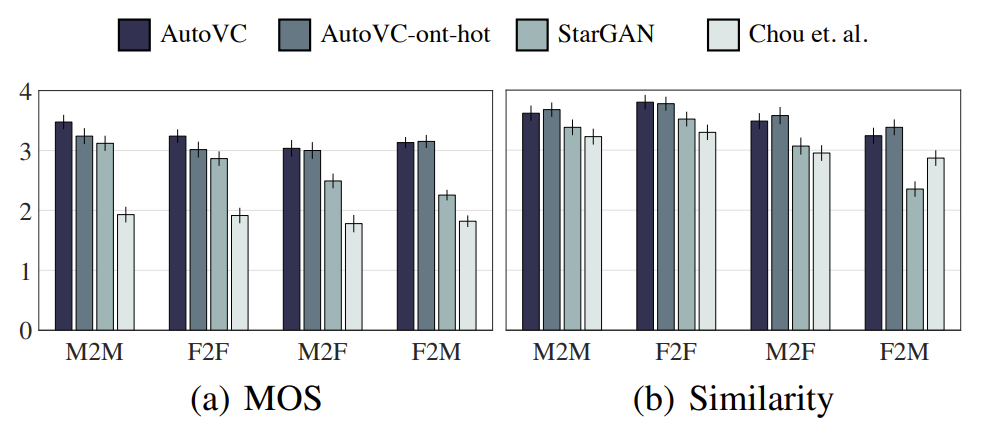
- Zero-shot Conversion
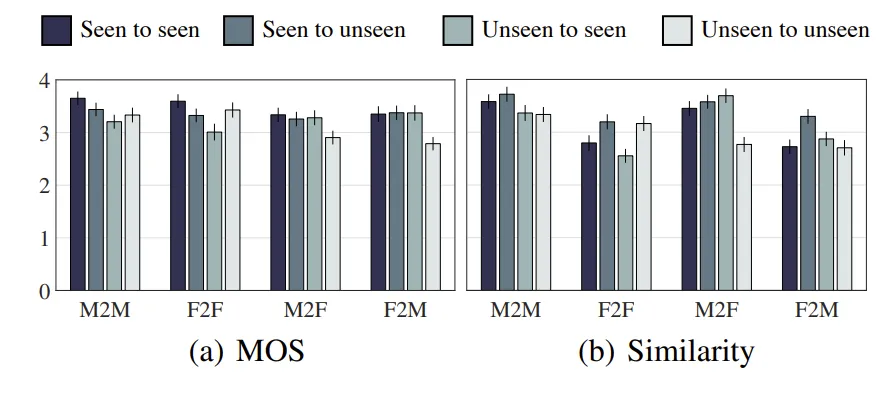
2.3. Auto-VC와 Audio 데이터
Auto-VC는 기존 Voice Conversion 모델과 비교했을 때, 다음과 같은 특징을 가지고 있습니다.
2️⃣ Many-to-Many Voice Conversion이 가능하다. GAN 기반 모델로 교체됨에 따라, 추출된 화자들의 임베딩(Speaker Embedding)들을 활용해 특정 화자의 음성을 여러 화자로 변환하거나, 여러 화자의 음성을 서로 변환시키는 것도 가능해졌습니다.
3️⃣ Zero Shot Voice Conversion이 가능하다. 인코더를 통해 추출된 화자 임베딩은 일관성, 유사성에 기반한 Latent Space 상의 위치를 가지게 됩니다. 따라서, 이미 추출된 임베딩의 Latent Representation을 활용해 학습되지 않은 화자에 대한 음성 변환이 가능해졌습니다.
위 내용을 종합해보면, Auto-VC는 1) Non Parallel Data을 활용한 학습이 가능하고, 2) Many-to-Many Voice Converion, 3) Zero-Shot Voice Conversion을 가능하게 만든 모델입니다. 또한 이미지 분야에서 자주 사용되던 GAN + CVAE 구조의 도입을 통해 음질 향상, Latent Space에서의 임베딩 효율성을 크게 높혀 더 자연스러운 음성 변환을 가능하게 만들었습니다.
