
서비스 소개
안녕하세요, LLM을 활용한 올인원 집필 서비스 쓰담입니다. API를 호출하여 사용하기 때문에 리서치와는 다른 성격의 발표지만, LLM을 실제 프로덕트에 이렇게도 활용할 수 있구나를 봐주시면 감사하겠습니다.
소개 영상
사용자 가이드
자세한 서비스 기능과 가이드는 위 링크에서 확인하실 수 있습니다.
서비스 링크
프로젝트 기획
출판 시장 트렌드

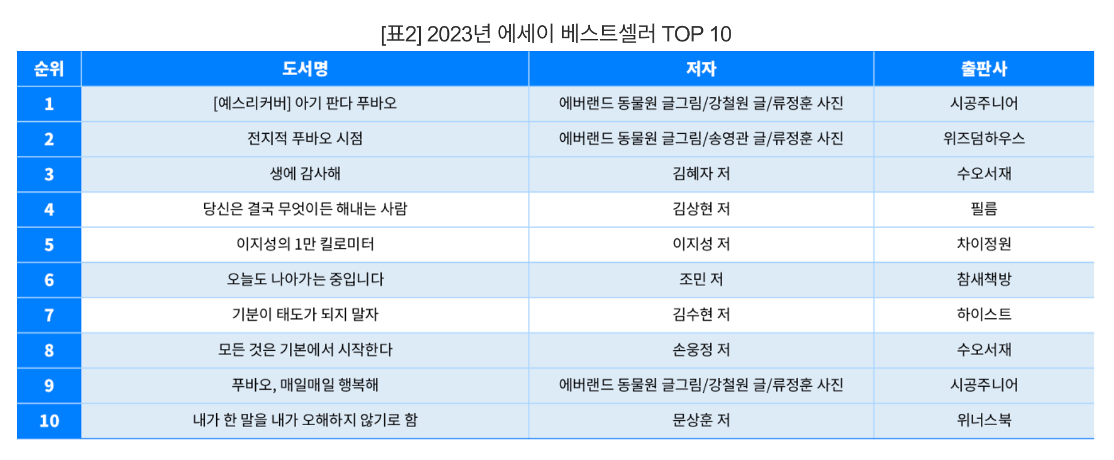
출판 시장 중에서도, 최근 에세이 시장의 트렌드는 이전과는 다른 방향으로 변화하고 있습니다. 기성 작가보다는 유명인이나 유튜버 등 인플루언서 저자들이 늘어나고 있는 추세입니다. 또한 yes24에서 공개한 자료에 따르면, 초고령화 시대를 앞두고 노년 에세이 판매도 증가하고 있습니다.
현직자 인터뷰
시장 조사를 위해 추가적으로 길벗 출판사의 편집장님과 인터뷰를 진행했습니다. 앞서 조사한 자료대로, 최근 출판사에서는 주로 인플루언서 저자 분들을 컨택하는 방식으로 섭외를 진행하고 있었습니다. 또한 책 출판의 벽 자체가 예전에 비해 낮아졌다보니 인플루언서 분들이나 일반인 분들을 대상으로 하는 기획도 고려하고 있는 것으로 확인했습니다.

저희 팀은 이러한 트렌드에 궁금증이 생겼습니다. 인플루언서나 일반인 분들 중에서는 책 출판을 처음 접하시는 분들도 많고 글쓰기 자체를 어려워하는 분들이 많을텐데, 출판사에서는 어떠한 방식으로 협업을 하고 있는지 궁금하였습니다. 실제로 책 출판 경험이 없는 분들은 어디서부터 어떻게 시작할지 모르기 때문에 방황을 많이 한다고 합니다. 때로는 편집자가 전부 봐줘야 하는 상황도 있고, 서로가 성에 차지 않아 원고가 계속 왔다 갔다 하기도 한다는 답변을 얻었습니다.
기획 의도
이렇게 책을 집필하는 과정이 어렵다는 것을 확인하였고, 이 어려움들을 어떻게 도울 수 있을지 고민하였습니다.
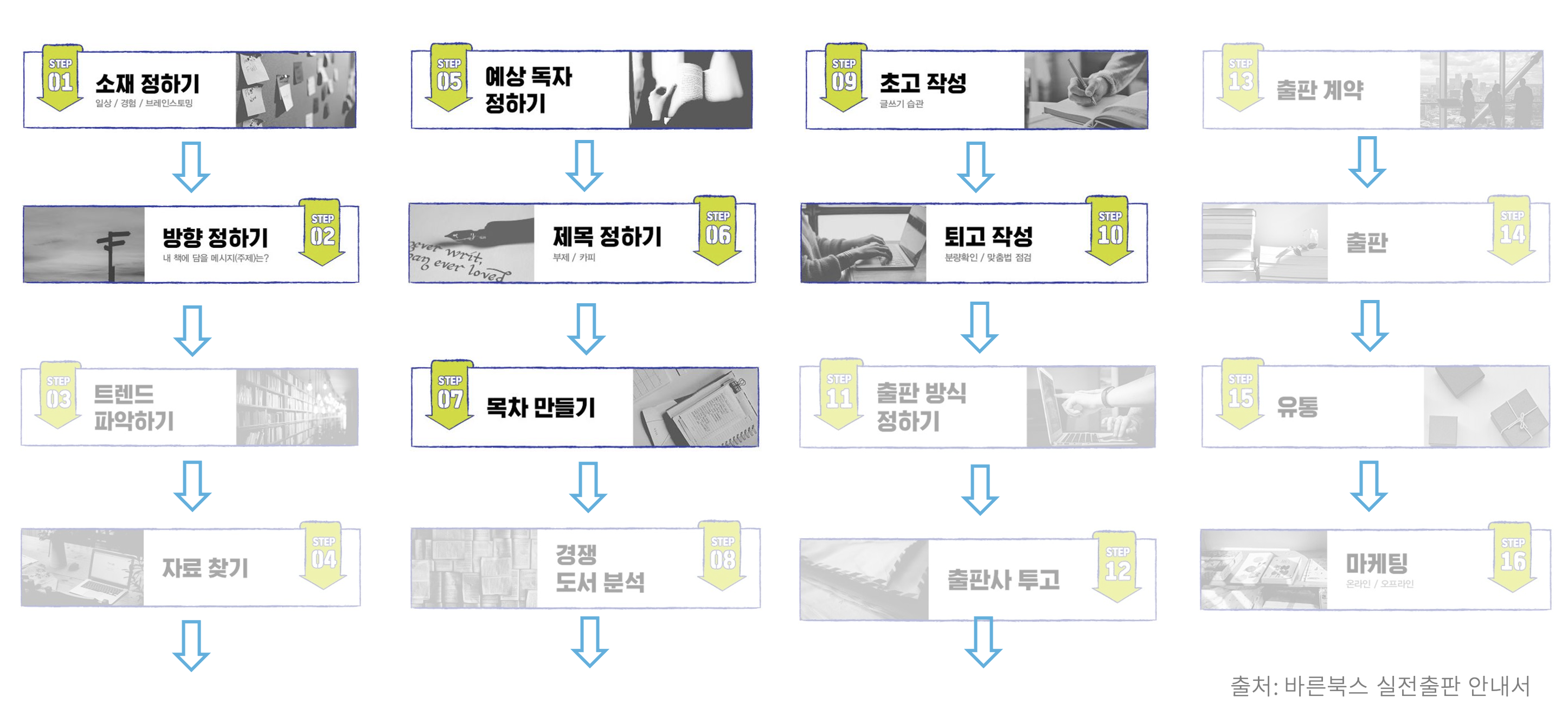
위 이미지는 바른북스 출판사에서 정리한 16단계의 출판 과정입니다. 이중 현재까지 저희가 도와주고 있는 부분을 진하게 표시했습니다. 크게 글을 쓰기 위한 뼈대를 잡는 부분과 글을 쓰는 과정, 그리고 글을 마무리하는 과정까지 도와주는 기능을 제공하고 있습니다.
자세한 기능은 서비스 소개 파트의 영상과 사용자 가이드를 참고해주시면 감사하겠습니다.
프롬프트 엔지니어링
프롬프트 팁
해당 프롬프트 팁은 정답이 아닙니다. 프롬프트 엔지니어링에는 공식이 없으며, 태스크에 따라 많은 부분이 달라지기 때문에 직접 적용해보고 효과가 좋은 부분만 참고하시면 됩니다.
- 각 모델마다 적합한 프롬프트가 다릅니다.
GPT-3.5-turbo와 GPT-4o 처럼 모델의 성능 차이가 있을 때, Claude와 GPT처럼 모델을 제공하는 주체가 다를 때 등 사용하는 모델이 달라질 때마다 적합한 프롬프트를 찾아 수정해야 합니다.
- 한국어와 관련된 태스크의 경우 Claude 사용을 시도해보세요.
Claude의 경우 GPT에 비해 확연하게 한국어를 잘합니다. GPT의 경우 웬만하면 프롬프트를 영어로 작성하는 것을 권장하지만, Claude는 태스크에 따라 한국어로 작성해도 성능이 좋은 경우가 있습니다. 물론 태스크의 세부적인 요구사항에 따라 다르기 때문에 직접 해보아야 합니다. 다만, API 비용 측면에서는 Claude의 비용이 훨씬 비쌉니다.
- LLM이 읽기 쉬운 구조가 존재합니다.
사람이 읽기 쉬운 구조가 존재하는 반면, LLM이 읽기 쉬운 구조가 존재합니다. #과 같은 마크 다운이나 XML 태그를 활용하면 더 좋은 성능을 이끌어낼 수 있습니다. XML 태그의 경우 Claude 모델에 효과적이며, 태그를 중첩해서 사용할 수도 있습니다.
- 퓨샷과 같은 예시 제공은 좋지만, 편향이 생길 가능성이 있습니다.
대부분의 가이드에서 예시를 주는 것이 좋다고 설명합니다. 분명 좋은 경우가 많지만, 태스크에 따라 편향이 생길 가능성도 있습니다. 많은 시도를 통해 적절한 예시를 주거나, 꼭 필요한 경우에만 활용하는 것을 추천합니다.
- Let’s think step by step.
매우 잘 알려진 마법의 문장입니다. 많은 논문에서 CoT(Chain of Thought)을 연구하고 있고, 최근에는 OpenAI에서도 o1-preview와 o1-mini 등의 CoT를 활용한 모델을 공개했습니다. 다만, 주의할 점은 해당 방법은 답이 명확히 존재하는 경우에만 적용되기 때문에, 답이 없는 문제에는 사용하지 않습니다.
- 어떤 태스크든 요구사항을 명확히 정의해주는 것이 중요합니다.
요구사항을 상세히 작성하는 것은 매우 중요합니다. 예를 들어 교정 및 교열 작업을 수행할 때, 단순히 교정 및 교열을 해주세요 보다는 아래와 같이 원하는 목표와 범위를 명확히 기재해주는 것이 좋습니다.
1. 교정 및 교열 범위:
- 국립국어원 한글 맞춤법 규정 기준 올바른 표기
- 띄어쓰기 (복합어와 합성어, 의존 명사와 단위성 의존 명사 등)
- 중복 표현 제거
- 앞뒤 문맥의 일관성- 출력 JSON format 설정 시, 내부에 설명을 적어주면 좋습니다.
출력의 경우, 보통 JSON 형식을 정의하여 프롬프트와 함께 입력합니다. 이때, JSON 키 값에 출력하고자 하는 내용을 함께 적으면 확연한 성능 차이를 얻을 수 있습니다.
{
"tagged_text": "교정 및 교열이 필요한 부분만 태그로 감싼 원본 텍스트",
"revision_list": [
{
"revised_text": "교정된 텍스트",
"reason": "교정 이유"
}
]
}- 출력 JSON 앞단에 더미(description) 데이터를 추가해보세요.
LLM에서 단어를 생성하는 디코더의 기본 원리는 다음 단어를 확률적으로 예측하는 것입니다. 따라서 원하는 출력 데이터 앞에, 얻고자 하는 부분을 설명하도록 하면 더 정확한 결과를 얻을 수 있습니다. 실제 데이터를 활용할 때는 앞의 데이터를 버리면 됩니다.
{
"description": "step by step으로 교정 분석을 설명해주세요.",
"tagged_text": "원본에서 교정이 필요한 부분에 태그 추가",
"revision": [,
]
}- 용어는 일관되게 사용해야 합니다.
예를 들어 퇴고 작업을 수행한다고 하면 revision, editing, proofreading 등 다양한 단어들이 존재합니다. 하나의 프롬프트 내에서는 가급적 용어를 통일하는 것이 좋습니다. 어떤 단어를 사용할지 고민된다면, Google의 Books Ngram Viewer를 활용하여 자주 쓰이는 단어를 선택하는 것이 성능이 좋을 확률이 높습니다.
- 강조할 때는 큰따옴표 보다는 마크다운 강조 표시 가 효과적입니다.
