
숨은 그림 찾기

숨은 그림 찾기는 사진에서 여러가지 물체를 숨기는 게임입니다. 물체를 숨기는 방법은 크게 2가지 방법이 있습니다. 위의 그림을 보시면 알겠지만 오른쪽에 있는 빵은 풀의 갈색 색깔과, 타원형 모양이라는 2가지 요소가 비슷하기 때문에 눈에 띄지 않게 물체를 숨길 수 있었습니다.
색깔


첫번째 시도한 방법은 비슷한 색깔을 갖는 물체를 숨기는 것입니다. 위의 사진처럼 빨간색 사과를 빨간색 배경에 숨긴다면 사람들이 쉽게 알아채지 못할 것이라는 가정이었습니다.

하지만 예상처럼 쉽게 물체가 숨겨지지 않았습니다. 첫번째로 물체의 배경색과 사과의 빨간색이 정확히 일치하지 않았습니다. 두번째로 사과의 색깔은 단일색이 아닌 노란색 부분, 꽁지 부분들 다양한 색이 존재하기 때문에 생각보다 눈에 뜨이는 결과가 나타났습니다.

이를 보완하기 위해 물체에 Blur처리를 해서 숨길 수 있습니다. 하지만 Blur 처리를 이용한다는 것은 색깔이라는 알고리즘을 사용하기 보다는 단순히 물체를 안보이게 하기 위해서 물체 자체를 흐리게 하는 방식이기 때문에, 퀄리티가 좋은 프로젝트 결과를 해야하는 다이브와는 거리가 있다고 생각했습니다.
모양


두번째 방법은 비슷한 모양의 물체를 대입하는 방법입니다. 위의 예시처럼 사진에서 사각형 부분을 찾은 후, 해당 부분에 사각형 물체를 대입하면 이전 색깔을 사용하는 알고리즘보다 물체를 숨기는 측면과 완성도 측면 모두 좋은 결과를 얻었습니다. 비슷한 모양을 갖는 물체를 숨기는 방법을 사용하기 위해서는 어떤 알고리즘이 필요할까요?
- 사진에서 물체의 모형을 감지하는 알고리즘 → Detectction & Segmentation
- 인식된 모형과 동일한 모양을 갖는 물체
- 물체를 Mask에 적절하게 대입하는 알고리즘
크게 위의 3가지 알고리즘이 필요합니다. 한가지씩 자세히 알아보도록 하겠습니다.
Segmentation
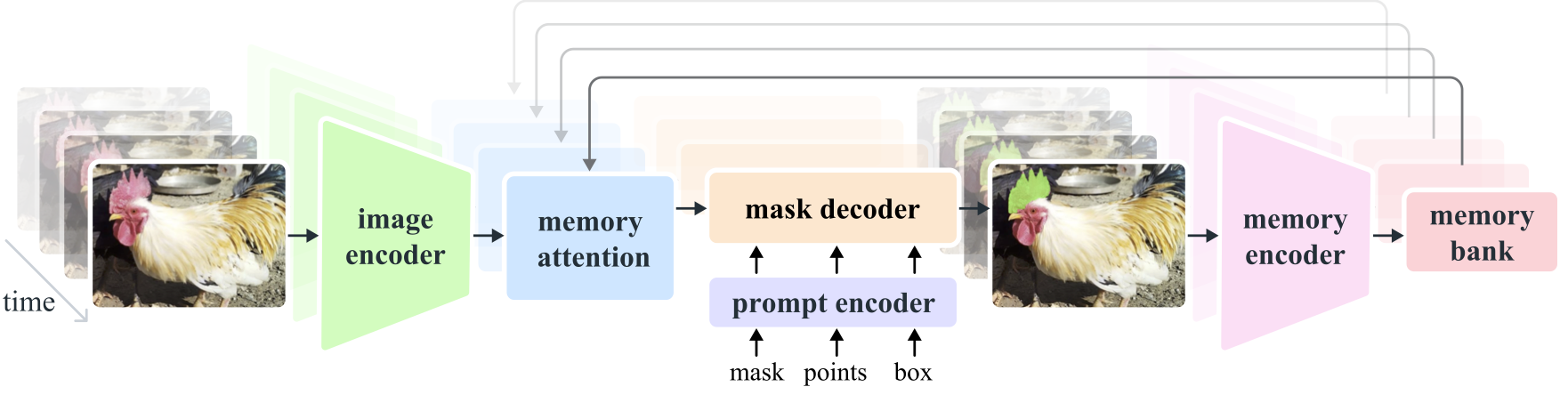
Segmentation을 진행하기 위해서 어떤 물체든 segmentation을 가능하게 해주는 segment anything model2(SAM2)를 사용했습니다. SAM2의 이용방법은 points, bounding box, mask를 condition으로 주어서 segmentation을 활용하는 방식, 혹은 Auto Labeling해주는 방식 2가지가 존재합니다.

