
Introduction
자취생 현실이라는 제목으로 유명해진 카톡 대화 짤입니다. 혹시 아시나요? 모르시더라도 내용에 공감하시나요? 자취를 해본 적 있는 분들이라면 알겠지만 자취 초기에는 매일 집에서 새로운 메뉴로 밥을 해먹고자 하는 사람들이 많습니다. 하지만 한 달만 지나도 집에서 대충 라면에 밥으로 끼니를 때우는 사람이 굉장히 많아집니다. 거창한 요리를 해먹기 위해서 들이는 시간과 노력이 아깝기 때문입니다. 간단하게 해먹을 수 있는 요리를 잘 모르는 경우도 많습니다. 용산과 길음사이 팀은 여기에서 프로젝트를 시작하게 되었습니다. 추천시스템 모델을 활용하여 자취생을 위한 요리 레시피를 추천하는 서비스를 구현하는 것이 본 프로젝트의 목표입니다.
Method
Dataset
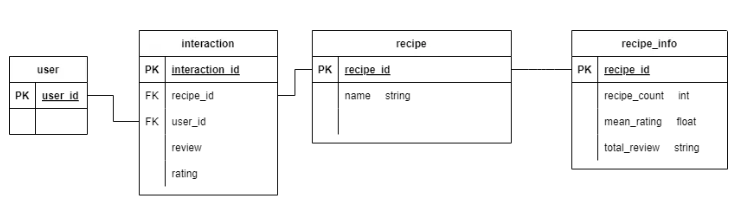
본 프로젝트에서는 Food.com Recipes and Inteactions Dataset을 사용하였습니다. 이 데이터는 Food.com이라는 미국의 온라인 레시피 공유 사이트에서 수집되었으며, 크게 레시피와 유저 간 상호작용 데이터로 구성되어있습니다.

현재는 Kaggle에서 데이터를 조회할 수 있습니다. (링크)
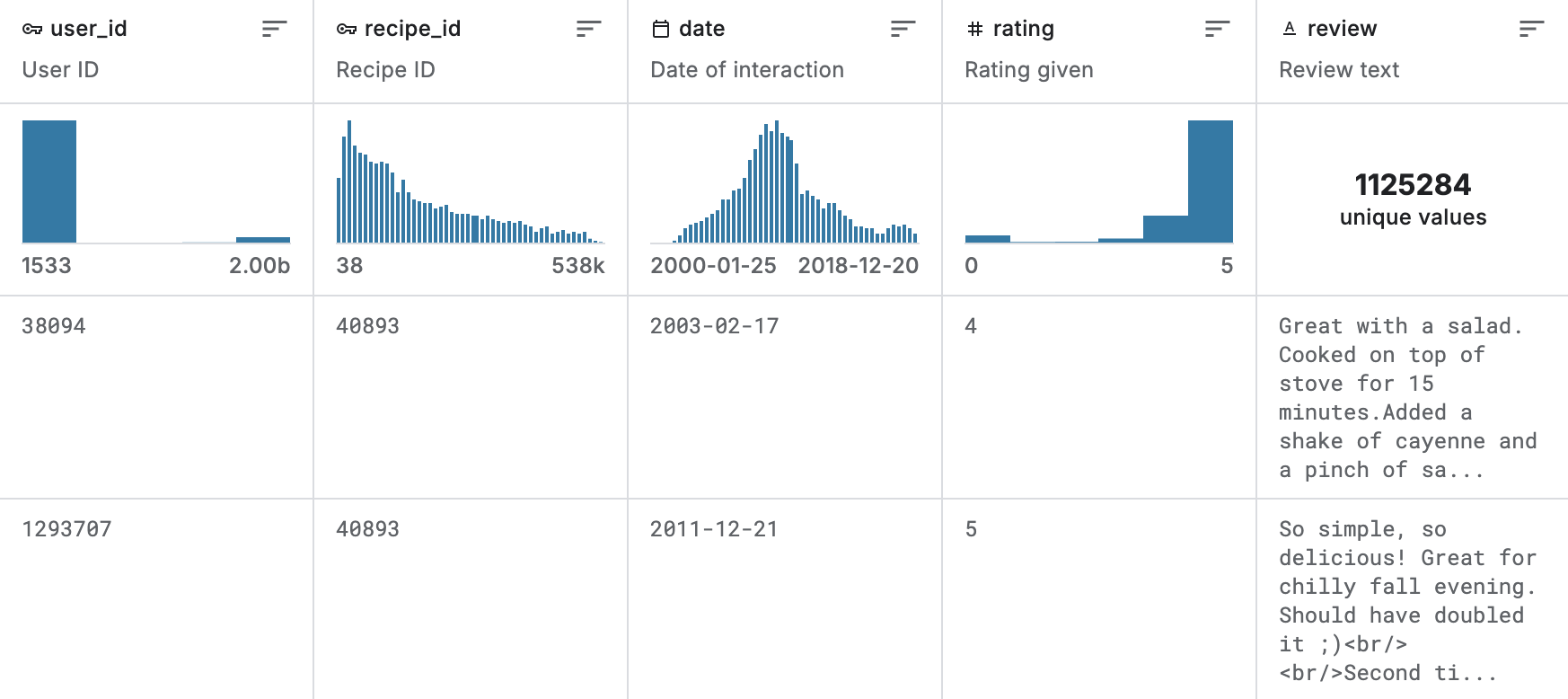

왼쪽은 상호작용 데이터를 나타내고, 오른쪽은 레시피 데이터의 일부분입니다. 더 정확한 데이터셋 모양에 대해 알고 싶으실 경우 링크를 통해 조회해주시면 감사하겠습니다.