앞서 설명한 LLM이 읽기 쉬운 구조와 동일한 맥락입니다. 태스크와 세부사항에 따라 다를 수 있지만, 보통은 모델이 이해하기 좋은 마크다운 강조 표시를 사용하는 것이 효과적입니다.
- 프롬프트는 YAML 파일 등을 활용하여 따로 관리하면 좋습니다.
LangChain 등을 활용하여 코드를 작성하다보면, 프롬프트를 코드 실행 파일 내에 작성하는 경우가 있습니다. 프롬프트는 YAML 파일 등을 활용하여 따로 관리하는 것이 좋습니다. 아래 형식과 같이 버전 등을 함께 명시하고, 버전이 바뀌는 경우 새로운 YAML 파일과 코드 내 버전 숫자만 바꿔주면 편리하고 효율적으로 관리가 가능합니다.
version: "1.1"
last_updated: "2024-09-11"
description: "prompt for draft generator"
prompts:
- name: "system"
content: |
프롬프트
- name: "user"
content: |
제목:
- name: "json_format"
content: |
variables:
- name: "text"
description: "user text"
notes: >예외 처리
LLM은 아래와 같은 작동 원리로 인해, 일정한 결과를 얻기 어렵습니다.
- 통계적 패턴 학습: LLM은 방대한 양의 텍스트 데이터를 학습하여 언어의 패턴을 파악합니다.
- 확률 기반 예측: 주어진 컨텍스트를 바탕으로 다음에 올 가능성이 높은 단어나 문장을 확률적으로 예측합니다.
- 샘플링: 예측된 확률 분포에서 실제 출력할 단어를 선택하는 과정에서 무작위성이 개입됩니다.
때문에 실제 프로덕션 환경에서는 불확실성으로 인해 생기는 예외에 대한 대비를 해야 합니다. 기존에 정의한 출력 구조에서 벗어나거나, 예상하지 못한 출력이 생성되는 경우를 최대한 테스트합니다. 문제점을 찾았다면, 프롬프트 수정을 통해 최대한 해결하고, 그럼에도 생기는 문제들은 코드를 통해 예외 처리가 가능합니다.
아래 코드는 퇴고 기능의 예외 처리 예시입니다. 태그된 텍스트와 수정된 텍스트의 개수가 일치하지 않는 경우, 프론트에서 렌더링 시에 에러가 발생하기 때문에 중요하게 고려해야합니다. 이 외에도 원본 텍스트와 수정된 텍스트가 동일한 경우, 즉 수정하지 않았음에도 수정했다는 할루시네이션 현상 등도 정규 표현식을 활용해 처리합니다.
def check_revision_tag_match(
tagged_text: str,
revision_count: int
) -> bool:
tag_count = len(re.findall(r'(.*?)', tagged_text))
if tag_count == revision_count:
return True
return Falsedef compare_original_and_revised_text(
tagged_text: str,
revision_list: list
) -> (str, list):
to_remove = []
# tag 안의 원본 텍스트와 수정된 텍스트가 같은 경우 tag 제거
for idx, revision in enumerate(revision_list):
pattern = f''
if re.search(pattern, tagged_text):
to_remove.append(idx)
tagged_text = re.sub(pattern, revision["revised_text"], tagged_text)
# 퇴고 리스트에서도 제거
for idx in reversed(to_remove):
del revision_list[idx]
return tagged_text, revision_list
배치 처리
LLM 사용 시에는 API 호출 시간과 출력 생성 시간을 고려해야 합니다. 특히 입력이나 출력 텍스트가 길어지거나 요구 사항이 많아지는 경우에는 시간이 더 오래 걸립니다. 따라서 분리할 수 있는 태스크라면, 가능한 배치 API를 활용하는 것이 좋습니다. (OpenAI의 경우 배치 API가 더 저렴하다는 장점도 있습니다.)
# 각 블록 배치 처리 (빈 블록 제외)
llm_results = await chain.abatch([
{
"json_format": json_format,
"text": blocks[idx]["text"],
} for idx in target_block_indices if idx < len(blocks)
])
예를 들어 쓰담의 퇴고 기능에서, 3문장 기준으로 기존에 10초 가량 걸리던 시간을 4초 이내로 줄일 수 있었습니다. 텍스트 길이가 길어지고 수가 많아질수록, 병렬 처리의 효율은 더욱 올라가게 됩니다.
# 3문장 기준
{'blocks_result': [{'tagged_text': '당신은 이렇게 물을 수 있다.', 'revision_list': [{'revised_text': '당신은', 'reason': "'당신'은 높임말이므로 '이렇게 물을 수 있다'와 같은 평어체와 함께 사용하는 것은 어색합니다. 문맥에 따라 '귀하는', '선생님은', 또는 '여러분은' 등으로 바꾸거나, 뒷부분을 '이렇게 물으실 수 있습니다'로 수정하는 것이 좋습니다."}]}, {'tagged_text': '"모든 위인이 정말 그렇게 추악할까요?" 크게 비판 받을 만한 점 하나 없는 사람들도 분명 있을 겁니다.', 'revision_list': [{'revised_text': '"모든 위인이 정말 그렇게 추악할까요?"', 'reason': '문장 부호 수정 (문장 끝 물음표 뒤의 따옴표 위치 조정)'},]},, {'tagged_text': '오늘 날에는 많은 사람들이 물질적이거나 외향적인 것을 중요하게 여긴다. 하지만 우리는 이럴때일수록 내면의 중요함을 생각해야 한다.', 'revision_list': [,,]}]}
11.481539249420166
===============
{'blocks_result': [{'tagged_text': '당신은 이렇게 물을 수 있다.', 'revision_list': [{'revised_text': '당신은 이렇게 물을 수 있습니다.', 'reason': '문장의 끝에 높임말을 사용하여 문체의 일관성을 유지하고 독자에 대한 예의를 갖추었습니다.'}]}, {'tagged_text': '"모든 위인이 정말 그렇게 추악할까요?" 크게 비판 받을 만한 점 하나 없는 사람들도 분명 있을 겁니다.', 'revision_list': [{'revised_text': '크게 비판받을 만한 점 하나 없는', 'reason': "띄어쓰기 수정: '비판받다'는 한 단어로 붙여 써야 합니다."}]}, {'tagged_text': '오늘 날에는 많은 사람들이 물질적이거나 외향적인 것을 중요하게 여긴다. 하지만 우리는 이럴때일수록 내면의 중요함을 생각해야 한다.', 'revision_list': [,,]}]}
3.772392988204956서버리스 아키텍처
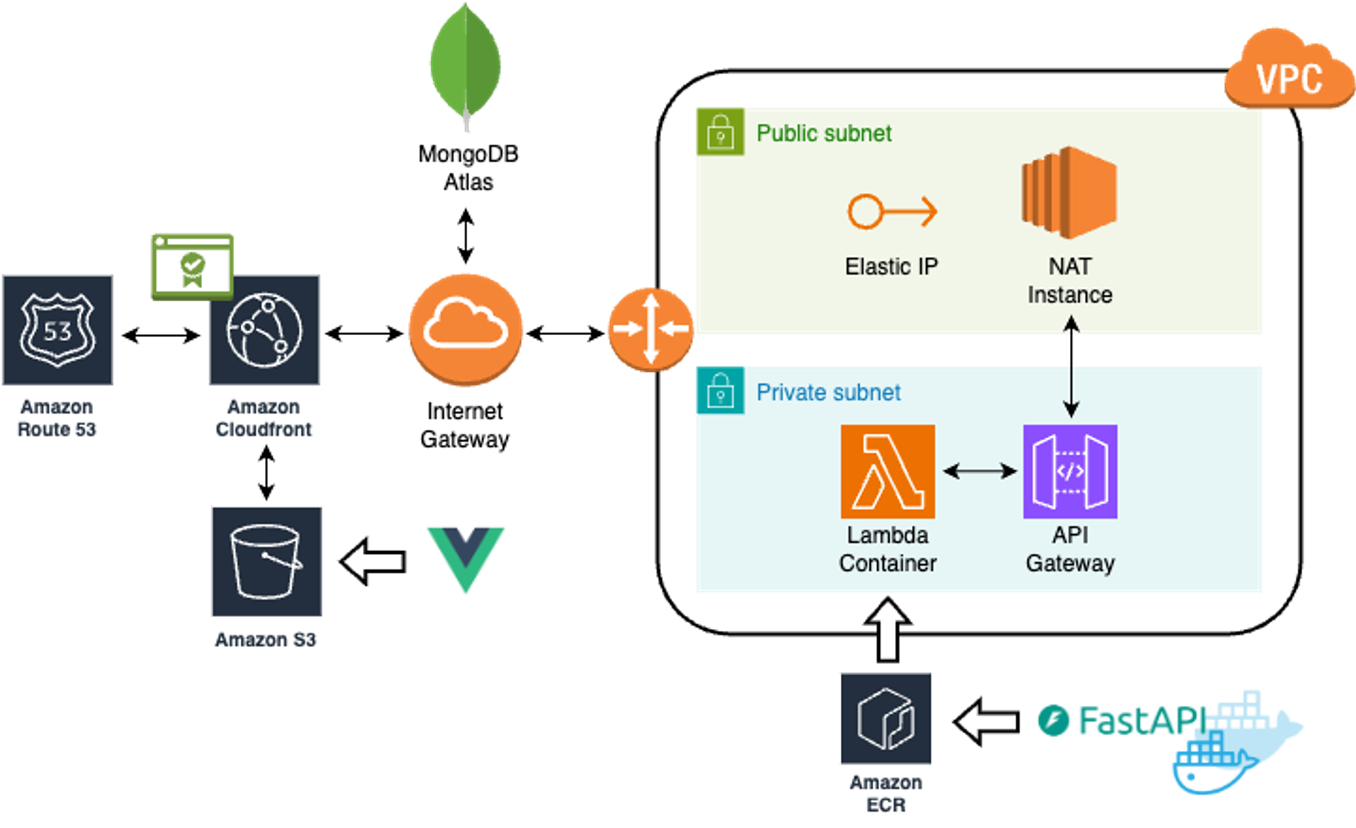
서버리스란?
서버가 없는 것은 아니지만, 개발자가 서버를 직접 관리하지 않아도 되는 서비스를 말합니다. 조금 더 자세히 설명하자면, 서버를 프로비저닝하거나 애플리케이션 확장 측면을 관리할 필요가 없는 클라우드 컴퓨팅 모델을 뜻합니다. 프로비저닝은 예를 들어 CPU, GPU 용량이나 성능, 스토리지 크기 등을 사용자 요구에 맞게 설정하는 것을 뜻합니다. AWS EC2와 같은 서버에서는 해당 요구 사항들을 직접 설정하고, 트래픽이 많아지면 서버를 확장하거나 마이그레이션을 진행하지만 서버리스에서는 따로 관리할 필요가 없습니다.
구축 과정
위 아키텍처 이미지를 구성하기까지 많은 고민이 있었지만, 최종 구축 방법에 대해 설명하겠습니다. 구축 시 고려사항은 비용, 보안, 관리 용이성 등입니다. CloudFront + S3 (Vue) + Lambda (private) + NAT Instance (public) + Atlas (IP 화이트리스팅)
자세한 과정은 아래와 같습니다.
- AWS IAM 유저 생성 및 권한 부여, AWS CLI 설정
- Lambda용 Docker 이미지 빌드 및 ECR 설정
- Lambda 함수 생성 및 API Gateway 연결
- VPC 서브넷 구성 및 인터넷 게이트웨이, 라우팅 테이블 연결
- NAT Instance 설정
- Lambda VPC 연결
- Atlas 연결 및 IP 화이트리스팅
- S3 프론트 빌드 파일 업로드 및 웹 호스팅, 버킷 정책 부여
- ACM 인증서 발급, CloudFront, route53 설정
- Github Actions CI/CD 구축
장단점
해당 아키텍처의 장점은 초기 구축만 완료되면, 서버 관리 측면에서 크게 신경쓸 부분이 없습니다. 트래픽이 증가하더라도 AWS Lambda에서 자동으로 유연하게 대처하기 때문입니다. 따라서 일반적인 서버처럼 오토스케일링 등을 고려할 필요가 없습니다. 같은 관점에서, 데이터베이스도 MongoDB Atlas를 사용하였습니다. 데이터베이스 이중화(레플리카 셋 등)를 기본적으로 제공하고, 마찬가지로 서버가 터지는 등의 고려 사항을 걱정하지 않아도 됩니다. 단점으로는 디버깅이 어렵습니다. 서버에 문제가 생기는 경우, 보통 Lambda 함수와 연결된 CloudWatch로 로그를 확인합니다. 로그를 볼 수는 있지만, 매우 불편하고 정확한 에러가 기록되지 않는 경우도 많습니다. 이외에도 콜드 스타트, AWS 권한 문제, Stateless로 동작해야하는 점 등의 단점이 존재합니다.
