

Team 강된장 열정 넘치는 4명의 팀원으로 이루어져있습니다! 팀원들 모두 cv는 이번이 처음이라 열심히 프로젝트 해봤어요 🥸
1. Introduction
1.1. 사회적 흐름
여러분, 혹시 눈과 귀를 막고 식당에서 주문해보신 적이 있으신가요? 이게 무슨 소리인가 싶겠지만, 실제로 시청각 장애인들은 매번 음식을 주문할 때 이런 곤혹스러움을 겪는다고 합니다. 특히나 모든 것이 자동화되어 가는 세상에서 분주히 일하는 직원들에게 도움을 요청하기도 뻘쭘한 것은 사실입니다.
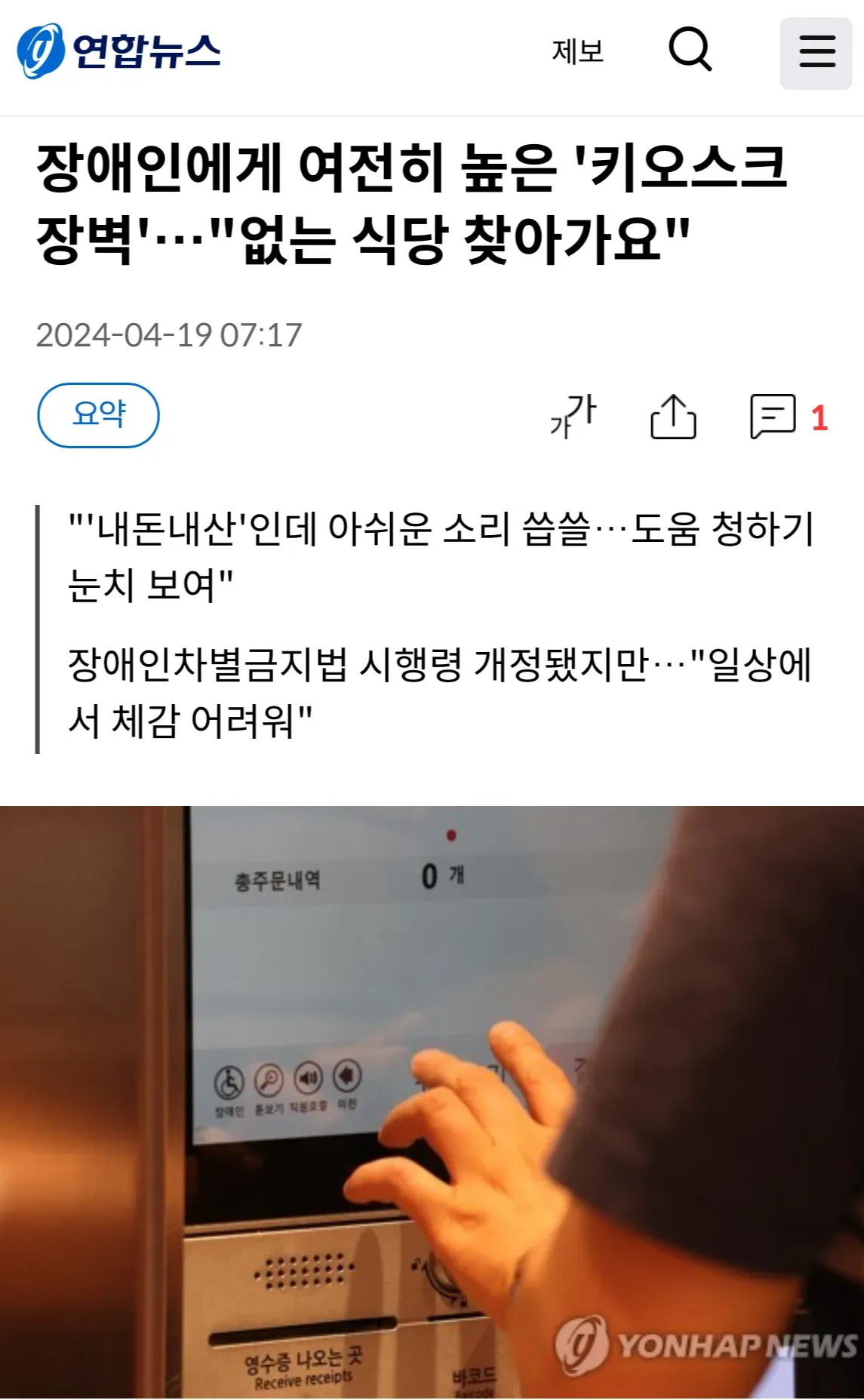
키오스크와 같이 기술이 고도화되고 사람들의 편의성을 위해 발전해가고 있는 지금, 아직도 장애인들은 사각지대에 놓여있는 경우가 많습니다. 특히 시청각 장애인의 경우 일반 장애인보다 3배 이상 도움의 필요성을 크게 느끼고 있다고 합니다. 이에 저희는 시청각장애인들을 위한 손동작만으로 원하는 주문을 할 수 있는 올인원 손동작 오더 시스템을 구축 프로젝트를 기획하였습니다. 주문을 위한 카메라를 켜는 것부터 원하는 오더를 내리는 것까지 모두 손동작으로 해결해보자는 것이죠. 더 나아가 음식점이 아닌 다른 환경에서도 사용할 수 있도록 시스템이 확장된다면 시청각 장애인 뿐만 아니라 전체 장애인분들을 위한 ‘배리어 프리’환경을 조성할 수 있을 것입니다. 다시 정리하자면 이번 프로젝트의 목표는 ‘직접 학습시킨 손동작 데이터셋을 바탕으로 학습된 모델을 통해 식당에서 쓸 수 있는 주문 메세지를 전송하는 데모 구현’입니다. 완성한 데모 미리보기
1.2. 연구적 의의

저희는 주제를 선정하며 Gesture Recognition이라는 분야 중에서도 ‘손동작 인식’이라는 큰 틀을 잡았습니다. 그 중 수화를 인식하여 메세지를 전송하는 관련 프로젝트들을 여럿 조사하면서, 손 인식에 랜드마크를 활용할 수 있음을 알게 되었습니다.
랜드마크란?

저희 프로젝트의 핵심이 되는 ‘손 랜드마크’ 데이터는 Mediapipe Hands에서 컴퓨터 비전 시스템이 인식하는 21개의 손가락 관절 특징점입니다. 특히 랜드마크를 활용하면 별도의 인식 센서 없이 동작을 해석하고 다양한 동작에 대한 자세한 인식이 가능해집니다. 저희 프로젝트는 신체에서 팔과 다리처럼 러프한 부위를 인식하는 것이 아닌 구체적인 손동작을 인식하는 것입니다. 비록 저희가 현재 데모 구현을 위해 설정한 동작들은 단순한 것들 위주로 되어 있지만, 추후 확장성을 고려하여 복잡한 동작을 인식시키는 등의 세밀한 분류에 랜드마크가 효과적일 것으로 기대하여 주된 방법으로 삼게 되었습니다.
2. Project Overview
저희 프로젝트는 크게 세 부분으로 나뉘어집니다. 1) Mediapipe Hands를 이용하여 손의 각 동작을 인식할 수 있도록 랜드마크를 추출하는 과정, 2) LSTM으로 동작을 구분할 수 있도록 모델을 학습 시키는 과정, 3) 인식된 동작을 바탕으로 데모 상에서 메세지 전송을 구현하는 과정으로 나누어집니다.
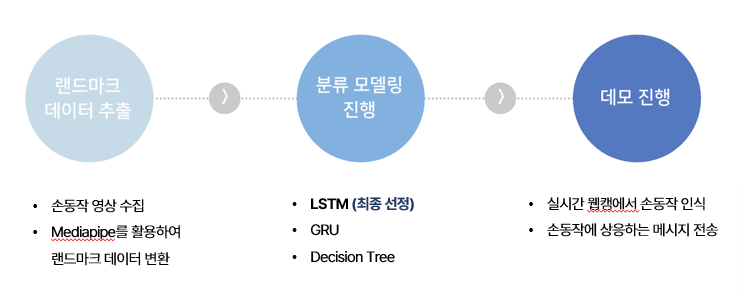
- 랜드마크 데이터 추출
저희가 도전한 방법은 기존의 CNN을 이용하여 이미지를 학습시켜 동작을 인식하는 방식이 아닌, 손의 21개 관절의 좌표를 추출하여 해당 좌표의 셋을 하나의 동작으로 인식하도록 하는 방식이었습니다. 저희가 사용한 Mediapipe Hands의 경우 단순한 3D 좌표가 아닌 2.5D (x, y, 상대적 깊이) 좌표를 추출해서 카메라와의 거리까지 효율적으로 계산이 가능한 모델이었습니다.
- 분류 모델링 진행
랜드마크 데이터를 활용하는 만큼 손동작 분류에 있어서 학습 알고리즘 역시 좌표의 시퀀스를 학습할 수 있는 LSTM과 같은 모델을 선정했습니다. 실제로 GRU나Decision Tree 등의 모델과 비교했을 때 더 나은 성능을 보여주는 것을 확인했습니다
- Sending Message
인식된 오더 동작을 주문과 연결시키는 방법으로는 웹페이지 상의 데모 구현과 카카오톡 API를 통한 메세지 전송을 활용했습니다. 실시간 웹캠에서 손동작을 인식하면, 단축키처럼 동작하여 해당 동작을 식당 채팅방에 전송하는 방식으로 구현했습니다.