Dataset Preprocessing
결측치 제거
데이터프레임에서 null 값을 제거했습니다.
평점 보정
상호작용 데이터셋을 살펴본 결과 특이한 부분을 발견할 수 있었습니다. 바로 유저의 리뷰 텍스트와 평점 점수가 일관되지 않는 경우입니다. 예를 들어보겠습니다. “This is a very good recipe. We also want to cut back on the fat content in our diet. Very tasty dish!!!”라는 리뷰는 매우 긍정적으로 레시피를 평가하고 있습니다. 하지만 실제로 유저가 부여한 평점은 0점이었습니다. 또 다른 리뷰는 “i made it and it was amazing”이라는 내용을 담고 있지만, 실제로 유저가 부여한 평점이 0점이었습니다. 이러한 리뷰 불일치성을 해결하기 위해 언어 모델을 활용하였습니다. 평점 보정은 다음과 같은 방식으로 진행하였습니다.
평점 보정 방식
- 리뷰 텍스트 감성 분석
- 실제 평점과 리뷰 테스트 감성 분석 점수가 3점 이상 차이나는 경우 두 개 값의 평균값으로 평점 변환
감성 분석을 위한 BERT 모델은 nlptown/bert-base-multilingual-uncased-sentiment을 사용하였습니다. 해당 모델은 주어진 텍스트에 대한 감성 분석 점수를 긍정 척도에 따라 1~5점 단위로 부여하는 모델입니다. 