그럼에도 일반적인 서버에 비해 합리적인 비용(AWS 프리티어 기준 한 달에 1만원 가량의 비용, 서비스마다 상이하지만 유저 1000명 이하 기준)과 유지보수 측면에서 유리하기 때문에, 서비스 특성을 잘 고려하여 활용한다면 많은 이점을 얻을 수 있습니다.
코드 버전 관리
해당 파트에서는 어떠한 방식으로 코드를 관리하는지 소개하겠습니다. 코드 관리에 정답이 있는 것은 아니며, 팀의 색깔과 서비스 특성에 맞게 구성하면 됩니다. 보통 코드 관리의 경우 Git과 Github를 활용하며, 브랜치나 PR(Pull Request) 등의 기능을 통해 협업합니다. 아래 예시는 쓰담 팀의 Git Rules 일부입니다.
Git Branch 전략 (Github Flow)
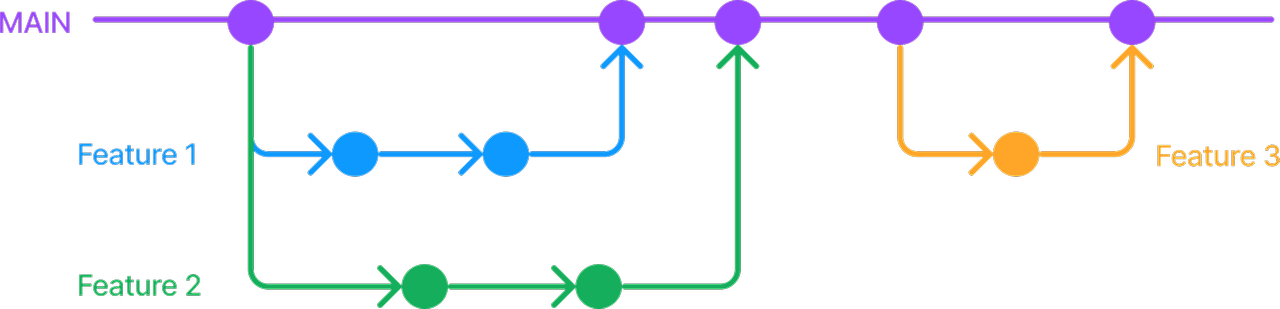
- main에서 새로운 branch를 생성한다. 이때, 브랜치 명은 어떤 일을 할지 자세하게 작성한다.
- 생성한 브랜치에서 작업이 끝나면 main으로 PR을 작성한다.
- 팀원들의 PR 리뷰가 끝나면 main으로 merge 한다.
- 버전 업데이트 시 main에서 release로 CI/CD를 거쳐 실제 서버에 반영한다.
Commit Convention
- feat: 새로운 기능 추가
- fix: 버그 수정
- docs : 문서 수정
- refactor : 코드 리팩토링
- chore : 빌드 업무 수정, 패키지 수정
- remove : 코드/파일 삭제
SWM-티켓 번호/작업 유형: 아래 예시대로 메시지 작성, “:” 뒤에 띄어쓰기 필수 git commit -m "SWM-68/feat: ”

Branch 규칙
작업 유형
- feature
- fix
- refactor
- bug
PR 규칙
- 이슈 당 1개씩 생성
- 코드 리뷰 후 main 브랜치에 merge
### 🔗 연관된 JIRA 티켓
-
### 📝 작업 내용
- 로그인 기능 열심히 개발함
### ✅ 참고 사항
추가적인 공유가 필요한 사항은 CommentCI / CD
CI / CD 란?
애플리케이션 개발 단계부터 배포 단계까지의 모든 단계를 자동화하는 것을 뜻합니다. CI(Continuous Integration)의 경우 지속적인 통합이라는 의미를 가지고 있으며, 코드 변경이나 버그 수정 등이 주기적으로 빌드 및 테스트를 통해 코드 레퍼지토리에 통합되는 것을 뜻합니다. CD(Continuous Delivery, Deployment)의 경우 지속적인 배포라는 의미를 가지고 있으며, CI 단계에서 테스트된 코드를 배포 환경에서 검증하고 실제 프로덕션 환경으로 배포하는 것을 뜻합니다.
Github Actions
CI/CD 툴로는 주로 Jenkins와 Gihub Actions가 사용됩니다. 이 외에도 다양한 툴들이 많지만, Github Actions가 다른 툴에 비해 쉽고 빠르게 구성이 가능하기 때문에, 시간적 효율을 고려하여 해당 툴을 활용하였습니다.
Github Actions의 핵심 개념들만 간단히 정리하고, 실제 쓰담 서비스에는 어떻게 적용했는지 살펴보겠습니다.

- Event
- Workflow를 실행시키는 트리거
- PR이나 push 등에 의해 발생
- 수동으로 정의된 일정이나 Github 제공 API 호출로도 발생
- Workflow
- 특정 Event 발생 시, 수행하고자 하는 행위를 정의하는 파일
- 레포지토리 .github/workflowsd 디렉토리에 yml 파일로 한 개 이상의 Job 정의 가능
- Job
- 하나의 Runner에서 실행되는 Workflow 단계 중 하나
- 여러 Step을 가지고 있으며 각 Step은 순서대로 실행
- 기본적으로 각 Job은 종속성 없이 병렬 실행
- 종속성 설정 시 해당 Job이 끝날 때까지 기다렸다가 실행
- Step
- Job을 수행하기 위해 필요한 행위 정의
- 행위 정의 방식 (순서대로 실행)
- Command 작성
- Script로 actions 정의하여 사용
- Github Marketplace에 정의된 actions 사용
- Actions
- 복잡하거나 자주 반복되는 작업을 미리 정의해 놓은 Application
- 직접 정의 가능, Github Marketplace에 이미 많은 Actions 자료 존재
- Runner
- 트리거 된 Workflow를 실행하는 서버(인스턴스)
- 한 번에 하나의 Job 수행
실제 구축 환경
쓰담 팀의 CI/CD 구축 목적은 배포 과정 자동화였습니다. 본래는 코드를 통합하는 과정에서 오류가 일어나지는 않는지 자동으로 테스트(유닛 테스트, 통합 테스트 등)하는 과정이 포함되어야 하지만, 해당 부분은 생략하였습니다. 구축된 Github Actions는 크게 프론트엔드와 백엔드 배포로 분리됩니다. Github 레포지토리에서 release 브랜치로 Push 혹은 Pull Request 등을 실행할 시, 코드 변경을 감지하여 해당 부분 배포를 자동으로 진행합니다.
백엔드 배포의 경우 미리 정의한 prod 버전의 docker 이미지를 빌드하고, AWS ECR로 push합니다. ECR(Elastic Container Registry)은 컨테이너 이미지를 저장, 공유 및 배포할 수 있는 AWS 서비스입니다. 이후 ECR에 저장된 이미지를 Lambda 함수로 업데이트를 진행합니다.
프론트엔드 배포의 경우 Vue3 코드를 빌드하고, S3로 업로드합니다. S3에서는 해당 파일로 정적 웹 사이트 호스팅을 합니다. 이때 실제 배포 환경에서는 각 유저의 콘텐츠가 CloudFront 캐시에 저장되어 있는 상태이기 때문에, 해당 캐시를 지우고 새로운 정보를 업데이트하여야 합니다. 따라서 마지막으로 CloudFront 무효화 작업까지 진행합니다.
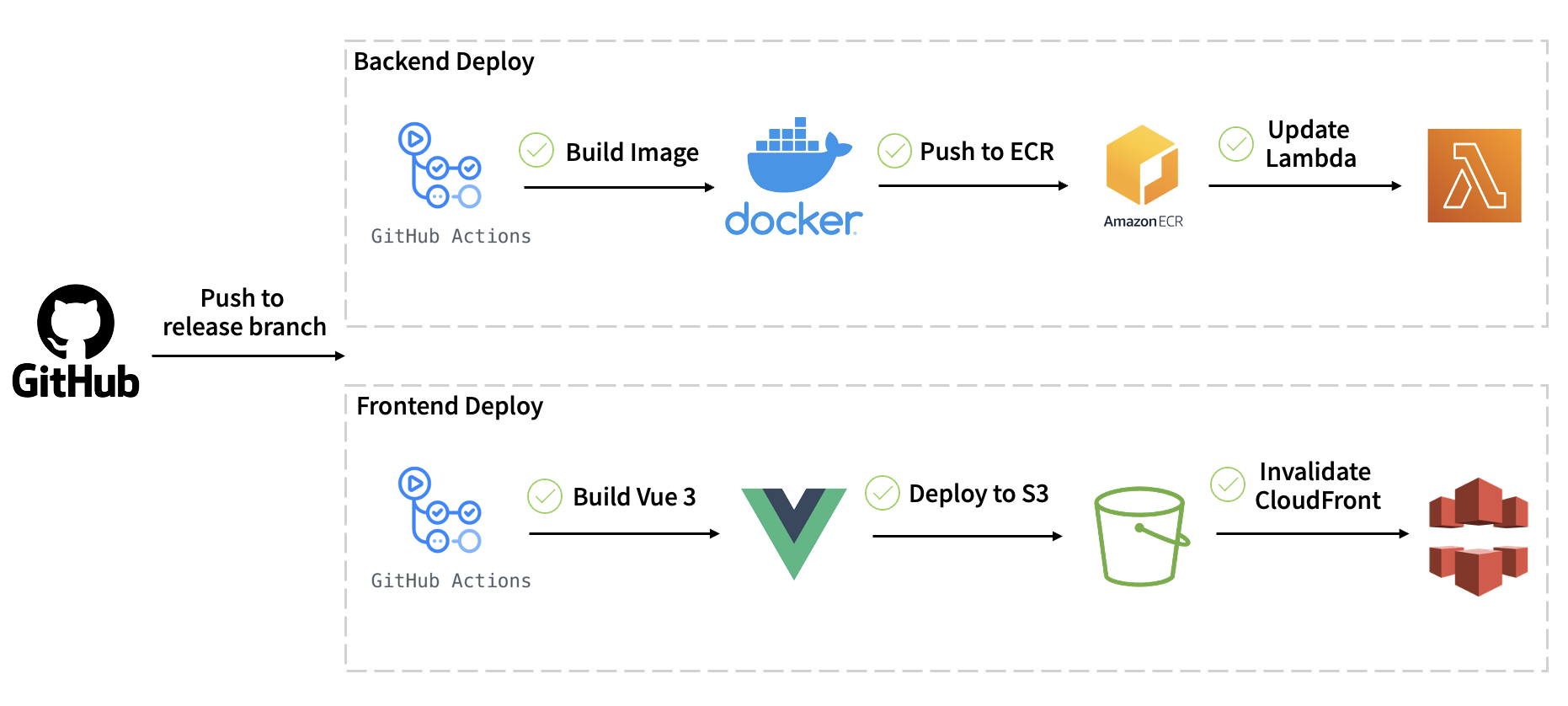
Backend Deploy 코드
name: Deploy Lambda Container
on:
push:
branches: [ release ]
paths:
- 'backend/**'
pull_request:
branches: [ release ]
paths:
- 'backend/**'
env:
AWS_REGION: (값 입력)
ECR_REPOSITORY: (값 입력)
LAMBDA_FUNCTION_NAME: (값 입력)
