
Preliminary
자율주행이란?
2023 CVPR Workshop - Ashok Elluswamy, Tesla
자율주행(Autonomous Driving)은 운전자가 직접 조작하지 않아도 차량이 주변 환경을 인식하여 스스로 주행하는 것입니다. 카메라, 레이더, 라이다 등의 센서를 통해 데이터를 수집하고, 이를 기반으로 알고리즘이 주행 경로를 계획합니다.
Setup

Nvidia Jetson Orin Nano 8GB : 임베디드 AI 및 엣지 컴퓨팅을 위한 플랫폼으로, 대규모 데이터 처리와 병렬 연산에 적합하며, JetPack SDK와 호환되어 TensorFlow, PyTorch 등 주요 딥러닝 프레임워크와의 통합이 용이합니다. TensorRT와 DeepStream SDK를 지원해 AI 모델 최적화와 실시간 비디오 분석 작업을 수행할 수 있습니다.

Nvidia Jetracer : NVIDIA Jetson 플랫폼을 기반으로 한 DIY(Do-It-Yourself) 자율주행 로봇 자동차 키트입니다. JetRacer는 NVIDIA의 Jetson Nano 또는 Jetson Xavier NX를 활용하여 인공지능(AI) 모델을 통해 자율주행 기능을 구현할 수 있도록 설계되었습니다.

CSI Camera : CSI Camera는 Camera Serial Interface의 약자로, 디지털 카메라 센서를 시스템 온 칩(SoC)에 직접 연결하는 표준 인터페이스입니다. 주로 NVIDIA Jetson 시리즈와 같은 임베디드 시스템에서 사용되며, 고속 데이터 전송과 저전력 소비가 특징입니다.
Overview
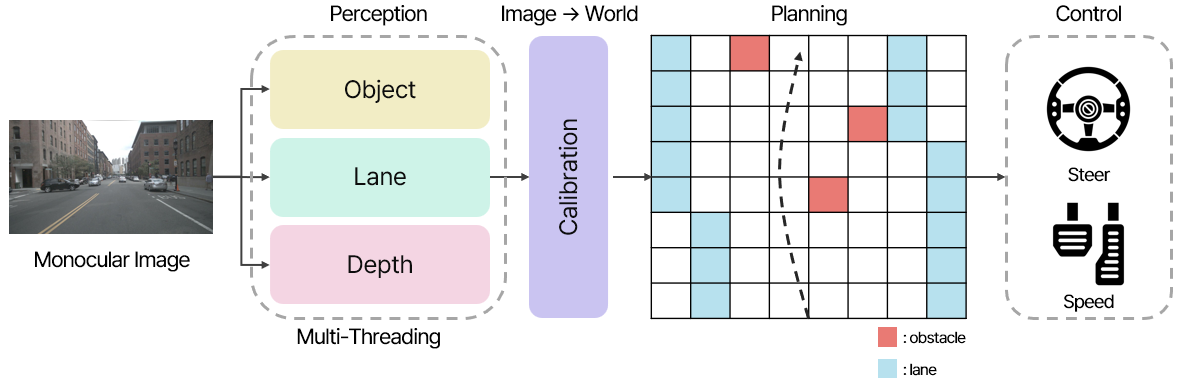
- Perception
자율주행 시스템에서 입력된 Monocular Image를 처리하여 주행에 필요한 주요 정보를 추출하는 단계입니다. 이를 통해 차량은 주변 환경을 이해하고, 적절한 주행 결정을 내릴 수 있습니다.
- Object (객체 탐지):
- 차량 주변의 장애물이나 보행자, 차량 등의 객체를 탐지합니다.
- 이 과정은 안전한 경로를 계획하기 위해 필수적입니다.
- Lane (차선 인식):
- 도로의 차선을 인식하고 차량의 위치를 차선 기준으로 파악합니다.
- 안정적인 주행을 위해 차선 중심을 유지하거나 차선 변경에 필요한 정보를 제공합니다.
- Depth (깊이 추정):
- 단안 카메라 데이터를 기반으로 주변 객체와의 거리(깊이)를 추정합니다.
- 이 정보는 장애물 회피 및 주행 경로 계획에 활용됩니다.
- Calibration
3차원 공간의 정보를 2차원 평면(이미지 센서)에 정확히 매핑하기 위해 카메라와 센서의 관계를 조정하는 과정입니다. Perception 단계에서 추출된 정보(객체, 차선, 깊이 등)를 차량의 물리적 환경에 맞게 조정하여, 주행 계획(Planning)과 제어(Control)에 사용할 수 있도록 변환합니다.
- Planning
A* 알고리즘으로 장애물과 차선을 고려하여 이동 경로를 계산하였습니다.
- Control
Control 부분은 자율주행 시스템의 최종 단계로, Planning 단계에서 생성된 경로와 정보를 기반으로 차량의 실제 움직임을 제어하는 역할을 수행합니다. 이 단계는 차량이 원하는 방향으로 안정적으로 주행할 수 있도록 물리적인 동작을 명령합니다.
- Steer (조향 제어):
- 주행 경로와 현재 차량의 방향을 바탕으로 핸들의 각도를 조정하여 차량의 진행 방향을 제어합니다.
- 장애물을 회피하거나 차선 중앙을 유지하는 등 차량의 방향성을 결정합니다.
- Speed (속도 제어):
- 장애물 거리, 차선 정보, 목표 속도 등을 고려하여 가속 및 감속 페달을 제어합니다.
- 정지선에서의 정차, 속도 제한 준수, 장애물 회피를 위해 차량의 속도를 조정합니다.
Model
Object Detection | YOLOv8
Object Detection이란?

Object detection은 이미지 내의 물체들의 위치를 찾고, 구분하는 기술입니다. 물체의 영역을 Bounding Box로 표시하고, Bounding Box에 존재하는 물체를 label로 분류합니다.
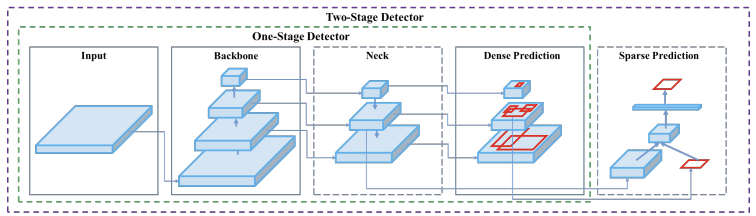
Object detection 모델은 one stage와 two stage로 나뉘는데, two stage는 객체를 검출하는 데 시간이 오래 걸린다는 단점이 있습니다. 따라서 자율주행과 같이 실시간으로 사물의 위치를 파악해야하는 작업에서 사용하기 어려웠습니다. 이를 해결하기 위한 방식이 one stage detector이고, 대표적인 모델로 YOLO가 있습니다. YOLO는 classification과 localization을 동시에 하여 실시간(real time)으로 객체 검출이 가능한 모델입니다.
YOLO의 특징 및 동작 과정
- You Only Look Once
YOLO 이전의 R-CNN과 같은 모델들은 이미지를 여러 번 분석해서 시간이 오래걸렸지만, YOLO는 이미지를 한 번 보고도 바로 객체를 검출할 수 있어서 실시간으로 객체를 탐지할 수 있습니다.
- One stage detection
기존 모델들은 region proposal, feature extraction, classification과 bbox regression의 과정을 별도로 수행했지만, YOLO는 한 모델로 앞 과정들을 한 번에 진행합니다. 따라서 속도가 빠르다는 장점이 있습니다.
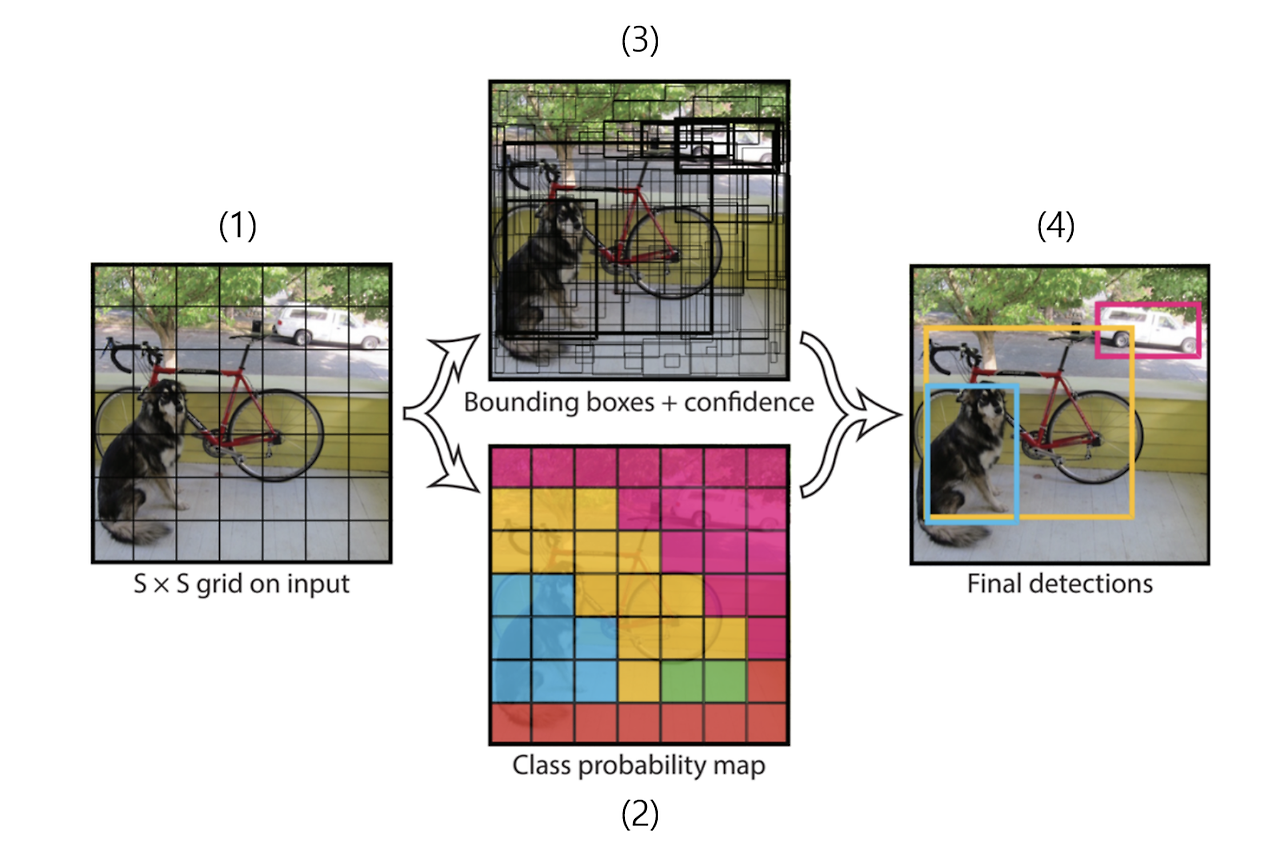
YOLO는 CNN을 기반으로 feature을 추출한 후, 이를 통해 물체의 종류와 위치를 예측합니다. Input 이미지가 들어오면 S x S 그리드로 영역을 나눕니다. (1) 각 그리드 영역에 대해 bounding box와 confidence를 예측하여 사물의 위치를 파악합니다. (2) confidence가 높을수록 bounding box를 굵게 그립니다. 동시에 사물의 종류에 대한 classification 작업이 진행됩니다. (3) 최종적으로 NMS(Non-Maximum Suppression) 알고리즘을 통해 confidence가 높은 예측 결과만 남깁니다. 즉, 굵게 표시된 bounding box만 남고, 사물이 있을 확률이 낮은 box들은 지워집니다.