위에서 예시를 든 “This is a very good recipe. We also want to cut back on the fat content in our diet . Very tasty dish!!!”라는 리뷰는 감성 분석 모델을 통해 5점이라는 점수를 부여받았습니다. 이를 기존 평점인 0점과 평균을 내 최종 평점을 2.5점으로 보정하였습니다.
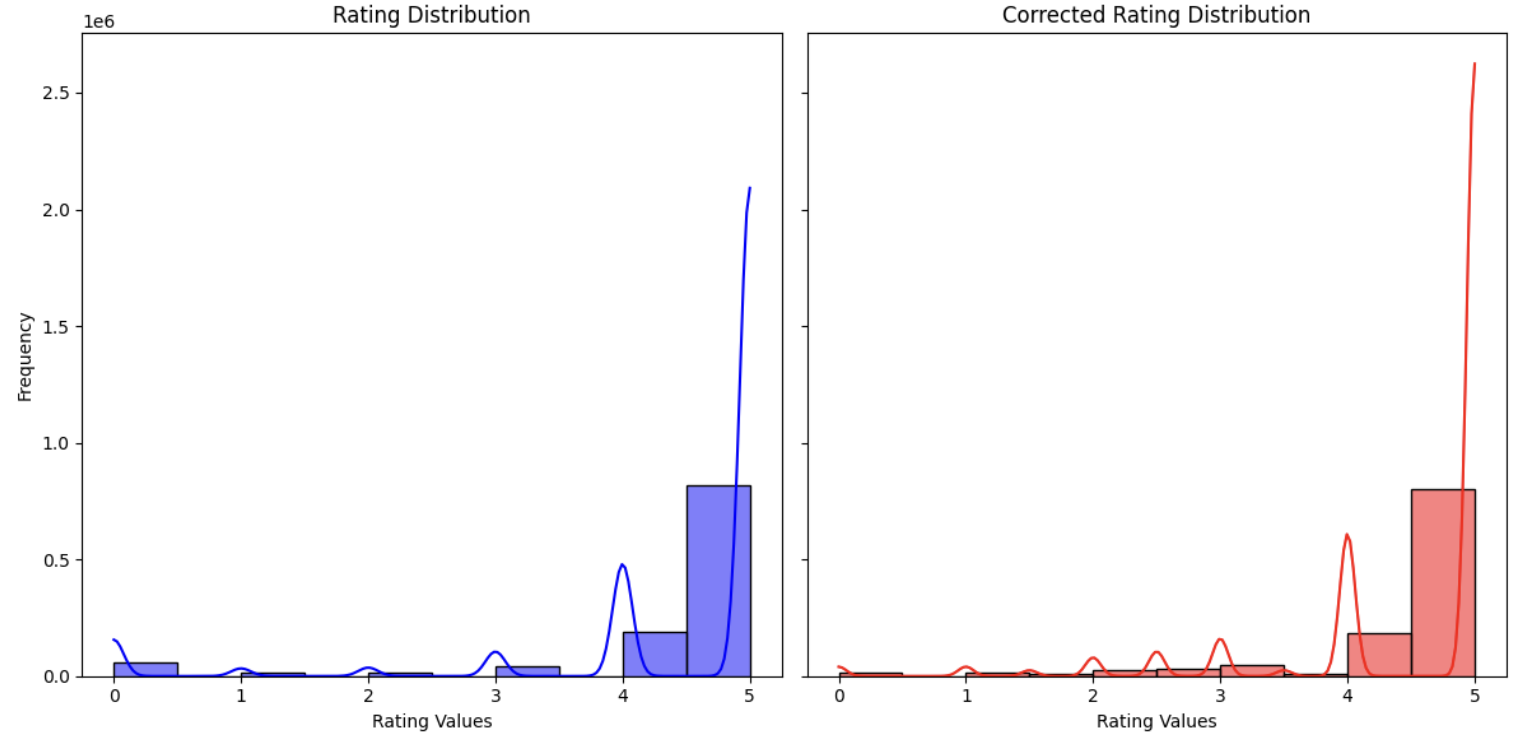
위 시각화 이미지는 평점 보정이 끝난 후 평점 분포를 보여주고 있습니다.
레시피 필터링
<자취생을 위한 요리 레시피 추천> 이라는 테마에 맞는 레시피만 사용하기 위해서 다음과 같이 레시피 일부를 필터링하였습니다.
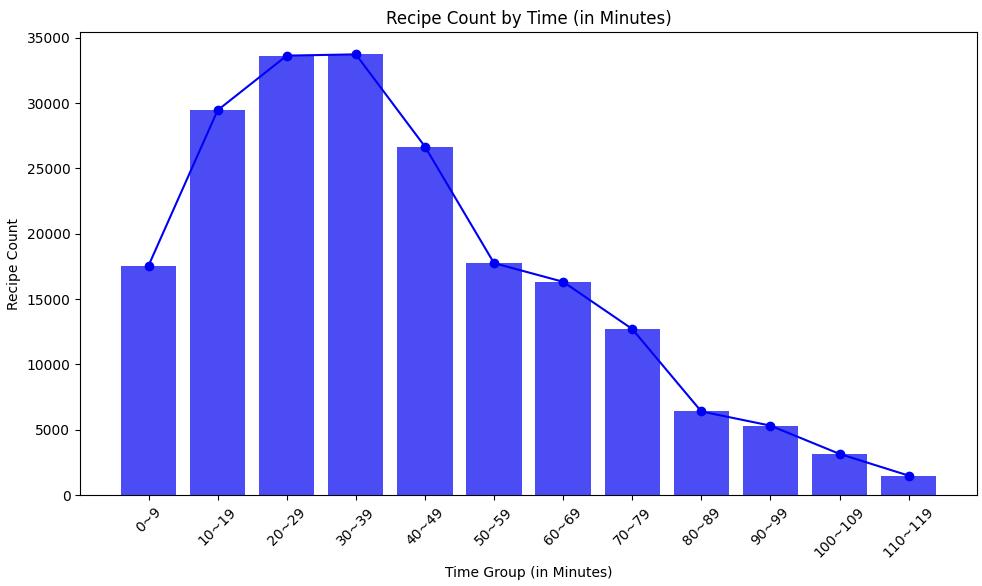
- 조리 시간이 30분이 넘는 레시피는 제거했습니다. 자취생은 보통 간단하게 끼니를 해결하는 것을 원하는 경우가 많습니다. 하지만 조리 시간이 긴 요리는 복잡하기 때문에 자취생이 해 먹기에는 부담스러울 수 있습니다. 따라서 조리 시간이 30분을 초과할 경우 추천 대상에서 제외하고자 필터링을 진행했습니다.
- 조리 과정이 나와있지 않은 레시피는 제거했습니다. 설명이 불충분한 레시피는 저품질의 레시피라고 판단하여 제거하였습니다.