3. Project
3.1. Building Baseline
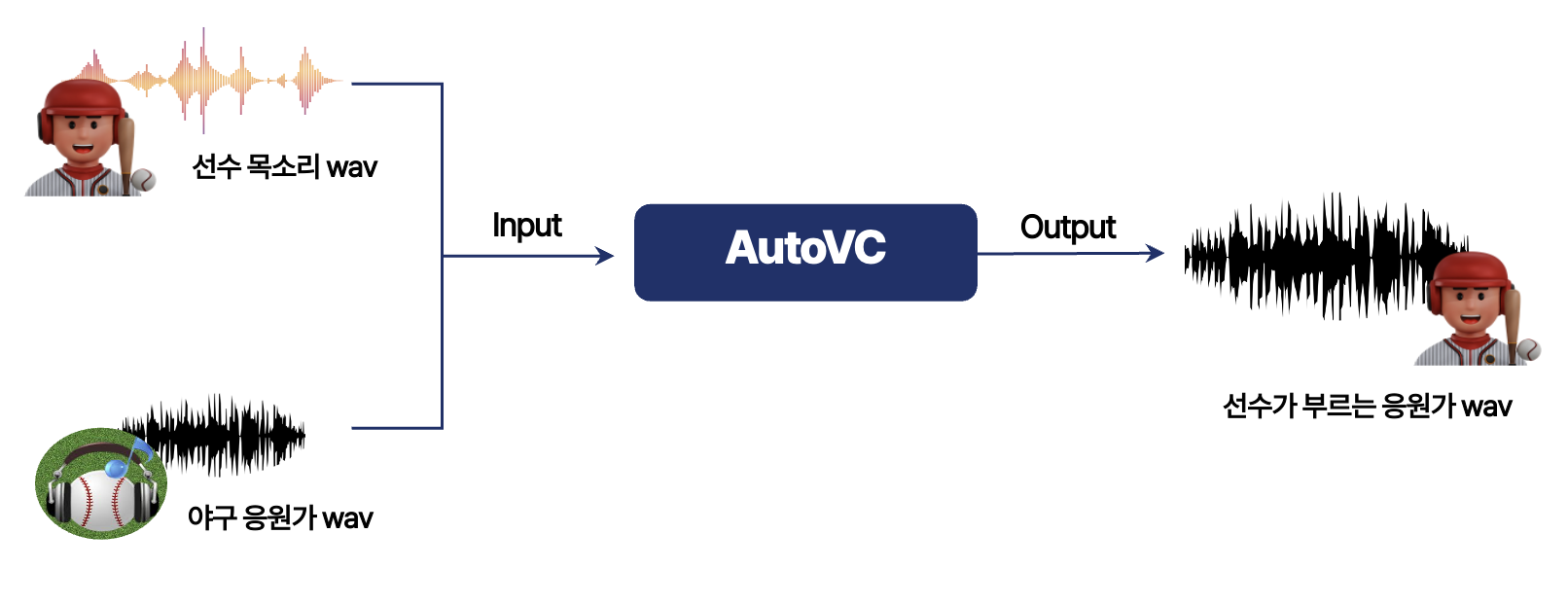
본 프로젝트는 선수 목소리를 Target Speaker, 야구 응원가를 Source Speaker로 하여 Voice Conversion을 진행합니다. 최종적인 출력 값은 선수가 부르는 응원가 음성 데이터입니다.
3.2. Data Preprocess
Auto-VC의 모델을 학습시키기 위해서는 각 파트에 맞는 데이터가 필요합니다.
- Auto-VC의 한국어 추출 능력을 향상시키기 위한 한국어 데이터
- AIHub에 존재하는 명령어 음성(일반 남여, AI-Hub)의 데이터를 수집한 뒤, 약 10명 가량의 목소리를 Auto-VC에 학습시켰습니다.
- 부르게 할 응원가 데이터
- 유튜브에서 각 구단 별 응원가의 데이터를 수집한 뒤, 배경 음악, 잡음 제거 등의 전처리를 거쳐 약 30곡 가량의 응원가 보컬 데이터를 수집했습니다.
- 응원가를 부를 선수의 목소리 데이터
- 유튜브, 방송에서 특정 선수의 인터뷰를 수집한 뒤, 배경음, 효과음 및 잡음을 제거한 뒤, 선수별로 파일을 수집했습니다.