YOLO Architecture
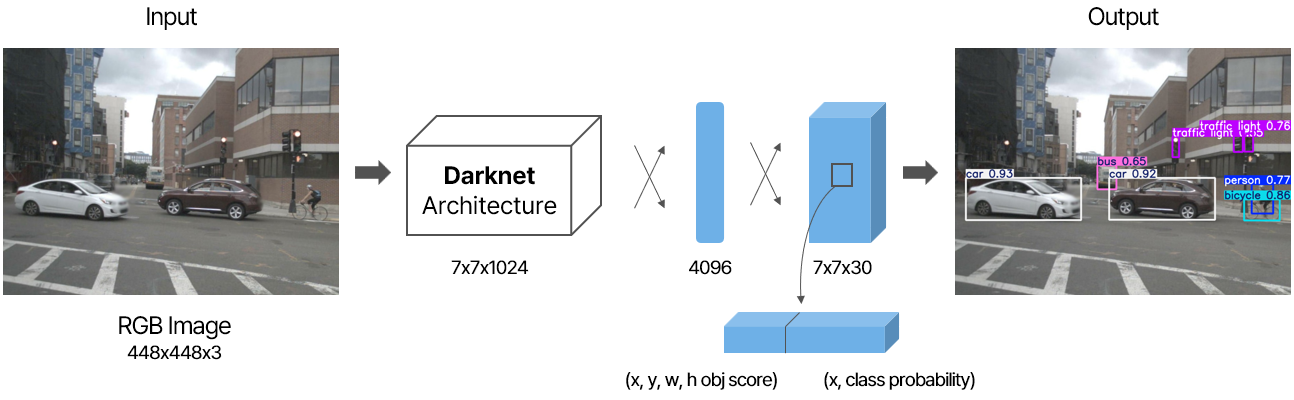
YOLO에서 backbone으로 Darknet이 사용되는데, Darknet은 경량화된 CNN 기반의 네트워크입니다. Backbone은 feature를 추출하는 역할을 합니다. Darknet으로 feature를 추출하고, convolution network를 거쳐서 bounding box 좌표와 class의 confidence를 예측하여 객체의 위치와 종류를 탐지합니다.
YOLO는 2015년부터 현재까지 v11까지 나왔는데, v8을 사용하였습니다.
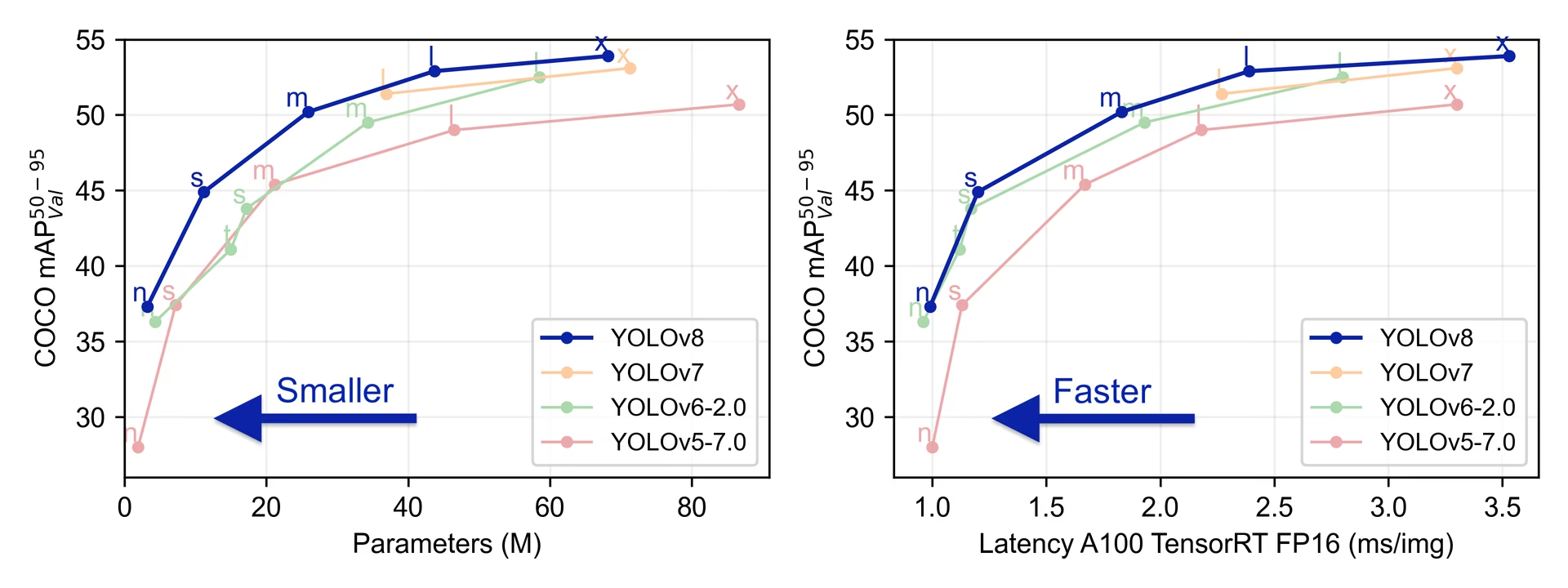
YOLOv8은 기존 버전의 모델들과 달리 anchor-free head를 사용하여 anchor-based에 비해 더 나은 정확도와 효율적인 detection을 수행합니다.
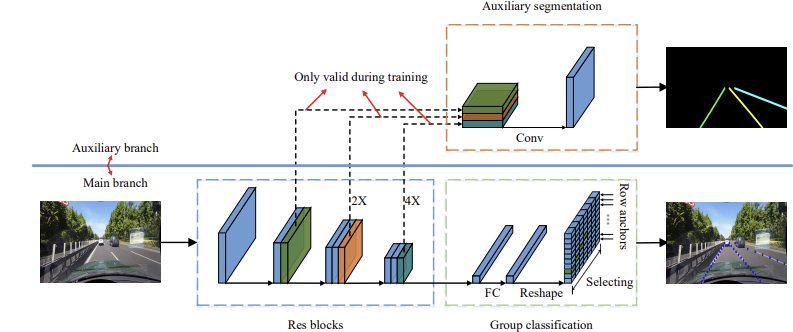
Lane Detection | Ultra Fast Lane Detection (UFLD)
차량이 스스로 주행할 때 차선을 잘 따라가는 것도 중요한 태스크이기 때문에, Perception 단계에서 lane detection 과정도 거쳤습니다.
기존의 차선 인식은 segmentation 기반으로 이루어졌습니다.

Segmentation으로 차선을 탐지할 경우, 이미지 픽셀을 분할하여 binary feature로 표현해서 차선의 직선, 곡선 정보를 활용하기 어렵다는 단점이 있었습니다. 또한 전체 이미지를 픽셀 단위로 분석해야 하기 때문에 computational cost가 높다는 단점이 있었습니다. 또한, 주변 물체에 차선이 가려지거나, 너무 어둡거나 밝아서 차선이 제대로 파악되지 않는 no-visual-clue 문제가 있습니다. 이를 해결하기 위해서는 receptive field를 확장해야 합니다.
따라서, UFLD에서는 연산량을 줄여서 추론 속도를 줄이고, 차선이 잘 보이지 않는 경우 발생하는 no-visual-clue 문제를 해결하기 위한 방법을 제안했습니다. 이를 통해 자율주행에서 요구되는 빠르고 정확한 차선 탐지에 적합한 방식을 제공하였습니다.

Task: 각 행(anchor)에서 특정 위치(cell) 선택하여 차선 좌표 예측
Depth Estimation | Metric 3D
Camera Parameters

카메라는 우리가 보고 있는 3차원 세상을 2차원 평면으로 기록하게 도와주는 도구입니다. 그런데, 위 사진과 같이 같은 물체를 찍더라도 찍는 각도가 다르거나(카메라 위치, 각도 변경), Zoom In/Out(카메라 고유 설정 변경)을 한다면 모두 다른 모습으로 기록될 것 입니다. 그 이유는, 바로 카메라 파라미터를 변화시겼기 때문입니다.
카메라 파라미터에는 카메라 외부 파라미터(Camera Extrinsics) 그리고 카메라 내부 파라미터(Camera Intrinsics)가 있습니다. 카메라 외부 파라미터는 카메라의 위치 및 방향 정보를 담고 있고, 카메라 내부 파라미터는 초점거리, 주점의 위치, 비대칭 계수 등 카메라 고유의 설정 정보를 담고 있습니다.
