
0️⃣ 프로젝트 추진 배경
*“저 건물이 무슨 건물이냐?”
”에펠탑이요.” 그는 고개를 끄덕이곤 조금 있다 다시 물었다. ”저 건물이 무슨 건물이냐?” ”에펠탑이라니까요.” 그는 고개를 끄덕이며 창밖을 바라보다가 또 같은 말을 했다. ”저 건물이 무슨 건물이라고 했지?” ”에펠탑이요, 에펠탑이라니까요!” 이어령의 『짧은 이야기, 긴 생각』 中 … (?)*
💡 Motivation
해외 여행을 하다 보면 곤란한 상황에 처하는 일이 적지 않게 발생합니다. 어딜 가든 생소하다는 느낌은 쉽게 떠나질 않고, 벼락치기로 암기한 여행 회화는 꼭 필요할 때만 잘 생각나질 않습니다. 그럴 때 나 대신 유창하게 현지인과 소통하고, 모르는 것이면 무엇이든 친절하게 알려주는 누군가가 있다면 어떨까요?
요새는 해외 여행을 갈 때 대부분 로밍 서비스를 사용하기 때문에, 이런 문제에서 비교적 자유로울 순 있습니다. 하지만 인터넷이 참 느리고 답답하다는 생각이 현지에서 항상 들곤 하죠. 스마트폰으로 인터넷을 접속해서, 이미지 검색을 하거나 번역기를 사용하면, 앞서 생각한 문제가 해결될 듯 했지만, 막상 필요할 때는 꼭 인터넷이 느려서 포기하는 일이 종종 생깁니다.
그러면 이제, 인터넷 연결 없이 모든 문제를 해결해주는 AI 챗봇이 있다면 어떨까요?
📈 Trend
그런데 마침, 2025년 세상을 떠들썩하게 만들 키워드 중 하나로 꼽힌 게 바로 On-device AI입니다. Edge AI라고도 불리는 이 기술은, 서버나 클라우드에 연결할 필요 없이 모바일 기기 자체적으로 정보를 처리하는 AI를 말합니다.
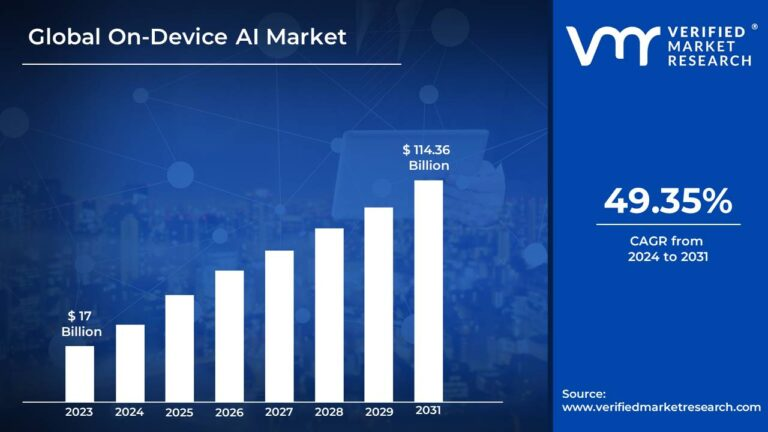
On-device AI 시장은 급격히 성장 중이며, Verified Market Research에 따르면, 2023년 기준 170억 달러 규모에 달했던 시장은 50%에 달하는 연평균 성장률(CAGR)을 보이며, 2031년 1140억 달러 이상의 가치를 가질 것으로 예측됩니다.
또한 Meta, HuggingFace를 비롯한 여러 AI 개발 기업이 디바이스용 LLM을 개발 및 배포하고 있으며, 마찬가지로 Qualcomm, NVIDIA를 포함한 수많은 하드웨어 제조사도 온디바이스용 칩을 개발하는 데 집중하고 있습니다.
이런 배경에서 우리 팀은, “여행 중에서 겪는 문제를 해결할 수 있는 온디바이스 AI를 개발해보자!”라는 목표를 설정하게 됩니다. 특히, 팀 명을 AIFFEL로 지은 이유는 이렇습니다. 라스 베가스에는 프랑스 파리의 에펠탑을 본떠 만든 에펠 타워 뷰잉 데크라는 곳이 있습니다. 우리는 AI가 이 비슷하지만, 실제로는 다른 곳을 구분할 수 있는, 여행 중에 실제로 유행한 정보를 제공할 수 있을 정도의 성능을 갖출 것을 기대했습니다.

그래서 가장 단순한 목표로, 파리의 에펠탑과 라스 베가스의 에펠 타워 뷰잉 데크를 구분할 수 있는 AI를 개발하고자 했습니다. 뒤에서 구체적으로 설명하겠지만, 프로젝트에서 실제로 사용할 AI 모델의 종류는 VLM입니다. VLM은 Vision Language Model의 줄임말로, 대규모 언어 모델(LLM)이 시각 정보를 처리할 수 있도록 정보 처리 능력을 확장한 모델입니다.
그럼 이제부터 AIFFEL 팀의 프로젝트 여정에 대해서 본격적으로 소개하겠습니다.
1️⃣ On-device AI
온디바이스 AI, 그게 뭔데?