저희가 사용하는 이미지는 처음보는 이미지에 대해서 진행하기 때문에 2번째 자동으로 레이블링을 해주는 방식을 사용해야됩니다. 그렇다면 자동으로 레이블링된 Mask에 대해서 어떻게 모형을 찾을 수 있을까요?
Language Segment-Anything(lang-SAM)
첫번째 방식은 text-prompt로 rectangle, triangle과 같은 모형을 입력하는 방식입니다. SAM2에서는 condition으로 텍스트를 입력할 수 없지만 Language Segment-Anything(lang-SAM)모델에서는 이를 지원합니다.


lang-SAM을 사용해서 텍스트로 Rectangle를 입력했을 때의 결과입니다. 결과는 우선 만족스러웠습니다. 하지만 개수가 너무 적다는 단점이 존재했습니다. 여러가지 다른 도형들, 예를 들어 삼각형, 원, 사다리꼴 다양한 형태를 입력했지만 여전히 도형의 개수는 적게 나왔습니다.
Auto labeling

Mask의 개수를 늘리기 위해서 텍스트를 Condition으로 사용하는 방식이 아닌, 자동으로 레이블링 해주는 경우를 고려해보도록 하겠습니다. 자동으로 레이블링한 결과는 위의 사진과 같습니다. 이전에 비해서 확실히 많은 레이블을 얻을 수 있습니다. 하지만 사각형, 원과 같이 정확한 도형을 얻을 수 없다는 새로운 문제가 발생합니다.
사각형

레이블링된 여러 마스크를 개별 도형으로 분리하기 위해 OpenCV에서 제공하는 findContours 알고리즘을 사용했습니다. 이 알고리즘은 이진화된 이미지(검은색과 흰색만 있는 이미지)를 입력으로 받아, 흰색 영역에 대해 윤곽선을 탐지합니다. 결과적으로, 위의 사진처럼 흰색 영역의 가장자리 윤곽선을 찾아낼 수 있습니다.
이후 2가지 조건을 추가로 만족하는 경우를 최종 사각형 도형의 마스크로 선택합니다. 2가지 조건은 아래와 같습니다.
- 꼭짓점이 4개인가?
- 마주보는 변의 길이가 비슷한가?
첫번째 조건은 간단합니다. 윤곽선에 대해서 4개의 꼭짓점을 갖고 있는 요소들만 필터링 하는 것입니다.
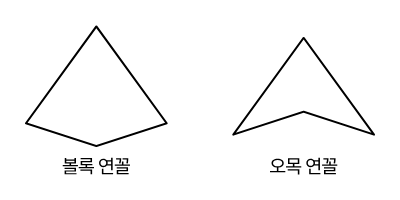
하지만 위와 같은 도형들도 첫번째 알고리즘을 통과하게 됩니다. 위의 도형들은 사각형이 아닌 단순히 꼭짓점이 4개인 도형들입니다. 위와 같은 도형들을 제거하기 위해서 두번째 조건을 추가합니다. 마주보는 변들의 길이 차이의 비율이 1.5가 넘으면 사각형이 아닌 것으로 간주합니다.

물론 두번째 조건을 추가한다고 해서 모든 도형들이 사각형이 되는 것은 아닙니다. 하지만 실험 결과를 보면 어느정도 타당한 도형들에 대해서만 사각형이라고 판단하고, 너무 까다로운 조건을 추가하면 개수가 줄어들기 때문에 2가지 조건만을 이용해서 사각형을 생성했습니다.
원형

두번째 원을 찾는 방법도 비슷합니다. 이전 사각형과 동일하게 윤곽선을 찾은 후 윤곽선을 포함하는 가장작은 외접원을 찾습니다. 이후 윤곽선 내부(초록색 선 내부)의 면적과 외접원의 비율이 0.7~1.2 안에 들어간 경우 원의 마스크로 간주합니다. 비율이 1이라면 완벽한 원이 되겠죠?