3.3. Train
데이터가 준비되었다면, 이제 학습을 시켜볼 차례입니다. 하지만, 음성 데이터의 특성상 데이터의 갯수와 용량이 크기에 사전 학습된 모델을 불러오는 것이 필수적입니다! 따라서 저희는 Auto-VC의 사전 학습 데이터, Speaker Encoder의 사전 학습 데이터, 마지막으로 WaveNet Vocoder의 사전 학습 데이터를 사용했습니다.
1️⃣ Auto-VC의 사전 학습 데이터 이 데이터는 Auto-VC 모델이 이전에 학습했던 다양한 화자의 음성과 그들의 음성 특징을 가지고 있습니다. 모델은 화자간의 차이를 학습하기 위해서 해당 데이터를 활용합니다.
2️⃣ Speaker Encoder의 사전 학습 데이터 이 데이터는 Speaker Encoder에서 화자의 고유 특징을 인식하고 분류할 때 사용됩니다. 여러개의 동일한 화자의 음성 데이터를 사용해 각 화자만의 음성 고유 특징을 확인하고 임베딩 벡터를 생성할 수 있습니다.
3️⃣ WaveNet의 사전 학습 데이터 이 데이터는 다양한 화자의 음성 데이터로 이루어져 있습니다. 음성의 특징을 학습하고, 주어진 멜 스펙트로그램을 음성 데이터로 변환하는 방법을 학습시키기 위해 사용됩니다.
위와 같은 데이터가 준비된다면, 모델을 불러오고 데이터를 적용해 파인튜닝을 시키거나, 바로 추론을 시켜볼 수 있습니다.
3.4. Conversion
이제 앞서 준비된 데이터로 실제로 음성 변환(Voice Conversion)을 수행하는 단계입니다. AutoVC 모델을 활용해 입력된 선수의 음성 데이터(Target speaker)와 응원가 음성 데이터를 기반으로 변환된 음성을 생성합니다. 이 과정은 크게 다음과 같이 진행됩니다.
1️⃣ 입력 데이터 전처리 먼저, 선수의 음성 데이터와 응원가의 음성 데이터를 각각 Mel-Spectrogram으로 변환합니다. Mel-Spectrogram은 시간에 따른 주파수 정보를 시각적으로 나타내어 모델이 음성의 특징을 더 잘 이해할 수 있도록 돕습니다.
2️⃣ Voice Conversion 변환된 Mel-Spectrogram은 AutoVC의 Content Encoder와 Speaker Encoder를 거칩니다. 이 과정에서 Content Encoder는 응원가의 음성 내용(발음, 말의 흐름 등)을 추출하고, Speaker Encoder는 선수의 음성 특징(목소리의 톤, 억양 등)을 추출합니다. 그 후, 두 결과를 결합하여 선수의 목소리로 부르는 응원가의 음성 스펙트로그램을 생성합니다.
3️⃣ Vocoder를 통한 음성 파형 복원 생성된 Mel-Spectrogram은 바로 음성 파일로 사용할 수 없기 때문에, 이를 다시 음성 파형(waveform)으로 변환해야 합니다. 이때 HiFi-GAN 같은 Vocoder를 사용하여 고품질의 음성을 생성합니다. Vocoder는 Mel-Spectrogram의 주파수 정보를 기반으로 음성 신호를 재구성해 자연스러운 소리를 출력합니다.
4️⃣ Conversion된 결과물 확인 마지막으로 Vocoder를 통해 복원된 음성 파일을 확인하면, 선수의 목소리로 부르는 응원가가 완성됩니다.