3. Dataset
3.1. 손동작 영상 데이터 수집
저희는 손동작 7개에 대한 데이터셋을 만들기 위해 OpenCV를 활용하여 웹캠으로 직접 1분 간의 영상을 수집하였습니다. 해당 영상들은 최종적으로 학습에 쓰일 랜드마크 데이터를 만들기 위한 기초 데이터라고 볼 수 있습니다. 손동작 종류의 경우, 시청각장애인이라는 대상과 음식점 주문 상황을 고려하여 직접 전달하기 어려운 추가 요청사항에 대한 손동작 6가지를 지정하였습니다. 또한 데모 시연에서 손동작 인식 시작을 알리는 장치가 필요한 것을 고려하여 시작을 알리는 제스처 1가지를 추가하여 영상을 수집하였습니다. 해당 부분은 4. 메시지 전송 및 데모에서 자세히 설명 드리겠습니다. 설정한 7가지 동작을 다양한 각도와 화면상 위치에서 촬영하여 데이터를 다양화하고자 했습니다.
아래는 저희가 지정한 6가지의 음식점 주문 추가 요청 사항에 대한 손동작, 1가지의 데모 시작용 손동작과 그에 대한 Label입니다.
Label 동작 손동작 인식 이후 데모에서 전송될 메시지
커넥트 🤙 전화 포즈 시작을 알리는 제스처
더워 🥵 손부채 에어컨 좀 틀어주세요
추워 🥶 두 손 주먹 에어컨 좀 꺼주세요
앞치마 쇄골에 한 손 올리기 앞치마 좀 주세요
으쓱 🤷♀️ 두 손을 들고 어깨 으쓱 음식 언제 나오나요?
하나 ☝️ 검지 손가락 들기 하나 더 주세요
따봉 👍 엄지 손가락 들기 맛있어요~







3.2. 랜드마크 데이터로 변환
촬영한 영상으로부터 랜드마크 데이터셋을 생성합니다. 이때의 최종 데이터는 (1) 랜드마크 변환 후 기본적인 전처리 (2) 위치 정규화 (3) 각도 데이터 추가 (4) 시퀀스 데이터로 정리 총 4가지의 작업이 이루어진 후의 랜드마크 데이터셋입니다.

최종 데이터셋 형태 미리보기 최종 랜드마크 데이터셋은 (시퀀스 수, 한 시퀀스를 구성하는 프레임 수, 학습에 사용할 특징값 수)로 구성되며 npy 파일로 저장하여 학습에 사용했습니다. 58개의 특징값의 경우 2D 데이터 (x, y) + 각도 데이터 15개 + 라벨링 넘버 1개 로 이루어져 있습니다.
good shape: (1287, 30, 58)
more shape: (1302, 30, 58)
when shape: (2612, 30, 58)
hot shape: (1262, 30, 58)
cold shape: (2672, 30, 58)
apron shape: (1275, 30, 58)
connect shape: (1299, 30, 58)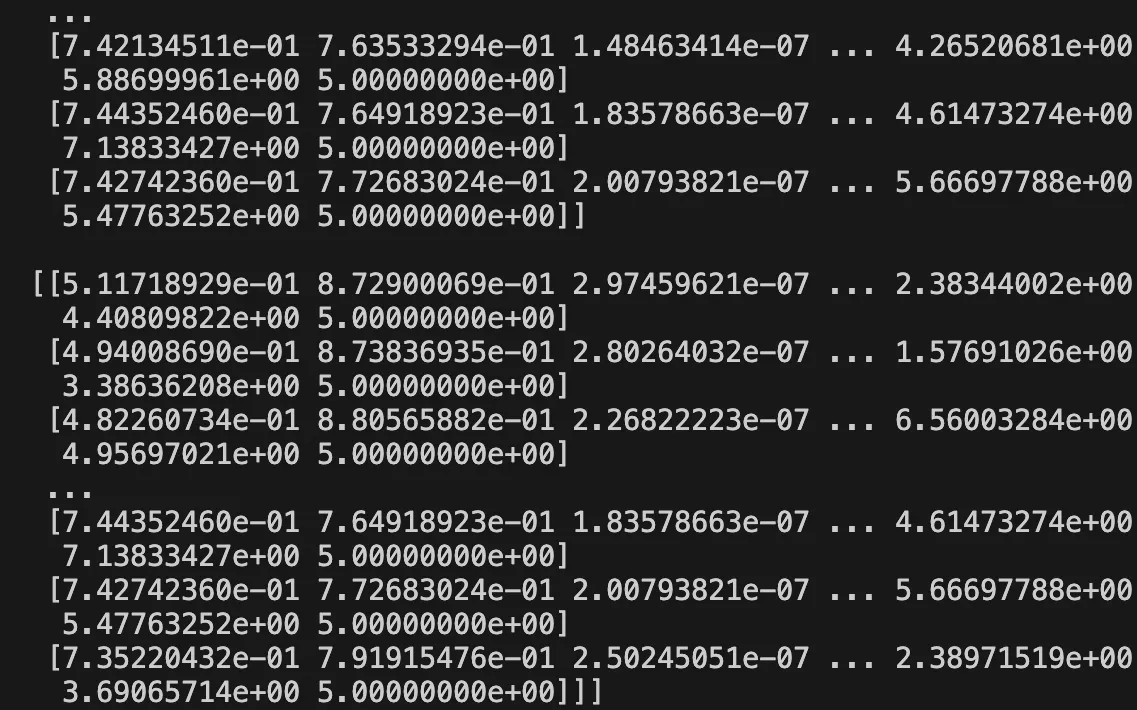
(1) 랜드마크 변환 후 기본적인 전처리
우선 Mediapipe가 구현된 라이브러리를 활용하여 영상 데이터를 21개의 손 랜드마크 데이터로 변환합니다. 손동작을 인식하는 데에 있어, 상대적 깊이를 의미하는 z좌표가 큰 도움이 되지 않을 것이라 판단하였으며 데이터의 차원을 줄이면 더 학습이 용이할 것이라 생각하였기에 최종적으로 z좌표를 제외하고 데이터셋을 구성했습니다.
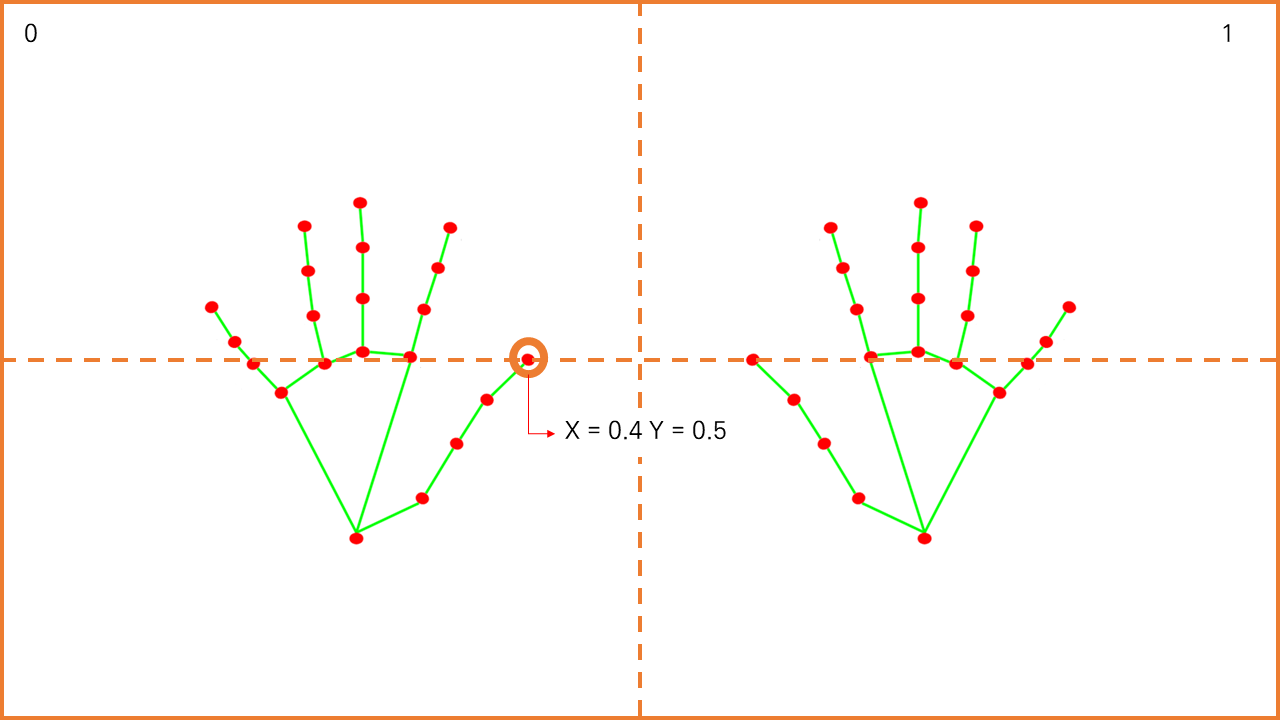
(2) 위치 정규화
위치 정규화란 화면 어떤 곳에 손이 위치하여도 같은 동작으로 인식하도록, 손목 좌표인 0번을 기준으로 랜드마크를 정규화하는 것을 의미합니다. 즉, 0번과의 좌표 차이를 리스트에 저장하여 -1~1 사이 값으로 바꿔주는 것입니다. 데이터에 음수가 나온다는 것은 좌표값의 차이에 따라 음수가 발생하며 방향 정보를 표현한다는 것입니다.
