
목차
1. Motivation

‘외롭게 살다가 쓸쓸히 숨진다’ 노인 고독사의 증가와 관련된 뉴스의 헤드라인입니다. 저희 팀은 이 헤드라인이 중요한 메시지를 던진다고 생각했습니다. 현재 급속히 진행되고 있는 초고령화 사회에서 발생하는 심각한 문제들에 주목해야 한다고 판단했습니다. 특히 독거노인의 수가 급격히 증가하면서 그들의 고독사와 정신 건강 문제가 사회적으로 큰 이슈가 되고 있습니다. 고독사 통계에 따르면 독거 노인들은 우울증 및 외로움 등의 감정을 겪고 있음에도 불구하고, 이를 체계적으로 관리하고 보호하는 시스템이 미비한 실정입니다. 이에 따라 저희는 독거 노인들의 발화를 통해 감정을 정확하게 파악하는 아키텍쳐를 구현하고자 합니다. 이는 그들의 정신 건강을 모니터링하는 디바이스를 개선하거나 고령자의 AI 친구를 개발하는 등 다양한 서비스의 기반이 될 것으로 기대합니다. 궁극적으로 독거 노인의 삶의 질을 향상시키고, 고독사 예방에 기여하는 것을 목표로 합니다.
2. Related Work
Audio Spectrogram Transformer(AST)는 Yuan Gong에 의해 2021년 제안된 모델로, CNN의 한계를 Transformer로 극복할 수 있지 않을까? 라는 질문에서 출발했습니다. CNN은 시퀀스 길이가 길어질수록 전역적인 정보를 추출하는 데 한계가 있었기에, 이를 해결하기 위해 CNN을 제외하고 Attention만을 이용하여 특징을 추출하는 기법을 채택했습니다. AST는 오디오 데이터를 스펙트로그램으로 변환한 후 이를 패치 단위로 나누고, 각 패치 간의 연관성을 Transformer 구조로 학습하도록 구조화되어 있습니다.
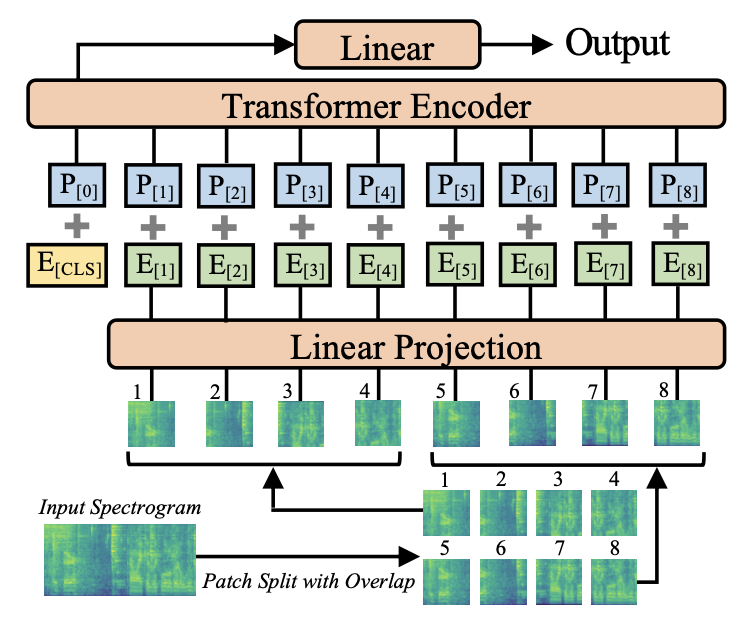
AST는 특히 Speech Commands V2 분류 과제에서 사전학습된 가중치를 사용하여 98.11% 의 정확도를 기록하면서 SOTA 성과를 달성했습니다. 그러나 AST는 사전학습에 크게 의존한다는 한계를 가지고 있으며, 성능을 높이기 위해서는 대규모의 라벨링된 오디오 데이터셋이 필요하다는 단점도 지적됩니다.
3. Methodology
3.1 Pipeline
저희는 Self-Supervised Audio Spectrogram Transformer (SSAST)를 기반 모델로 삼았습니다. AST는 다양한 오디오 분류 문제에 대해 SOTA를 기록할 만큼 가치 있는 모델입니다. 하지만 CNN에 비해 많은 양의 라벨링된 훈련 데이터를 필요로 하고, 복잡한 훈련 파이프라인에 의존한다는 한계점이 존재합니다. 따라서 저희는 이러한 한계점을 self-supervised learning을 통해 극복한 SSAST를 선택했습니다.