최종적으로 자동으로 레이블링된 마스크들 중에서 원으로 분류된 마스크들입니다.
대입할 도형
Segmentation과정을 통해서 저희는 사각형과 원형 두가지 도형을 얻었습니다. 그러면 대입할 물체를 찾도록 하겠습니다. 물론 매번 도형에 맞는 물체를 생성해서 대입할 수 있습니다. 하지만 빠른 데모를 진행하기 위해서 고정된 물체를 사용했습니다.

마지막 다이브 프로젝트인 만큼 다이브와 관련된 물체를 넣고 싶어서 사각형은 위의 사진처럼 다이브를 상징하는 네이비와 알파벳 D를 이용해서 생성한 이미지

그리고 원형은 다이브를 상징하는 또다른 물체가 아닌 인물이죠? 대표 성배님의 얼굴을 대입하도록 하겠습니다.
물체 → Mask


물체를 대입하는 알고리즘은 간단합니다. 단순히 Resize 할 수도 있지만 Mask가 정확히 직사각형이 아닌 경우도 있기 때문에 4개의 꼭짓점을 기반으로 변형했습니다. 자세히 설명해드리면 대입하는 물체의 4개의 꼭짓점과 Mask 4개의 꼭짓점에 대해서 변환 행렬을 찾고, 이를 이용해서 물체를 대입하게 됩니다.

원형의 경우는 더 단순합니다. Mask원의 반지름을 기준으로 성배님 얼굴을 Resize해서 변형시키고 단순히 대입합니다.

최종적인 결과는 다음과 같습니다.
Cartoonization



최종적인 결과도 만족스럽지만 조금 더 자연스러운 결과를 내기 위해서 카툰화 과정도 진행했습니다. 카툰화 과정에서 사진이 단조로워지고, 이러한 과정으로 인해서 대입된 물체와 원본 이미지와의 구분이 모호해지기 때문입니다. 최종적인 결과는 아래와 같습니다.
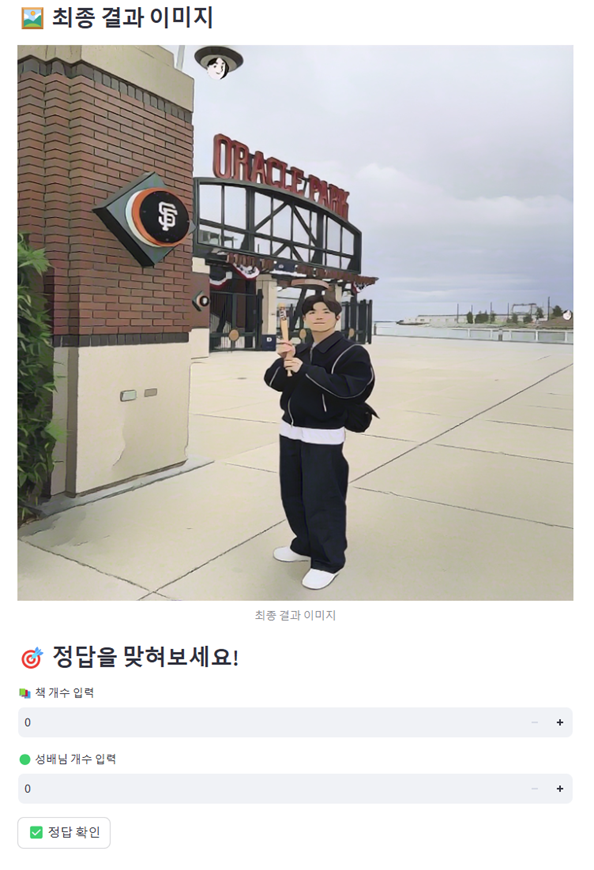
최종 결과: 약 50초


dive 책 개수: 4, 성배님 개수: 11

dive 책 개수: 2, 성배님 개수: 20 →

최종 결과 예시들입니다. 모든 과정은 약 50초가 소요되고, dive 책의 개수와 성배님의 개수를 파악하는 게임입니다.
포즈 분류
이구동성 게임을 다들 기억하시나요? 제시된 단어에 적합한 동작을 시간 내에 적절히 취하는게 중요한 게임입니다! 이런 포즈 분류 게임을 간단히 해볼 수 있게 AI 모델을 사용하여 구현해 보았습니다.
데이터 수집
다양한 포즈를 모두 포함하고 싶었지만 우선 브이, 파이팅, 하트(양손), 다이브 포즈로 총 4개에 대해 진행하였습니다.
크롤링 데이터
Google에서 포즈별로 100개의 동작을 크롤링하여 사용했습니다. 선명한 동작을 취하는 사진을 얻기 위해 주로 연예인들의 기사 사진을 위주로 다시 선별했습니다. 또한 중복 제거와 워터마크가 강하게 들어간 이미지는 제외했습니다.