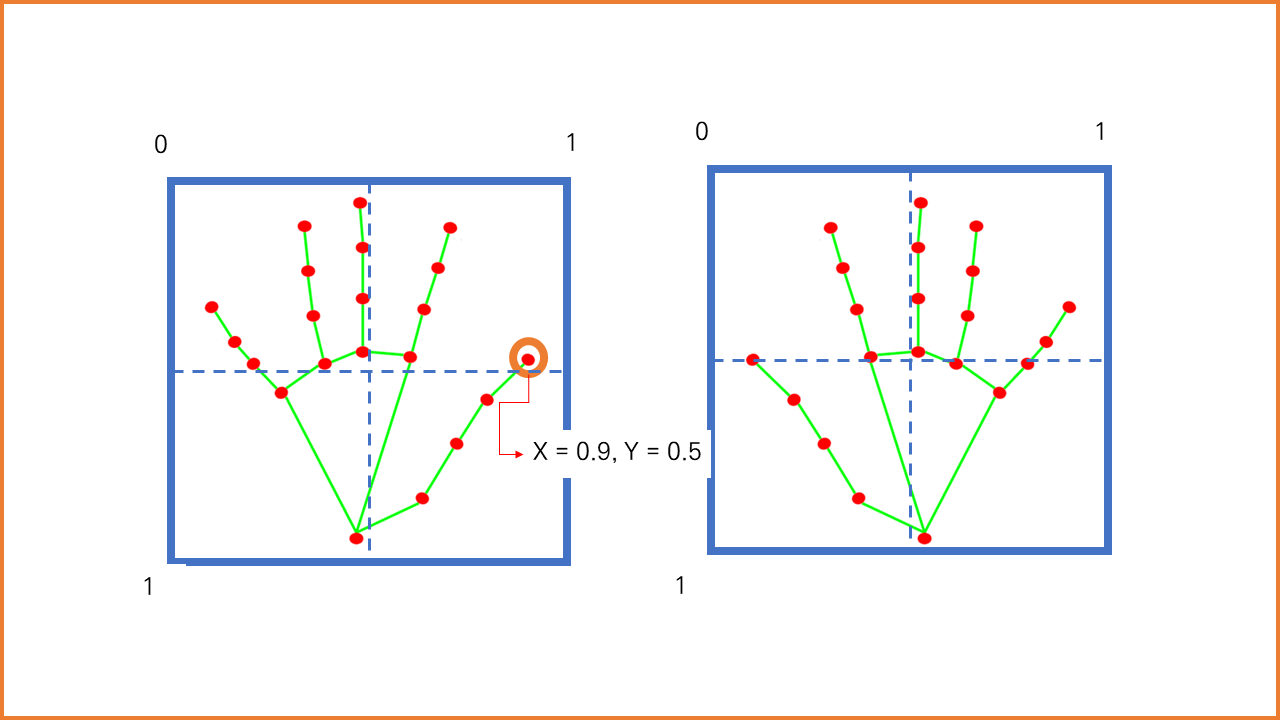
(3) 각도 데이터 추가
상황과 동작을 취하는 사람에 따라 동일한 포즈라도 조금씩 달라지는 점을 보완하기 위해 저희는 각도 데이터를 추가하였습니다. 우선 Mediapipe가 추출한 21개의 손 랜드마크를 기반으로 각 손가락 마디 간의 벡터를 계산합니다. 이때 벡터의 크기를 1로 만들어 방향만 고려할 수 있도록 벡터 정규화를 시킵니다. 이후 각 손가락의 관절 간 각도를 계산하기 위해 두 벡터 간 내적을 사용합니다. v라는 배열의 부모 - 자식 벡터를 사용하여 계산합니다.
(4) Sequence 데이터 추출
저희는 동작에 따라 움직임이 필요하여 연속적인 관찰이 필요한 데이터가 있음에 주목하여, 시퀀스 데이터를 만들어 동작 인식이 용이하도록 하였습니다. 이전 과정까지 처리된 랜드마크 데이터를 30프레임씩 슬라이딩 윈도우로 묶어 Sequence 데이터를 구성한 후, 해당 데이터를 손동작 분류 학습을 위한 최종 입력 데이터로 확정하였습니다.
21개의 랜드마크 데이터에 각도 데이터를 추가하고, 위치 정규화를 진행한 후 시퀀스로 묶어서 최종적으로는(Sequence 개수, 한 시퀀스 내의 프레임 개수인 30, 21*2 + 15 + 1)의 구조를 갖는 데이터셋을 구축한 것입니다.
이를 바탕으로 학습한 결과 비슷한 손동작을 여전히 혼동하는 모습을 보였습니다. 이에 대해 손의 위치와 각도가 중요한 손동작에서 강제적으로 축이 회전하며 비슷한 동작과 제대로 구분하지 못하는 것이라 판단하였습니다. 따라서 차원 회전 증강을 하는 방법 대신 직접 데이터셋을 수집할 때 손동작을 구분 가능한 범위 내로 직접 각도를 회전하며 수집하는 것으로 결정하였습니다.
B. Optical Flow Optical Flow는 비디오 또는 이미지 시퀀스에서 물체의 움직임을 추적하는 방법입니다. 연속된 두 프레임 사이에서 각 픽셀의 움직임을 벡터 형태로 나타내며 벡터는 픽셀의 이동 방향과 속도를 나타냅니다.
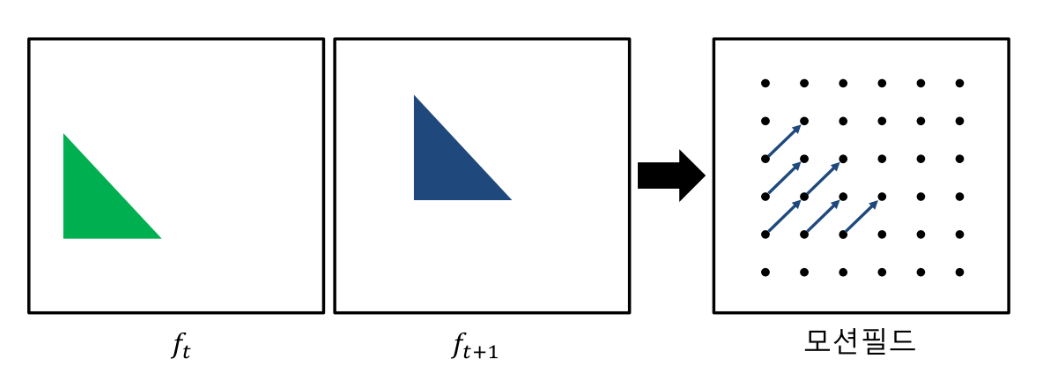
저희는 Optical flow를 활용하여 하나의 동작이 일관되게 인식될 수 있도록 할 수 있으리라 생각했지만, 실제로 분석해보았을 때 저희의 태스크에 알맞은 방법은 아니였습니다. 해당 방법은 비슷한 손동작들이 동적인지 정적인지를 구분하는 것에서는 확실한 성능을 가져올 수 있었지만, 장기적으로 보았을 때 각각의 손동작을 섬세하게 분류하는 데에 있어서 본질적인 성능을 개선해주지는 못했습니다. 더불어 Optical Flow 실험을 진행하며 손동작을 동적/정적으로 굳이 분류하지 않고, 시퀀스 처리로 한 번에 처리할 수 있다고 판단하였기에 저희 태스트에는 필요가 없는 방법이라 결론을 내렸습니다.
C. 랜드마크 확장 기존에 사용하고 있는 Mediapipe Hands에서는 손에 대한 랜드마크 정보만을 가져올 수 있었기에 동작의 확장성을 위해 어깨, 팔꿈치 랜드마크를 추가로 가져와 데이터셋에 추가로 반영해보기로 했습니다. 어깨와 팔꿈치 랜드마크는 Mediapipe Pose를 통해 추출했습니다. 추가한 결과 동작의 확장성을 위해 가져온 팔꿈치 랜드마크가 동작을 취하는 사람마다 달라 오히려 손동작 인식 성능을 저하시킨다고 판단하여 사용하지 않기로 결정했습니다.
💡결론 실험 결과 위의 방법들에 비해 각도 데이터를 추가시킨 데이터셋에 대해서 손동작 분류를 가장 잘했으며, 헷갈릴 수 있는 동작들을 잘못 인식하는 경우가 현저하게 줄었기 때문에 최종적으로 각도 데이터를 전처리 방법으로 선정했습니다.