자율주행할때 전방 카메라가 찍은 2차원 사진만으로 자동차 앞의 3차원 세상이 실제로 어떻게 생겼을 지 알아낼 수 있다면 얼마나 좋겠습니까? 이를 위해서는 카메라에 찍힌 2차원 이미지와 카메라로 찍은 실제 3차원 세상과의 관계를 아는 것이 굉장히 중요합니다. 이 2차원과 3차원의 관계에 대한 정보를 담고 있는 것이 바로 카메라 파라미터입니다.
Camera Calibration
카메라 파라미터의 정확한 값을 구하는 과정을 Camera Calibration이라고 하고, 과정은 4단계로 진행됩니다.
Step 1. 세계 좌표계 설정 Step 2. 여러 각도로 체커보드 촬영 Step 3. 체커보드에서 꼭짓점 인식 후 이미지 좌표점 추출 Step 4. 세계 좌표점과 이미지 좌표점을 활용해 카메라 파라미터 값 계산
: 카메라의 내부 파라미터를 이용해 3D 좌표를 2D 이미지로 투영한 값 : 실제 이미지에서 추출한 2D 점
Depth Estimation
사진을 촬영한 카메라와 사진 속 물체와의 거리를 알아내는 것을 Depth Estimation이라고 합니다. 공학자들은 다양한 논문에서 Depth Estimation 모델들을 제시했습니다. 그러나 기존 모델들은 카메라 일반화 성능이 떨어지거나, Metric Depth를 측정하지 못하는 한계점을 보였습니다.
카메라 일반화 성능이 떨어진다는 의미는 다양한 카메라로 찍은 사진의 깊이를 일관된 성능으로 측정하지 못함을 의미합니다. 제 카메라로 찍은 사진과 제 친구 카메라로 찍은 사진에서 깊이 추정 성능이 다르게 나타나는 문제입니다. 깊이 추정을 위해서 정해진 하나의 카메라만을 사용해야한다는 것은 굉장히 불편할 것 같지 않습니까?
Metric Depth를 측정하지 못한다는 것은 정확한 깊이를 측정하지 못함을 의미합니다. 기존 모델에서는 정확한 깊이를 측정하는 것이 아닌, 깊이의 상대적 비율을 측정하는 방식을 취했습니다. 정확한 깊이 값이 중요한 자율주행 도메인에서는 해결해야하는 필수적인 문제입니다.
Metric Ambiguity : 사진만 보고 정확한 깊이 추정은 불가능하다


사진 속 두 의자는 모두 카메라에서 비슷한 거리에 떨어져있다고 보입니다. 하지만 사실은 왼쪽 의자는 카메라로부터 2m, 오른쪽 의자는 카메라로부터 1m 떨어져있습니다. 이유는 서로 다른 카메라로 찍었기 때문입니다. 더 구체적으로는 초점거리가 2배 차이나는 카메라를 사용했기 때문입니다.
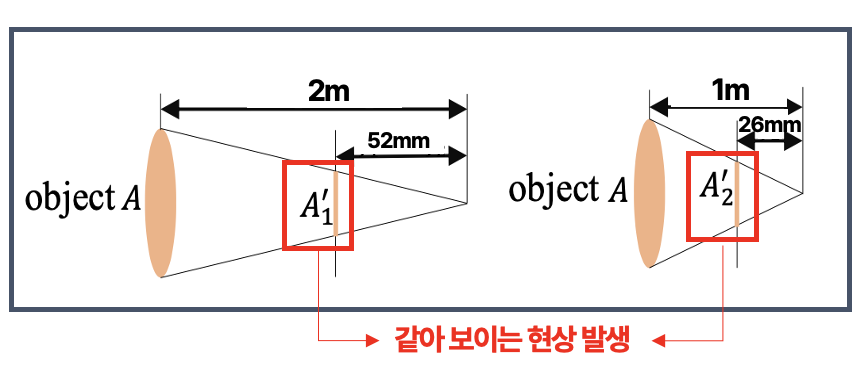
위 상황을 간단히 도식화한 것입니다. object A(의자)를 서로 다른 두 개의 카메라가 촬영하는데, 좌측, 우측 카메라의 초점거리는 각각 52mm, 26mm입니다. 비례관계에 의해 두 개의 이미지 , 는 같아 보이는 것입니다.
Metric3D
Metric Ambiguity 문제를 해결한 새로운 모델이 등장했는데 바로 Metric3D 입니다. 가상의 기준 카메라를 생각하고, 모든 이미지든 기준 카메라로 찍은 것 처럼 변환하는 Canonical Camera Transformation 과정을 추가하는 방식을 적용합니다. 이렇게 하면 카메라 일반화 성능이 높아지고, Metric Depth를 정확히 측정할 수 있게 됩니다. 또한, Random Proposal Normalization Loss를 활용해 이미지를 조각내어 이미지의 더욱 세밀한 부분의 깊이 추정이 가능하도록 했습니다.
Metric3D 모델은 Zero-shot Depth Estimation(처음 보는 사진 속 물체의 깊이 추정)과 3D reconstruction(3D 재구성) 벤치마크에서 SOTA 성능을 달성하며 성공적인 모델이 되었습니다. 자율주행을 할 때는 Metric Depth(정확한 깊이)를 알아야 안전을 보장할 수 있습니다.
그래서 이번 프로젝트에서는 Metric3D를 Depth Estimation 기준 모델로 선정했습니다.
Occupancy
깊이 추정의 목적
깊이 추정은 차량 주변환경에 대한 지도를 만드는 데 큰 도움을 줍니다. Metric3D 모델로 깊이 추정을 진행했으니, 이제 지도를 만들어야 할 시간입니다. 지도를 만드는 것은 3차원 세상을 보기좋게 표현하는 것과 같습니다. 다양한 3차원 표현 방식 중 어떤 방식이 자율주행을 할 때 가장 효과적일지 알아봅시다.
3차원 세상을 표현하는 법

다양한 3차원 표현 방식이 존재하지만, 그 중 자율주행 도메인에서는 Occupancy Map이 자주 사용됩니다. 3차원 세상을 voxel이라는 작은 영역(ex. 정육면체)으로 나눈 뒤, voxel 안에 물체가 포함되는 지 여부를 통해 세상을 표현하는 방식입니다. voxel은 부피를 의미하는 volumn과 pixel의 합성어입니다. 이외에도 점으로 세상을 표현하는 pointcloud, 다각형으로 세상을 표현하는 mesh가 있지만 연산 정확성 및 효율성을 고려하면 Occupancy Map이 자율주행 시 최선의 선택입니다.
Occupancy Map

Occupancy Map에는 3D 버전과 2D 버전이 있습니다. 3D Occupancy Map은 차량 주변환경을 3차원으로 확인할 수 있는 반면, 2D Occupancy Map은 새가 하늘에서 땅을 바라보는 관점(a.k.a Bird’s Eye View)으로 주변환경을 2차원으로 확인할 수 있습니다.
이번 프로젝트에서의 자동차는 오르막길, 내리막길을 가지 않습니다. 자동차의 방향의 자유도를 제한하여 자율주행의 코어 영역 구현에 집중하자는 의도입니다. 2D Occupancy Map 만으로도 주변환경을 모두 파악할 수 있습니다.
그래서 이번 프로젝트에서는 2D Occupancy Map을 주변환경을 표현하는 방식으로 선정했습니다.
Occupancy Network : Tesla에서 사용하는 Occupancy Map

자율주행에서 Tesla를 빼놓고 이야기할 수 없습니다. Tesla에서는 2022년 Occupancy Network를 발표했는데, 간단히 말하면 차량 주변 이미지만으로 시간정보를 포함하는 3D Occupancy Map을 실시간으로 생성하는 모델입니다. 이는 차량/물체 간 충돌 방지에 큰 기여를 했습니다.
구체적인 파이프라인은 다음과 같습니다. 먼저, 8개의 카메라를 사용해 차량 주변의 이미지를 수집합니다. 그 후 이미지들을 RegNet 이나 BiFPNs와 같은 백본 네트워크를 통과시켜 특징 정보를 추출합니다. 추출된 특징은 attention module을 지나 3D Occupancy Map인 Occupancy Feature Volumn(이하 OFV)으로 변환됩니다. 그러나 OFV는 순간의 정보이기 때문에 주변 물체의 운동상태에 대한 정보는 없다는 단점이 있습니다. 물체의 운동상태를 알기 위해서는 두 개 이상의 시각에 대한 위치 정보를 알고 있어야 하기 때문이죠. 이러한 이유로 Occupancy Network는 이전 timestamp에 생성한 OFV들도 함께 활용합니다. 즉, 현재와 과거의 순간들에서 포착한 OFV들을 융합해 4D Occupancy grid를 생성합니다. 이는 물체의 운동상태가 포함된 3D Occupancy Map입니다.
Planning
Planning 파트에서는, 이전 단계인 Depth Estimation 결과로 만들어진 Occupancy Map을 Input으로 받아 차의 이동 경로를 탐색합니다. 크게는 **A* 알고리즘으로 goal까지 전체 경로를 생성한 후, 경로를 따라가다 장애물을 마주치면 장애물이 적은 쪽으로 방향을 전환하도록** 하였습니다. 즉, A* 알고리즘으로 전체적인 경로를 구성하고 Occupancy map 기반으로 방향을 제어하도록 하여 보완했습니다. 각각 어떤 것인지 하나씩 살펴보겠습니다.