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${}
aws-secret-access-key: ${}
aws-region: ${}
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
- name: Build, tag, and push image to Amazon ECR
if: github.event_name == 'push' && github.ref == 'refs/heads/release'
env:
ECR_REGISTRY: ${}
IMAGE_TAG: ${}
run: |
cd backend
docker build -f dockerfile.prod . -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG \
--build-arg DB_PROD_URL="${}"
(관련 환경 변수들 이어서 입력)
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
- name: Update Lambda function
if: github.event_name == 'push' && github.ref == 'refs/heads/release'
run: |
aws lambda update-function-code \
--function-name $LAMBDA_FUNCTION_NAME \
--image-uri ${}/$ECR_REPOSITORY:${}Frontend Deploy 코드
name: Deploy Frontend to S3 and Invalidate CloudFront
on:
push:
branches: [ release ]
paths:
- 'frontend/**'
pull_request:
branches: [ release ]
paths:
- 'frontend/**'
env:
AWS_REGION: (값 입력)
S3_BUCKET: (값 입력)
CLOUDFRONT_DISTRIBUTION_ID: (값 입력)
jobs:
build-and-deploy-frontend:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Use Node.js
uses: actions/setup-node@v3
with:
node-version: '20'
- name: Install dependencies
run: |
cd frontend
npm ci
- name: Create .env file
run: |
cd frontend
echo "VUE_APP_API_HOST=${}" >> .env
(관련 환경 변수들 이어서 입력)
- name: Build
run:
cd frontend
npm run build
env:
VUE_APP_API_HOST: ${}
(관련 환경 변수들 이어서 입력)
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${}
aws-secret-access-key: ${}
aws-region: ${}
- name: Deploy to S3
if: github.event_name == 'push' && github.ref == 'refs/heads/release'
run: |
aws s3 sync frontend/dist s3://${} --delete
- name: Invalidate CloudFront
if: github.event_name == 'push' && github.ref == 'refs/heads/release'
run: |
aws cloudfront create-invalidation --distribution-id ${} --paths "/*"프로젝트 및 이슈 관리
애자일, 스크럼 (Scrum)
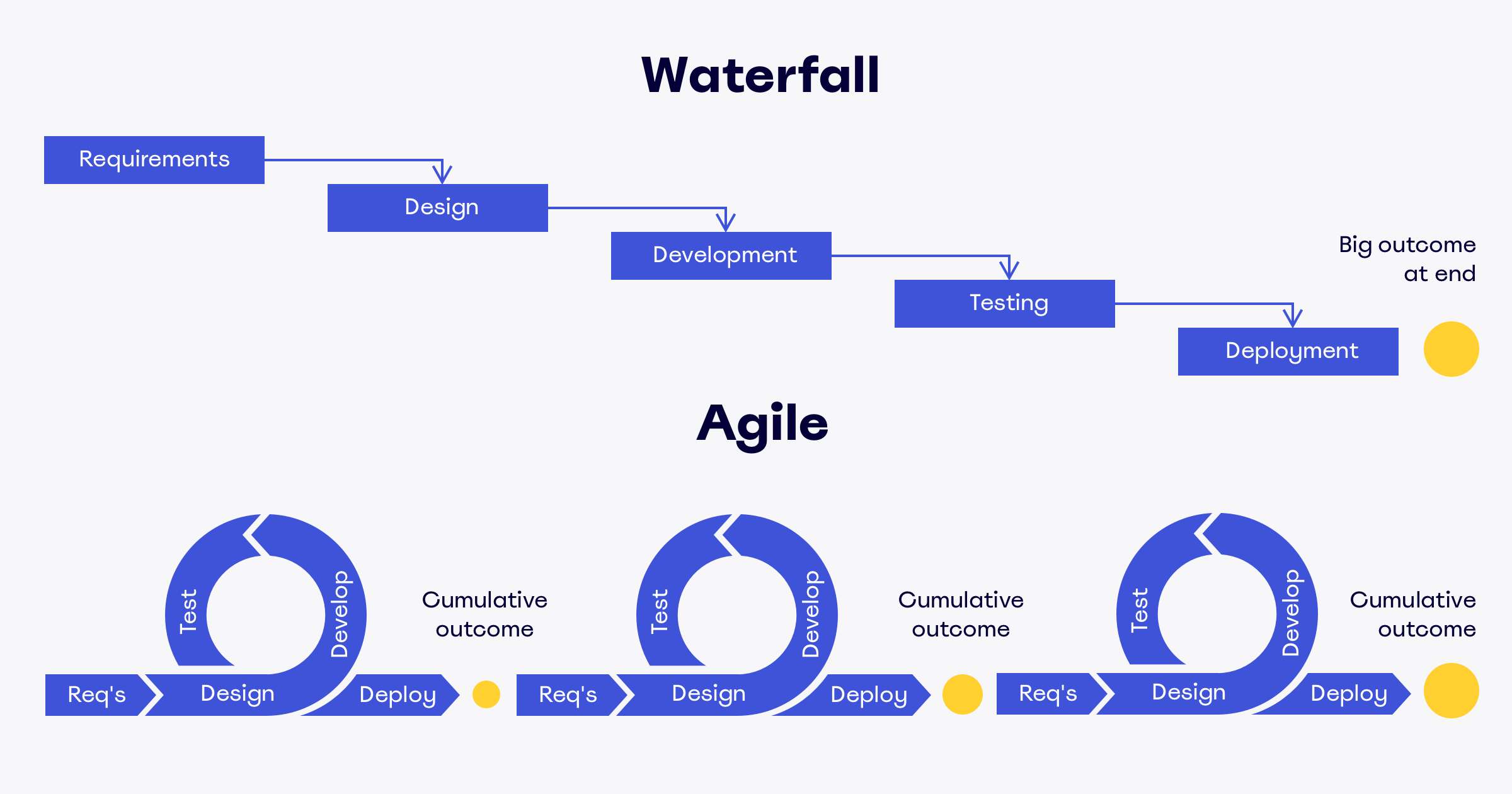
애자일 방법론은 짧은 주기의 개발 단위를 반복하여 하나의 큰 프로젝트를 완성해 나가는 방식입니다. 애자일의 핵심은 변화에 잘 대응하여, 유연하게 일을 진행하자입니다. 애자일 방법론의 대표적인 실행 방법 중 하나가 바로 스크럼입니다. 스크럼은 스프린트(Sprint)라고 하는 작은 주기를 반복하여 프로젝트를 진행합니다.
Scrum Master, Product Owner 등의 역할이나 제품 백로그, 스프린트 백로그, 데일리 스크럼, 회고 등 다양한 용어들이 존재하지만 발표의 취지에 벗어나므로 자세한 설명은 생략하고, 쓰담 팀이 어떤 방식으로 진행하는지만 간략히 소개하고 넘어가겠습니다.
Jira
Jira는 Atlassian이 개발한 이슈 트랙킹 툴입니다. 다양한 업무를 티켓(백로그) 단위로 나누고, 해당 티켓들을 에픽 등의 단위로 묶어 프로젝트를 진행할 수 있습니다.
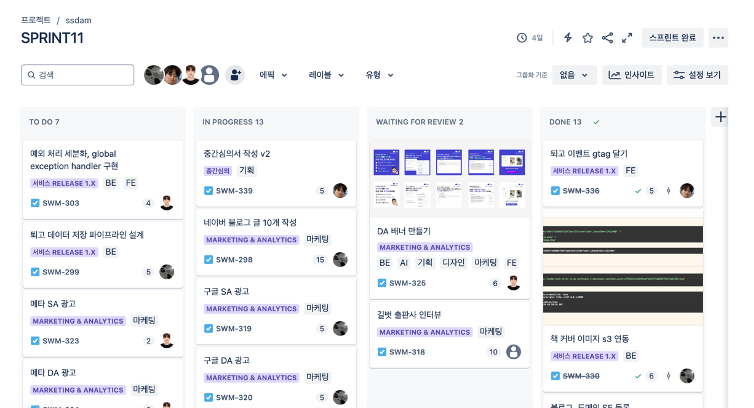
아래 이미지와 같이 주로 칸반 보드를 통해 해야할 일과 완료된 일을 구분합니다. 쓰담 팀은 TO DO, IN PROGRESS, WAITING FOR REVIEW, DONE 총 4가지 단계로 구분되어 있으며, 해당 단계는 자유롭게 커스터마이징이 가능합니다. 각 티켓은 Github의 브랜치와 연동하는 것도 가능합니다.
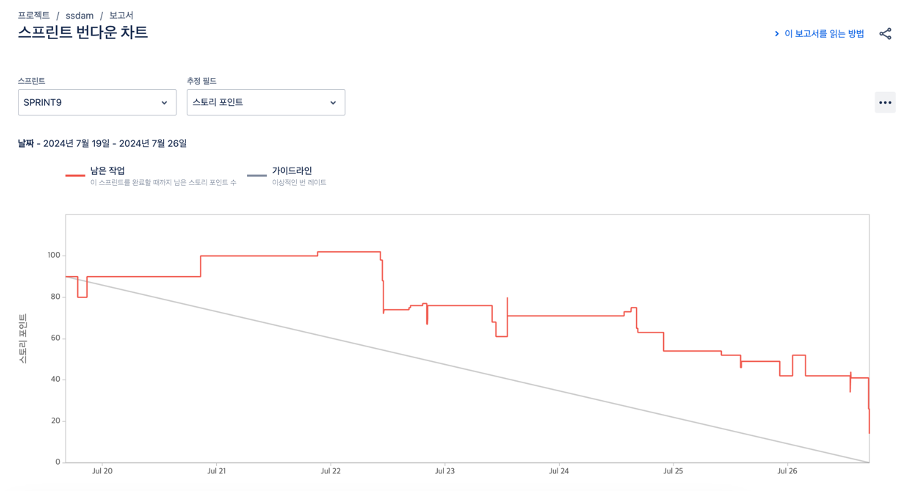
각 스프린트 별로, 계획했던 대로 일을 잘 진행했나를 보고서로 확인할 수 있습니다. 보고서에는 여러 종류가 존재하지만, 주로 아래와 같은 번다운 차트나 누적 흐름 다이어그램을 활용합니다.
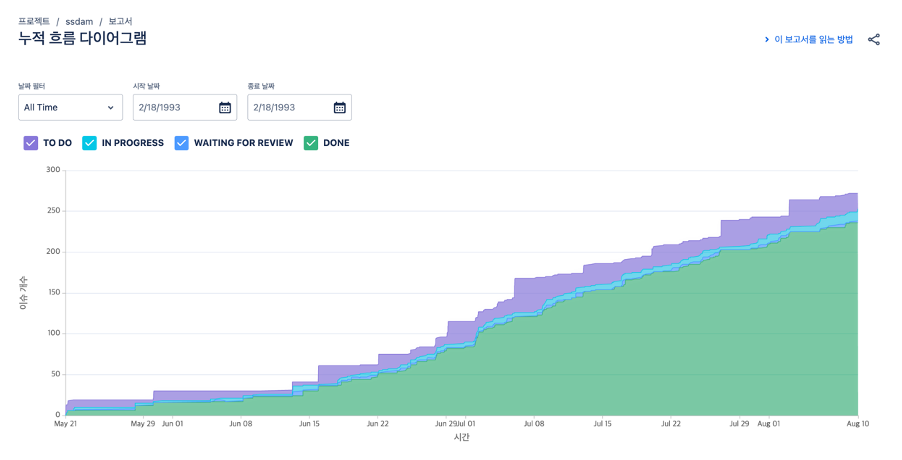
처음 Jira를 사용하게 되면, 정말 번거롭고 해당 툴을 왜 사용하는지 이해가 가지 않을 수 있습니다. 하지만 스프린트 2~3번을 거치고 나면, 효율적인 일처리를 위한 정말 좋은 툴이라는 것을 알게됩니다. 지금은 Jira 없이 프로젝트를 진행하는 게 상상이 가지 않습니다. 약 6개월 동안 애자일 방법론을 적용해본 경험과 공부한 내용에 따르면, 애자일에 정답은 없습니다. 각 프로젝트와 팀의 성격에 맞게 작업 속도를 조절하고, 유연하게 대처하는 것이 핵심입니다.
마케팅
마케팅은 크게 Paid와 Viral로 나누어 진행하였습니다. 마케팅도 깊게 들어가면 내용이 많지만, 마찬가지로 발표의 취지에 벗어나므로 간략하게 소개드리도록 하겠습니다.