4. Classification
모델 비교 저희의 최종 데이터는 Sequence로 정리된 랜드마크 데이터이기에, 연속적인 입력 데이터를 처리하기 용이한 LSTM과 GRU를 선정하여 모델 비교를 진행하였습니다. 또한 상대적으로 간단한 Decision Tree 모델로도 학습을 진행하여 확실하게 성능을 비교해보고자 하였습니다 학습-검증 데이터 구분 이에 전체 데이터셋을 70%의 train dataset,30%의 validation dataet으로 분할하였습니다. 웹캠으로 직접 수집한 데이터셋의 특성상 해당 데이터 안에서 지표로서 테스트한 결과를 완전히 믿을 수 없다 판단하여 train과 validation dataset으로만 구분하여 1차적으로 성능 개선 정도를 확인하였습니다. 이에 최종적인 성능은 데모에서 실시간으로 손동작을 인식하여 확인할 수 있도록 하였습니다. 최종 선정은 LSTM 1차적으로 지표 결과도 가장 안정적이고, 최종적으로 데모 시연 결과가 특히 뛰어났던 LSTM을 분류 모델로 최종 선정하였습니다. 모델 성능 평가에 사용했던 accuracy의 경우, categorical class 분류 문제이기에 높은 예측 확률에 해당하는 클래스로 예측 클래스 선정한 후 전체 결과에 대해 정답 클래스와 동일한 개수를 산정하여 accuracy를 계산하였습니다.
4-1. LSTM
초기에 저희가 설계한 LSTM에 대한 재현율, 정밀도, AUC (분류 모델의 성능을 보여주는 ROC 곡선의 아래영역)을 분석해본 결과는 다음과 같습니다.
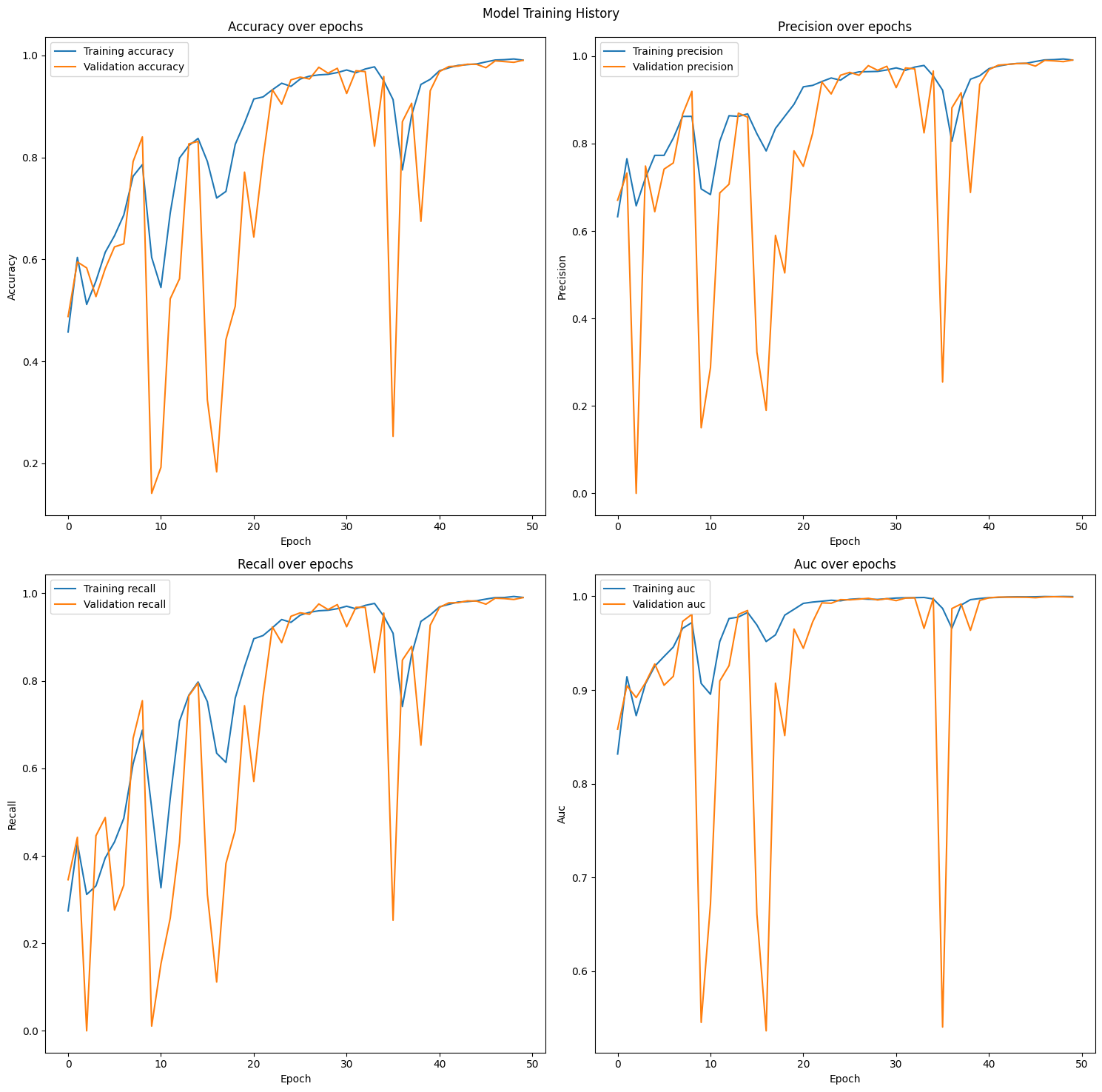
그러나 너무나 비현실적인 정확도 수치와 더불어 중간 중간 과도하게 발생하는 과적합에 대해서 성능 개선을 위해 몇 가지 장치를 더 추가해봤습니다. 첫번째 시도: LSTM 레이어 추가
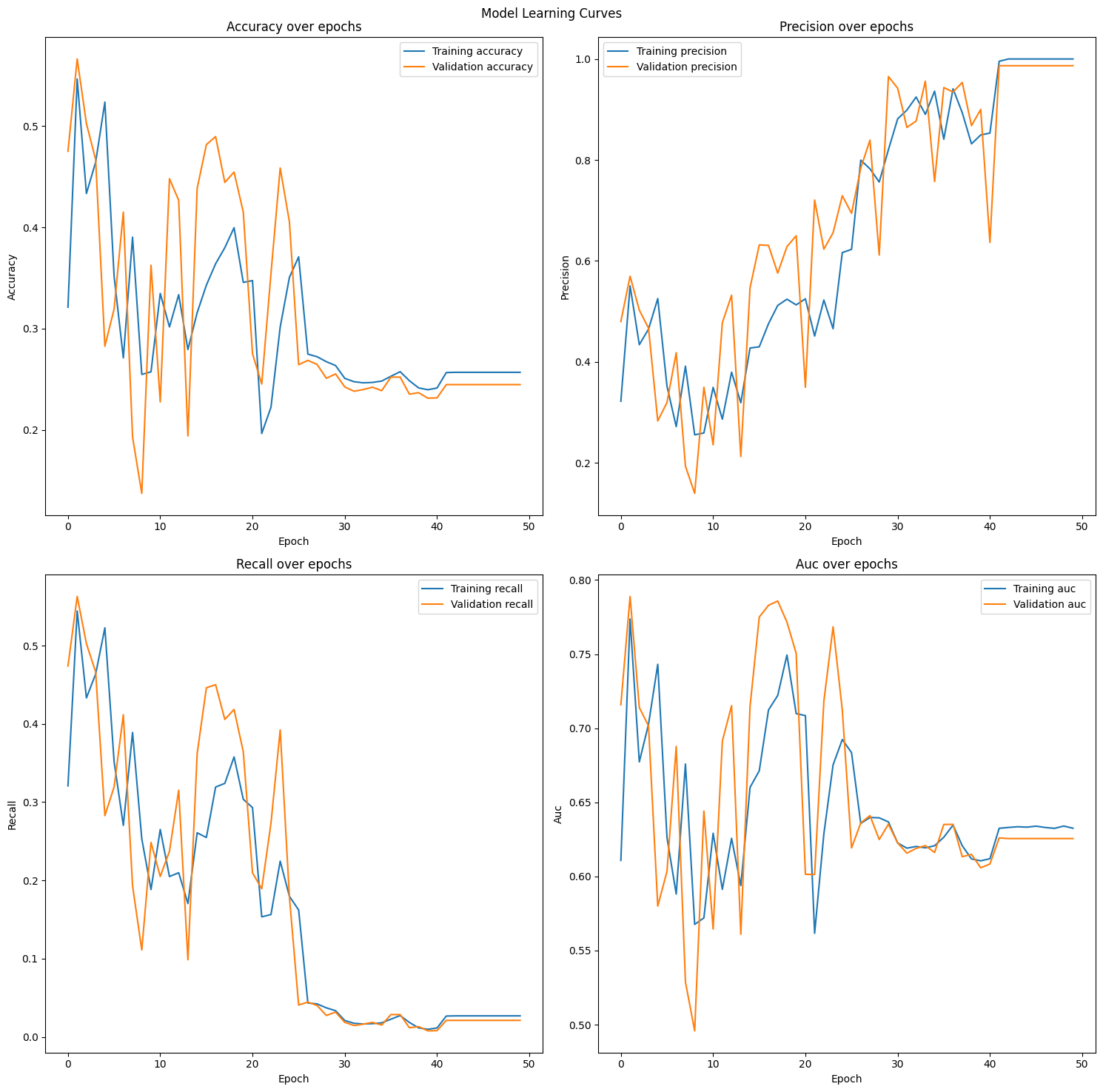
저희가 개선하고자 하는 과적합 문제는 전보다는 비교적 나아진 모습입니다. 그러나 매우 높은 정밀도 이외에 나머지 지표가 낮게 나온 것을 볼 수 있습니다. 결과적으로 성능이 높아지지 않았다고 판단했습니다.