**A* 알고리즘** A* 알고리즘은 주어진 출발 노트부터 목표 노드까지의 최단 경로를 찾아내는 그래프 탐색 알고리즘으로, 다익스트라 알고리즘을 확장한 것입니다.
알고리즘 적용 예시
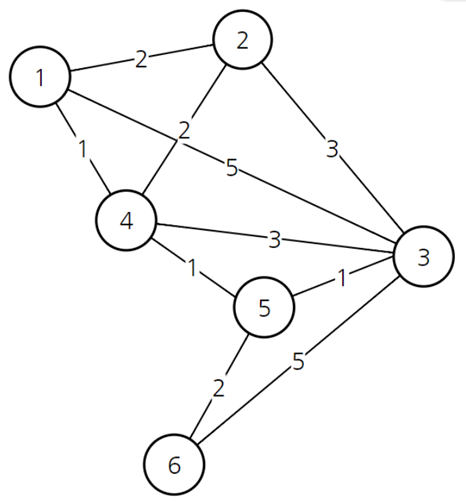
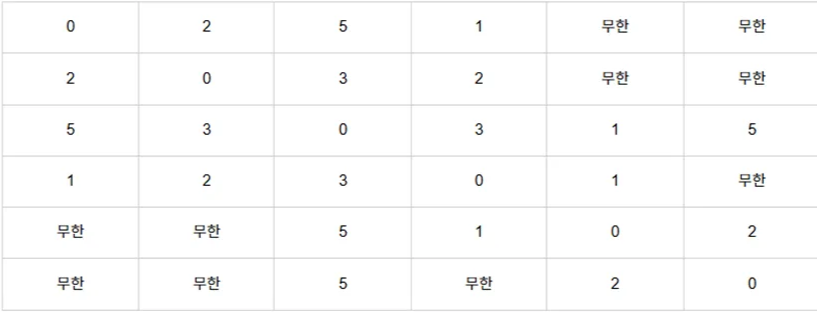
이 사례에 대해서 다익스트라 알고리즘을 적용해보면 다음과 같습니다.
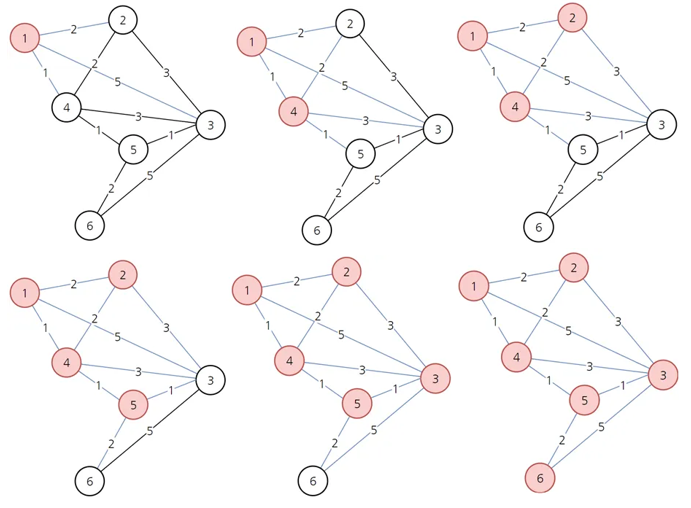
위와 같이, 직전에 선택된 노드를 거쳐갈 때의 거리와, 기존의 거리와 비교하여 더 짧은 값을 배열에 포함시키며 업데이트합니다.
두 알고리즘은 어떤 차이가 있을까요? 다익스트라 알고리즘은 지금까지 가장 최소의 비용으로 도달한 지점부터 탐색하는 알고리즘인 반면, A 알고리즘은 현재 상태에서 다음 상태로 이동할 때의 비용을 나타내는 휴리스틱 함수를 함께 사용한다는 점에서 차이가 납니다. 이 차이를 이해하기 위해 A 알고리즘을 설명하는 공식을 살펴보면 다음과 같습니다.
A* 알고리즘의 순서와 함께, 알고리즘을 적용한 예시를 살펴보면, 다음과 같습니다. Start node와 End node가 정해져 있는 Occupancy map에서, 출발 노드 부터 인접한 사각형을 확인하며 최소 비용을 가지는 지점들을 이어서 경로를 만듭니다. 피타고라스 정리를 활용하여 가로 한 칸 당 이동 거리는 10, 대각선 이동 거리는 한 칸 당 14라고 가정합니다.
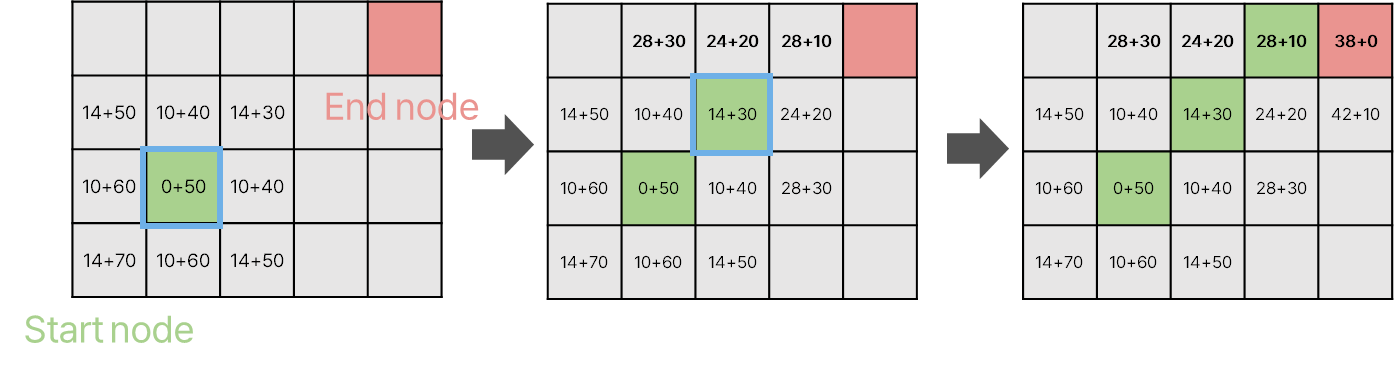
탐색 종료 조건은, (1) 경로 탐색 종료 목적 사각형을 ‘열린 목록’에 포함하는 경우 (2) 열린 목록이 비게 되는 경우 (목표사각형을 찾는데 실패한 경우이다. 이 경우에는 길이 없는 경우임.) 이 둘 중 하나를 만족할 경우입니다. 그럼 아래와 같이, 최소의 비용을 갖는 노드끼리 이었기 때문에 최종적으로 다 이은 경로는 최단 경로가 된다는 것을 알 수 있습니다.
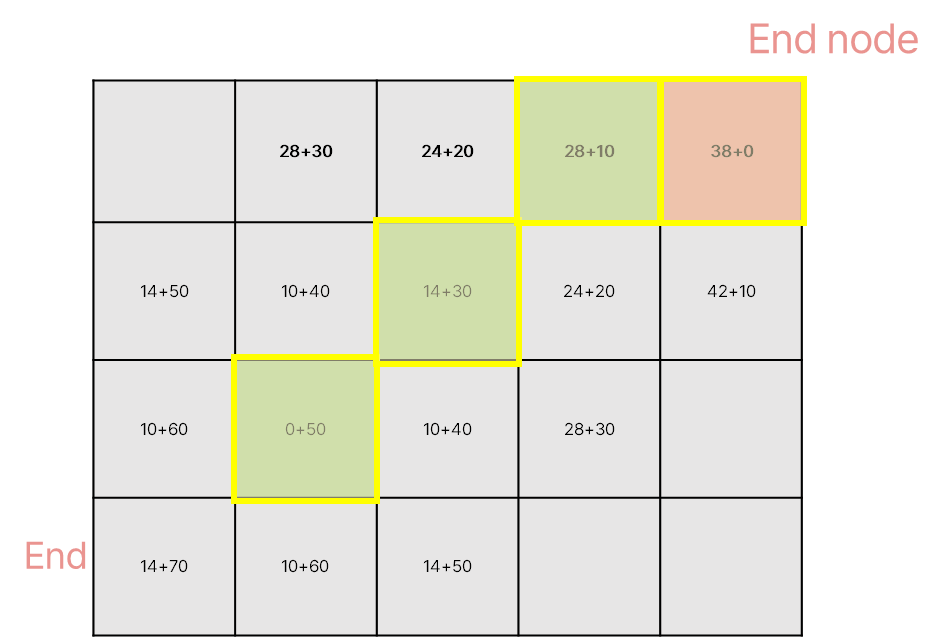
이렇게 경로를 찾으면, 다익스트라 알고리즘보다 속도는 빠르면서 현재 위치와 목표 지점까지의 비용까지 고려한 최단 경로를 찾아낼 수 있습니다.
Occupancy map 기반 방향 제어 위에서 설명하였던 것처럼, A* 알고리즘으로 goal까지 전체 경로를 생성하였는데, 경로를 따라가다 장애물을 마주치게 면 장애물이 적은 쪽으로 방향을 전환하도록 하였습니다.