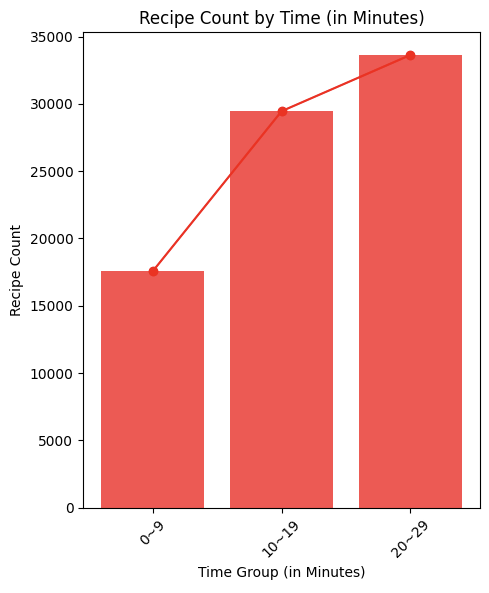
유저 필터링
- 총 리뷰 수가 2개 이하인 유저는 제외했습니다. 리뷰 수가 너무 적은 유저의 경우 신뢰도가 낮을 수 있다는 판단 하에 제거하였습니다.
- 평점 보정 이후에도, 모든 레시피에 5점을 부여한 유저는 제외했습니다. 모든 레시피에 5점을 부여한 유저가 많은 데이터셋으로 학습시킬 경우 데이터가 매우 편향되어있어 추천시스템의 추천 품질이 낮아질 수 있다고 판단하였기 때문입니다.
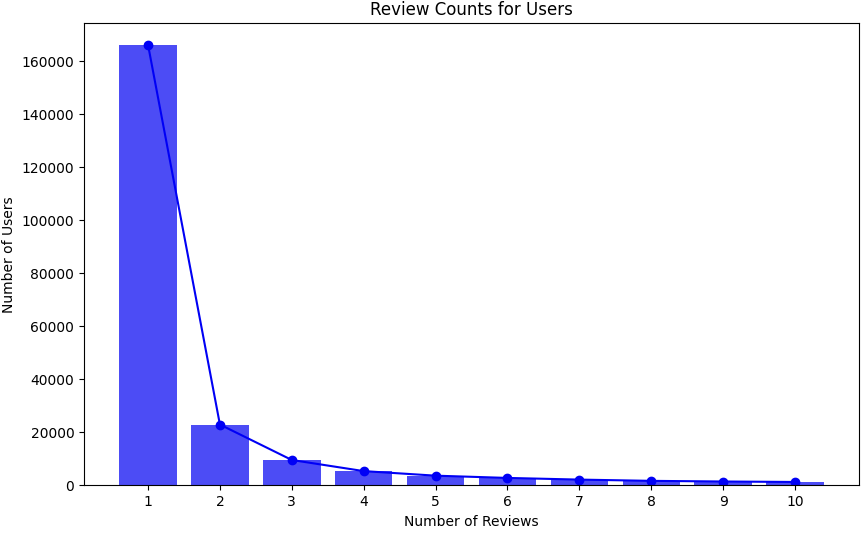
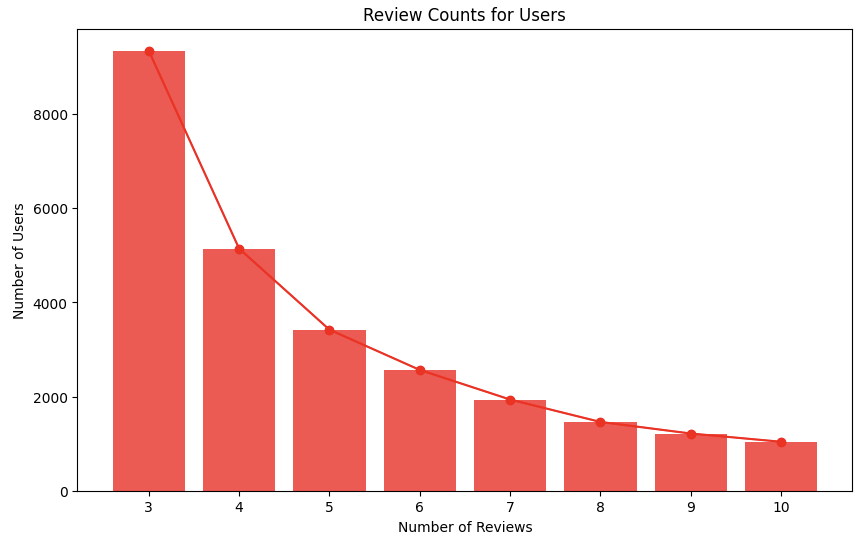
최종 데이터셋
최종 데이터셋의 크기는 다음과 같습니다.
- 유저와 레시피 간의 상호작용 데이터 : 237,084개
- 유저 수 : 9,529명
- 레시피 수 : 61,100개
추천시스템이란?
모델 소개에 앞서, 추천시스템이란 무엇일까요? 사전적인 정의는 “특정 사용자가 관심을 가질만한 정보 (영화, 음악, 책, 뉴스, 이미지, 웹 페이지 등)를 추천하는 것”입니다. (출처) 그렇다면 어떤 원리에 따라 추천을 하는 것일까요? 추천시스템은 크게 두 종류로 나눌 수 있습니다. 바로 Content-based Filtering, 그리고 Collaborative Filtering입니다.
