
1. Intro
여러분은 혹시 GAN을 얼마나 알고 계신가요?
GAN이란 출력값을 만들어 내는 생성자와 입력값이 진짜인지 아닌지 구별하는 판별자가 경쟁적으로 비교하면서 학습하는 모델입니다. 하지만 학습의 불안정성(Training instability)이라는 단점을 가지고 있어 GAN을 이용하여 음성을 생성할 때 듣기에 거북 🐢한 노이즈가 들릴 수 있습니다. 저희는 이러한 부자연스러움을 완화하고자 즉, 자연스러운 음성을 생성하기 위해 여러가지 실험을 진행해보았습니다.
2. Background
2.1 보코더
보코더는 보코딩 (혹은 Speech Generation)은 Text-to-Speech (TTS), Voice Conversion (VC) 등 다양한 Generative Speech Models, 나아가 Speech Enhancement (SE), Speech Super Resolution (SSR), Speech Source Separation 등 다양한 Speech quality restoration 작업에 널리 사용되는 기술입니다.
주어진 음성 신호를 분석, 합성하고 특성을 변형하는 과정을 통해 실제로 들을 수 있는 음성으로 복원하는 것이 보코더의 기본 역할입니다.
2.2 GAN 구조
GAN은 두 개의 신경망인 “생성자” 와 “판별자”로 이루어져 있는 AI 기술을 말합니다. 각각의 신경망은 서로 경쟁을 통해 더 나은 생성물을 만들고, 더욱 정확하게 판별하는 것을 학습합니다. 하지만 GAN 경쟁을 통해 학습을 하는 구조상, 학습의 불안정성, Mode Collapse등의 문제가 자주 발생하곤 했습니다. 이에 많은 사람들이 이 문제들을 해결하기 위해 여러가지 아이디어를 제시했습니다.
2.2.1 WGAN & WGAN-GP
WGAN은 기존 GAN의 문제점인 학습 불안전성을 해결하기 위해 Wasserstein 거리를 도입한 모델입니다. 이 거리는 두 확률분포 간의 차이를 측정하는데, 기존에 사용되던 Jensen Shannon Divergence 보다 학습에 더욱 안정적인 모습을 보여주었습니다.
WGAN-GP는 WGAN이 학습 안정성을 확보한 대신, 모델의 표현성이 줄어드는 Mode Collapse를 해결하기위해 Gradient Penalty라는 개념을 적용한 모델입니다. 이를 “가중치 클리핑”이라고 부르는데, 제한된 데이터 패턴만 생성하게 하는 특정 가중치에 패널티를 적용함으로서 다양한 패턴을 생성하게 유도하게 한 모델입니다.
2.2.2 RSGAN-GP
RSGAN-GP는 GAN에서 상대적인 관점(Relativistic)을 도입하여 “실제 데이터가 생성된 데이터보다 더 진짜처럼 보이는가?”를 학습 목표로 설정한 RSGAN에 GP의 개념을 더한 모델입니다. 이 모델을 통해 모델은 주어진 데이터의 상대적인 비교를 진행할 수 있고, 안정성과 학습 성능을 모두 향상시킬 수 있었습니다.
2.2.3 RPGAN
RPGAN은 진짜 데이터와 가짜 데이터를 상대적으로 평가하는 방법을 적용한 GAN입니다. 위의 RSGAN과 마찬가지로 진짜 데이터와 가짜 데이터의 상대적인 차이를 학습을 하는 것은 같습니다. 하지만 RPGAN은 모든 진짜 샘플과 가짜 샘플 간의 전역적인 비교를 통해서 학습을 하는 것이 아닌, 각 진짜 데이터와 가짜 데이터를 샘플 단위로 비교는 식으로 학습을 하여 국소적인 결정 경계를 생성합니다. 이는 단일 경계로 학습을 진행하는 RSGAN에 비해 모드 붕괴가 일어날 확률을 비약적으로 줄이는 효과를 가져오게 됩니다.
2.3 Perception Informed Loss
Perception Informed Loss는 즉 “인간의 인지적 측면을 반영한 손실”입니다. 간단하게 말하자면 생성된 데이터를 평가할 때, 그 평가 기준이 인간이 평가하는 것과 얼마나 유사한 것인지 측정하는 지표입니다. 저희는 아래 3가지 Perception Informed Loss를 적용하기로 했습니다.
2.3.1 Formant Loss
Formant는 음성 발화에서, 신호의 공명 주파수를 의미합니다. 발성 기관에 의해 생성된 음향 신호에서 강하게 증폭되는 현상으로, 음질과 음색을 결정하는 중요한 요소입니다. 모델이 생성한 음성과, 원본 음성의 Formant 차이를 줄이는 방향으로 학습을 진행하면 원본 음성과 인지적 측면에서 차이가 줄어들 것이라고 생각했습니다.
2.3.2 SCOREQ
SCOREQ는 음성 합성 및 변환 등의 모델에서 생성된 결과물의 품질을 평가하기 위한 MOS 점수를 예측하는 모듈입니다. 모델이 생성한 음성과, 원본 음성의 MOS 점수 차이를 줄이기 위해 SCOREQ 모듈을 이용해 MOS 점수를 추출한 후 두 점수의 L1 차이를 줄여가는 식으로 학습을 진행했습니다.