다이브 단체 사진
또한 빠질수 없는 저희 다이브 공식 포즈를 추가하기 위해 단체 사진에서 인물 별로 crop하여 100장의 이미지를 수집했습니다.
데이터 증강
증강 전
원본 이미지들(400장)으로만 학습을 진행할 경우 68%대의 낮은 정확도를 보임 추가적으로 직접 찍은 사진을 통해 test를 진행해본 결과 모두 daiv 포즈로 예측하는 현상을 보임
크롤링한 데이터의 경우 고해상도이며, 색상의 분포가 매우 극단적임 반면 학습에 사용한 daiv 포즈의 경우 상대적으로 저해상도이며, 색삭의 분포가 고름
⇒ 이미지의 해상도를 통일하고 색감을 정규화한 뒤 노이즈를 추가해보자!
증강 후
def augment_image(image, target_size=(224, 224)):
"""
해상도를 통일 및 색감을 정규화 후, 노이즈를 추가.
Parameters:
- image: 입력 이미지 (numpy array, BGR 형식)
- target_size: (width, height) 형태의 목표 해상도
Returns:
- 증강된 이미지 (numpy array)
"""
resized_image = cv2.resize(image, target_size, interpolation=cv2.INTER_LINEAR)
normalized_image = resized_image.astype(np.float32) / 255.0
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
normalized_image = (normalized_image - mean) / std
noise = np.random.normal(0, 0.01, normalized_image.shape).astype(np.float32)
augmented_image = normalized_image + noise
augmented_image = np.clip(augmented_image, 0, 1)
augmented_image = (augmented_image * 255).astype(np.uint8)
return augmented_image다음 알고리즘을 통하여 400 → 800 장으로 데이터를 증강했습니다. 이에 대한 학습 결과:
Training : Epoch 9: 100%|██████████| 20/20 [00:04<00:00, 4.98batch/s, accuracy=99.5, loss=0.0151]
Testing : Epoch 9: 100%|██████████| 5/5 [00:00<00:00, 8.96batch/s, accuracy=100, loss=0.000276]
New best model saved at epoch 9 with accuracy: 100.00%