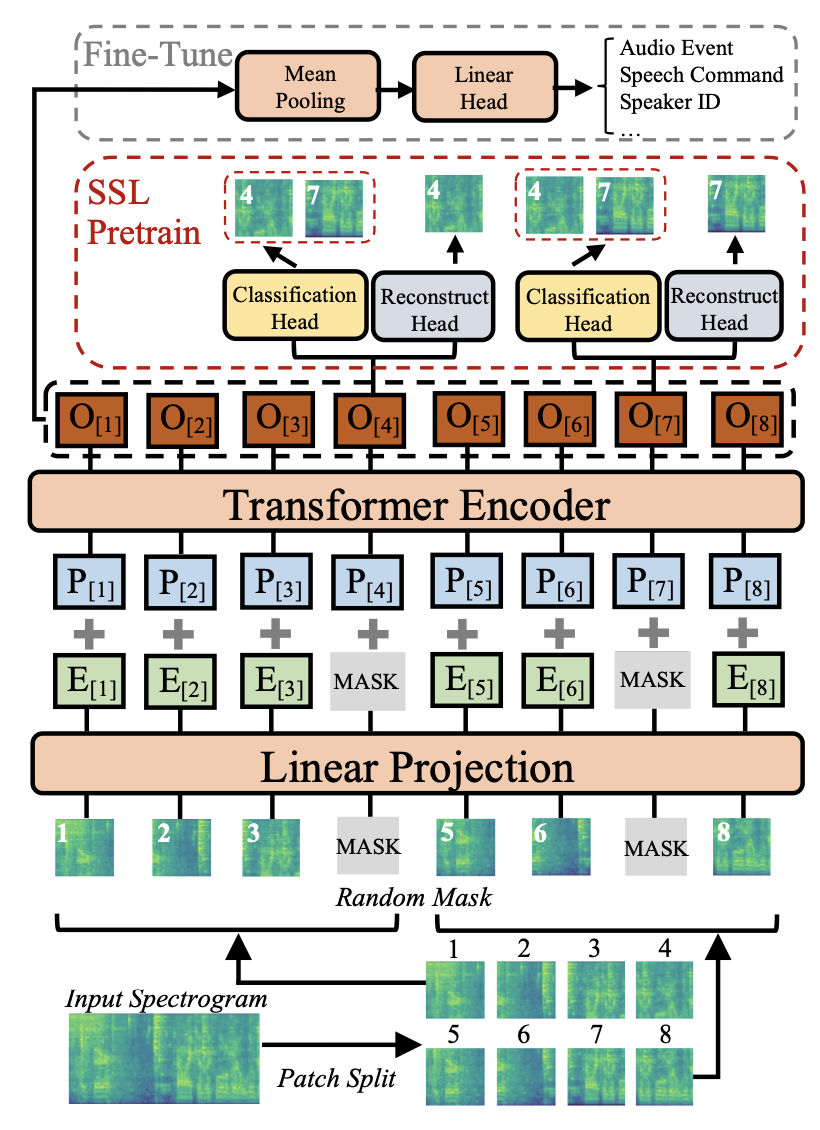
SSAST는 self-supervised pretraining 과정에서 스펙트로그램 패치의 일부를 무작위로 마스킹합니다. 이러한 패치 표현으로 transformer encoder를 거친 {} 가 도출되면, 1) 모든 마스킹된 패치로부터 각 마스킹 위치에 올바른 패치를 찾고, 2) 마스킹된 패치를 재구성합니다. 각각 위의 그림 속 Classification Head와 Reconstruct Head가 수행하는 내용입니다. 이를 통해 AST 모델이 시간 및 주파수 구조를 모두 학습함으로써, 일반화 능력 뿐만 아니라 성능 향상도 가능하게 합니다. 이렇듯 SSAST는 Self-Supervised Learning (자기 지도 학습) 방식을 사용하여, 제한적인 데이터로도 풍부한 오디오 표현을 학습할 수 있습니다. 자유 대화 데이터는 다양한 소리의 특성을 담고 있을 뿐만 아니라 높은 정확도를 요한다는 점에서 저희 프로젝트에 적합한 모델으로 볼 수 있습니다.
3.2 Datasets
저희가 사용한 데이터셋은 AI hub의 감정이 태깅된 자유대화 (성인) 입니다. 20대 이상의 성인 두 명이 3000시간 동안 대화한 데이터로, 7가지 감정(기쁨, 놀라움, 두려움, 사랑스러움, 슬픔, 화남, 없음) 클래스로 구성되어 있습니다.
저희는 원본 데이터인 음성 데이터 .wav 와 라벨링 데이터인 텍스트 데이터 .json 을 사용하였습니다.
3.2.1 Data Preprocessing
본격적으로 데이터셋을 사용하기 전 몇 가지 전처리 과정을 거쳤습니다.