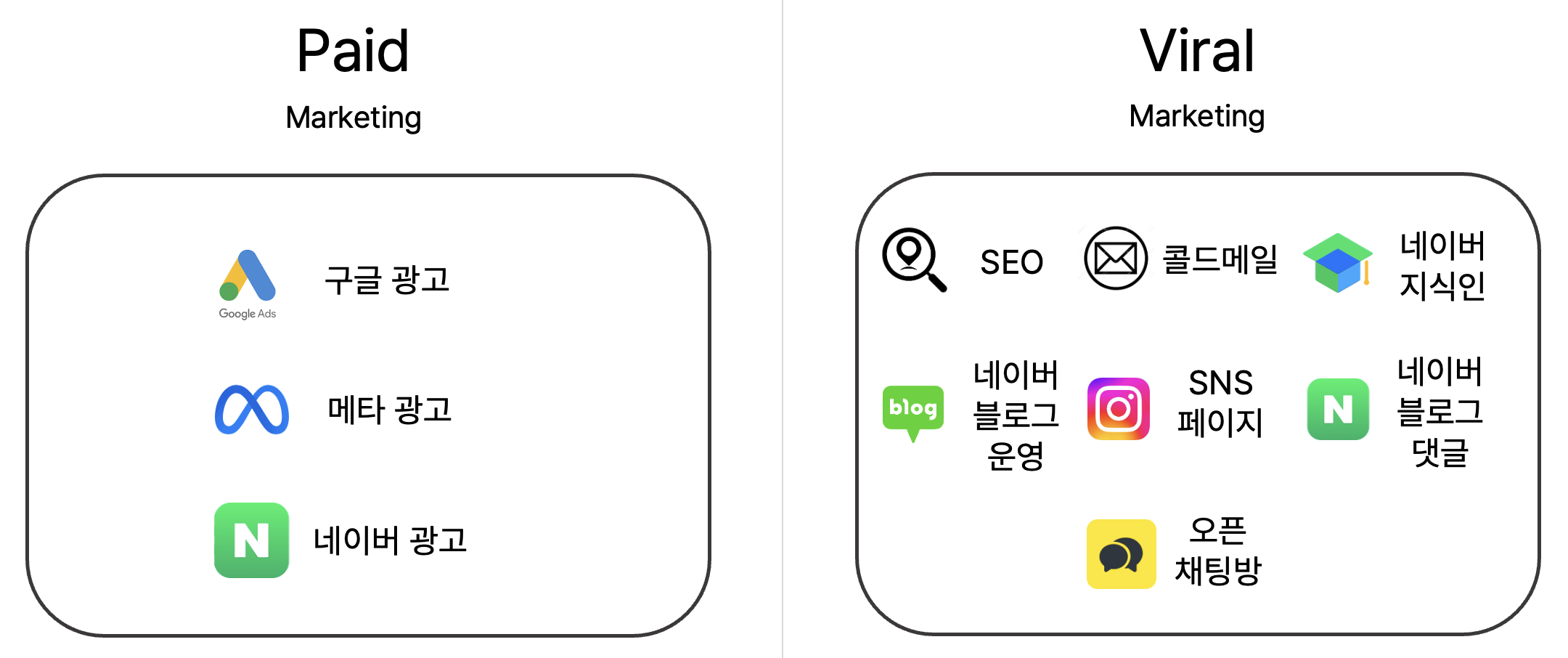
Paid Marketing
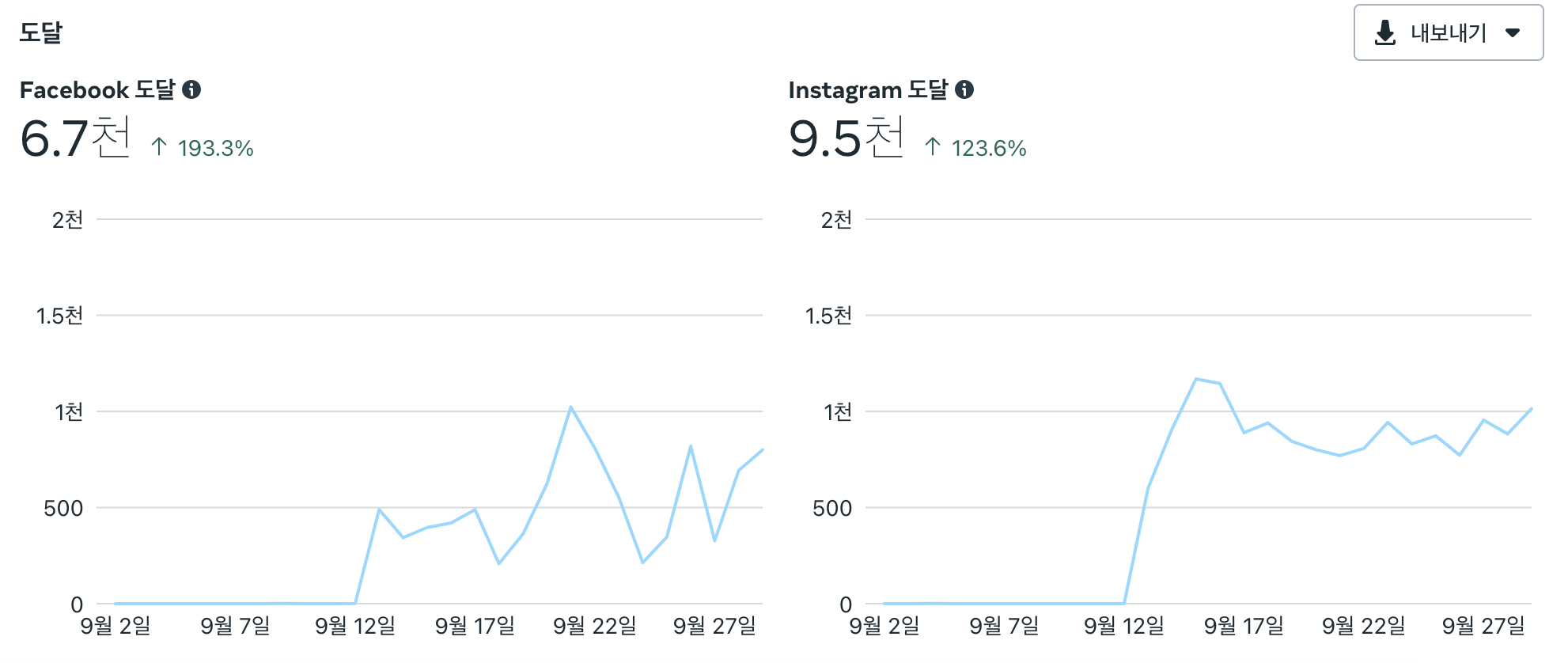
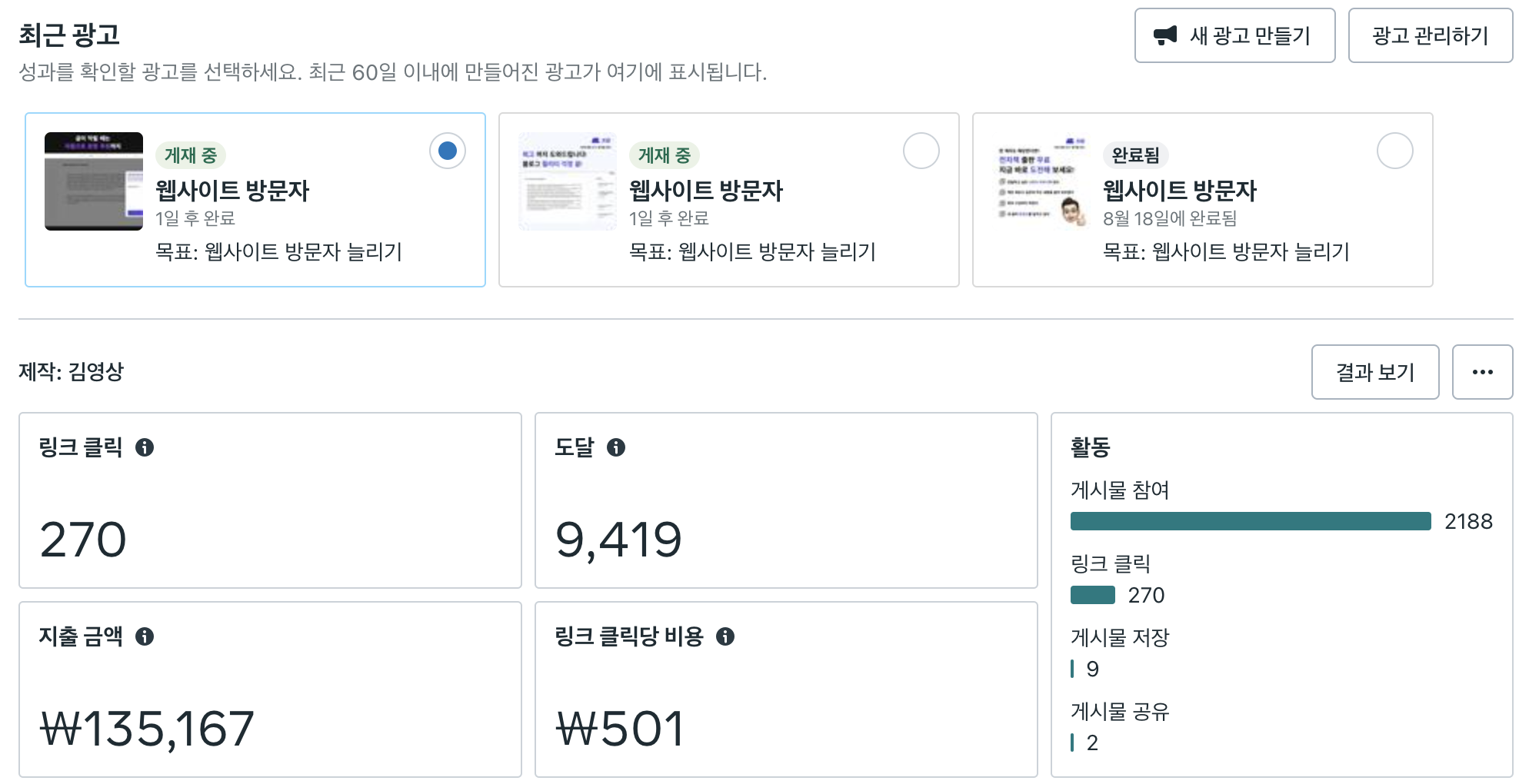
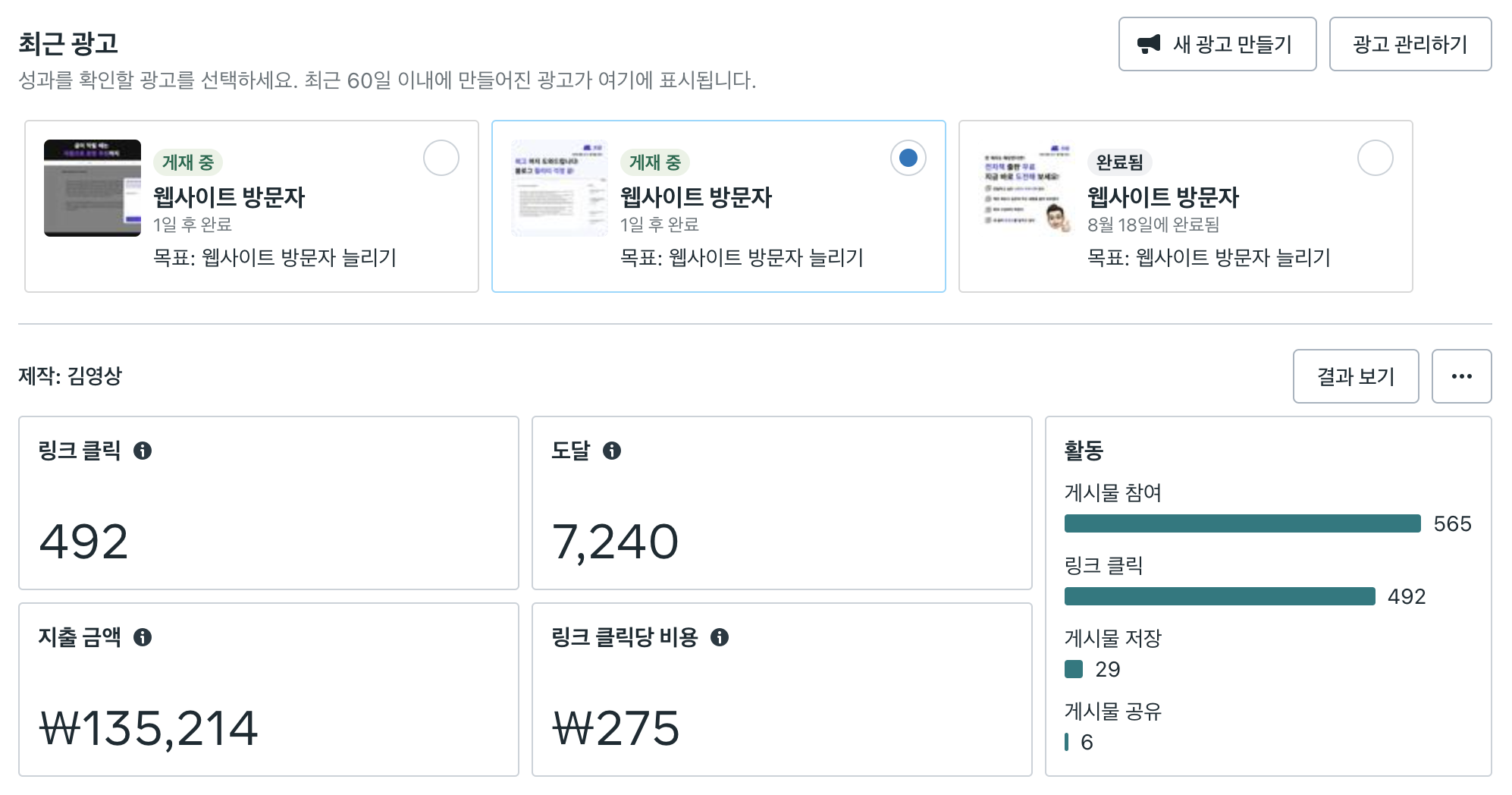
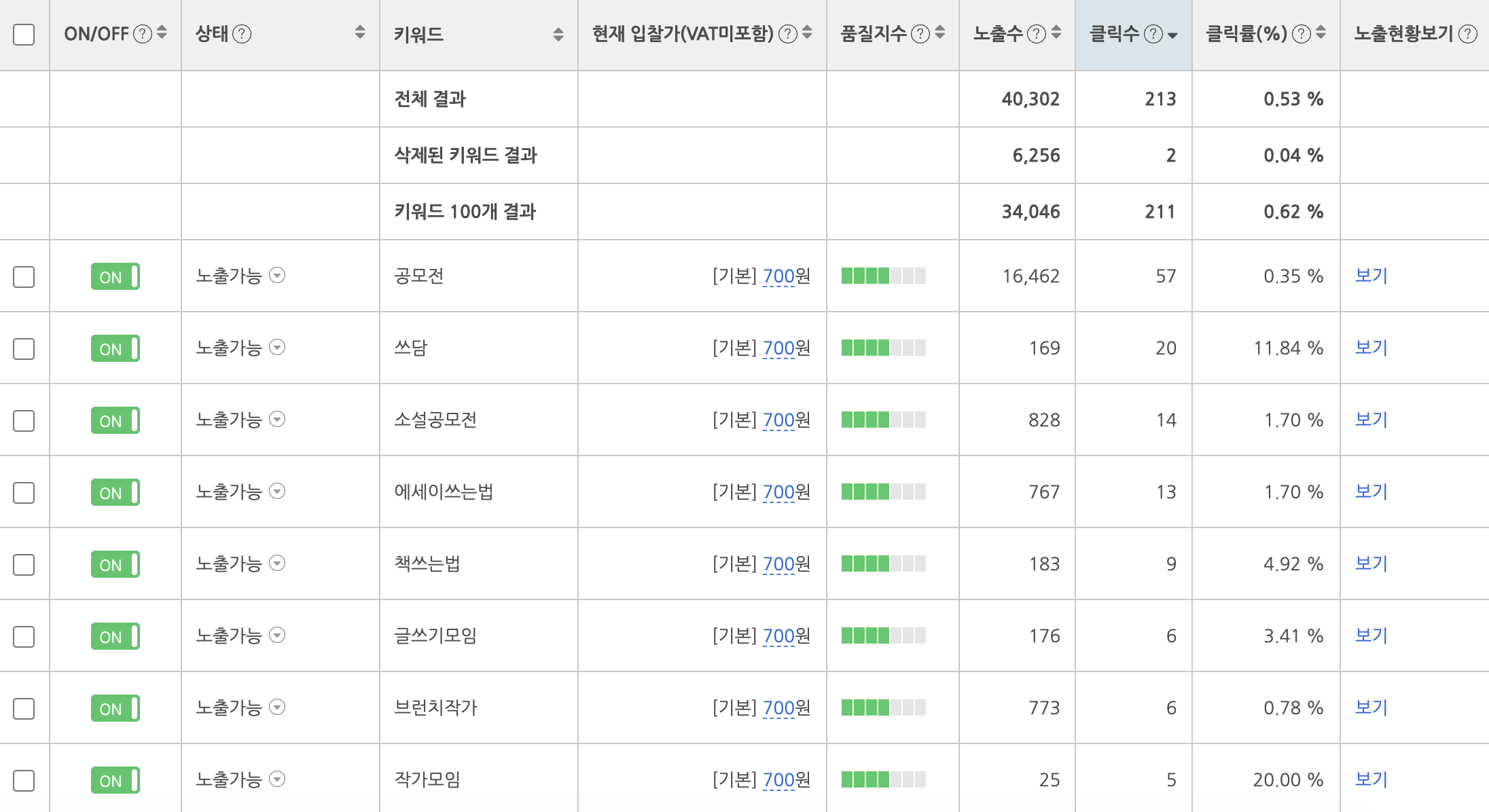
페이드 마케팅이란 Paid + Marketing으로 돈을 지급하는 마케팅을 의미합니다. 대표적인 광고 채널로 Google, Meta(Facebook + Instagram), Naver 등이 있습니다. 각 마케팅 채널마다 특성도 다르고, 각 채널 안에서도 활용할 수 있는 방안이 매우 다양하기 때문에, 서비스 특성에 따라 효율적으로 활용하여야 합니다.