두번째 시도: Dropout Dropout은 과적합 방지에 효과적인 한 방법으로, 각 학습단계에서 신경망의 뉴런을 일정 비율로 선택하여 비활성화합니다. 각 훈련 반복마다 임의로 선택된 뉴런을 사용하지 않고 무시하는 방식으로, 보통 0.2-0.5 사이의 값으로 설정합니다.
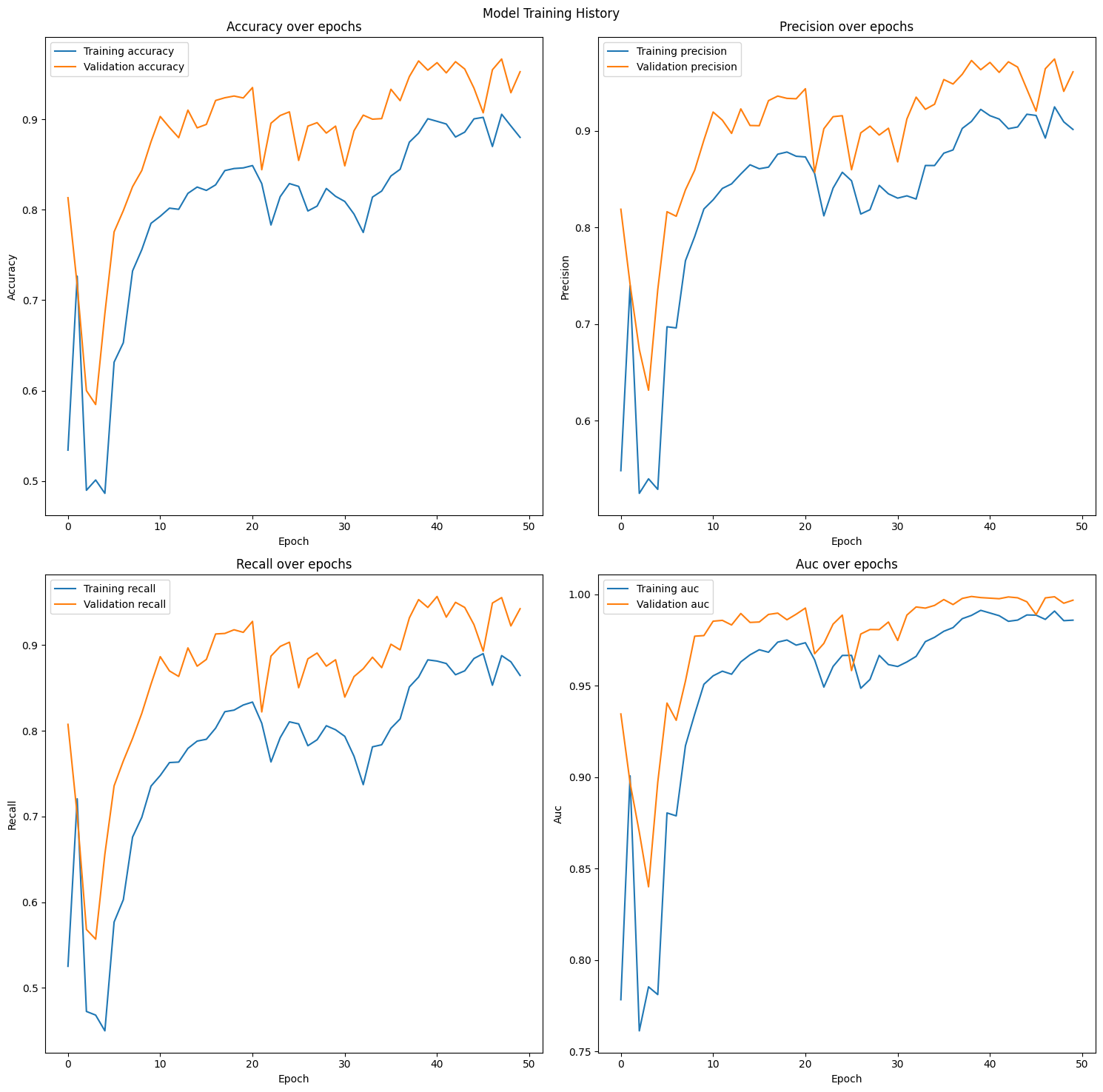
그러나 Dropout을 적용했을 때 검증 데이터셋의 결과가 학습 데이터셋의 결과보다 높게 나오는 현상이 발생되었습니다. 또한 웹캠 테스트에서 각 손동작을 제대로 분류하지 못하는 것을 확인했습니다.
세번째 시도: BatchNormalization
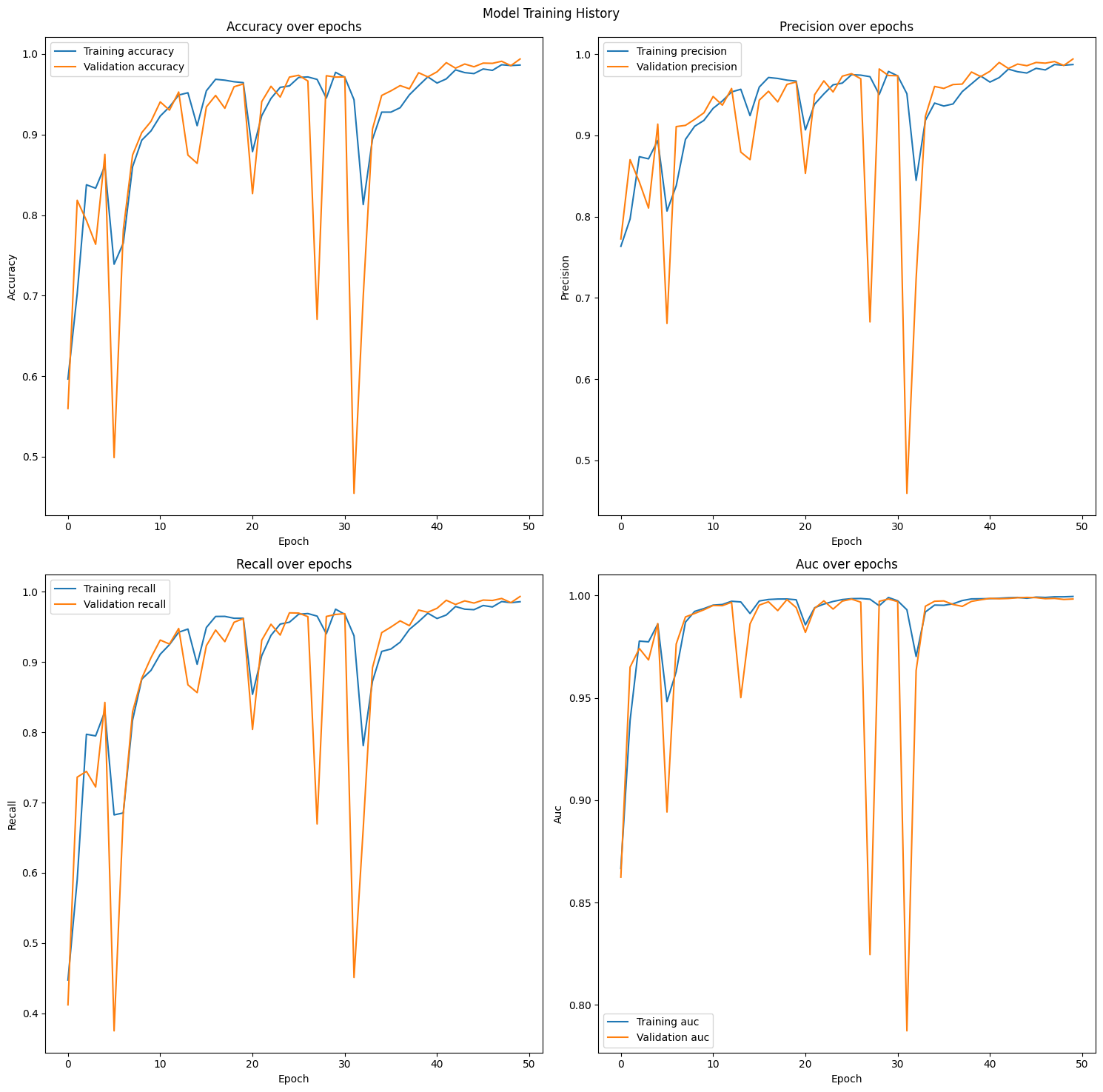
지금까지의 결과 중 가장 안정적인 학습 결과를 보였습니다. 줄어들긴 하였으나 중간에 여전히 발생하는 과적합의 문제를 제외하고는 성능 상 큰 문제가 없다고 판단했습니다. 따라서 Dropout은 사용하지 않고 BatchNormalization만 사용하기로 결정했습니다. 최종 정확도는 0.983으로 양호한 수치를 나타냈습니다. 또한 웹캠으로 테스트 결과 모든 포즈를 구현했을 때 올바른 동작을 예측했으며 화면 중앙이 아닌 곳에서 동작을 하더라도 높은 정확도를 보였습니다.
4-2. 기타 비교모델
(1) GRU
GRU는 LSTM과 달리 Cell State와 Output Gate가 없기 때문에 더 단순한 구조를 가지고 있습니다. 이에 효율적으로 좋은 성능을 보일 수 있을 거라는 가정 하에 학습을 진행했습니다.