- 연령대 Slicing
저희가 수집한 데이터는 20대부터 60대 이상까지 성인 남녀의 대화 데이터이었습니다. ‘음성을 통해 고령자의 감정을 파악’하는 프로젝트이기에 저희는 고령자 데이터만 필요했습니다. 따라서 50대, 60대 이상의 발화자가 대화하는 .wav 파일만 따로 선별하였습니다.
- 데이터 Slicing
AI hub의 데이터는 ‘두 사람이 대화하는 데이터’로 원본 데이터 .wav가 짧게는 10초, 길게는 몇 분으로 데이터의 길이가 길다는 특성이 있었습니다. 저희가 사용할 모델의 특성 상 데이터의 길이가 길어질 수록 해석을 하지 못한다는 특성이 있었기 때문에 .json 파일의 Conversation의 StartTime와 EndTime을 기준으로 데이터를 Slicing 하여 여러 개의 파일로 분할하였습니다.
3.2.2 Exploratory Data Analysis
전처리가 끝난 데이터셋의 특징을 파악하기 위해 탐색적 데이터 분석을 진행했습니다. 다음은 Label에 대한 정보를 담고있는 .json 파일 중 일부입니다.
"Conversation": [
{
"Text": "어디 가는 거야 지금 어디쯤 화성 간다 그랬지",
"TextNo": "000007"
"EndTime": "22.66"
"SpeakerNo": "Speaker1",
"StartTime": "19.54",
"VerifyEmotionLevel": "보통",
"SpeakerEmotionLevel": "보통",
"VerifyEmotionObject": "1",
"VerifyEmotionTarget": "기쁨",
"SpeakerEmotionObject": "1",
"SpeakerEmotionTarget": "기쁨",
"VerifyEmotionCategory" : "긍정",
"SpeakerEmotioncategory": "긍정",
},
...Conversation 관련 Label 중 감정 Label과 관련된 부분은 VerifyEmotionTarget 과SpeakerEmotionTarget 입니다.