4. Experiment : Make it Better
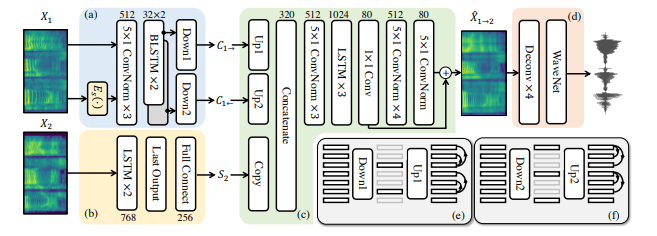
GitHub - auspicious3000/autovc: AutoVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss
4.1. Down Sampling - Up Sampling Method 개선
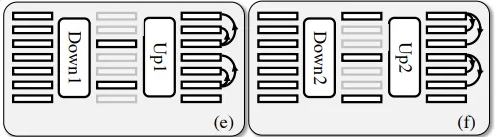
Auto VC 원문에서는 특징 추출을 위한 Downsampling operator로 vector를 select 하는 방법을 사용하고 있고, Upsampling operator로는 select된 vector를 이어붙이는 방법을 활용하고 있습니다. 하지만 이 방법의 Down sampling과 Upsampling 방식은 너무나도 select된 vector에 의존적이고, 복원 과정에서 데이터의 손실이 큽니다. 따라서 저희는 다른 방법을 사용해서 특징을 추출하는 실험을 진행해 보았습니다. 새로운 Downsampling operator로는 Average Pooling, 1D-Convolution, Upsampling operator로는 Transposed Convolution, Interpolation이 사용되었습니다.
4.2. Vocoder 개선
Auto-VC의 Vocoder는 기본적으로 pretrain된 WaveNet을 사용합니다. WaveNet은 2016년 딥마인드(DeepMind)에서 처음으로 공개한 딥러닝 기반 End-to-End 음성 생성 모델입니다. 당시 Vocoder 중 가장 좋은 성능을 차지했던 WaveNet이지만, Vocoder에 대한 연구가 지속되며 2021년 GAN 기반의 HiFi-GAN이 세상에 공개되었습니다. 아직까지도 압도적으로 좋은 성능을 보이고 있는 HiFi-GAN은 충분히 WaveNet을 대체해 볼만한 저희의 Motivation이 되었습니다. HiFi-GAN은 1개의 Generator과 2개의 Discriminator로 구성되어있는데, Discriminator는 Multi-scale & Multi-period Discriminator로 나눠집니다.
4.2.1 HiFi-GAN ; Generator
Generator의 상세한 구조는 다음과 같습니다.
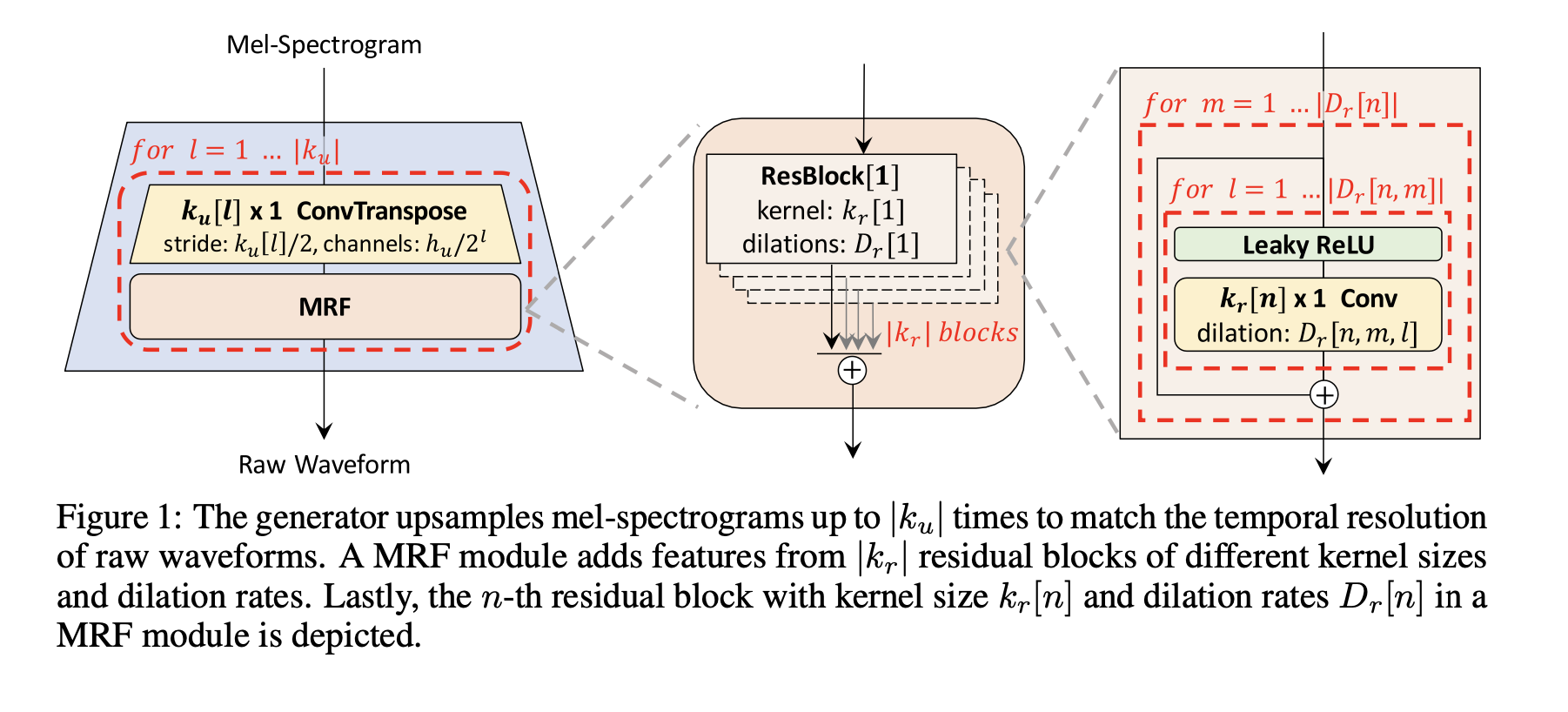