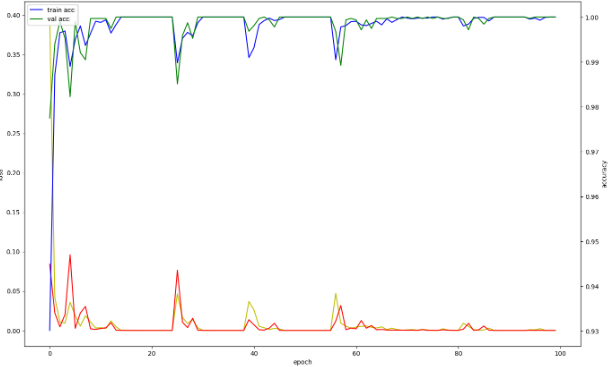
첫 번째 시도에서는 기본적인 조정만 한 상태로 학습을 시도했습니다. Epoch=15에서부터 Validation Accuracy가 100%가 나오기 시작하는 비정상적인 결과를 확인할 수 있었습니다.
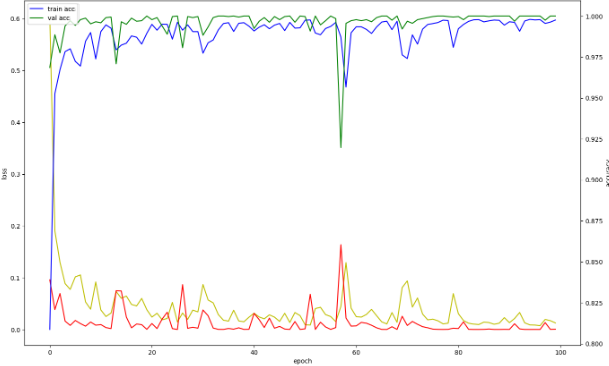
이에 몇 가지 조치를 추가로 취했습니다. Batch Normalization을 통해서 데이터 정규화를 해준 후, Dropout과 Early Stopping을 통해 너무 깊게 학습되는 것을 막고자 했습니다. 하지만 여전히 과적합 경향을 보였기에 최종적으로 GRU는 사용하지 않기로 결정했습니다.
(2) Decision Tree
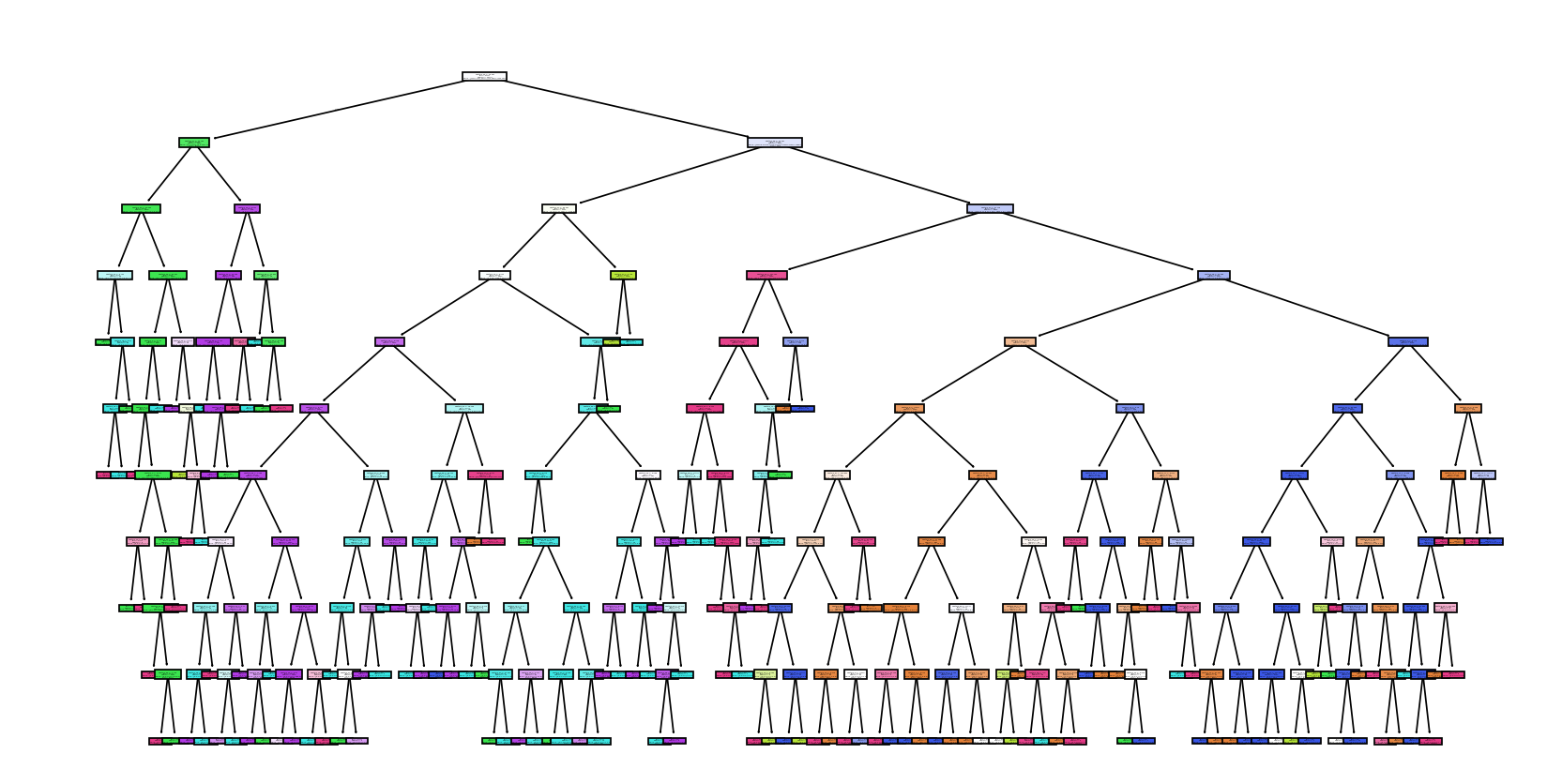
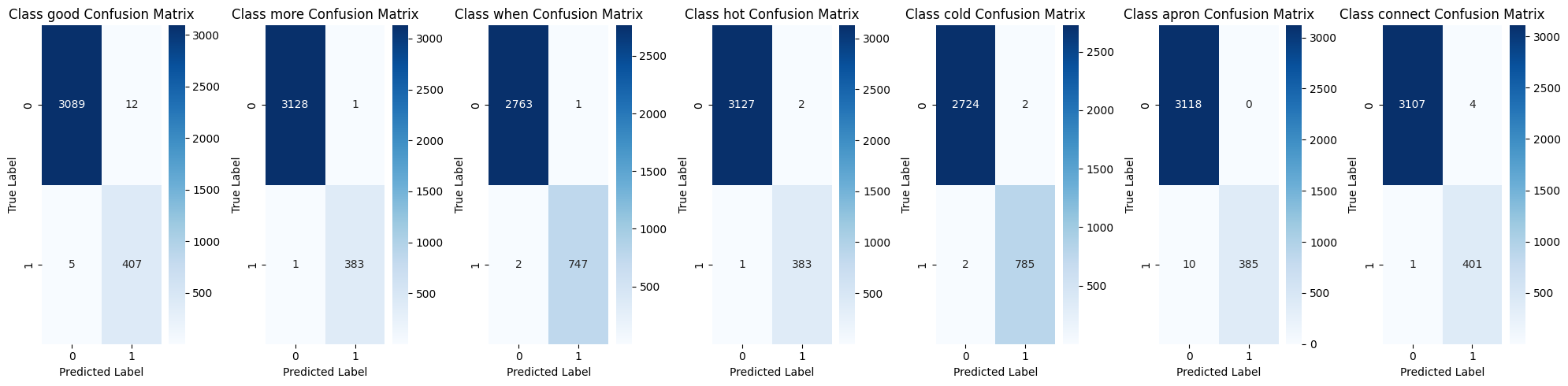
Decision Tree의 경우 최종 정확도 0.987로, StratifiedKFold로 교차 검증을 했을 때에도 정확도가 모두 1이 나왔습니다. 비현실적인 정확도 점수에 대해서 저희는 max_dept = 10 으로 설정하여 모델이 복잡해진 탓이라고 생각하였습니다.
따라서 Decision Tree 파라미터 중 max_depth를 10에서 5로 줄이고, min_sample_split 과 min_samples_leaf 를 도입했습니다. 여기서 min_sample_split과 min_samples_leaf란 각각 노드 분할을 위한 최소한의 샘플 수와 말단 노드가 되기 위한 최소 샘플 수를 의미합니다. 마지막으로 ccp_alpha 로 가지치기를 적용하여 Decision Tree 학습을 진행했습니다.