VerifyEmotionTarget: 제 3자가 음성을 듣고 판단한 감정SpeakerEmotionTarget: 음성을 통해 자동으로 판단된 감정
두 가지 Label이 차이가 있는 지 분석하였습니다.
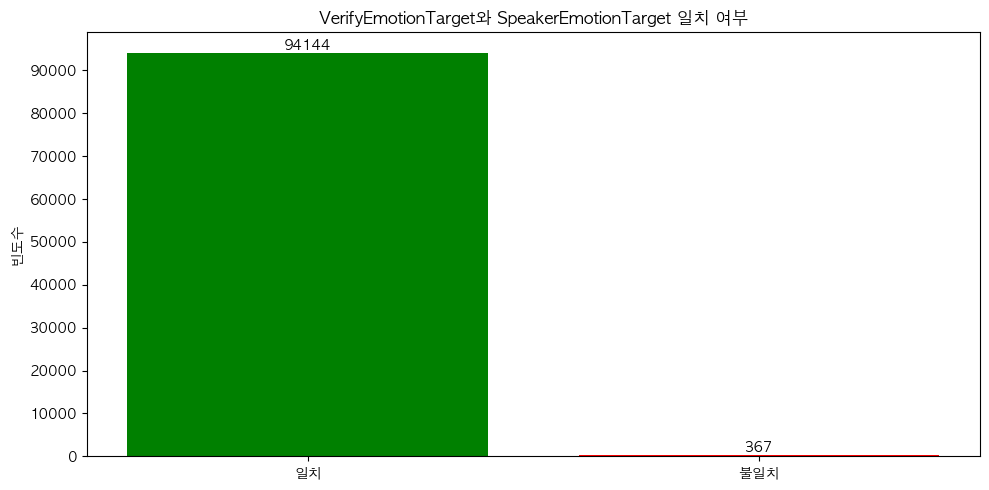
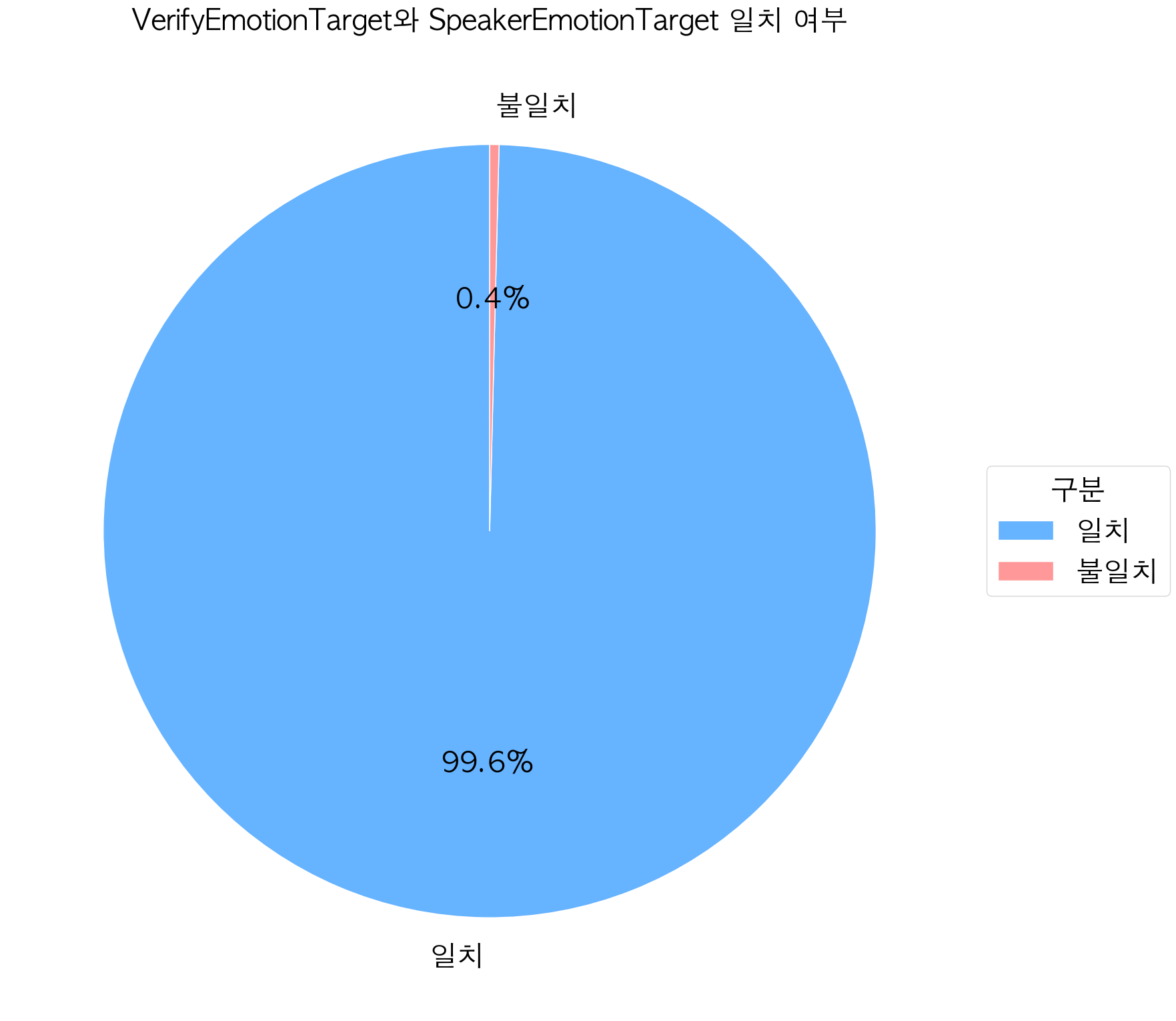
분석 결과 VerifyEmotionTarget 과SpeakerEmotionTarget 가 동일한 경우가 94,144건(99.6%)으로, 대부분 일치함을 확인할 수 있었습니다. 또한, 7가지 감정 Labels가 균등한지, Class Imbalance 여부를 분석하였습니다.
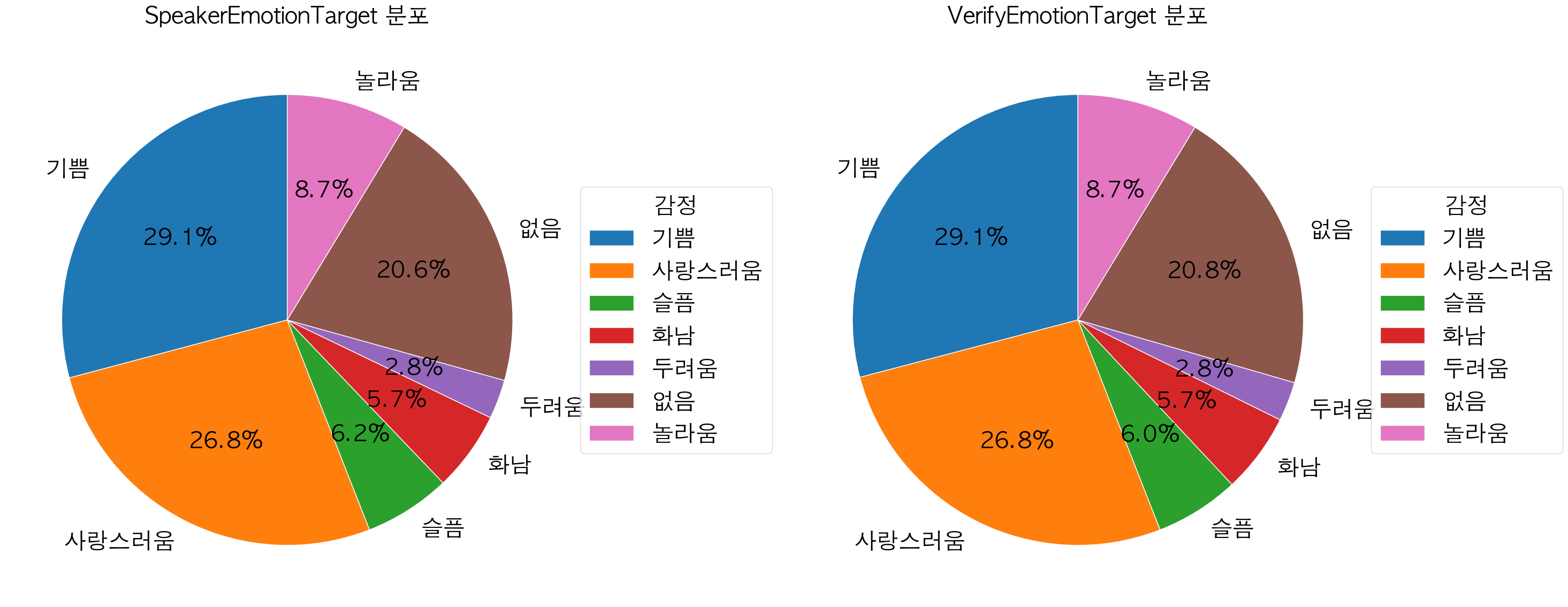
SpeakerEmotionTarget에서는 ’긍정’ 관련 감정인 기쁨(29.1%), 사랑스러움(26.8%)이 ‘부정’ 관련 감정인 놀라움(8.7%), 슬픔(6.2%), 화남(5.7%), 두려움(2.8%) 보다 비율이 높게 나타나는 것을 확인할 수 있었습니다. VerifyEmotionTarget 에서도 비슷한 비율로 나타났습니다. 이를 통해 7가지 감정의 Class Imbalance가 존재한다는 것을 파악할 수 있었습니다.
4. Experiments
4.1 Baseline : Self-Supervised Audio Spectrogram Transformer(SSAST)
저희는 SSAST의 사전학습 가중치를 다운받아 모델에 적용하고, 저희 데이터셋으로 fine tuning을 진행하는 실험 방식을 채택했습니다. 사전학습 가중치는 실험 환경 상 ‘SSAST-Tiny-Patch-400’ 버전을 사용하였습니다. SSAST-Tiny 모델은 레이어 수, 임베딩 차원, Attention head 수를 줄이고 Feed-Forward Network 크기를 축소하여 6M 파라미터로 구성된 모델입니다. 저희는 이 모델을 이용하여 사전학습된 SSAST 모델을 이용하였습니다.