Loaded pretrained weights for efficientnet-b0
100%|██████████| 5/5 [00:00<00:00, 5.78it/s]
Test Accuracy: 100.00%Overfitting을 걱정하였으나 현장에서 찍은 이미지로 test 결과 안정적으로 예측을 진행했습니다.
모델 선정
처음에는 요가 포즈에 대해 classification을 진행한 다음 github를 참고하여 학습을 진행했습니다. 그러나 해당 모델로 웹상에서 테스트해본 결과 정확도가 떨어지는 현상이 발생하여, MediaPipe라고 하는 손동작 인식 모델을 기반으로 입력 데이터에 대해 손동작에 대한 13개의 관절 포인트를 추출하고 이를 기반으로 classification 모델을 설계하였고 이를 통해 해당 문제점을 해결할 수 있었습니다.
학습 결과
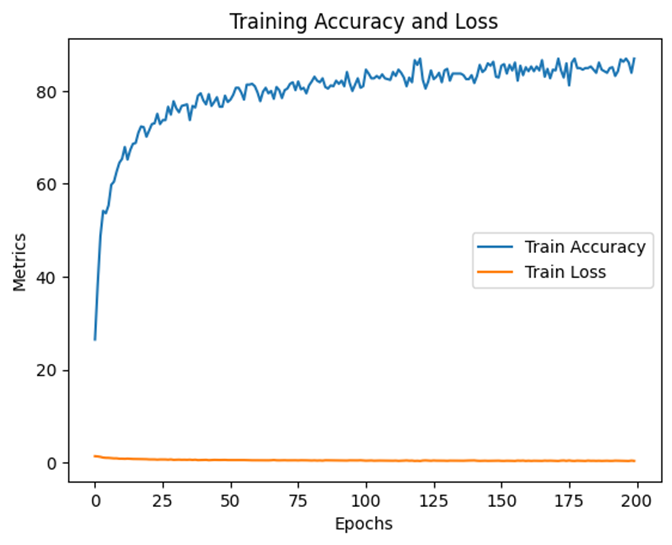
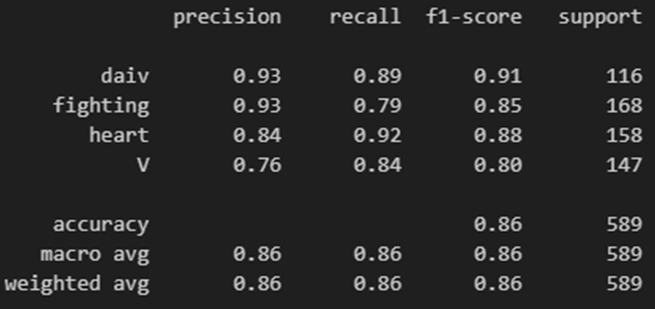
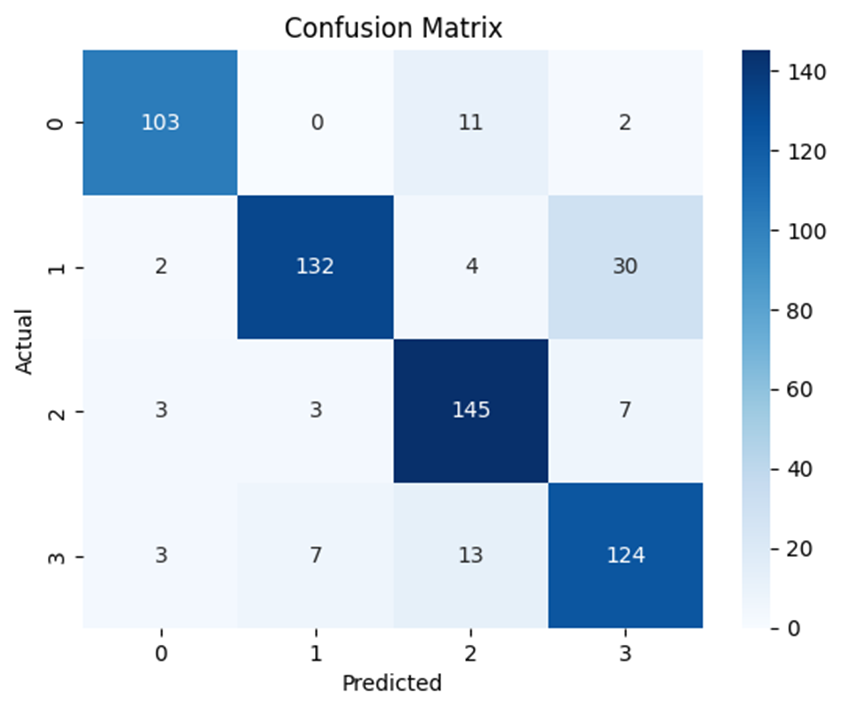
모델의 학습 결과는 다음과 같이 평균적으로 86%의 정확도를 보였습니다. 또한 이에 대한 confusion metrix는 아래와 같았습니다.
이러한 동작 인식 모델을 기반으로 한 포즈 분류 게임을 제작하였습니다.
틀린 그림 찾기
틀린 그림 찾기를 구현해봅시다. 어떻게 하면 틀린 그림 찾기를 구현할 수 있을까요? 틀린 그림 찾기에는 크게 2가지 유형이 있습니다. 있는 물체 없애기 / 있는 물체 바꾸기
있던 물체를 없애거나 바꾸기 위해서 우리가 해야할 일은 다음과 같습니다. 첫째, 어떤 영역을 바꿀지 ROI 알고리즘을 구현 둘째, ROI만 자연스럽게 변형하기 위한 Image Inpainting
효율적인 Image Inpainting을 위해 모델은 Hugging face의 stable diffusion-inpaining, 사전학습된 가중치는 stable-diffusion-v1.5로 선정했습니다.
이제 어떻게 후보 영역을 선정할지에 대한 알고리즘을 정리해보겠습니다.
Methodology
Image Normalization→ Edge Enhancement → Candidate Contour Detection → Image Inpainting
Image Normalization
- **Input image ⇒ 1024*1024**
모델이 동일한 인풋을 받을 수 있도록 정규화하여 최적의 성능을 도출했습니다.
Edge Enhancement
- Grayscale convert
- binary convert
- morphological dilation
-