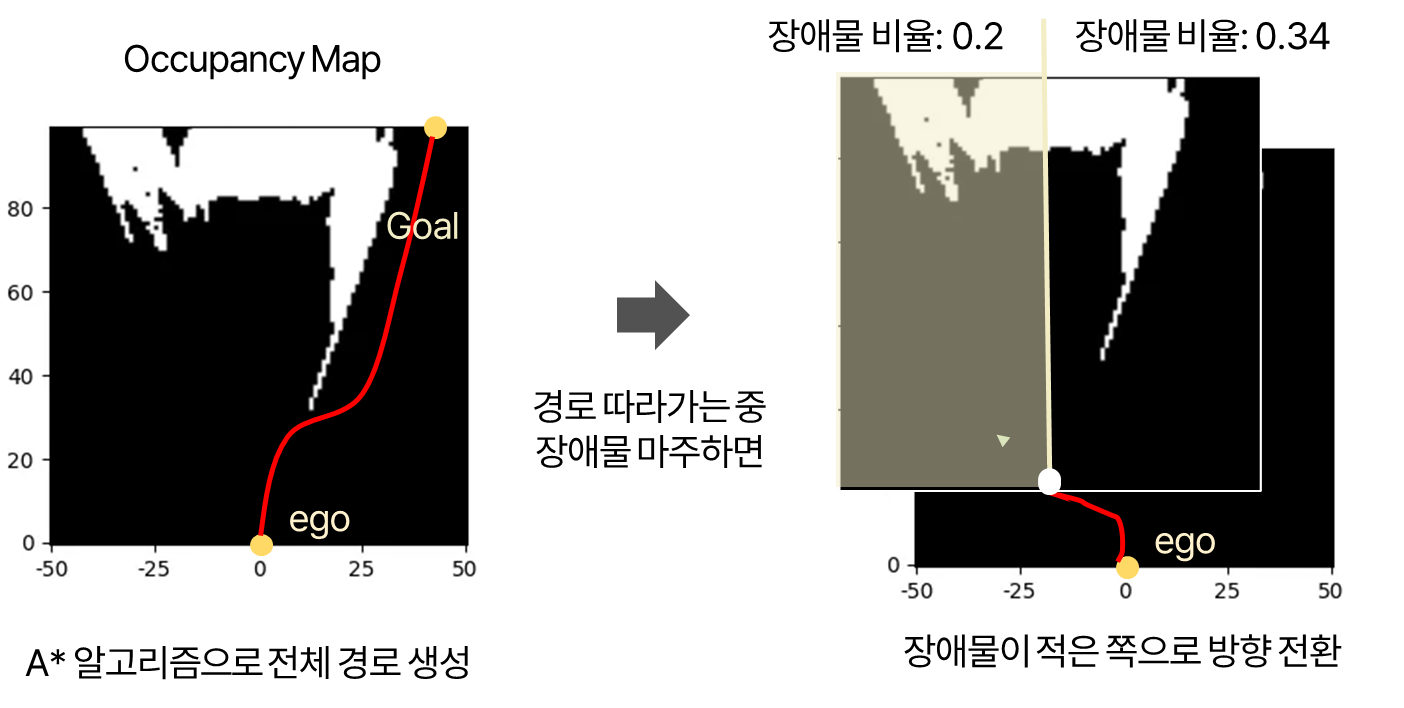
A* 알고리즘으로 전체 경로를 설정할 때 장애물까지 고려할텐데 왜 추가적으로 Occupancy Map 기반 방향 조정이 필요한가에 대한 이유가 궁금하실 수 있습니다. 그 이유는, 센서 데이터의 불완전성, 모델링 및 Occupancy Grid의 한계, 경로 추종의 부정확성, Occupancy Grid의 좌표 체계와 실제 환경의 불일치, 실제 장애물의 크기와 형상, 장애물 감지 및 경로 업데이트 주기의 한계, 테스트 환경과 실험 환경 간 차이 등 때문입니다. 자세한 설명은 아래 토글에서 확인하실 수 있습니다.
Occupancy Map 기반 방향 조정이 필요한 이유
- 센서 데이터의 불완전성 (Imperfect Sensor Data)
- 센서 노이즈: Occupancy Map을 생성하는 데 사용되는 센서(깊이 카메라 또는 LiDAR)의 데이터에 노이즈가 포함될 수 있습니다. 이로 인해 실제 장애물이 제대로 탐지되지 않거나 잘못된 위치에 표시될 가능성이 있습니다.
- 해상도 한계: 센서의 해상도가 낮거나 Occupancy Map의 셀 크기가 너무 클 경우, 작은 장애물(예: 돌멩이, 낮은 구조물)이 무시될 수 있습니다.
- 모델링 및 Occupancy Grid의 한계
- 맵의 시간적 지연: 센서 데이터로부터 Occupancy Map을 생성하고 경로를 계산하는 동안 환경이 동적으로 변할 수 있습니다. 예를 들어, 이동 중인 장애물이 위치를 바꾸면 예측된 경로가 더 이상 유효하지 않을 수 있습니다.
- Occupancy Map의 단순화: 실제 환경은 3D 구조를 가지지만, Occupancy Grid는 2D 평면으로 단순화됩니다. 예를 들어, 공중에 있는 장애물(낮게 걸친 구조물)은 탐지되지 않을 가능성이 있습니다.
- 경로 추종의 부정확성 (Path Tracking Inaccuracy)
- 차량의 제어 한계: 차량이 계산된 경로를 정확히 따르지 못할 수 있습니다. 특히 PID 또는 Bang-Bang 제어 같은 간단한 제어 알고리즘은 급격한 커브나 좁은 경로에서 부정확한 결과를 낼 수 있습니다.
- 지형의 특성: 실제 도로 표면이 미끄럽거나 기울어진 경우, 차량이 의도한 경로에서 벗어날 가능성이 높아집니다.
- Occupancy Grid의 좌표 체계와 실제 환경의 불일치
- Ego 위치와 장애물의 상대 좌표가 정확하지 않으면 경로 생성 시 잘못된 결정을 내릴 수 있습니다. Occupancy Map의 좌표 체계와 차량이 실제로 있는 위치 간에 오차가 있으면, 경로 생성은 유효하지만 실제로는 장애물에 더 가까이 접근하게 됩니다.
- 실제 장애물의 크기와 형상
- 크기가 큰 장애물: Occupancy Map에서는 하나의 셀로 표현되지만, 실제 환경에서 장애물의 크기와 형상이 더 크거나 복잡하면 부딪힐 가능성이 있습니다.
- 예측되지 않은 장애물: 예를 들어, 작은 물체나 투명한 장애물(예: 유리창, 얇은 구조물)은 센서에 의해 탐지되지 않을 수 있습니다.
- 장애물 감지 및 경로 업데이트 주기의 한계
- 차량이 빠르게 이동하거나 장애물 감지 및 경로 업데이트 주기가 느리면, 새로 감지된 장애물에 대해 즉각적으로 반응하지 못해 부딪힐 가능성이 커집니다.
- 테스트 환경과 실험 환경 간 차이
- 시뮬레이션과 현실의 차이: Occupancy Map 기반 시뮬레이션은 이상적인 조건을 가정하지만, 실제 환경에서는 조명, 날씨, 표면 상태와 같은 외부 요인들이 영향을 미칠 수 있습니다.
Data
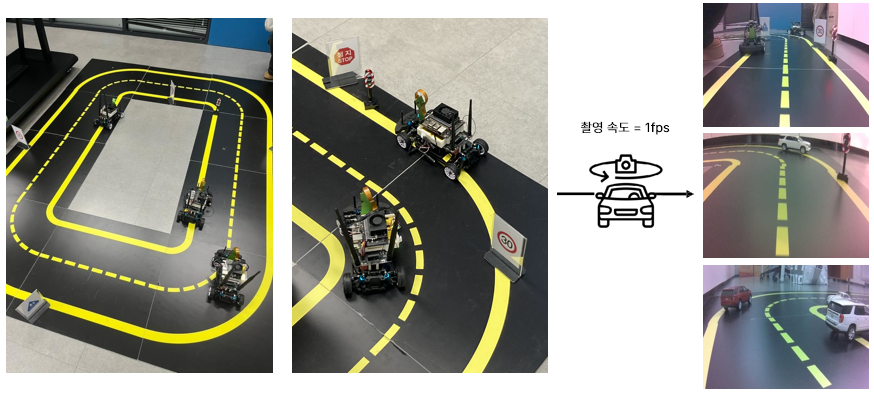
Jetracer에 CSI 카메라를 달아서 직접 주행하며 1FPS로 사진 11243장을 촬영했습니다.
Experiments
YOLOv8s
Data
Jetracer로 주행하면서 CSI 카메라로 촬영한 사진 1262장을 라벨링하였습니다. 사용한 라벨링 툴은 Roboflow입니다.

```plain text
dataset 구조
test ㄴ images # 212 images ㄴ labels train ㄴ images # 840 images ㄴ labels valid ㄴ images # 210 images ㄴ labels data.yaml README.dataset.txt
위와 같은 구성으로 데이터 폴더를 구성하였습니다.
총 9개의 클래스가 있습니다.
class name
jetracer
jetracer
표지판_어린이보호구역
sign_kid
표지판_천천히
sign_slow
표지판_속도30제한
sign_speed_30
표지판_멈춤
sign_stop
신호등_**초록**
traffic_green
신호등_꺼짐
traffic_off
신호등_**빨강**
traffic_red
신호등_**노랑**
traffic_yellow
### Train
model = YOLO('yolov8s.pt') model.train(data='your_dataset.yaml', epochs=20, batch=1, fliplr=0)
Pre-trained된 yolov8s.pt를 직접 촬영한 데이터로 batch = 1, epoch = 20, fliplr = 0으로 설정하고 학습시켰습니다.
이때 fliplr은 좌우반전 설정으로, 데이터 증강 관련 옵션입니다. 표지판 글씨가 좌우반전 되는 것을 막기 위해 0으로 설정했습니다.
모델을 학습시킨 후, Pytorch(.pt) 모델을 **TensorRT(.engine)로 변환**하여 **추론 속도를 최적화**하였습니다.
> 📌
**TensorRT**란?
딥러닝 모델을**최적화**하여 NVIDIA GPU 상에서 **추론 속도를 향상**시키는 모델 최적화 엔진입니다.
변환되는 과정은 `.pt ->.onnx ->.engine (or.trt)` 입니다.
.trt와.engine 모두 TensorRT에서 사용할 수 있는 최적화 모델 형식입니다.
### Inference & Evaluation
precision
recall
mAP50
0.96
0.91
0.96
Inference time
fp16
fp32
pt (Pytorch)
302.7ms
-
engine (TensorRT)
**21.8ms**
26.2ms
fp16인 yolov8s.engine의 추론 속도가 가장 빨랐습니다.