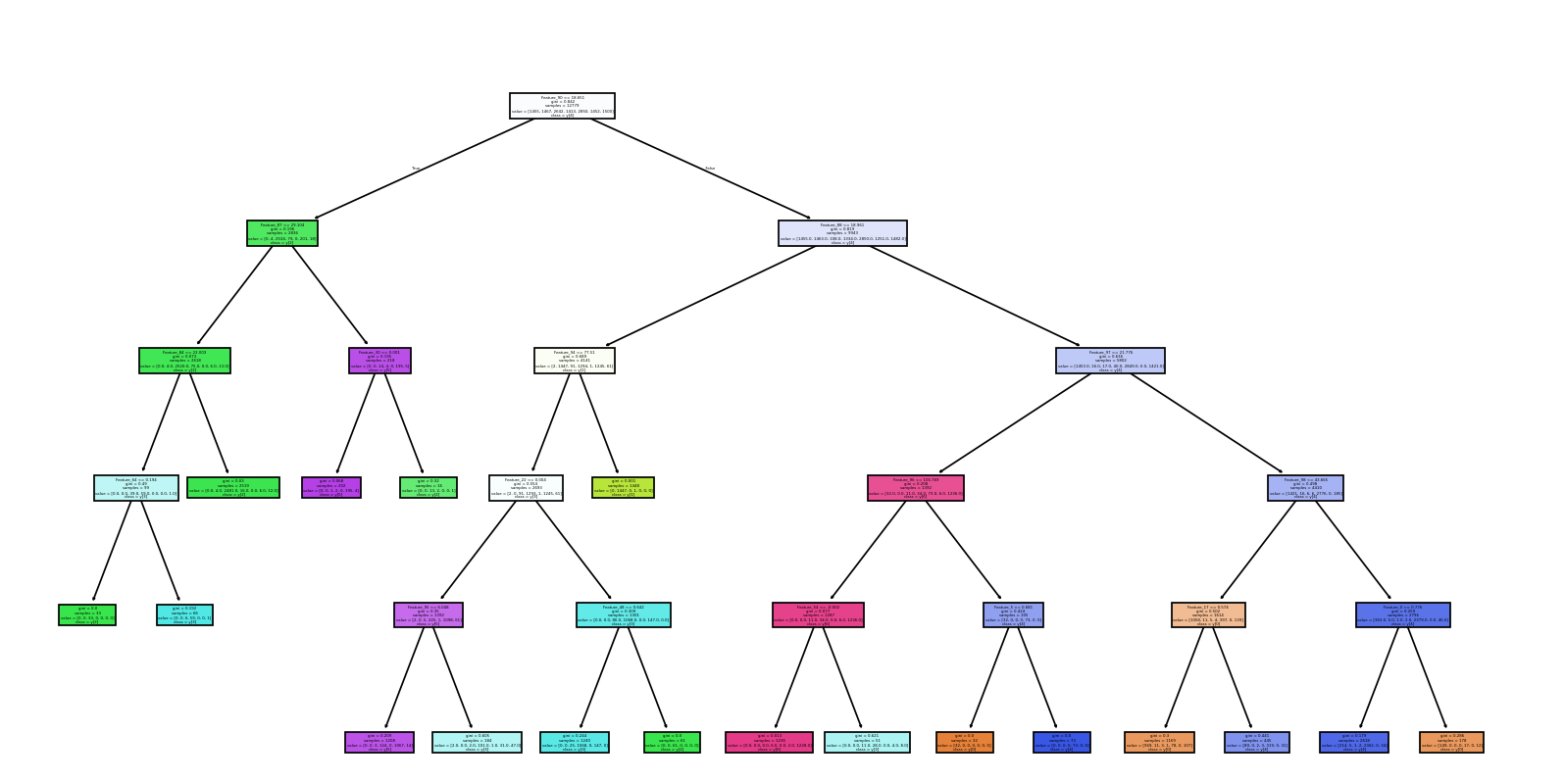
결과는 정확도 0.925로, 수치적으로는 더 낮지만 더욱 현실적인 정확도를 얻어낼 수 있었습니다. 그러나 실제로 테스트 결과 특정 위치에서는 잘 인식하지만 위치에 변화를 줬을 때 인식을 잘 못하는 현상을 보였습니다. 또한 더워🥵를 앞치마와 헷갈려하는 모습이 매우 자주 포착되었습니다. 다른 동작들에서는 나쁘지 않은 성능을 보였습니다.
5. Sending Message & Demo
5-1. 구현 방식 및 고려 사항
손동작에 매칭되는 주문 메시지를 미리 지정한 후, 손동작을 취했을 때 그에 맞는 메세지를 자동으로 전송해주는 방식으로 데모의 구조를 설계했습니다. 메시지 전송의 경우, 식당 오더 시스템과 연결할 수 없는 데모 상황을 고려하여 카카오톡 메시지 전송으로 대체하여 구현하였습니다. 저희가 웹캠 데모에 설정한 두 가지 규칙은 다음과 같습니다.
- 손이 화면 밖으로 나가지 않도록 할 것 (10 프레임 이상 인식되지 않으면 해당 시퀀스 삭제) → 위치 정규화를 통해 화면을 움직이지 않아도 학습 가능하도록 조정했습니다.
- 일정 프레임 (30개) 동안 3번 이상 해당 클래스로 인식되어야 동작 레이블을 출력합니다.
저희 팀의 목표는 학습한 손동작을 인식했을 때 해당 내용을 식당에 원격으로 전달하는 것입니다. 그러나 학습하지 않은 손동작을 데이터셋에 있는 동작으로 인식하는 경우가 빈번하게 발생했습니다. 따라서 커넥트🤙 동작을 취한 이후 첫 번째로 인식하는 동작을 말하고자 하는 내용으로 정의하기로 했습니다. 손동작 메시지를 카카오톡으로 전송하기 위해서 카카오톡 메시지 API를 사용했습니다. API로부터 받아온 토큰을 이용하여 메시지를 보내는 방식입니다.
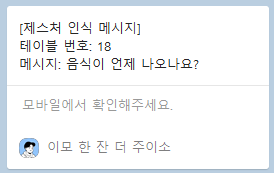
예를 들어 커넥트🤙 동작 이후 으쓱🤷♀️ 동작을 취한다면 아래와 같이 메시지가 전송됩니다.
5-2. 기본 작동 구조
기본적인 구현을 위하여 flask 라이브러리를 사용한 결과입니다.
- 커넥트🤙 동작을 취합니다.
- 커넥트🤙 동작을 취했을 때만 ‘원하는 제스처를 취해주세요’라는 메시지가 등장합니다.
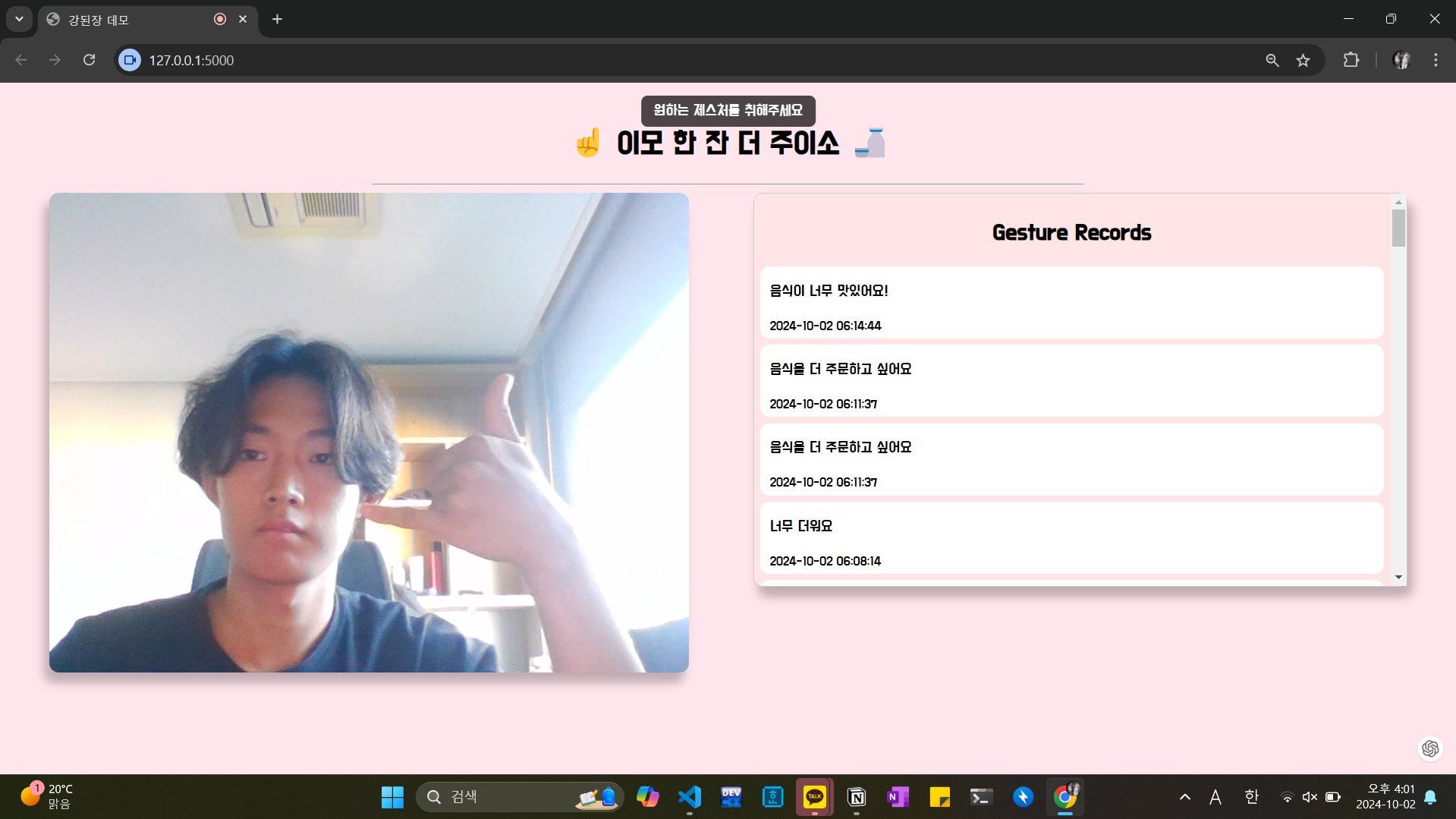
- 이 상태에서 커넥트🤙 이후에 취하는 첫 번째 손동작을 메시지로 보낼 동작으로 인식합니다.