경계를 명확하게 탐지하기 위해 grayscale로 변환했습니다. 128을 기준으로 binary 변환을 통해 물체의 경계선을 추출했습니다. morphological dilation (kernal size 5*5)를 진행해 이진화 결과에서 끊어진 부분을 채워 연속성 향상시켰습니다. 마지막으로 dilation result - binary result를 적용하여 엣지를 강조합니다.
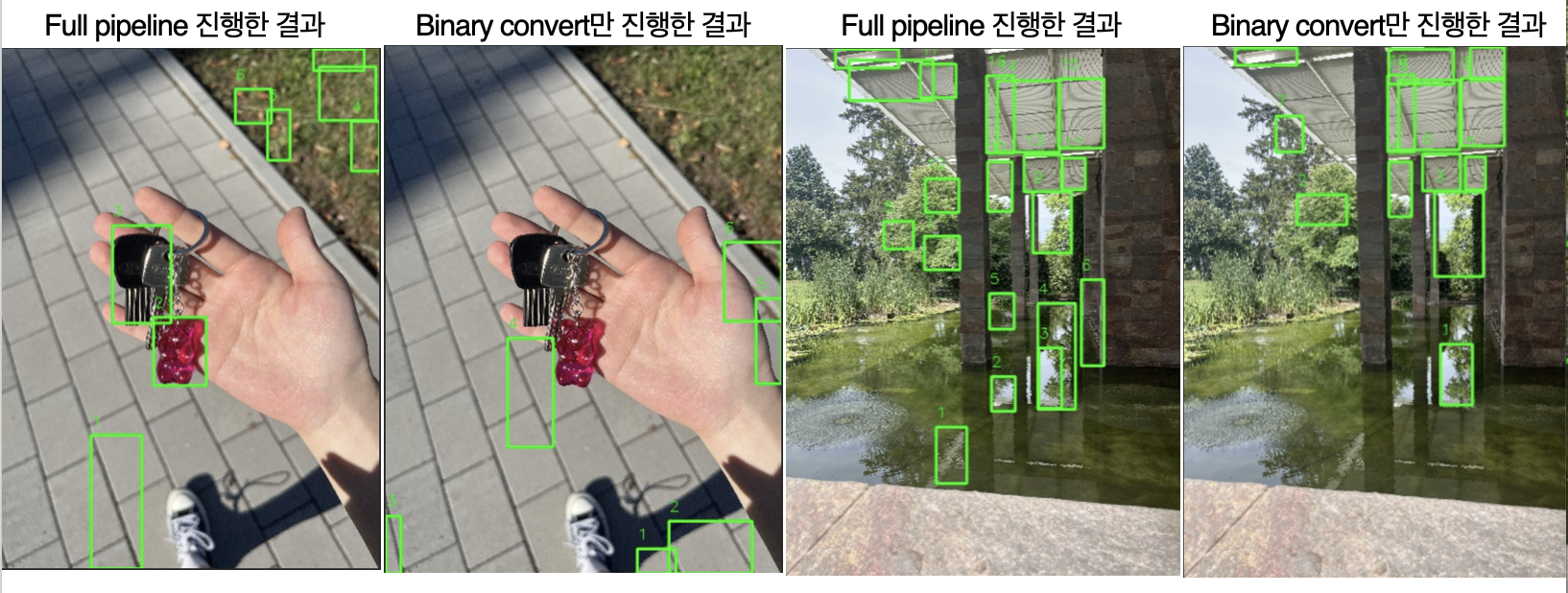
⇒ 끊어진 부분들이 연결되어 보다 풍부한 후보 영역이 발생하며, 의미 없는 배경에 후보 영역이 추출되는 것을 방지해 더 적절한 후보 영역 추출이 가능합니다.
Candidate Contour Detection
- Edge Enhancement 결과 이미지의 컨투어(윤곽선) 탐지 # cv2.findContour
- 컨투어 외접하는 최소크기 사각형 생성 # cv2.boundingRect
- 사각형을 기준으로 컨투어 필터링
- Min : 400픽셀 이하
- Max : 전체 이미지 1/8 이상
- 도출된 후보 영역 중 최소 거리 10 filter 적용 # 최종 ROI가 겹치지 않음
- output : 필터링된 외접 사각형 좌표 & 단순화된 컨투어 점 리스트
엣지 강조 결과 이미지의 컨투어를 탐지하고 효율적인 연산을 위해 최소 크기 사각형을 생성합니다. 이를 기준으로 최소 영역과 최대 영역을 필터링해 부적절한 컨투어를 탈락시킵니다.