Content-based Filtering
각 유저와 아이템의 프로필을 생성하여 특성을 파악하고, 이 프로필을 통해 유저와 맞는 아이템을 연결하는 방식입니다. 즉, 아이템과 유저의 내부 정보/특성만을 사용하여 추천을 진행하는 방식입니다. 따라서, 아이템과 유저의 상호작용 등 외부의 정보를 추천에 사용할 수 없다는 단점이 있습니다.
Collaborative Filtering
유저와 아이템 사이 관계, 그리고 아이템과 아이템 사이 상호 의존성을 분석하여 새로운 유저-아이템 연관성을 파악하고 이에 기반하여 추천을 진행하는 방식입니다. 유저의 행동(예를 들자면 아이템에 대한 클릭이나 구매), 활동을 기반으로 추천이 진행됩니다. 다만, 새로운 유저와 아이템에 대해서는 과거 행동 이력을 알 수 없기 때문에 정확도가 낮아진다는 단점이 있습니다. 이를 Cold-Start Problem이라고 부릅니다.
Models
이번 프로젝트에서 사용한 모델에 대해 알아보겠습니다.
Content-based Filtering
레시피의 재료(ingredients)와 조리 방법 (steps)를 TF-IDF 방식을 이용하여 벡터로 변환하고, 이 벡터 간 코사인 유사도를 계산함으로써 추천을 진행하는 방식입니다. TF-IDF는 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지 나타내는 통계적 수치로, 다음과 같은 수식으로 계산합니다. 여기에서 tf는 단순 빈도를 나타내며, 문서에서 해당 단어가 나타난 횟수 / 문서에 등장한 모든 단어 수로 계산할 수 있습니다. idf는 역 문서 빈도를 나타냅니다. 이 값은 총 문서의 개수 / 해당 단어를 포함하는 문서의 수 값에 log를 씌워 계산합니다.
TF-IDF는 텍스트 속성을 갖고 있는 레시피를 벡터로 변환하여
K-Nearest Neighbor
User-Item Matrix를 기반으로 유사한 사용자/아이템을 찾아내는 방식입니다. ItemKNN, UserKNN의 두 종류가 있는데, ItemKNN은 아이템끼리의 유사도를 비교하고, UserKNN은 유저끼리의 유사도를 비교합니다. User-Item Matrix란 무엇일까요?
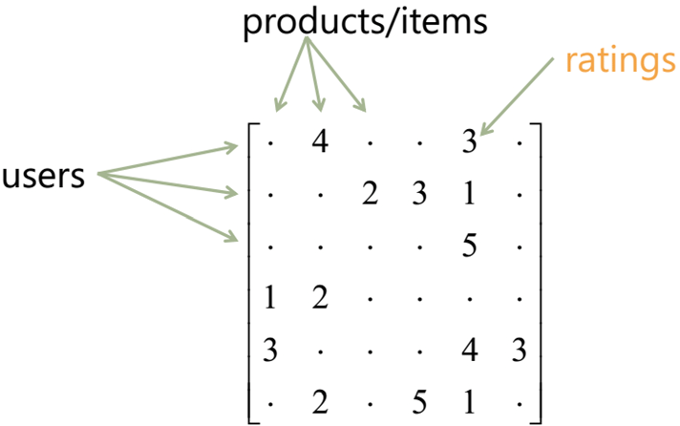
각 유저가 매긴 아이템별 평점을 행렬 형태로 만드는 것입니다. 각 행은 유저마다 할당되고, 각 열은 아이템마다 할당됩니다. 본 프로젝트에서는 아이템별로 유저가 매긴 평점 정보를 활용하여 KNN 모델을 구성하였습니다.
그렇다면 유사도는 어떻게 계산할까요? 유사도를 계산하는 방식은 여러 가지가 있지만, 코사인 유사도(Cosine Similarity)를 사용하여 프로젝트를 진행하였습니다. 코사인 유사도란 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미합니다.
가장 간단하게 KNN 모델을 구현할 수 있는 방법은 sklearn 라이브러리를 이용하는 것입니다.
from sklearn.neighbors import NearestNeighbors
knn_model = NearestNeighbors(metric='cosine', algorithm='brute')
knn_model.fit(user_item_matrix.values)Matrix Factorization
Matrix Factorization(MF) 모델의 아이디어는 아이템과 유저간의 잠재적인 패턴을 학습하여, 아이템과 유저간의 높은 일치를 보이면 추천하는 것입니다. 잠재적인 패턴은 잠재 벡터(latent feature vector)를 통해 특징화됩니다. 잠재 벡터란 우리가 흔히 생각하는 영화의 ‘장르’, 책의 ‘주제’와 비슷하게 해석될 수 있습니다.