Generator에서는 Mel-Spectorgram이 input으로 입력되어, Raw Waveform이 output으로 나옵니다. 이는 모든 Transposed Convolution Layer 뒤에 Multi-Receptive Field Fusion(MRF) 모듈이 존재합니다. 이전의 일반적인 GAN처럼 Noise를 Generator의 추가적인 input으로 사용하지 않는다는 특징이 있습니다.
4.2.2 HiFi-GAN ; Dscriminator
실제와 같은 Speech audio를 모델링하기 위해서는 Long-term Dependencies를 식별하는 것이 핵심입니다. 이를 위해 Generator과 Discriminator의 Receptive Field를 증가시키는 방법을 사용하기도 하였습니다. 추가로 고려해야할 점은 Speech audio는 다양한 주기를 가진 신호로 구성되기에 audio 데이터에 존재하는 다양한 주기의 패턴을 식별할 필요가 있다는 점입니다. 이를 위해 HiFi-GAN은 Multi-Period Discriminaotr (MPD)를 제안합니다.

MPD는 여러 개의 Sub-Discriminator로 구성되고, 각 Discriminator는 input auido의 각 주기 신호 부분을 처리하는 특징을 가집니다. 또한 연속적 패턴과 Long-term Dependencies를 포착하기 위해 , MelGAN에서 제안한 Multi-Scale Discriminaotr(MSD)를 차용하였습니다. 이를 통해 다양한 레벨에서 audio sample을 연속적으로 평가할 수 있게 되었습니다.
그다음으로 Multi-Scale discriminator입니다. MPD의 각 Sub-Discriminator들은 분리된(이산적인) sample만 수용하기 때문에, MSD도 사용하여 audio sequence를 연속적으로 평가하도록 합니다. MSD구조는 MelGAN에서 사용되었던 것과 유사합니다. 3개의 Sub-Discriminaotr로 이뤄져있고, 각 Discriminaotr는 서로 다른 input scale에서 작동합니다. Raw audio, x2 Average-Pooled Raw audio, x4 Average-Pooled Raw audio와 같은 형태로 3가지의 서로 다른 스케일에서 작동합니다.
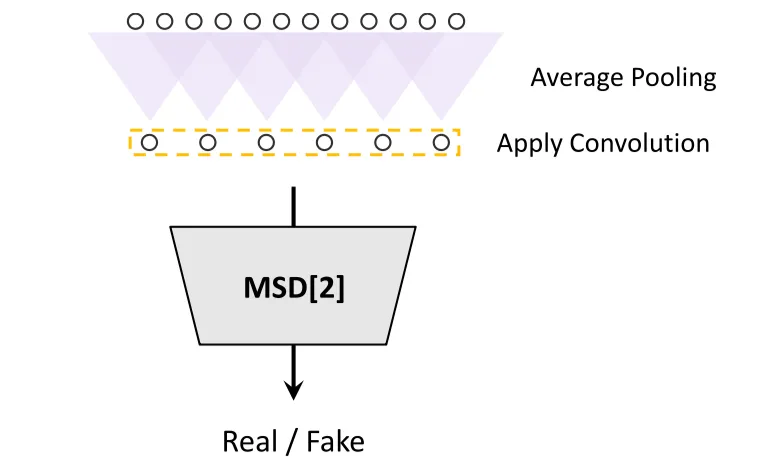
MPD와 MSD의 차이점은 전자는 Raw Waveform에서 분리된 샘플에서 작동하고 후자는 Smoothed Waveform에서 작동한다는 점입니다.