4.2. Experiment
4.2.1 Label Smoothing
일반적으로 딥 러닝 모델은 실제로 정답을 맞힐 확률보다 자신이 예측한 결과를 과잉 확신하는 경향이 있습니다. 이러한 상황을 해결하기 위한 기술 중 하나가 바로 이 라벨 스무딩입니다. 라벨 스무딩에 대해 자세히 설명하기 전에, 두 가지 구조의 라벨을 소개하겠습니다. 먼저, Hard label은 One-hot encoded vector로 정답 인덱스는 1, 나머지는 0으로 구성된 다소 단순한 라벨을 의미합니다. 반대되는 개념인 Soft label은 0과 1사이의 값으로 부여되는 상태를 의미합니다. 라벨 스무딩은 Hard label에서 Soft label으로 스무딩하는 기술입니다. 번째 클래스에 대해 스무딩하는 방법은 다음과 같습니다. 이러한 라벨 스무딩은 이전 레이어의 출력값고 정답 클래스의 템플릿이 최대한 가깝도록 만들고, 다른 클래스의 템플릿들에 대해서는 같은 거리로 떨어져 있도록 만드는 효과를 낳습니다. 즉, 간단한 방법으로 모델의 일반화 성능을 높여줄 수 있는 기술입니다.
4.2.2 SpecAugment
SpecAugment: A Simple Data Augmentation Method for Automatic... SpecAugment는 위 논문에서 소개하는 음성 인식에서 데이터 증강을 수행하는 방법입니다. 입력 오디오의 log mel spectrogram에 직접 적용됩니다. 이 방법은 3가지 정책으로 구성되어 있습니다.
- time warping
시간 축을 기준으로 시계열을 변형하는 방법입니다. tensorflow의 sparse_image_warp 함수로 구현할 수 있습니다. 일정 기준을 바탕으로 무작위 기준 점과, 무작위 거리 변수를 선택하여 왼쪽 또는 오른쪽으로 spectrogram을 왜곡합니다.