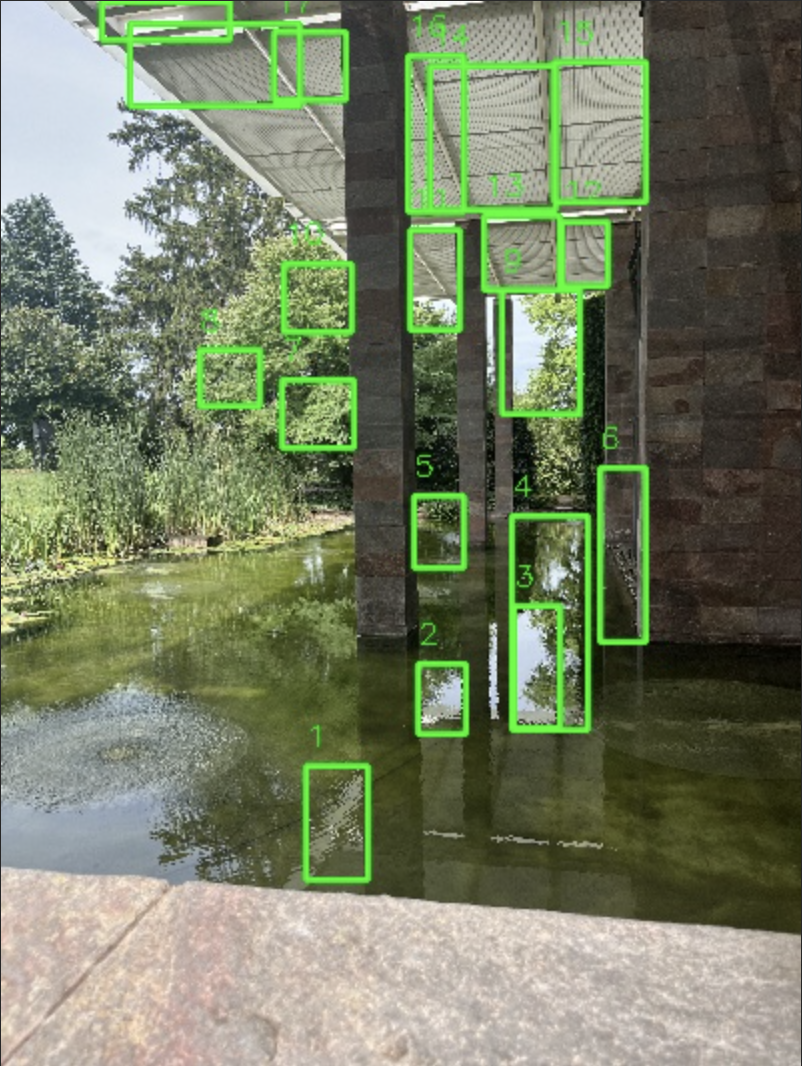
Image Inpainting Model : Hugging face의 runwayml/stable-diffusion-inpainting Pretrained weights : stable diffusion v1.5 Input : Image, ROI Mask, Prompt (‘A clean natural background’) num_inference_step : 30 guidance_scale : 7.5
- **10241024 이미지 → 512512 4개로 분리 **
- 개별 타일 stable diffusion inpainting 적용
- 각 타일 병합해 최종 이미지 생성
일반적으로 stable diffusion은 512512 이미지 처리하게 되어있으며 10241024 이미지 한 번에 처리하게 되면 해상도가 낮아지거나 메모리 부족 문제가 발생할 수 있다. 따라서 각 타일을 독립적으로 처리하여 GPU 메모리 사용량을 효율화하며 세부 디테일을 더 잘 복원하여 최종 이미지의 품질을 향상시킨 결과를 얻을 수 있다. [타일 분할 적용하지 않은 결과]