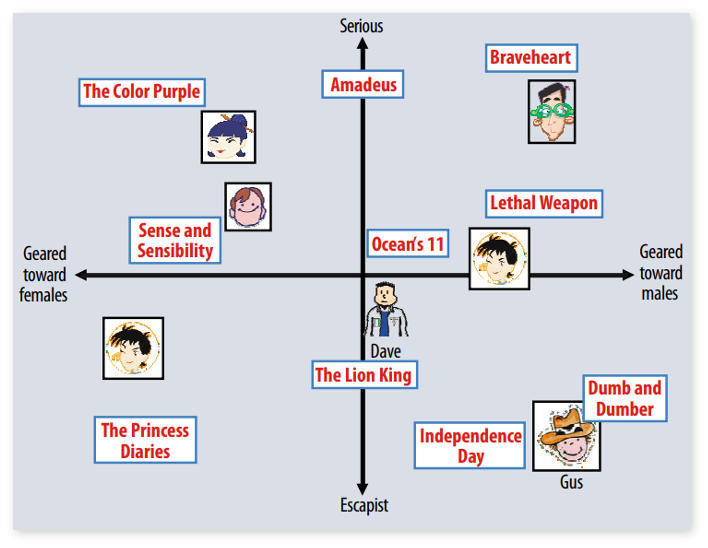
예시를 들어보겠습니다. 어떤 유저들은 역사 영화와 같이 진지한(serious) 장르를 좋아할 수도, 또 어떤 사용자들은 로맨스, 액션과 같은 오락(escapist) 영화를 좋아할 수 있습니다. 이렇듯 유저의 잠재 벡터 U가 이러한 ‘장르’에 대한 유저의 선호를 나타내고, 아이템의 잠재 벡터 V는 영화가 어느 정도 해당 장르에 속하는지를 표현합니다.
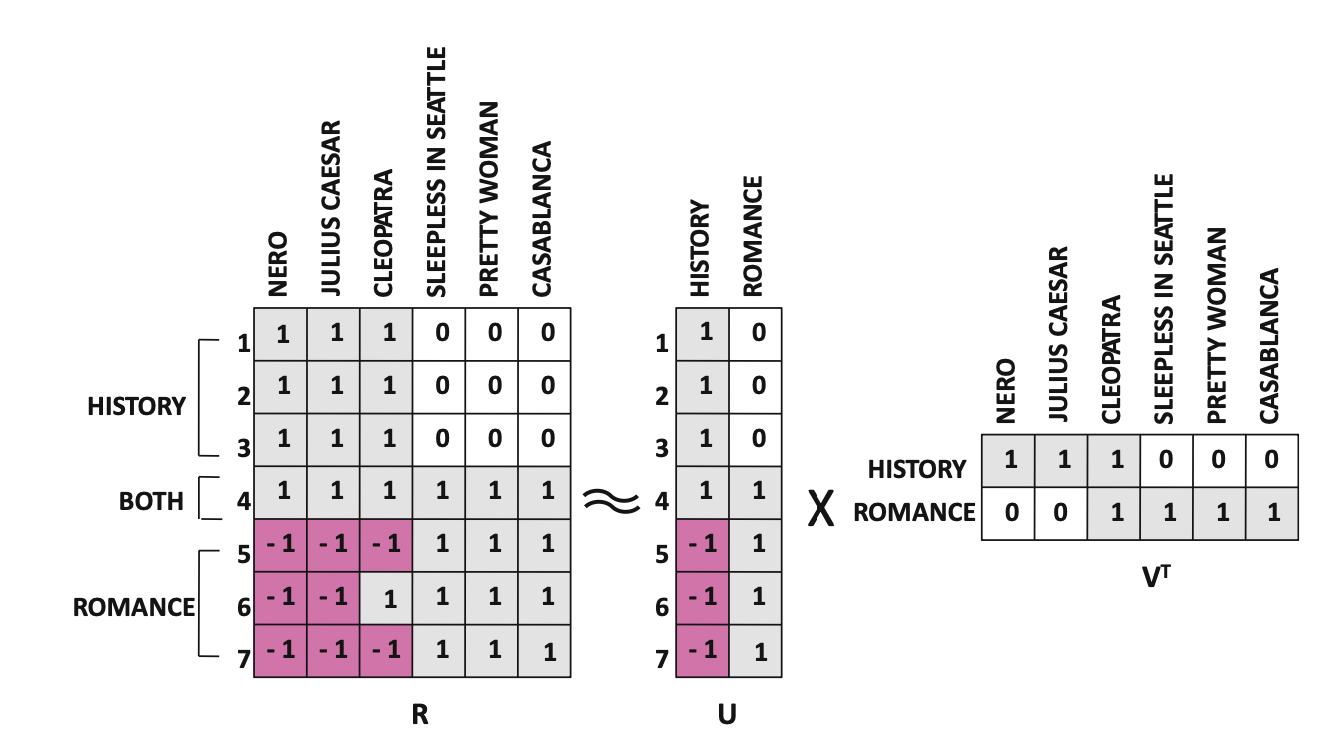
최종적으로 평점(R)을 예측할 때는 유저의 취향 벡터 U와 아이템 특성 벡터 V를 곱해서 계산합니다. 즉, "이 유저가 이 아이템을 얼마나 선호할까?"를 두 벡터의 내적(곱셈)으로 예측하여, 해당 유저가 가장 높은 평점을 줄 아이템을 추천하게 되는 것입니다.