4.3. Speaker Encoder Feature Extraction Method 개선
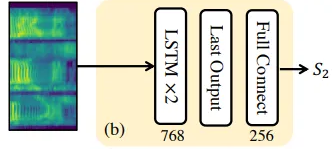
AutoVC 공식 Github repository에서 가져온 D_VECTOR 클래스의 forward pass (D_VECTOR : Generate speaker embeddings and metadata for training)
def forward(self, x):
self.lstm.flatten_parameters()
lstm_out, _ = self.lstm(x)
embeds = self.embedding(lstm_out[:,-1,:])
norm = embeds.norm(p=2, dim=-1, keepdim=True)
embeds_normalized = embeds.div(norm)
return embeds_normalizedembeds 문이 LSTM의 Output을 임베딩하기 위해 저장하는 구문이므로, 수정. 간단하게 torch.mean 메서드를 이용하여 전체 time step에 대하여 Average pool을 해주었습니다.
embeds = self.embedding(torch.mean(lstm_out, dim=1))이를 통해, 비록 Speaker encoder의 사전학습된 모델을 update하지는 못하지만, Conversion 단계에서 보다 효과적으로 음성 맥락 정보를 임베딩하기를 기대할 수 있습니다.
5. Conclusion
아쉽게도 저희 팀은 이번에는 선수가 직접 부르는 응원가를 들을 수는 없었습니다. 🥲 하지만 포기하지 않고 맞서 싸운 저희는, 어째서 이런 결과가 나왔는지 요인 탐색을 진행해보았습니다!
1️⃣ Auto-VC에서의 한국어 학습의 어려움 한국어는 영어와는 다른 발음 체계와 음운론적 특징을 가지고 있습니다. 예를 들어, 한국어의 모음 조화나 종성 발음은 영어와 다른 규칙을 가지고 있어 파인튜닝을 진행할 때 특징이 잘 학습되지 않는 경우가 많았습니다. 위와 같은 이유와 더불어 영어 음성 데이터를 토대로 사전학습된 AutoVC가 제공하는 사전학습된 모델은 한국어의 특징을 잘 학습하고 있지 않기에 추가적인 조정없이 저희가 바로 사용하기에는 어려움이 존재하였습니다.
2️⃣ 오디오 도메인에서의 학습의 어려움 음성 모델의 학습에서는 충분한 데이터를 확보하는 것이 어렵습니다. 1명의 화자를 학습시키기 위해서는 최소 1시간의 발화 데이터가 필요합니다. 또한, 모델의 개선을 통한 피드백 과정이 오래걸리기 때문에 학습 과정을 최적화하는 데 많은 시간이 걸리는 것을 확인할 수 있었습니다.
이외에도 다양한 관점에서 AutoVC를 개선하고, 한국어에서도 VC가 잘 수행되도록 Vocoder를 fine tuning하는 등의 많은 시도와 실험을 진행해보았으나, 결론적으로는 저희가 목표한 바를 이루지 못하였습니다. 발견한 실패 요인들을 바탕으로 추후 지속해서 프로젝트를 진행해보고자 합니다.
이번 deep.daiv에서 ‘야구선수의 응원가 쟁탈기’의 연구는 이렇게 진행되었습니다. 감사합니다! 👏🏻
6. Reference
- Qian, Kaizhi, et al. "Autovc: Zero-shot voice style transfer with only autoencoder loss." International Conference on Machine Learning. PMLR, 2019.
- Kong, Jungil, Jaehyeon Kim, and Jaekyoung Bae. "Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis." Advances in neural information processing systems 33 (2020): 17022-17033.
- Intro 음원 야구팬 공통 응원가 아파트 떼창!