2.3.3 WavLM
WavLM은 다양한 음성 작업(Task)에 적합한 음성 특성 추출 모델로, Wav2Vec의 구조를 기반으로 확장된 모델입니다. WavLM은 음성 인식(ASR), 화자 분리(Speaker Diarization), 감정 분석(SER) 등 다양한 음성 관련 작업에서 뛰어난 성능을 발휘하도록 설계되었습니다. 또한, Transformer 기반 아키텍처를 통해 입력 데이터를 처리하며, 저수준 음향 정보부터 고수준 의미 정보에 이르기까지 다양한 특징을 추출합니다. 이러한 표현들은 특정 음성 작업의 요구에 맞게 유연하게 활용할 수 있습니다.
2.4 Avocodo
저희는 Base 보코더 모델로 Avocodo를 사용했습니다. Avocodo 모델은 HiFI-GAN 모델을 기반으로 노이즈 문제를 해결하기 위해 CoMBD, SBD 기법을 적용한 모델입니다.
2.4.1 CoMBD & SBD
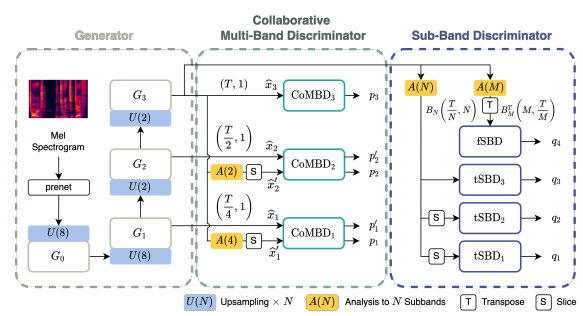
- CoMBD는 생성된 음성을 다양한 해상도를 조절해 중간 출력을 평가함으로써 업샘플링 노이즈를 줄이는 방법입니다.
- SBD는 주어진 음성을 여러 주파수 대역으로 분해하여 각 대역별의 특징을 학습해 음성의 품질을 높이는 방법입니다.
3. Experiments
3.1 Building Baseline
본 실험에서는 기존 Avocodo의 구조를 바꿔 MOS값을 기준으로 모델을 평가하고, 가장 나은 성능의 모델에 Perception Informed Loss를 추가하여 최종 성능을 평가했습니다.
3.2 Data Preprocessing
보코더는 입력값으로 멜 스펙트로그램을 받기에, 저희는 LJ Speech 데이터셋의 wav파일을 멜 스펙트로그램으로 변환시켜 학습에 사용했습니다. 데이터는 학습 데이터 13000개 검증 데이터 100개로 구성되어 있으며, GPU A100의 환경에서 실험을 진행했습니다.
3.3 Train
Base Avocodo 모델은 LSGAN을 사용하여 학습을 진행합니다.
원본 Avocodo의 구조를 다른 GAN으로 변환시켜 성능을 비교하고, Perception Informed Loss를 적용시켜 전체적인 성능을 확인해보았습니다.
4. Results
GAN Stabilization
먼저 GAN의 Stabilization에 대한 실험 결과 입니다. 저희는 MOS Score가 가장 높은 RPGAN을 기반으로 Perceptual Informed Loss 실험을 진행했습니다.
LSD ↓ LSD-HF ↓ RMSE ↓ RMSE f0 ↓ MOS Score ↑
LSGAN 0.13 0.087 0.46 71.64 3.91
LSGAN + R1R2 0.11 0.072 0.35 85.66 3.27
RPGAN 0.12 0.083 0.46 59.79 4.05
RPGAN + R1R2 0.12 0.073 0.40 100.79 3.31
GT_Audio
- LSGAN
- LSGAN + R1R2
- RPGAN
- RPGAN + R1R2
Perceptual Informed Loss
총 3가지의 perceptual informed loss(Formant, SCOREQ, WavLM)를 조합하여 실험을 진행했고 RPGAN와 Format loss를 결합한 모델이 가장 MOS Score가 높은것을 확인할 수 있었습니다.
LSD ↓ LSD-HF ↓ RMSE ↓ RMSE f0 ↓ MOS Score ↑
RPGAN 0.12 0.083 0.46 59.79 4.05
RPGAN + Formant 0.13 0.083 0.47 69.26 4.11
RPGAN + SCOREQ 0.13 0.086 0.45 61.25 4.02
RPGAN + WavLM 0.13 0.089 0.46 60.85 4.01
RPGAN + Formant + SCOREQ 0.13 0.091 0.47 61.29 4.02
RPGAN + Formant + WavLM 0.13 0.085 0.45 60.74 4.07
**RPGAN + Formant
- WavLM + SCOREQ**
0.12 0.082 0.48 60.84 4.06
GT_Audio
- RPGAN
- RPGAN + Formant
- RPGAN + SCOREQ
- RPGAN + WavLM
- RPGAN + Formant + SCOREQ
- RPGAN + Formant + WavLM
- RPGAN + Formant + SCOREQ + WavLM
TTS 에 적용해보기
학습된 보코더를 저희는 TTS(Text to Speech) 분야에 적용하기로 결정했고, Fast Speech2 모델을 활용해 추가적인 프로젝트를 진행해 보았습니다.