- 오른쪽 기록에 “음식이 너무 맛있어요”가 추가된 것을 확인할 수 있습니다.
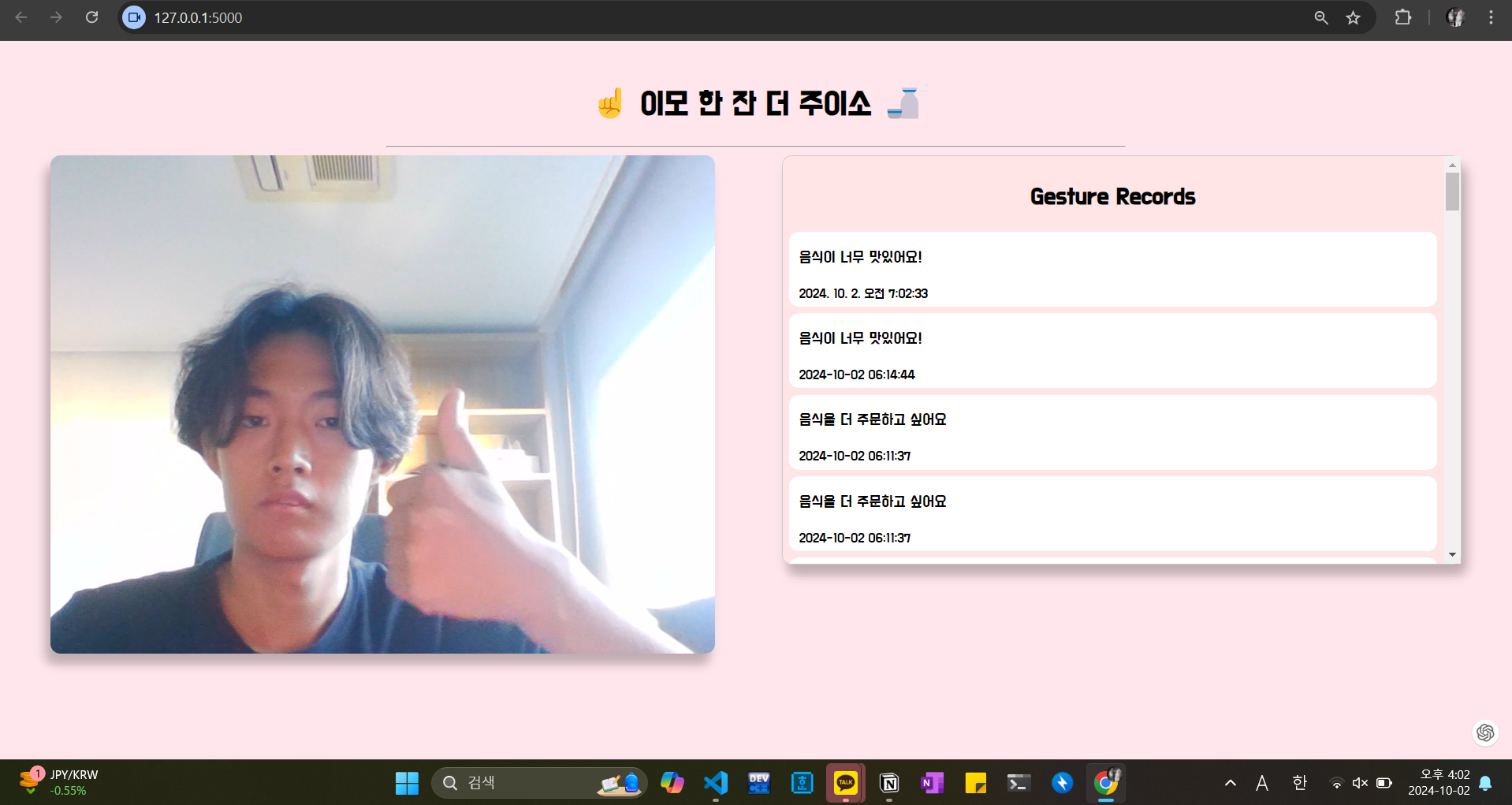
- 카카오톡에도 메세지가 정상적으로 전송됩니다.
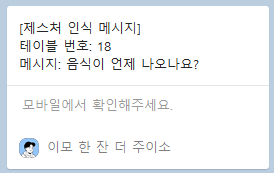
- 원하는 제스처를 취하라는 알림은 메시지를 보낼 손동작을 인식한 후 사라집니다.
6. Results & Contribution
1. 결론 및 의의
저희 팀은 이번 프로젝트를 통해 직접 학습시킨 손동작 데이터셋을 바탕으로 학습된 모델을 통해 식당에서 쓸 수 있는 주문 메세지를 전송하는 데모 구현이라는 목표를 달성할 수 있었습니다. 이 프로젝트는 시청각 중복 장애인들이 식당에서 어려움 없이 주문할 수 있도록 손동작만으로 의사 전달을 할 수 있다는 점에서 의의를 가집니다. 시청각 중복 장애인들의 경우 잔존 시청력의 정도가 사람마다 다르고, 일상생활의 도움이 필요하다는 응답이 전체 장애인(5.9%)들보다 3배 높았습니다(14.9%). 현재 이들을 고려한 대책이 없는 상황이기에 혼자 돌아다니거나, 독립적으로 주문하는 것에 많은 어려움이 있습니다. 이 상황에서 저희의 시스템이 현재는 몇 가지 기본적인 손동작만을 인식하고 있지만, 이후 더 많은 손동작을 추가한다면 식당에서 더 정교한 주문이 가능하도록 발전시킬 수 있다는 기대 효과를 가집니다.
2. 한계
1️⃣ 데이터셋 최종 선정 이후 모든 모델에 적용하여 비교 진행하지 않은 점 모든 모델에 (각도 데이터, 위치 정규화 o)로 확정된 최종 데이터셋을 넣어서 제대로 학습 비교를 진행하지 않은 점이 첫 번째 한계입니다. 여러 데이터 처리를 비교하고 모델 학습을 하다보니 시간 한계상 메인 모델로 정한 LSTM에만 최종적인 데이터셋을 적용하였는데, 비교를 진행한 GRU와 Decision Tree에도 최종 데이터셋을 적용하여 비교를 진행하였으면 보다 확실한 결과를 얻을 수 있었을 것입니다.
- 최종 LSTM 결과 : 각도 데이터 추가, 위치 정규화까지 진행된 데이터
- 최종 GRU 결과 : 각도 데이터만 추가된 데이터
- 최종 Decision Tree 결과: 각도 데이터만 추가된 데이터
2️⃣ Decision Tree 모델의 비정상적인 accuracy 결과 분류 모델 중 Decision Tree의 경우 validation accuracy를 하나만 추출하여 결과를 냈을 땐 0.987나왔지만, 오히려 StratifiedKFold로 교차로 검증했을 때에는 5번 폴드 모두 정확도가 1이 나오는 비정상적인 결과가 나왔습니다. 이러한 문제가 일어난 원인에 대한 깊이 있는 분석을 진행하지 못한 부분이 두 번째 한계입니다.
3️⃣ LSTM 최종 학습에서 Validation Accuracy 급감하는 지점 발견 학습 과정에서 validation accuarcy가 epoch 중반에서 갑작스럽게 낮아진 현상을 보였습니다. 저희는 해당 문제가 일어난 원인에 대해 두 가지 가설을 세웠습니다. (1) 데이터가 충분히 섞이지 않았다 (2) 데이터 크기 자체의 문제다 (3) 과적합이 되었다. 추후 연구를 진행한다면 해당 가설 하에 문제를 해결하기 위한 여러 시도를 해볼 예정입니다. DecisionTree 뿐만 아니라 다른 모델의 지표 결과를 내는 데 있어서도 일괄적으로 Kfold 교차검증을 하여 정확한 결과를 도모하거나, 데이터셋 자체를 늘려보거나, 하나의 시퀀스 내의 프레임 수를 줄여보는 등의 시도를 해볼 수 있을 것입니다.
4️⃣ 이미지 자체를 활용하지 않은 점 저희는 세밀한 동작을 인식할 수 있을 것이라는 기대 하에 랜드마크 데이터만을 사용하여 프로젝트를 진행하였습니다. 이에 대해 같은 데이터로 (1) 이미지만을 활용한 손동작 인식 (2) 단순한 동작에는 이미지를 활용하고 세밀한 동작에 추가적으로 랜드마크를 활용하여 손동작 인식 (3) 랜드마크만을 활용한 손동작 인식 , 이렇게 세 가지를 모두 진행하여 비교하였으면 더욱 큰 의의를 가져갈 수 있었을 것입니다.