### 시각화
### **engine.py 생성**
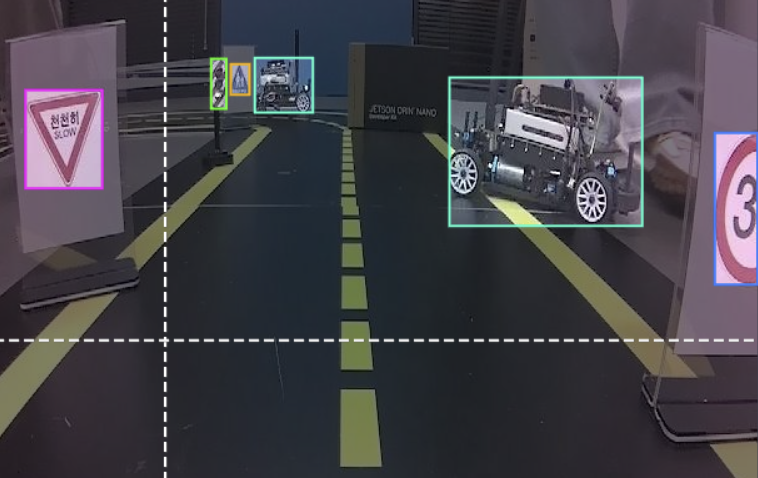
**YOLOEngine **클래스에서는 JetRacer 차량을 제어하기 위해 YOLOv8 모델을 활용하는 시스템을 구현합니다. `yolov8s.engine`을 로드하고, 표지판이나 신호등 등의 **객체를 감지 하여 차량을 제어**합니다.
Input이 촬영된 이미지 **`frame`**이고, output은 **`speed`**입니다.
YOLO 모델로 추론을 하고, 추론된 클래스에 따라 차량이 주행해야 하는 속도가 결정되도록 구현하였습니다.
- **stop_signals** 감지 시: 차량 정지 (stop_speed = 0)
- self.stop_signals = \["traffic_red", "traffic_yellow", "sign_stop"\]
- **go_signals** 감지 시: 기본 속도로 주행 (default_speed = 0.20)
- self.go_signals = \["traffic_green"\]
- **slow_signals** 감지 시: 느리게 주행 (slow_speed = 0.19)
- self.slow_signals = \["sign_speed_30", "traffic_off", "sign_slow"\]
- **very_slow_signals** 감지 시: 매우 느리게 주행 (very_slow_speed = 0.18)
- self.very_slow_signals = \["sign_kid"\]
**신호가 감지되지 않은 경우**에는 **None**을 반환하여 **현재 상태를 유지**하도록 하였습니다. 표지판 같은 경우, 2초 동안 표지판에 따라 반응한 후, 2초가 지나면 무시되도록 구현하였습니다.
---
## Ultra Fast Lane Detection (UFLD)
### **Data**
Jetracer로 주행하면서 CSI 카메라로 촬영한 사진 11,243장을 라벨링하였습니다. 사용한 라벨링 툴은 [CVAT](https://www.cvat.ai/)입니다.
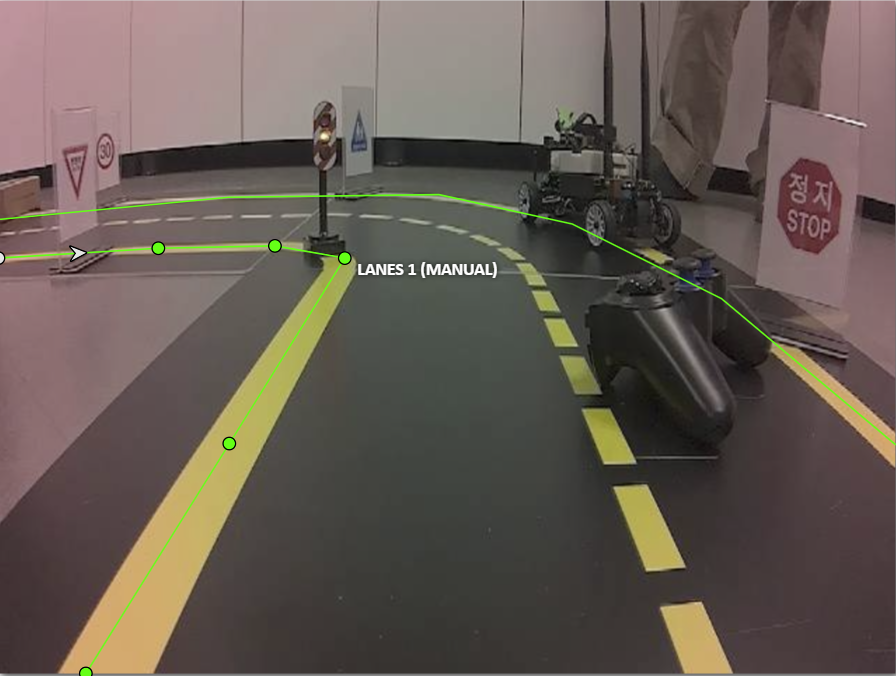
dataset 구조
labels ㄴ lanes ㄴ scene_0000 ㄴ annotations.xml ㄴ scene_0001 ... ㄴ lane_visualization_results ㄴ splits.json ㄴ test.json ㄴ train.json
annotations.xml 일부
각 scene의 폴더 안 annotations.xml은 CVAT에서 생성된 데이터로, 차선에 대한 정보를 담고 있습니다. `points` 는 차선이 위치한 좌표 리스트입니다.
### Train
**데이터셋 구성 및 전처리**
데이터셋은 Train 70%, Validation 20%, Test 10%로 분할하여 데이터의 학습, 검증, 평가를 위한 균형 잡힌 구성을 유지하였습니다.
이미지 전처리 과정에서는 데이터의 크기를 640x480에서 320x160으로 조정하여 계산 자원을 효율적으로 활용하고 모델의 학습 속도를 향상시켰습니다.
추가적으로, 데이터 증강을 위해 horizontal flip과 random brightness contrast를 적용하여 모델이 다양한 환경에서의 변화를 학습할 수 있도록 데이터 다양성을 확보하였습니다.
**하이퍼파라미터**
모델의 안정적인 성능 향상을 위해 Epoch을 100으로 설정하였습니다.
마찬가지로, 모델을 학습시킨 후 Pytorch(.pt) 모델을 **TensorRT(.engine)로 변환**하여 **추론 속도를 최적화**하였습니다.
### Inference & Evaluation

### 시각화
## Metric 3D
### Overview
- 카메라로 찍은 이미지만을 활용해 주변 환경 지도를 생성합니다.
- 주변 환경 지도는 2D Bird Eye View Occupancy Map 으로 구성합니다.
> 🚨
Q. Bird Eye View란?
A. 새가 하늘에서 땅을 바라보는 시야로 만든 지도를 의미합니다. 이는 자동차가 이동할 경로 계산을 쉽게 하도록 도와줍니다.
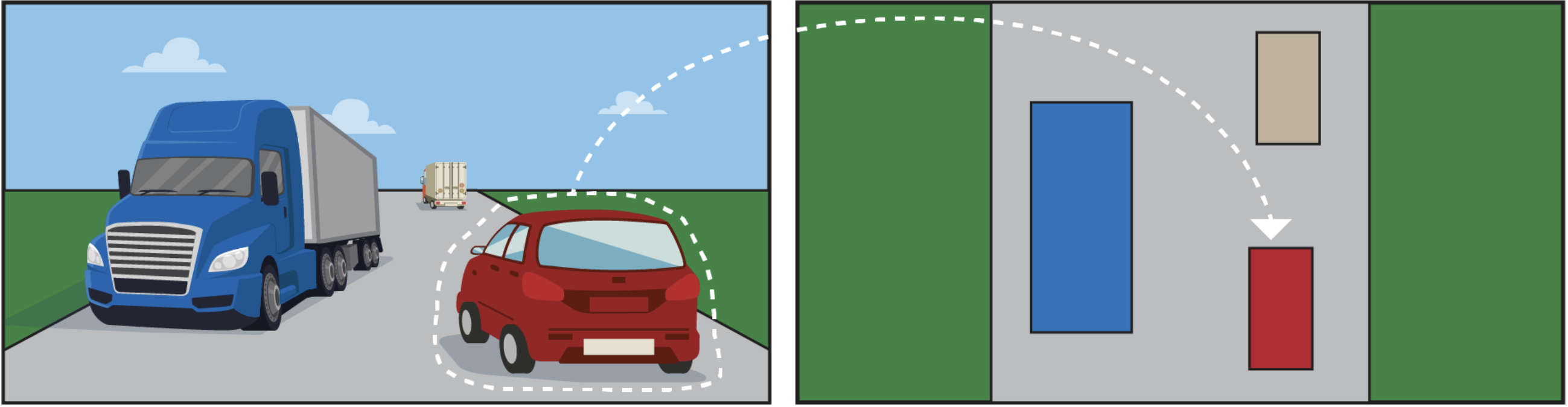
### DepthEngine
- 카메라로 찍은 이미지로 2D Occupancy Map을 만드는 코드입니다.
- 사용한 Metric3D는 추론 속도 향상을 위해 TensorRT로 최적화하였습니다.
- 이미지 입력 크기를 기존 (480, 640)에서 (308, 504)로 축소하여 TensorRT로 변환함으로써, 추론 속도를 효과적으로 개선하였습니다.
- 행렬 연산이 많아 반복문 없이 numpy로 병렬연산하도록 구현해서 Inference 속도를 높였습니다.
### 시각화
- 왼쪽은 원본 이미지
- 가운데는 Metric3D 모델로 추출한 깊이 값 이미지
- 오른쪽은 Camera Intrinsics를 활용해 생성된 2D BEV Occupancy Map
### 결과
10.3 FPS의 속도로 Occupancy Map을 만들어냅니다.
> 🚨
Q. FPS란?
A. Frame Per Second 의 약자로, 초당 몇개의 frame을 처리하는 지를 나타내는 단위입니다. 10.3 FPS 속도로 Occupancy Map을 만든다는 말은 초당 약 10개 정도의 사진에 대한 Occupancy Map을 만들고 있음을 의미합니다. 자율주행은 실시간으로 모든 것이 처리되어야하므로, FPS가 높을수록 활용성이 좋아집니다.
## TrackingEngine
### **Overview**
`TrackingEngine`은 **차량의 자율주행**을 위한 경로 탐색 및 제어 시스템입니다.
- DepthEngine에서 생성된 Occupancy Map을 주기적으로 업데이트하며, 그것을 기반으로 실시간으로 경로와 속도를 조정해 장애물 회피 및 경로 탐색을 수행합니다.
- **A***알고리즘을 사용하여 Occupancy Map 기반으로 최적 경로를 탐색합니다.
- 장애물 정보를 고려해 확장된 맵을 생성하고, Goal 지점을 상단부의 가장 긴 통로로 설정합니다.