- Frequency masking
특정 주파수 범위를 마스킹하는 방법입니다. 균등 분포에서 선택된 개의 연속적인 채널을 마스킹합니다.
- Time masking
특정 시간 구간을 마스킹하는 방법입니다. 균등 분포에서 선택된 개의 연속적인 시간 구간을 마스킹하여 훈련합니다.
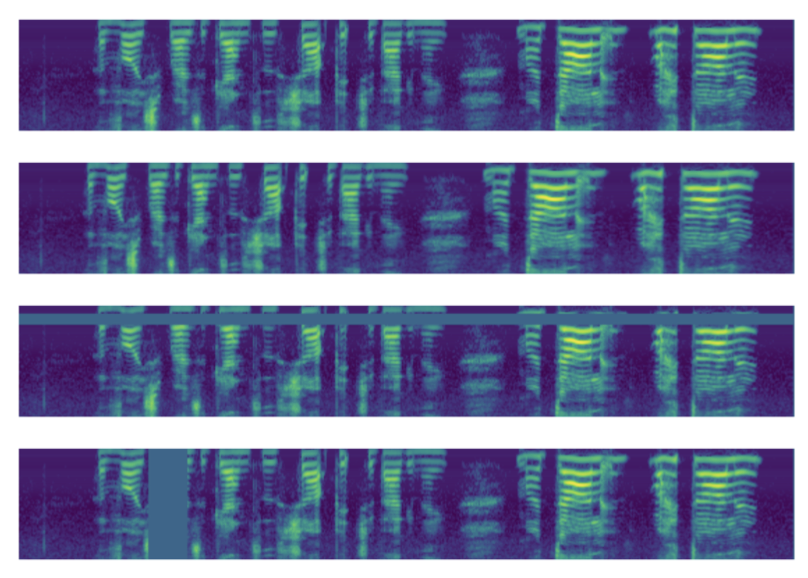
왼쪽의 이미지를 통해 각 방법론이 어떻게 적용되는지 확인할 수 있습니다. ① base input의 log mel spectrogram ② time warp 적용된 상태 ③ frequency masking 적용된 상태 ④ time masking 적용된 상태
신경망의 과적합 문제를 과소적합 문제로 바꾸고, 이를 해결하기 위한 더 깊고 넓은 모델과 더 긴 학습 과정이 성능 향상으로 이어집니다.
4.3 Results
이 프로젝트에서 가장 중요한 지표는 Accuracy (정확도)라고 판단했습니다. 두려움이나 놀라움의 감정은 고령자의 감정적 동요를 의미합니다. 이러한 감정의 동요는 독거 노인의 위험 요소를 의미할 수 있으므로, 정확하게 감정을 분류하는 모델에 집중해야 합니다. 전체 데이터 중에서 정답을 맞힌 비율을 계산해보았을 때, 개선 정책을 적용하기 전의 모델은 74.87%를 기록했습니다. 이후 라벨 스무딩과 데이터 증강을 적용한 모델은 83.84%의 정확도를 보였습니다.
4.4 Attention Map
“Attention is all you need” 논문에서 소개된 Transformer의 가장 큰 특징은 Self-Attention으로 각 요소가 다른 요소들과 관련성을 파악하며 중요한 부분에 더 큰 가중치를 부여한다는 것입니다. 이를 통해 모델은 전체 입력을 처리할 때 중요하거나 관련있는 부분에 더 집중할 수 있습니다.

Attention Map을 활용하면 이를 시각적으로 파악할 수 있다는 장점이 있습니다. NLP의 Transformer에서는 Attention Map을 활용하여 특정 Token이 어느 Token과 관계가 있는 지 파악할 수 있고, Vision의 ViT(Vision Transformer)에서는 이미지의 어떤 부분에 집중하고 있는 지 파악할 수 있습니다.
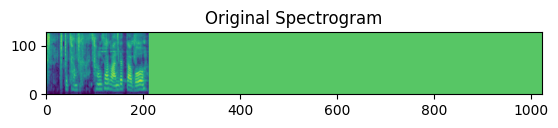
ViT에 기반한 모델인 Audio Spectrogram Transformer(AST)와 Self-Supervised Audio Spectrogram Transformer(SSAST)에서도 Attention Map을 활용할 수 있습니다. 다만, NLP와 Vision 분야의 Attention Map과는 조금 다른 형태인데요, 시간에 따른 주파수 내용을 시각적으로 표현한 그래프인 Spectrogram을 활용하여 Attention Map을 구현할 수 있습니다.