Factorization Machines
Matrix Factorization이 주로 유저와 아이템 간의 상호작용을 단순한 2차원 행렬로 처리한다면, Factorization Machines(FM)은 훨씬 더 다양한 특성을 모델에 반영할 수 있습니다. Matrix Factorization에서는 유저와 영화간의 상호작용을 입력으로 받아 잠재벡터를 특징화한다면, 그 잠재벡터에 장르라는 특성이 녹아있다고 기대해야 합니다. 그러나 FM은 영화의 장르, 감독, 출연 배우, 개봉 년도 등 영화의 정보, 유저의 나이, 성별과 같은 유저 정보를 직접 입력으로 넣을 수 있습니다. 이를 수식으로 이해해보겠습니다.
- : 평점 예측값
- 모든 데이터에 공통으로 적용되는 편향. global bias
- : 각 특성 에 대한 가중치
- \mathbf_i: 특성 에 대한 k-차원 잠재 벡터
- \hat w_ := \langle \mathbf_i, \mathbf_j \rangle
: 두 특성의 상호작용을 모델링
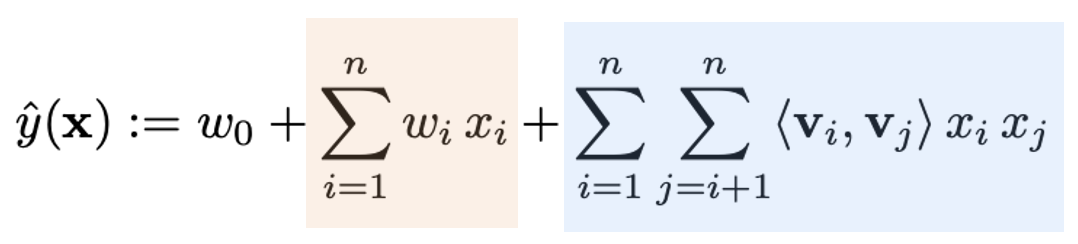
1차 상호작용 항은 일반적인 선형 회귀 모델처럼 각 변수에 가중치를 곱해 더한 값입니다. 그리고 2차 상호작용 항이 바로 FM 모델의 핵심입니다. 변수 간의 상호작용을 잠재 벡터의 내적으로 계산하므로 상호작용 항을 별도로 정의하지 않더라도 데이터에서 자동으로 중요한 상호작용을 학습할 수 있습니다. 현재 수식은 2차원의 경우이나, 이를 k차원으로 확장하면 다양한 특성 간 상호작용을 학습하여 모델에 반영할 수 있다는 장점을 갖습니다. 또한, 고차원의 매우 희소한(sparse) 데이터를 다룰 수 있다는 엄청난 장점을 갖습니다. 일반적인 모델에서는 많은 특성들이 비어있는 희소한 데이터에서 성능이 저하되지만, FM은 이러한 희소한 데이터에서도 잠재 벡터를 사용해 유효한 패턴을 학습할 수 있습니다. 이는 추천시스템의 특성상 유저-아이템 행렬이 매우 희소한 형태를 갖는 데이터를 효과적으로 다룰 수 있게 해줍니다. 결국 이러한 모델 구조는 다항 회귀를 희소한 데이터에서도 사용할 수 있도록 일반화한 형태로 이해할 수 있습니다.
Modelling
평가 지표
추천시스템 모델의 평가 지표는 일반적인 인공지능 모델과 비슷하지만 다른 지표를 사용합니다. 본 프로젝트에서는 Precision@5라는 지표를 사용하였습니다. 우선 일반적으로, Precision은 예측값 중 옳게 예측한 비율을 의미합니다.
하지만 추천시스템의 Precision은 모델이 추천한 아이템 중 유저가 실제로 관심을 가진 아이템의 비율을 의미합니다. 따라서, Precision@k는 추천시스템 모델을 통해 도출해낸 k개의 추천 결과 중 실제로 유저가 관심을 가진 아이템의 비율을 나타내는 지표입니다.