- 경로 탐색 시 후진 방향을 제거해 효율적으로 최적의 경로를 찾도록 설계되었습니다.
- **PID 제어 알고리즘**으로 조향과 속도를 제어합니다.
### 특징
- 장애물 확장을 통해 차량 크기를 고려한 안전한 경로 설정합니다.
- Numpy 병렬 연산과 최적화된 알고리즘으로 경로 탐색 속도를 향상시킵니다.
- 차량 크기 및 다양한 주행 조건에 맞게 파라미터(`kp`, `kd`, `ki`, `max_steer`, `threshold`)를 조정 가능합니다.
### **구현 기능**
1. **장애물 확장 ( `expand_obstacles` )**
- 차량 크기를 고려하여 Occupancy Map에서 장애물 주변을 확장합니다.
- JetRacer의 너비와 길이에 따라 셀 단위로 확장 크기를 조정합니다.
- `numpy`와 `binary_dilation`을 사용하여 **병렬 연산**으로 처리 속도를 향상시켰습니다.
2. **Goal 탐색 ( `find_goal` )**
- 상단부 Occupancy Map에서 긴 빈 통로를 탐색하여 Goal로 설정합니다.
- `threshold`를 설정하여 좁은 통로나 짧은 영역을 제외합니다.
- 탐색된 통로의 **중간값을 Goal로 반환**하여, 차량이 통로의 중심을 따라 가도록 설계되었습니다.
- `current_chunk`의 길이가 `threshold` 이상인 경우, 그 중간값을 Goal로 설정하고 즉시 반환합니다. 이는 `threshold` 이상의 첫 번째 통로를 선택하는 로직으로, 이후에 더 긴 통로가 있더라도 고려하지 않습니다.
3. **경로 탐색 ( `a_star` )**
- *A** 알고리즘을 사용해 Start 지점에서 Goal까지 최적 경로를 탐색합니다.
- 후진 방향을 제거하여 **전진 주행**만 수행하도록 설계되었습니다.
- 장애물에 대한 경로 유효성을 확인하며, 유효한 경로가 없는 경우 실패 메시지를 반환합니다.
4. **조향 제어 ( `calculate_steering` )**
- PID 제어 방식을 사용하여 차량의 조향 값을 계산합니다.
- 경로의 Target Point와 현재 위치 간의 오차를 최소화하며, 조향 각도를 계산합니다.
- `np.clip`으로 조향 각도를 차량의 최대 조향 범위(`max_steer`) 내로 제한합니다.
5. **주행 실행 ( `run` )**
- Occupancy Map을 기반으로 장애물을 확장하고 Goal 및 경로를 탐색합니다.
- PID 제어로 조향 값과 속도를 설정하여 차량을 실시간으로 제어합니다.
- 경로 탐색 실패 시 차량을 정지 상태로 유지합니다.
### **Pipeline**
1. **Input**
- **Occupancy Map**: DepthEngine을 통해 생성된 2D Occupancy Map.
2. **Process**
- 장애물 확장 → Goal 탐색 → 경로 탐색(A*) → PID 제어 → 조향 및 속도 계산.
3. **Output**
- 조향 값(Steering)과 속도(Throttle)를 계산하여 차량을 제어합니다.
### 시각화
- DepthEngine에서 들어온 Occupancy Map을 기반으로 합니다. 하얀색(1)은 장애물이 위치하여, 검정색(0) 영역만 지나갈 수 있습니다.
- Occupancy Map은, DepthEngine에서 10.3 FPS의 속도로 만들어냅니다.
- A* 알고리즘을 활용하여 전체 경로를 실시간으로 업데이트합니다.
# AutonomousEngine.py
학습시킨 **YOLOv8s, Metric3D, UFLD** 모델을 활용하기 위해 object, depth, lane, planning 각각의 기능을 담당하는 독립적인 engine을 설계하였습니다.
폴더 구조
depth ㄴ engine.py ㄴ metric3D_vit_small.engine lane ㄴ engine.py ㄴ ufld.trt object ㄴ engine.py ㄴ yolov8s.engine ㄴ jetracer # jetracer github clone planning ㄴ engine.py
autonomousengine.py ultralytics # ultralytics github clone
### Input/Output
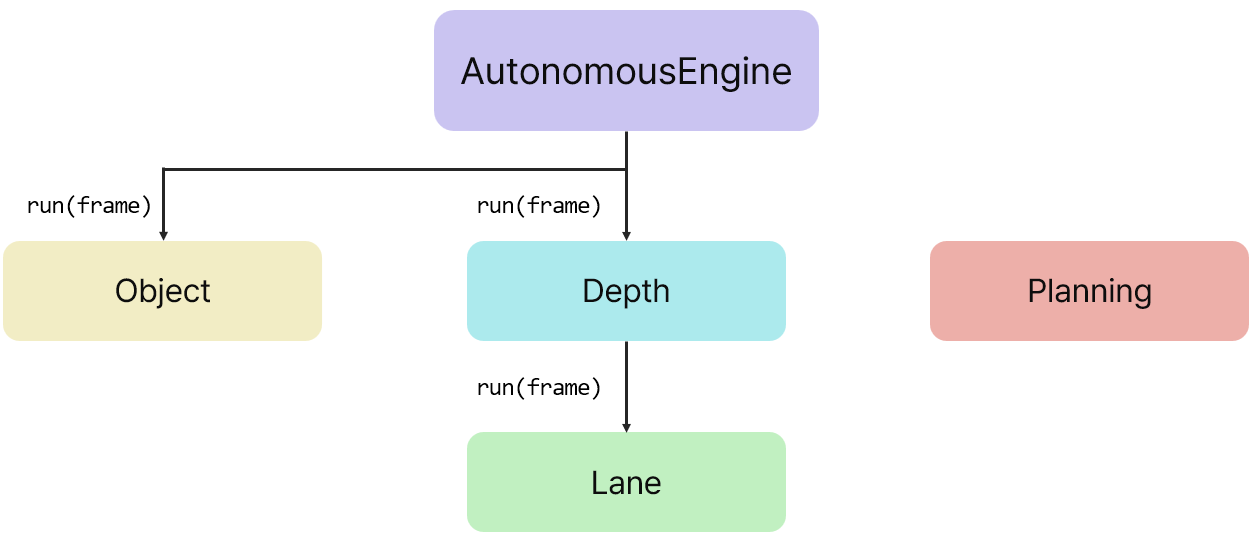
**Input**
**Output**
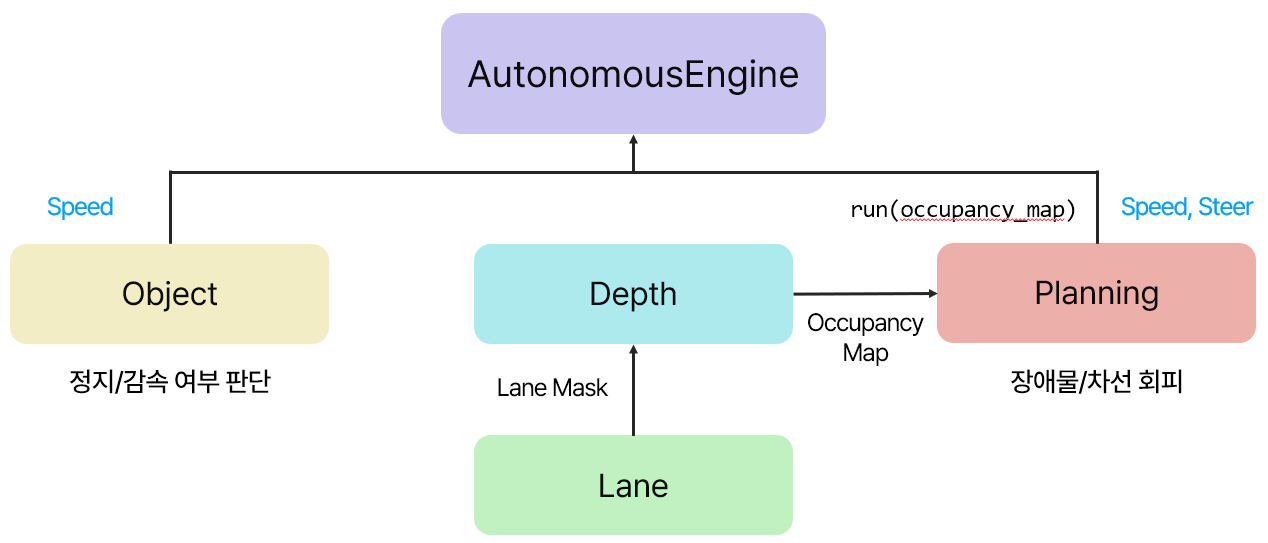
Input인 카메라 프레임(`frame` )이 세 가지 엔진 클래스인 YOLOEngine, DepthEngine, LaneEngine으로 전달됩니다.
1. Object `YOLOEngine`
- Input: frame
- Output: speed
yolov8s를 활용하여 객체를 탐지하고, 신호등이나 표지판에 대해 속도를 조절할지 판단합니다.
speed는 AutonomousEngine으로 전달되어 주행 속도 제어에 활용됩니다.
2. Lane `LaneEngine`
- Input: frame
- Output: Lane Mask
UFLD로 차선을 검출하고, Lane Mask는 Depth 클래스로 전달됩니다.
3. Depth `DepthEngine`
- Input: frame
- Output: occupancy map
Metric3D로 깊이 정보를 추출하고, LaneEngine에서 전달받은 Lane Mask와 함께 좌표변환을 통해 2D Occupancy Map을 생성해 TrackEngine에 전달합니다.