엣지 강조 알고리즘 결과


정답



정답

Edge Enhancement 알고리즘의 한계

첫째, 동일한 색상/텍스처의 후보 영역 추출 엣지 강조 알고리즘은 색상을 고려하지 않는다. 따라서 동일한 색상이나 텍스처에 대한 고려를 할 수 없다. 둘째, 부적절한 후보 영역 추출 도출한 컨투어의 외접 사각형을 기준으로 한 필터링으로는 정교한 컨트롤이 힘들다. 매우 비정형적인 컨투어 다루기는 많은 연산량이 필요하다. 이 한계로 인해 유의하지 않은 혹은 부적절한 후보 영역들이 추출된다. 셋째, 후보 영역 부족 단순한 이미지의 경우 컨투어 개수 자체의 부족으로 인해 최소/최대 크기와 컨투어 간 최소 거리 필터링을 거치고 났을 때 도출되는 마스크 개수가 적다.
따라서 엣지 강조 알고리즘을 사용하게 되면 예외 상황이 많으며 난이도 조절 등의 세밀한 컨트롤이 힘들어진다.
본 프로젝트는 보다 효율적인 방법으로 외부 종속성을 최소화한 알고리즘을 도출하는 것이 목표이다. 따라서 sam 등의 추가적인 모델을 사용하지 않고 보다 단순하며 현재 한계점을 해결할 수 있는 새로운 알고리즘을 적용하였다.
Final Methodology
Random Bbox Generation 알고리즘
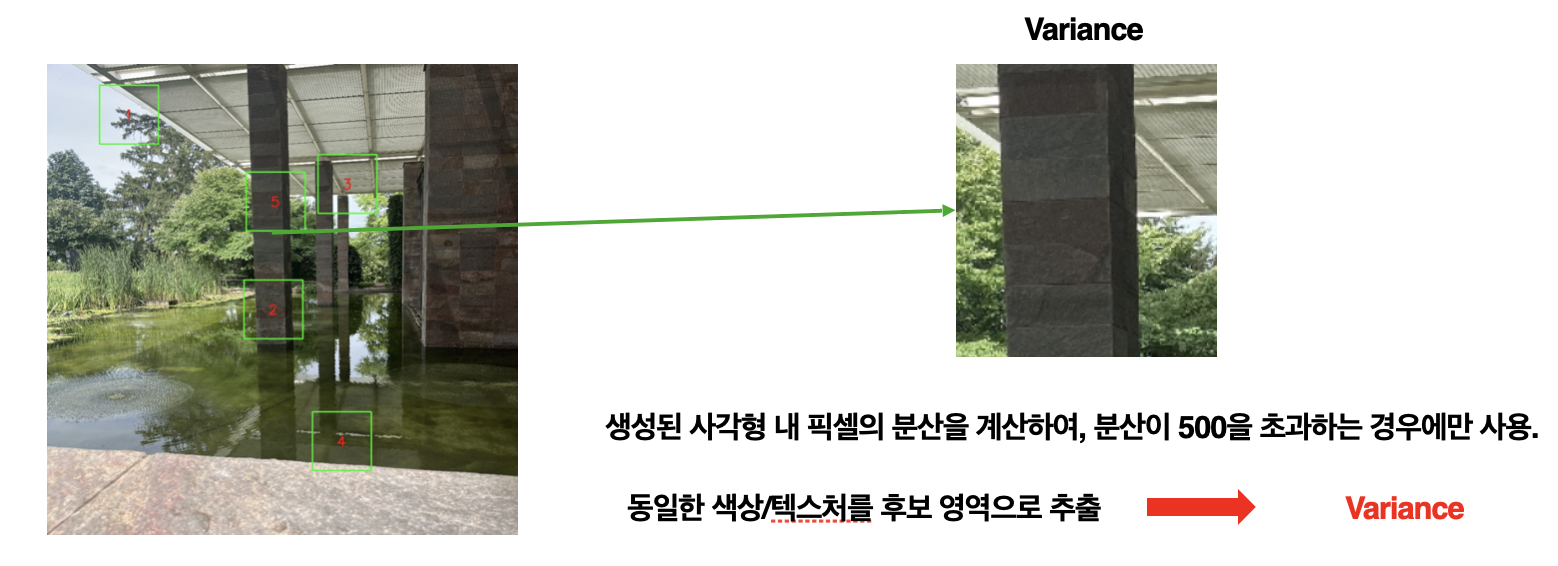
랜덤 사각형 생성 Input : img, num, rect_size, color_threshold, min_distance num만큼 이미지에 랜덤 사각형 생성 필터링을 통해 적절한 마스크 도출 Output : mask 이미지 & 사각형 좌표 리스트 필터 : 최소 거리, 색상 다양성 검사
Color_threshold Filtering 인페인팅하고자 하는 뒷 배경이 동일한 색상이나 텍스처인 경우를 처리하고자 사각형의 내부 픽셀들을 grayscale convert를 적용하여 단일 픽셀들을 0~255로 나타낸다. 사각형 내부 픽셀의 분산 값을 도출한다 color_variance ≥ color threshold일 때, 사각형을 생성한다.
Result


정답



정답



정답