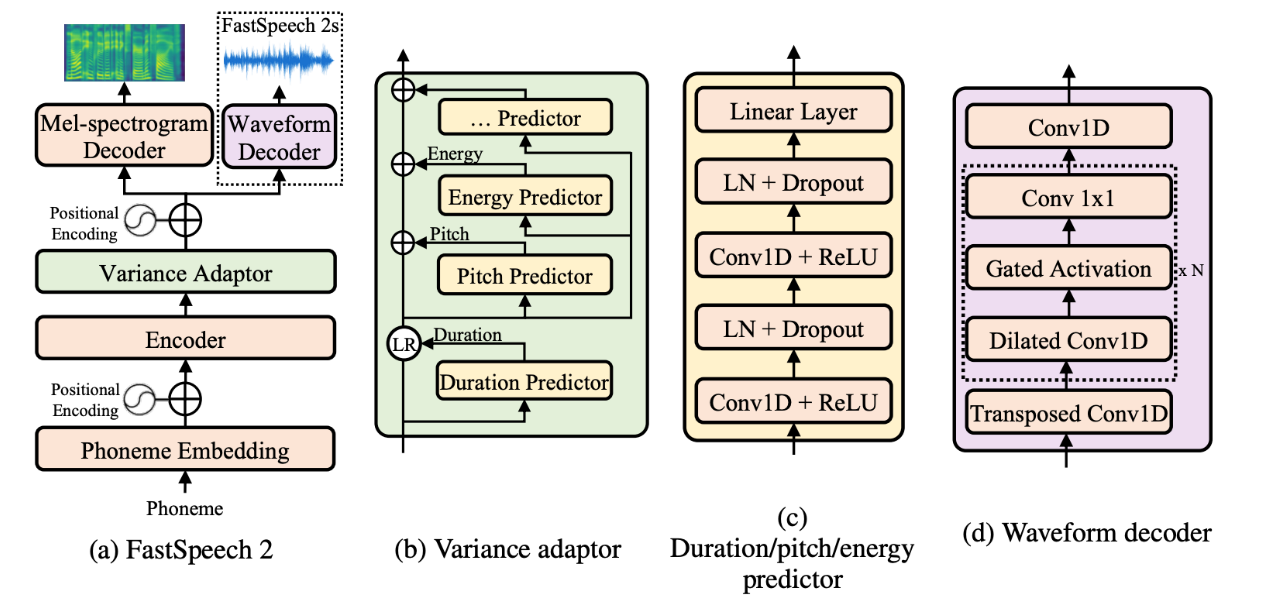
Fast Speech2 모델은 (Non-Autoregressive) 구조로 이루어져 있는 모델로써, 음성을 병렬적으로 빠르게 생성하는 것이 가능한 모델입니다. 또한 학습 데이터에서 F0, Alignment, Energy등의 추가적인 정보를 추출해 합성에 사용함으로써 더욱 자연스러운 음성을 생성하는 것이 가능합니다. 학습을 위해 저희 팀원 중 1명이 약 1시간 반 정도의 녹음을 진행했습니다. 이후 음성에 대한 음소, 발음 간격 추출을 위한 g2p 과정을 진행한 후, Mel-Spectrogram, F0, Alignment, Energy 를 추출했습니다. 이후 저희가 학습시킨 RPGAN + R1R2 보코더를 이용하여 waveform을 생성했습니다.
아래는 그 결과입니다!
- 안녕하세요 이 목소리는 tts입니다.
- 딥다이브 여러분 10기까지 고생하셨습니다.
- 간장공장공장장
- Fastspeech2 모델과 결합하는 과정에서 이슈가 있어서 아직 미완성 상태인 점을 감안해주세요 ^_^
5. Conclusion
저희는 Vocoder가 생성하는 음성의 품질을 최대한 개선해보자는 목표를 가지고 GAN 학습 방식을 바꿔 보고, Perceptual Informed Loss를 추가하였습니다. 시도해본 GAN 학습 방식 종류는 LSGAN, RSGAN, RPGAN, RPGAN+GP입니다. 성능 결과를 토대로 RPGAN 학습 방식을 채택하여 Perceptual Informed Loss를 추가해 보았습니다. 결론적으로 RPGAN + Formant Loss 를 추가한 조합을 통해 Baseline의 MOS 점수인 3.91 보다 무려 0.2나 상승한 4.11 MOS 값을 달성하였습니다. 저희 실험의 한계는 GPU가 부족하여 충분한 Epoch 만큼 학습을 하지 못했다는 점을 들 수 있습니다. 충분히 수렴했다고 보이긴 하지만, 모든 모델은 50 Epoch을 기준으로 학습을 멈췄습니다. 또한 저희가 실험한 3개의 Loss 이외에 더 다양한 Perceptual Informed Loss를 실험해볼 수 있다면 더 의미 있는 실험이 되었을 것 같습니다.