모델별 추천성능 비교
프로젝트에서 사용된 모델에 대한 추천 성능을 비교해보겠습니다. PopRec(인기도 추천 시스템)은 단순히 가장 많이 선택되거나 평가가 높은 아이템을 추천하는 방식입니다. 이 모델은 사용자의 개별 취향이나 행동 패턴을 반영하지 않으나, 생각보다 나쁘지 않은 성능을 보입니다. 가장 인기 있는 아이템은 많은 사용자가 선호하기 때문에, 유저 중 상당수가 인기 있는 아이템을 선택할 가능성이 있습니다. 따라서, 보통 Baseline 모델로 많이 사용되며, 다양한 추천 시스템의 성능 평가에서 좋은 출발점을 제공해줍니다.
모델 Test Precision@5
PopRec (Baseline) 0.0029
UserKNN 0.0038
Matrix Factorization 0.0081
Factorization Machine 0.0123
평가지표로 비교하니 잘 와닿지 않으시죠? 실제 케이스로 추천 결과를 확인해봅시다.

예시로, 새로운 유저가 위와 같은 세 가지 레시피를 선호한다고 선택한다면, Matrix Factorization 모델은 quick chiken, caramel apples in rum sauce, flavored onion rice with brocolli를 추천해주었습니다.
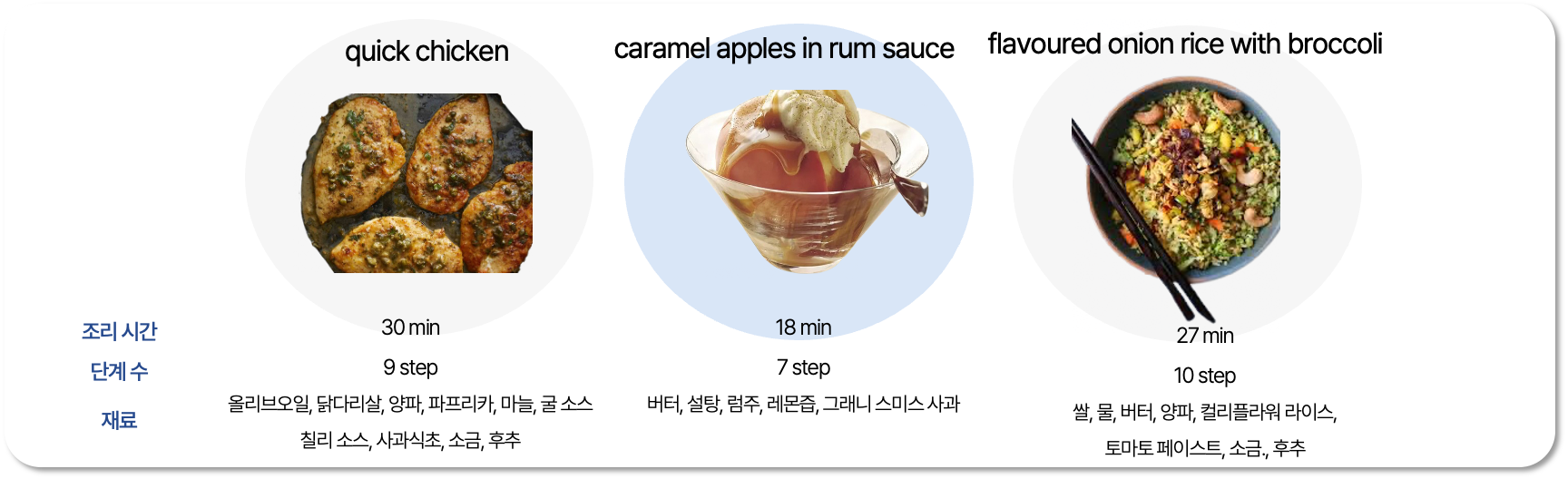
이는 아래와 같이 (레시피 스타일에 대한 이 유저의 선호)X(이 레시피가 어느 정도 해당 스타일에 속하는지)의 결과로 유저가 이 아이템을 얼마나 선호할까에 대한 정도를 평점으로 예측한 결과입니다.

다음으로, Factorization Machine의 추천 결과입니다.

Conclusion
Limitations & Future Works
추천시스템은 다른 인공지능 모델과 달리 정확도가 높은 편이 아닙니다. 따라서 추천의 품질을 높이기 위한 방법에 대해서 더 연구해보아야 합니다. 또한 프로젝트에서 사용한 Food.com 데이터셋은 영미 문화권 데이터셋으로 한국의 자취생들에게 레시피 추천을 진행하기에는 문화적으로 맞지 않을 가능성이 높습니다. 실제로 데이터셋을 확인해본 결과 대부분의 요리가 양식에 집중되어있다는 사실을 확인할 수 있습니다. 따라서 한국에서 사용할 수 있는 진짜 <자메추> 서비스를 구현하기 위해서는 한국 레시피를 데이터를 구하거나, Food.com 데이터셋을 한글화하는 방식이 필요합니다. 마지막으로 프로젝트를 구체화하여 실제 서비스로 확대하는 방안도 생각해보아야 합니다.