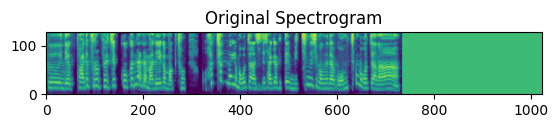
Spectrogram의 예시는 위와 같습니다. 가로이자 X축은 시간을, 높이이자 Y축은 주파수를 나타냅니다. 위의 이미지에서 X축 750~1000 부분은 Spectrogram이 나타나지 않는데요, 이는 음성 데이터의 길이가 짧기 때문에 빈 값으로 나타나는 것입니다. 주파수의 Y축의 값은 클 수록 주파수가 높고, 작을 수록 주파수가 낮다고 해석할 수 있습니다. 보통 사람이 들을 수 있는 주파수는 낮은 주파수입니다. 따라서 사람의 음성을 Spectrogram으로 나타낼 경우 Spectrogram에서는 사각형의 아래 부분이 진하게 나타나게 됩니다. 이와 같은 사전 지식을 통해 ‘특정 조건에 따라 Attention Map이 다르게 나타날까?’라는 가설을 설정하고 실험을 진행했습니다.
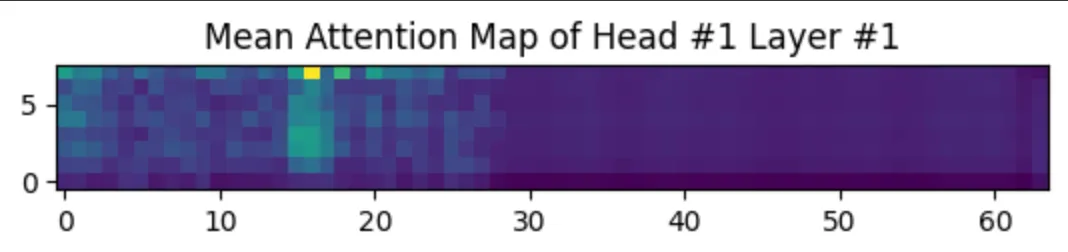
- Attention Head에 따라 Attention Map이 다르게 나타날까?
Attetntion Head는 Transformer 모델에서 각 요소들 간의 관계를 학습하는 역할을 합니다. Head마다 Data의 다른 특성에 주목합니다. 저희는 Attention Head의 이런 특성에서 착안하여 Head에 따라 Attention Map이 다르게 나타날 지 실험해보았습니다. 딥러닝 모델 특성 상 각 Head가 어떤 부분에 집중했는지 알 수 없습니다. 따라서 Attention Map을 통해 Head마다 다른 부분에 집중했는 지 대략적으로라도 파악할 수 있을 지 확인해보려 하였습니다.
저희가 분석에 사용한 음성은 다음과 같습니다.
결과는 다음과 같습니다.
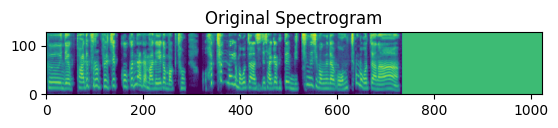
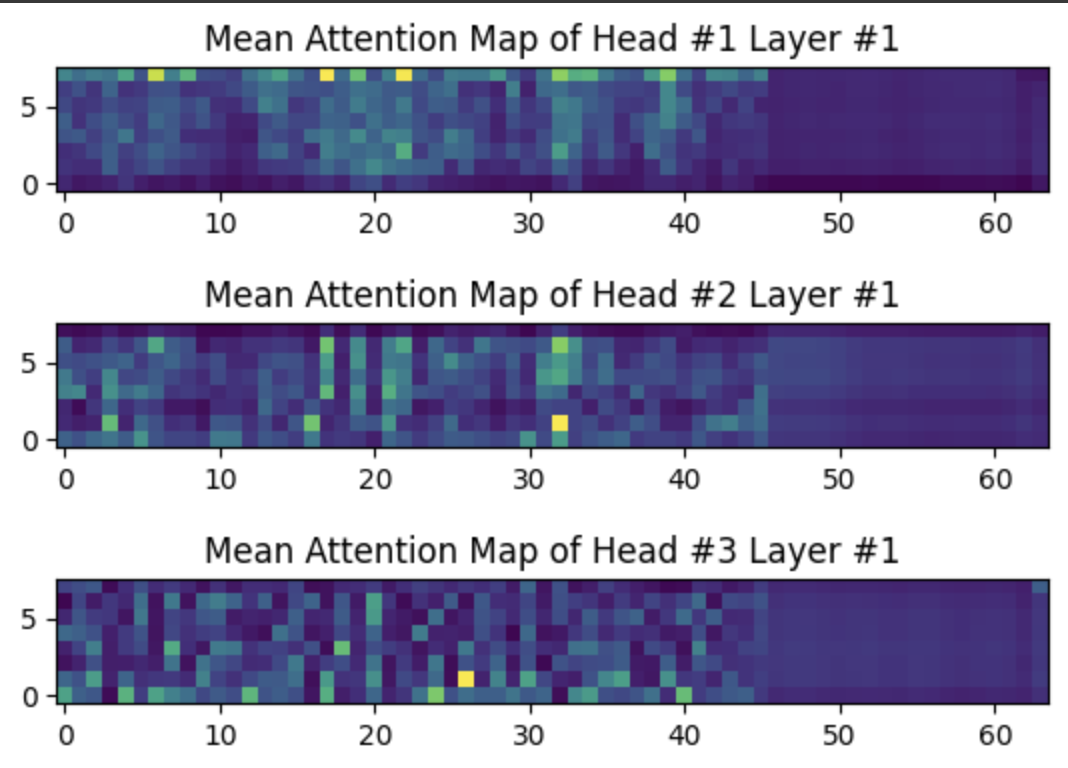
실험 결과, Head 2나 3보다 Head 1에서 밝게 나타나는 영역이 더 많다고 해석할 수 있습니다. 이는 모델이 중요하게 여기는 요인이 Head 1에서 다수 포함하고 있다고 말할 수 있습니다.