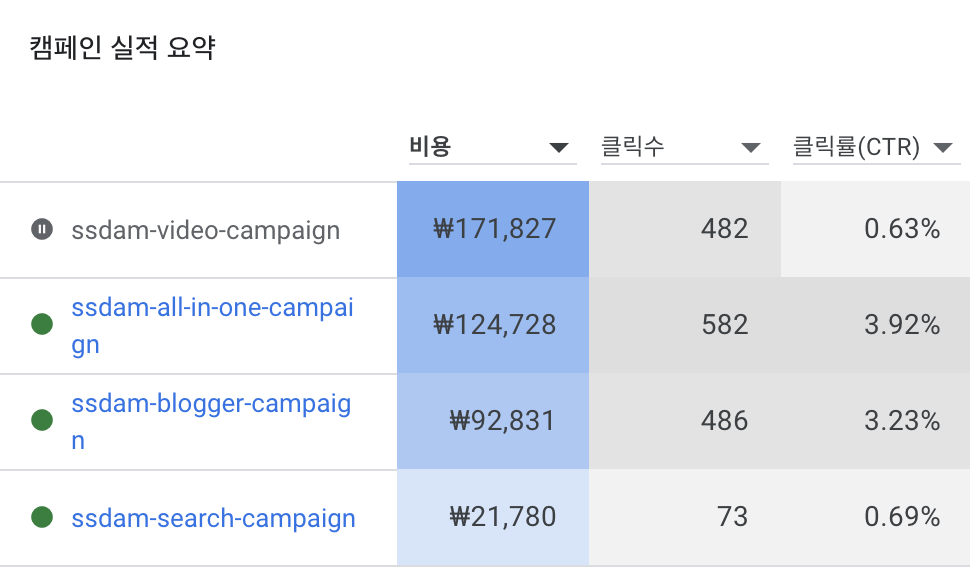
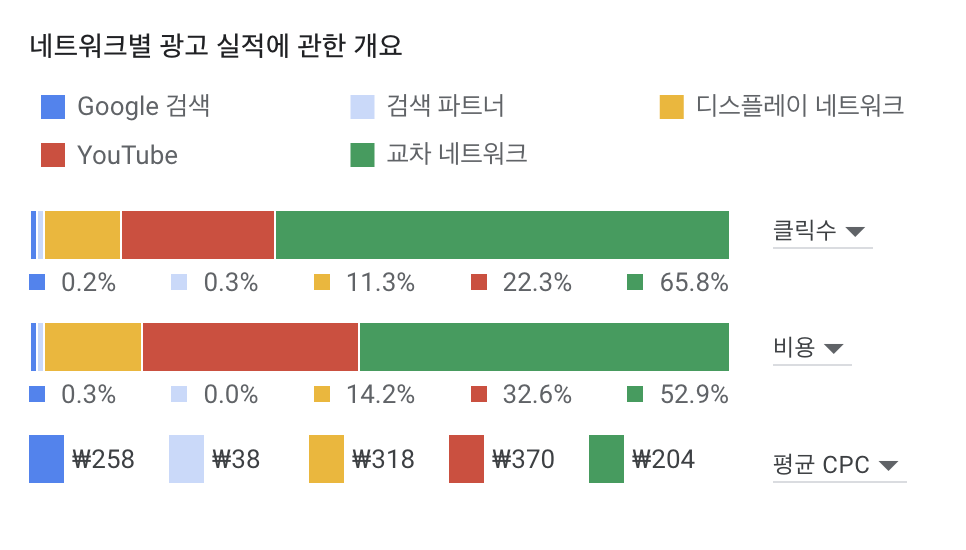
광고를 게재하는 방식은 크게 Video, Search, Display 등으로 나눌 수 있습니다. 쓰담 팀에서는 앞서 서비스 소개에 있던 홍보 영상, 아래와 같은 홍보 이미지, 다양한 텍스트 등을 통해 광고를 진행했습니다.

Google Ads
Meta Ads
Naver 검색 광고
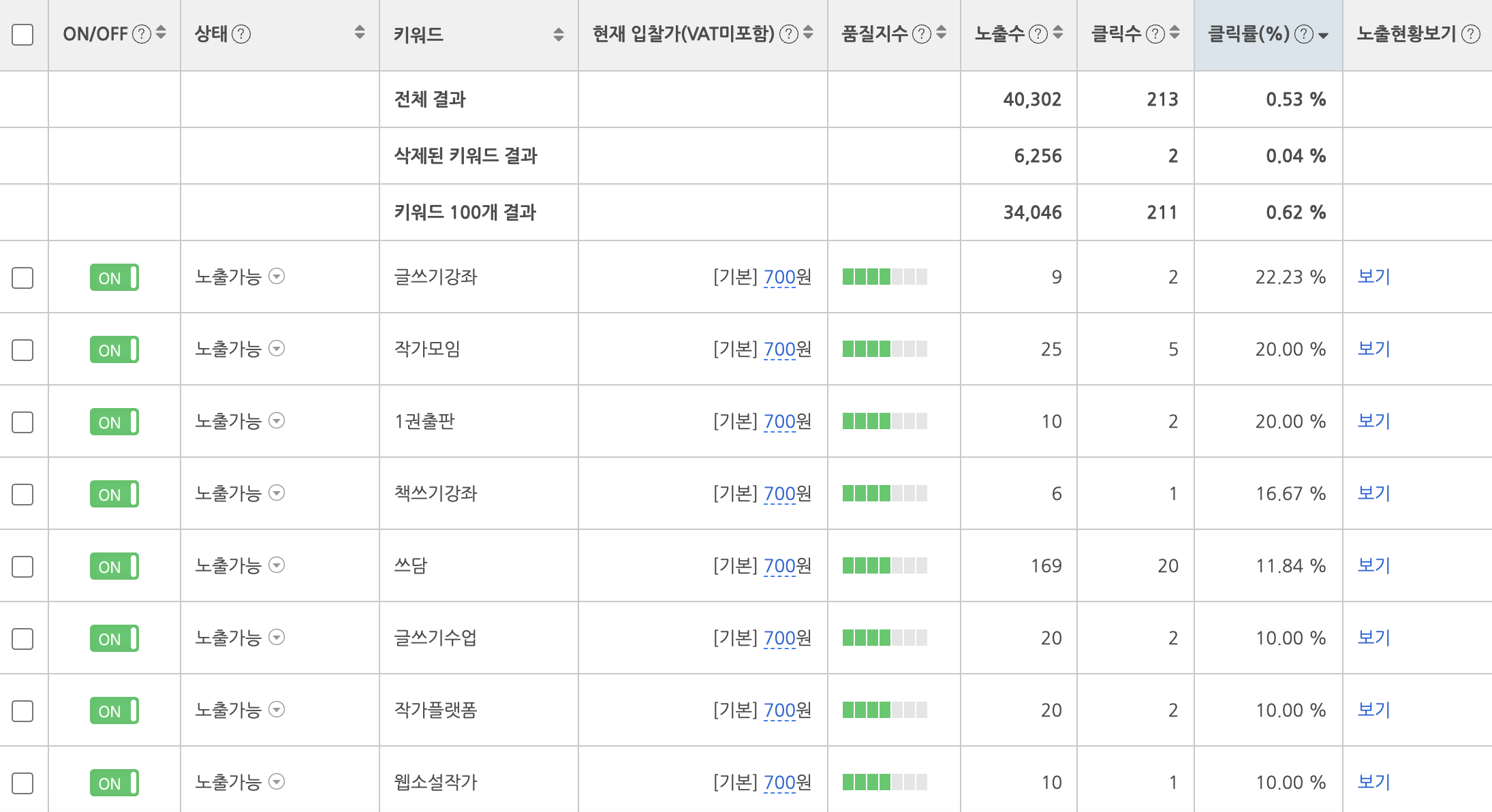
Viral Marketing
바이럴 마케팅은 제품이나 서비스가 소비자들 사이에서 자발적으로 전파되길 기대하는 마케팅 전략입니다. 앞서 소개한 페이드 마케팅의 경우 많은 비용이 들어가기 때문에, 바이럴 마케팅의 경우 비용 없이 홍보 가능한 방법들을 최대한 활용했습니다.