4. Planning `TrackingEngine`
- Input: Occupancy Map
- Output: speed, steer
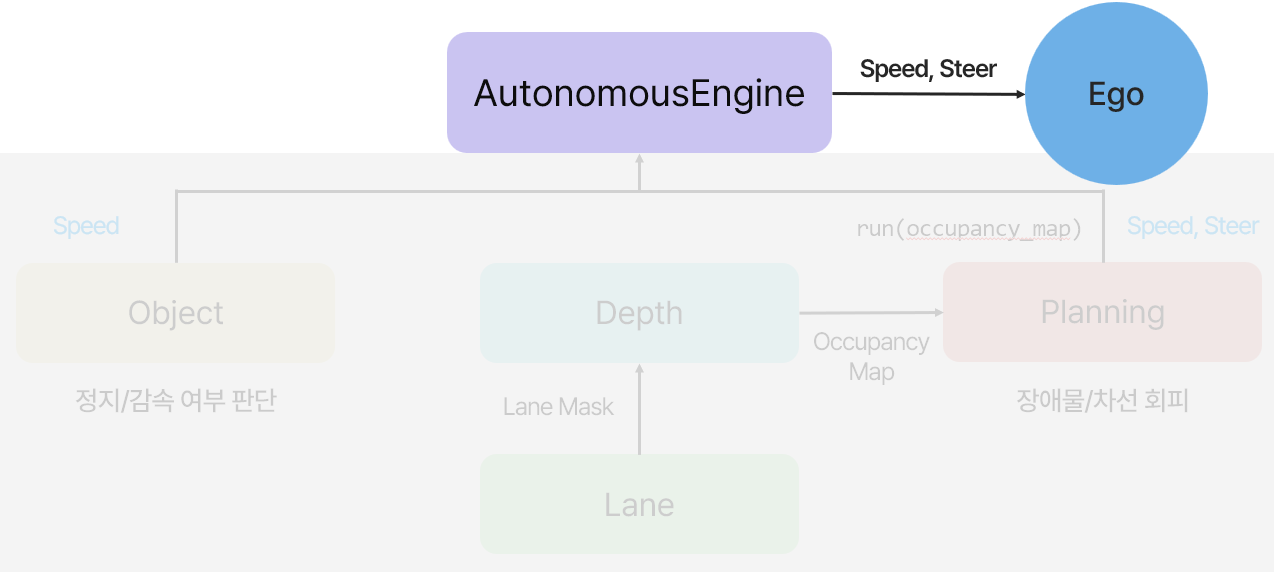
최종적으로 결정된 **speed, steer**값이**차량(Ego)**에 전달되며, AutonomousEngine이 차량을 제어하게 됩니다.
### 주행 흐름
AutonomousEngine 클래스의 run 함수는 차량의 전체적인 주행을 담당합니다.def run(self): try: ret, frame = self.camera.read()
yolo_speed = self.yolo_engine.run(frame) occupancy_map = self.depth_engine.run(frame) speed, steer = self.track_engine.run(occupancy_map)
speed = yolo_speed if yolo_speed is not None else speed
self.car.throttle = speed self.car.steering = steer
except Exception as e: print(f"Error during run:") self.reset()
> 📌
카메라에서 프레임 읽음
➡️ YOLO로 객체 감지하여 속도 결정
➡️ Occupancy Map 분석
➡️ 경로 계획 및 최적화된 steer, speed 값 결정
➡️ steer, speed 값 적용하여 차량 제어
➡️ 위 흐름 반복하여 수행하고, 오류 시 차량 정지
- **throttle**: 차량의 **속도**를 조절하는 값
- 일반적으로 0(정지)에서 1.0(최대 속도) 사이의 값을 가짐
- **steering**: 차량의 **조향(방향 전환)**을 조절하는값
- 값의 범위: -1.0 ~ 1.0
- `0` : 직진
- `-1.0` : 최대 좌회전
- `1.0` : 최대 우회전
# Experiment 2
### ResNet18로 차선 중심 좌표 예측
### Data
(이미지, 차선중심좌표) 형태로 라벨링을 하여 학습 데이터셋으로 활용했습니다.
라벨링 툴은 ipycanvas, ipywidget을 사용하여 차선 중앙에 점을 클릭할 수 있도록 직접 구현하였습니다.
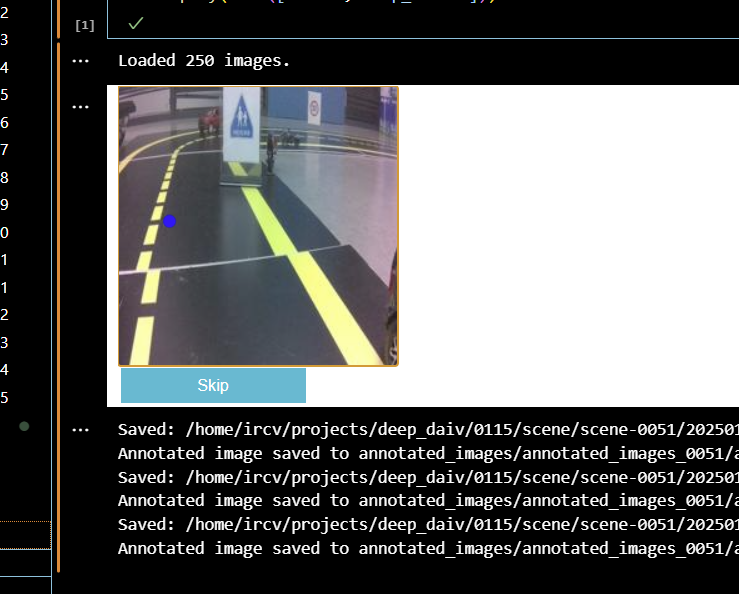
클릭하여 라벨링을 하고 나면 이미지 경로, 중심점의 x, y 좌표가 csv 파일로 저장됩니다.image_path x y /home/ircv/projects/deep_daiv/0115/scene/scene-0023/20250118154347934419.jpg 57.20000076 90.19970703 /home/ircv/projects/deep_daiv/0115/scene/scene-0023/20250118154338136273.jpg 52.20000076 92.19970703 ...
### Train
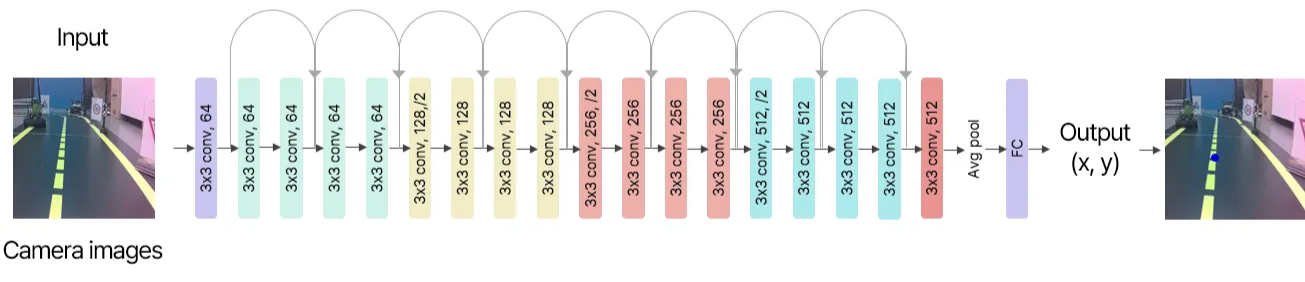
예측해야 하는 것이 차량이 이동해야 하는 **도로의 중심점**이기 때문에 `output dimension=2`로 설정하고, **사전 훈련된 ResNet-18 모델**을 활용하여 라벨링된 데이터로 학습시켰습니다. 즉, 차량의 주행 경로에 해당하는 `(x, y)` 좌표를 예측하도록 모델을 구성하였습니다.
약 8000장의 사진을 활용해 50분 정도 걸려 학습되었습니다.
### 속도 제어
- 코너를 돌 때 바퀴에 전달하는 전압을 유지하면 속도가 느려지는 현상이 있었습니다.
- PID 제어를 활용해 다음 순간까지의 속도 변화량을 계산해 코너링 시 전압을 자연스럽게 높여 속도를 일정하게 유지했습니다.speed_diff = kp error + kd (error - previous_error) + ki * integral_error
- error : 목표 속도와 현재 속도와의 차이 → 얼마나 중요히 볼 것인가는 kp 변수를 조정하며 실험 진행
- previous_error : 이전 순간의 error값 → 얼마나 중요히 볼 것인가는 kd 변수를 조정하며 실험 진행
- integral_error : 지금까지의 누적 error값 → 얼마나 중요히 볼 것인가는 ki 변수를 조정하며 실험 진행
- kp : 0.1
- kd : 0.01
- ki : 0 → 누적에러까지 보지 않아도 충분히 제어가 잘 되었기에, 추가적인 계산소요를 없앴습니다.
### 결과
**50 FPS**의 속도로 차선 중심 좌표를 예측합니다. 굉장히 속도가 빠릅니다.
### 시각화
- **파란 점**은 라벨링한 데이터를 통해 추가 학습한 ResNet에서 예측한 **차선 중심 좌표**입니다.
- 이미지에 오른쪽 차선, 왼쪽 차선 중 하나만 나타나는 경우에도 robust하게 동작합니다.
# Ablation
### UFLD
추론 속도가 빠른 모델을 찾기 위해 input_size, num_grid, cls_num_per_lane 값들을 바꿔가며 실험을 진행하였습니다.
> 🛠
학습환경: RTX 6000
input_size (288, 800)
input_size (128, 384)
input_size (96, 288)
input_size (64, 192)
input_size (96, 288) | num_grid=40
input_size = (96, 288) | cls_num_per_lane= 21
input_size (128, 384) | num_grid=40
input_size (128, 384) | num_grid=35
input_size (128, 384) | num_grid=40 | cls_num_per_lane= 21
input_size (128, 384) | cls_num_per_lane= 25
input_size (64, 192) | num_grid=40
IoU
0.8659
0.8438
0.7999
0.8315
0.8439
0.8314
0.8580
0.8326
0.8308
0.8473
0.8746
loss
0.4264
0.5127
0.6564
0.6051
0.4848
0.6180
0.4546
0.4316
0.4987
0.5016
0.5169
train_time (ms)
1342231.25
(= 26m)
635872.5625
501831.59375
444142.6875
522873.8125
529963.75
595666.3125
593732.1875
522625.25
526481.6875
337289.21875