- Data의 특징에 따라 Attention Map이 다르게 나타날까?
- 기쁨 vs 슬픔
Label이 기쁨인 데이터와 슬픔인 데이터에 따라 Attention Map을 그려봤습니다. 성별 및 나이대는 동일하게 ‘50대 여성’인 데이터를 사용했습니다.
기쁨 저희가 분석에 사용한 Label이 ‘기쁨’인 음성은 다음과 같습니다.
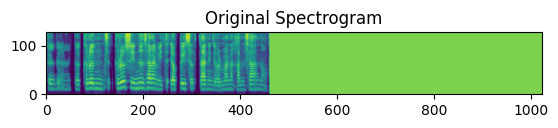
슬픔 저희가 분석에 사용한 Label이 ‘슬픔’인 음성은 다음과 같습니다.
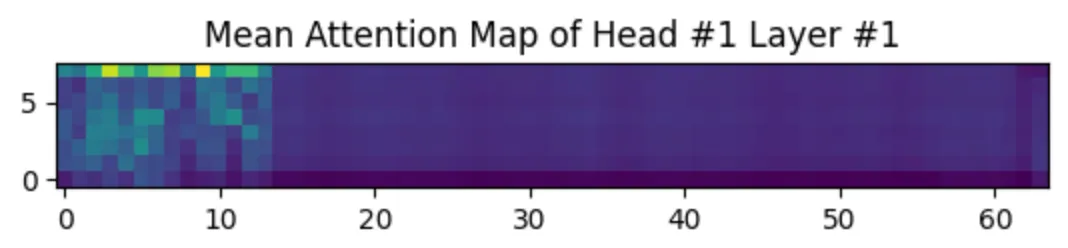
실험 결과, ‘기쁨’에서는 1~2초 사이 특정 시간대에 모델이 집중하는 모습을 보입니다. ‘슬픔’의 경우 전반적으로 밝은 것을 보아 모델이 특정 부분이 아닌 전체를 중요하거나 관계가 있다고 판단한다고 해석할 수 있습니다.
5. Conclusion
5.1 Conclusion
저희는 고령자의 발화를 입력으로 받아, 라벨 스무딩과 SpecAugment가 결합된 SSAST를 활용하여 감정을 분류하는 서비스를 구축했습니다. 주기적인 점검과 보호가 부족한 독거 노인의 감정을 분석함으로써 중병 예방이나 추가적인 조치로 이어질 수 있습니다. 이에 저희 팀은 궁극적으로 독거 노인의 전반적인 삶의 질이 향상되기를 기대합니다.
5.2 Limitations
- 데이터에 존재하는 성별 불균형을 해결하지 못했습니다. 데이터의 분포를 확인해보면 남성 발화 데이터보다 여성의 데이터가 더 많은 것을 확인할 수 있습니다. 하지만 감정 불균형 해결에만 집중하고, 성별 불균형은 해결하지 못한 채로 훈련을 진행했습니다. 이는 남성 고령자가 해당 서비스를 사용할 때의 정확도 저하로 이어질 수 있기에 보완이 필요한 부분입니다.
- 데이터 수집의 한계로 인해 훈련 데이터의 특성과 실제 사용 환경의 특성에 차이가 존재합니다. 독거 노인을 타겟으로 하여 프로젝트를 진행했으나, 고령자의 독백을 수집하는 것은 현실적으로 어려웠습니다. 이에 2인의 대화 음성을 활용하여 훈련을 진행했습니다. 추가적인 정확도 개선이 필요하다면 독백 데이터를 추가하는 방안도 좋을 것으로 보입니다.