네이버 블로그
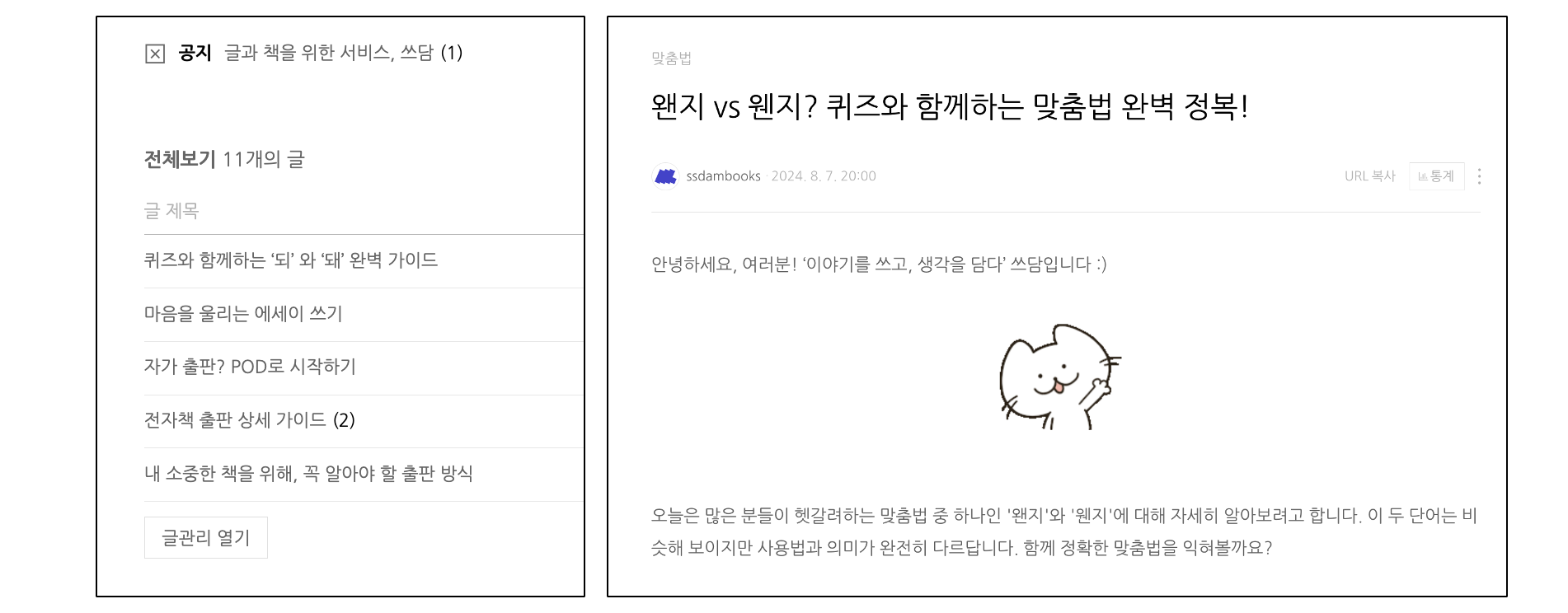
네이버 지식인
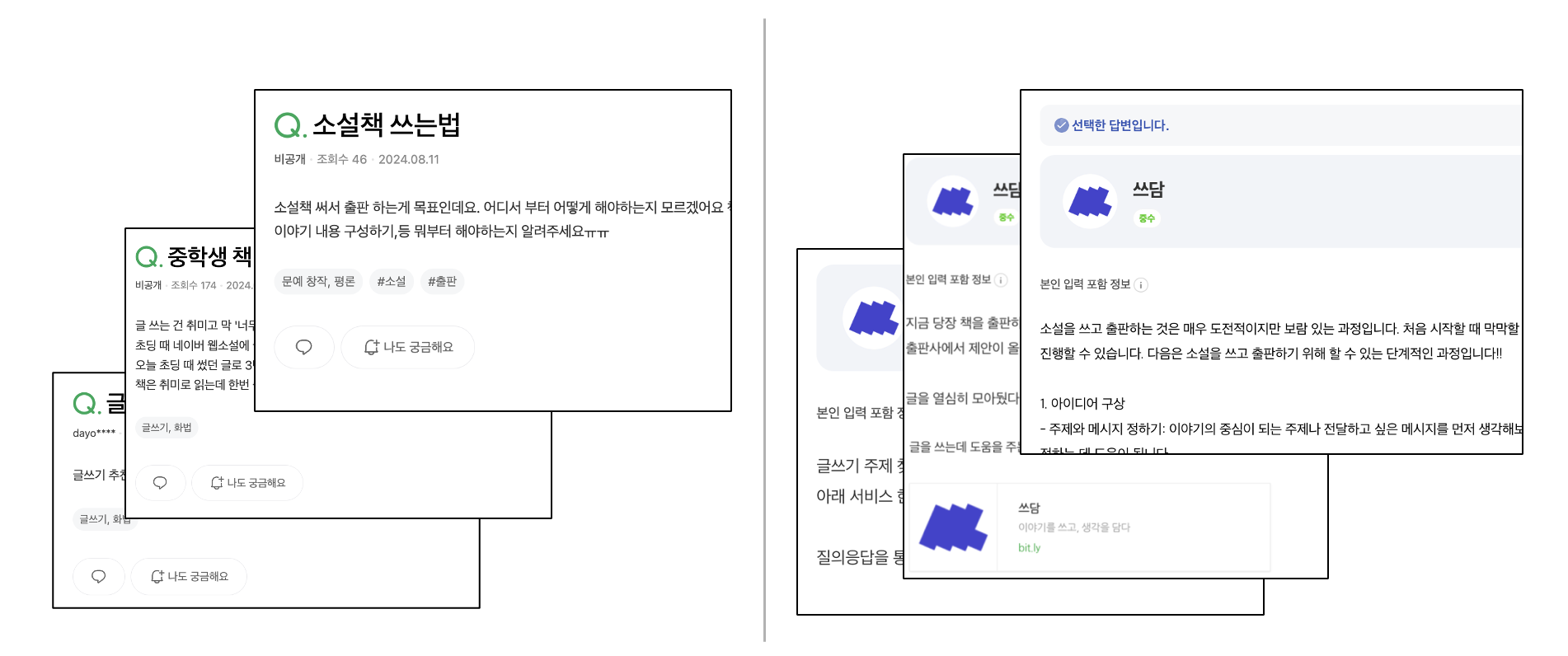
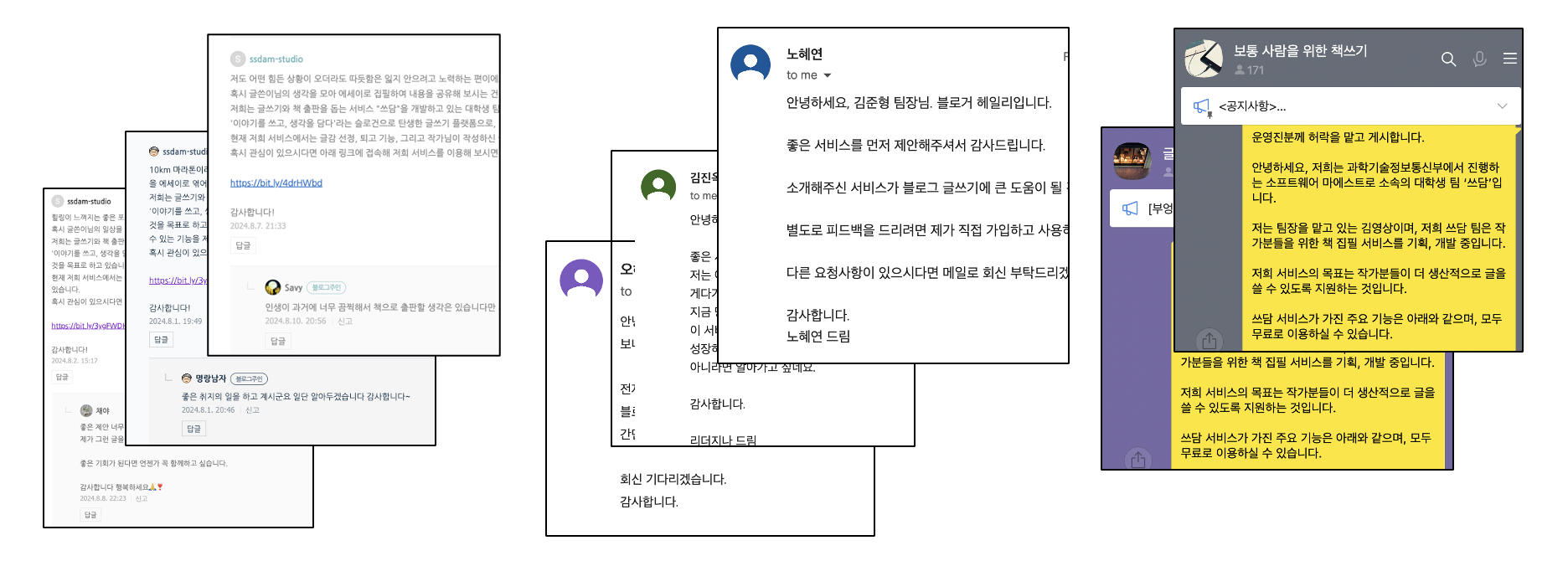
블로그 댓글, 콜드 메일, 오픈채팅방
GA4 (Google Analytics 4)
수많은 광고와 정보가 넘쳐나는 시대에, 마케팅으로 좋은 성과를 얻는 것은 어려운 일입니다. 단순히 많은 돈을 투자하는 것만으로는 좋은 성과를 얻기 어렵기 때문에, 다양한 방법과 소재를 활용해보고 분석하는 과정이 필요합니다.
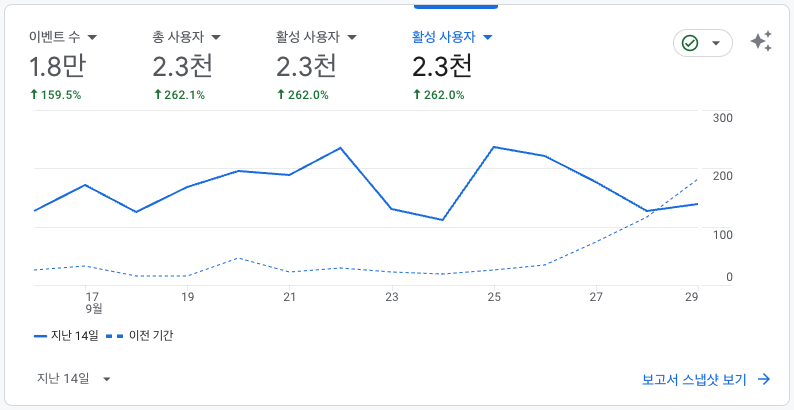
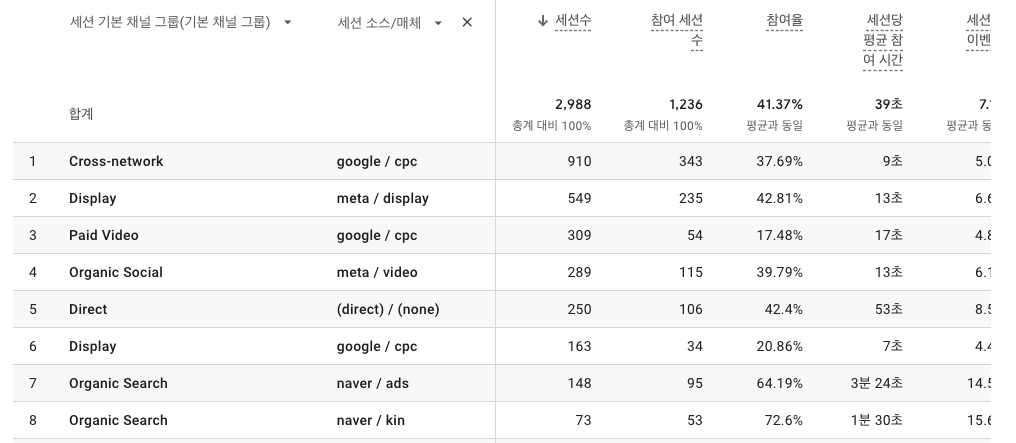
GA4와 함께 UTM 태그, Vue3(프론트)-gtag 등을 활용하여 유입 경로를 분석할 수 있습니다.

아래 예시처럼 소스나 매체 등을 나누어 UTM 태그를 활용할 수 있습니다. 소스/매체 별로 만들어진 URL로 접속하면, GA4와 프론트에서 해당 접속을 인식하여 분석합니다.
Platform source medium campaign UTM url bitly
네이버 블로그 naver blog content_blog https://ssdam.ink?utm_source=naver&utm_medium=blog&utm_campaign=content_blog https://bit.ly/3Wj5Bnq
네이버 지식인 naver kin seo_kin https://ssdam.ink?utm_source=naver&utm_medium=kin&utm_campaign=seo_kin https://bit.ly/3WDJMQQ
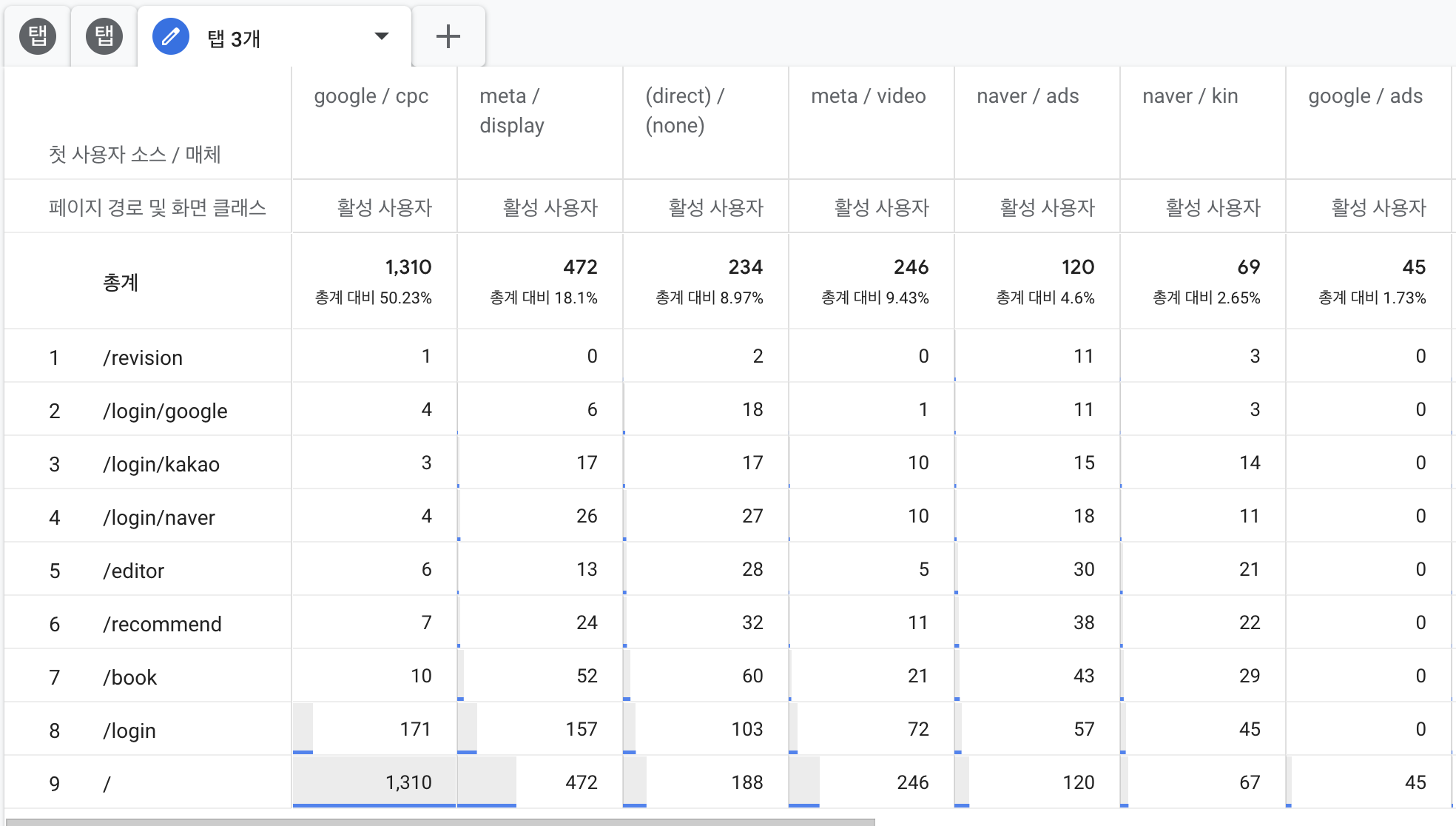
위 이미지처럼 매체별 유입 페이지를 분석할 수도 있습니다. 해당 기능을 활용하면 어떤 매체가 효율이 좋은지, 매체별 서비스 기능 유입이 어느 정도 효율을 보이는지 등 다양한 분석이 가능합니다.
결과 및 향후 계획
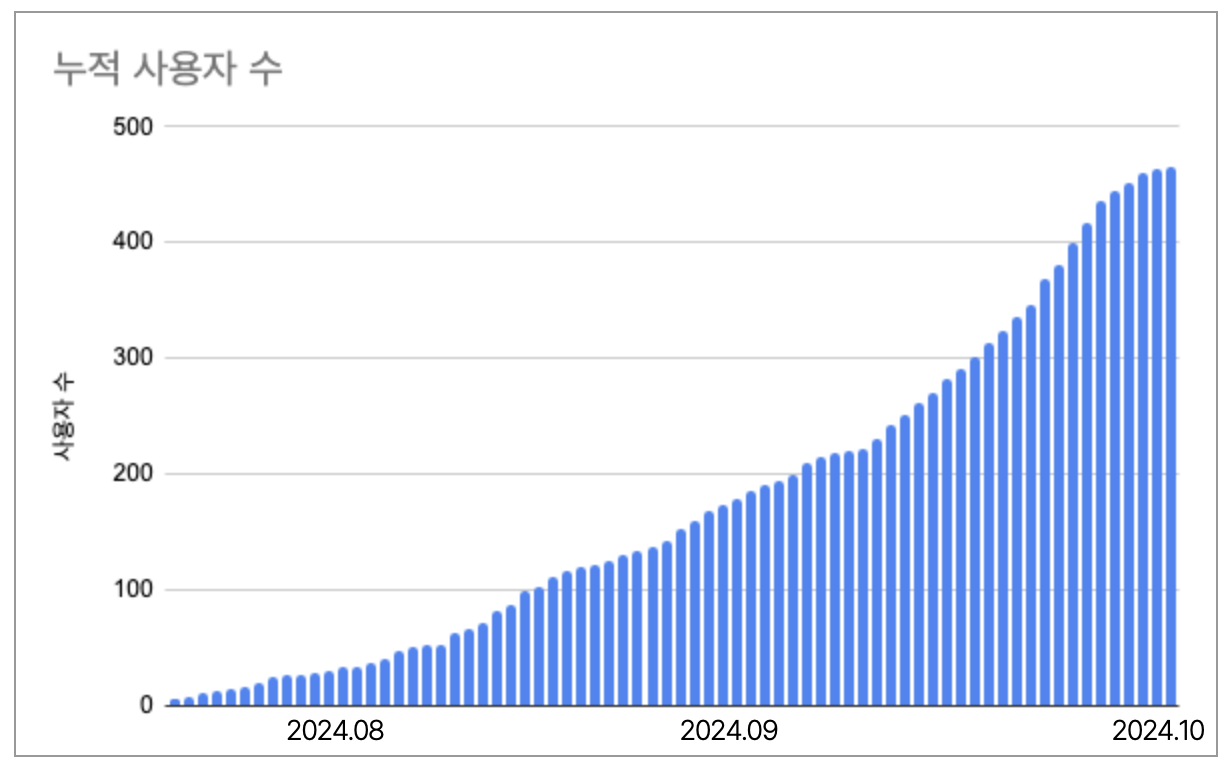
쓰담 서비스는 6월 중순부터 개발을 시작하여 7월 말 MVP를 출시하였고, 지속적인 업데이트를 진행 중입니다. 10월을 기준으로 450명 가량의 가입자 수를 달성하였습니다. 앞으로는 쓰담 서비스로 4주만에 출판하기 등의 프로그램을 운영하며, 사용자 분들과 직접적인 소통을 통해 지속적으로 서비스를 개선하려고 합니다.
궁금한 점 있으신 분은 부담 없이 아래 메일로 연락 주시면 감사하겠습니다. 커피챗도 환영입니다!
레퍼런스
프롬프트 엔지니어링 <프롬프트 엔지니어의 업무일지> (강수진 저) → product.kyobobook.co.kr OpenAI Platform Prompt Engineering Guide – Nextra Applied LLMs - What We’ve Learned From A Year of Building with LLMs LLM From the Trenches: 10 Lessons Learned Operationalizing Models at GoDaddy Prompting Fundamentals and How to Apply them Effectively Bender, E. M., Gebru, T., McMillan-Major, A., & Mitchell, M. (2024). Should we respect LLMs → Should We Respect LLMs? A Cross-Lingual Study on the Influence of... Lin, Z., Liu, Z., & Wang, W. Y. (2023). Large Language Models Understand and Can be Enhanced by Emotional Stimuli → Large Language Models Understand and Can be Enhanced by Emotional Stimuli Hao, S., Shinn, N., Siegel, N., & Xu, H. (2023). Adaptive Planning from Feedback with Language Models → AdaPlanner: Adaptive Planning from Feedback with Language Models Wang, Z., Cai, H., Hao, J., Tian, Y., Wen, C., & Zhang, M. (2023). Prompting with Pseudo-Code Instructions → Papers with Code - Prompting with Pseudo-Code Instructions Zhang, Y., Jiang, H., Xiao, T., & Wu, Q. (2024). Is Temperature the Creativity Parameter of Large Language Models → Is Temperature the Creativity Parameter of Large Language Models?
서버리스 아키텍처 Serverless를 선택한 이유(Lambda, Altas) AWS Lambda 고오급 튜토리얼 - 1 AWS VPC 설정 가이드 + AWS Lambda에 연결하기 (시리즈3) AWS를 이용한 클라우드 네이티브 어플리케이션 인프라 구축 (5) - NAT Gateway → NAT Instance 로 대체해서 비용 절약하기(FinOps) step by step AWS Lambda/CDK - Docker - Fastapi를 통해 서버리스 백앤드 배포하기(1) AWS Lambda/CDK - Docker - Fastapi를 통해 서버리스 백앤드 배포하기(3) AWS Route 53 / ACM 을 활용한 사설 도메인 연결 및 HTTPS 적용 undefinedAWSundefined Lambda에서 Timeout 걸릴 때 해결 가능한 방법 알아보기 undefinedAWSundefined IAM 사용자 생성하는법 - 액세스 키 발급 undefinedAWSundefined ECR 시작하기 Vue2를 AWS S3에 배포하고 운영해보자 undefinedAWSundefined ACM 인증서 발급 (Route 53, 가비아) undefinedAWSundefined 7. CloudFront로 HTTPS (SSL) 설정하기 & ACM 에서 인증서 만들기 🌐 IP 기초 (사설IP / 공인IP / NAT) 개념 정말 쉽게 정리 🌐 NAT(Network Address Translation) 이란 무엇인가? 🌐 IP 클래스 · 서브넷 마스크 · 서브넷팅 계산법 💯 총정리 🌐 CIDR 개념 쉽게 이해해보자 & 계산법 undefinedAWSundefined 📚 AWS CLI 설치 & 등록 방법 - 쉽고 빠르게 설명 undefinedAWSundefined 📚 장기 자격 증명(Access Key) & 임시 자격 증명(AssumeRole) 사용법 undefinedAWSundefined 📚 아마존 웹 서비스 구조 (Region / AZ / Edge Location / Cache) undefinedAWSundefined 📚 클라우드 용어 정리 (고가용성 / 장애내구성 / 확장성 / 탄력성) undefinedAWSundefined 📚 VPC 개념 & 사용 - 인프라 구축 undefinedSubnet / Routing / Internet Gatewayundefined undefinedAWSundefined 📚 NAT Gateway → NAT Instance 대체해서 비용 절약하기 undefinedAWSundefined 📚 Route53 개념 원리 & 사용 세팅 💯 정리 undefinedAWSundefined 📚 S3 정적 웹 사이트 호스팅 + 도메인 설정 Manage Connections with AWS Lambda Set Up a Network Peering Connection Atlas M0 (Free Cluster), M2, and M5 Limits Serverless Instance Limits VPC 연결 Lambda 함수에 대한 인터넷 액세스 활성화 - AWS Lambda AWS 람다 고급 튜토리얼-2: 곰프로의 블로그 AWS NAT 인스턴스의 가성비 확인 How to assign a static IP address to AWS Lambda using NAT instance
CI/CD GitHub Actions 이해 - GitHub Docs Github Action 사용법 정리 Github Action에 대한 소개와 사용법
프로젝트 및 이슈 관리 Scrum (스크럼) 이해하기 undefinedAgileundefined JIRA를 활용한 협업(1부) undefinedAgileundefined JIRA를 활용한 협업(2부) 애자일(agile)이란 무엇인가? <스크럼> (켄 슈와버, 마이크 비들 저) → product.kyobobook.co.kr
마케팅 Paid 마케팅 정의와 Paid 마케팅을 해야 하는 이유 바이럴 마케팅이란 무엇인가? 뜻, 계수, 장&단점, 예제, 종류, 채널 등 총정리 인바운드 vs 아웃바운드 마케팅 인바운드 마케팅 vs 아웃바운드 마케팅 undefinedGA4undefined1. 구글 애널리틱스 4 시작하기 - 특징과 장점 - 분석마케팅 GA4 매거진 ② GA4 설치 방법 총정리 GA4 자유형식 리포트 살펴보기 - 제 1편 GA4의 측정기준과 측정항목 완벽 정리 - 제 2편 GA4와 구글 서치 콘솔 연결하기 GA4 & UTM 완벽 연동 가이드 구글애널리틱스4(GA4) UTM으로 광고 유입 경로 추적 GA4 내부 IP 차단하는 방법 실무 GA4 필수 설정 (1) 내부 IP 차단하기 모든 구글 광고 유입이 google / cpc 로 잡히는 이유