온디바이스 AI의 부상 배경
앞서 On-device AI가 무엇인지 간단히 정의를 내렸습니다. 그러면 온디바이스 AI는 기존의 AI와 어떻게 다를까요? 여러분은 ChatGPT를 모바일로 사용해 본 적이 있나요? 그 정도는 아니라도 파파고를나 이미지 검색을 사용한 경험은요? 아마 한두 번쯤은 있을 거라고 생각합니다. 이처럼 인터넷을 통해서 외부 서버에 의존하는 AI를 클라우드 기반 AI라고 합니다. 이미 언급했듯이, 이런 방식은 네트워크 연결에 의존한다는 문제 외에도 몇 가지 단점이 있습니다.
그중 가장 치명적인 건, 데이터 보안 문제입니다. 우리가 대화한 기록, 촬영한 사진이 모두 대기업의 서버에 저장된다고 하면 왠지 모르게 꺼려지죠. AI의 성능이 매우 좋아졌다고 하니까, 나만의 AI 비서를 만들고는 싶은데, 이런 정보를 외부로 내보내는 건 그닥 내키지 않습니다.
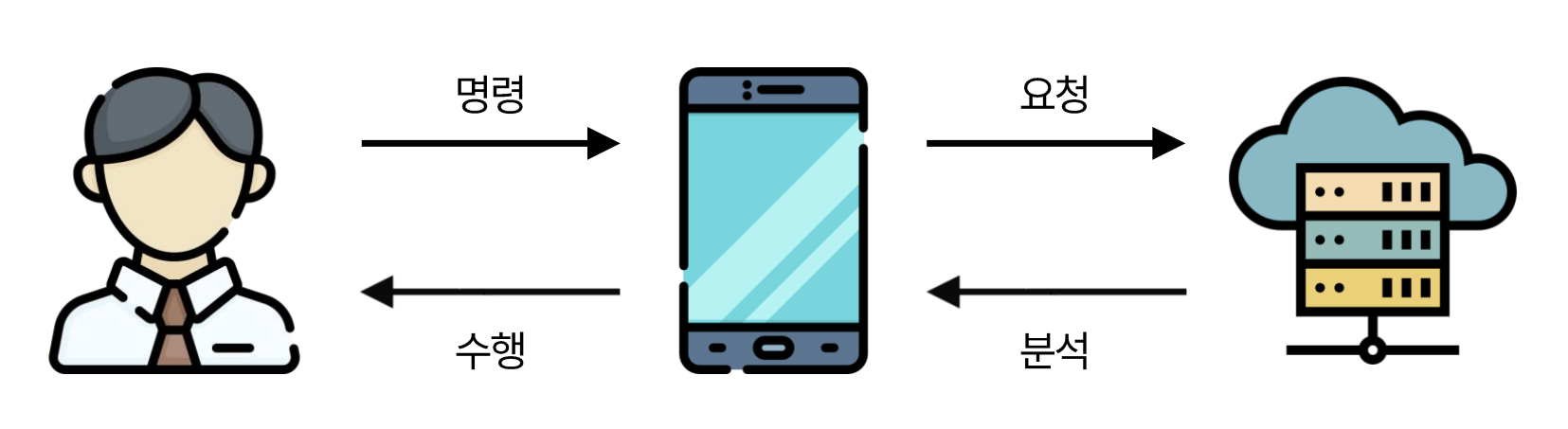
반면, 온디바이스 AI는 외부 서버가 따로 필요하지 않습니다. 이런 방식은, 빠르고, 안전하고, 에너지 효율적이기까지 합니다. 반복하지만, 무엇보다 중요한 점은 보안 문제겠죠. 이 문제에서 자유로워진다면, 진정한 의미의 개인화된 AI 구축이 가능해집니다.
앞서 2025년을 강타할 키워드 중 하나가 바로 On-device AI라고 했습니다. 그리고 그와 함께 항상 언급되는 키워드가 바로 AI 에이전트입니다. LLM이 언어를 이해하고 처리하는 능력이 극도로 발달함에 따라, 인간이 수행하는 대부분의 작업을 대신할 수 있게 되었습니다. 그런데 LLM은 아직 현실 세계와 소통에 어려움을 겪고 있습니다. 하지만 LLM을 검색 엔진, 코딩 도구 등과의 결합하면서 이런 문제를 점차 해결하기 시작했고, 그에 따라 AI 에이전트라는 분야가 부상하게 되었습니다.
자연스럽게 AI가 글 뿐만 아니라 이미지, 오디오 등을 처리하는 방법에 대한 연구도 함께 이뤄졌으며, 고성능 AI를 운용할 수 있는 하드웨어 개발도 가속화되었습니다. 결국 이런 기술적 흐름의 삼박자가 맞아 떨어지며, 온디바이스 AI에 대한 관심이 치솟고 있는 것입니다.
온디바이스 AI 개발의 구성 요소
온디바이스 AI를 구현하기 위해 필요한 기술은 크게 하드웨어와 소프트웨어로 구분할 수 있습니다. 하드웨어의 핵심은 NPU와 같이 AI 모델의 연산을 효율적으로 처리할 수 있는 반도체를 설계하는 게 핵심입니다. 그리고 소프트웨어는 AI 모델이 컴퓨터보다는 비교적 사양이 낮은 모바일 기기에서도 사용될 수 있도록 경량화를 하는 게 핵심입니다. 그럼 각각에 대해서 조금 더 알아보죠.
SoC
SoC는 System on Chip의 약자로, 하나의 IC칩(직접 회로) 내에CPU, GPU, NPU, RAM, Communication module 등 다양한 컴포넌트를 통합한 칩을 말합니다. 모바일 디바이스에서 SoC는 기기 성능에 핵심적인 부품으로 작동하게 됩니다.
- CPU: 일반적인 계산 및 운영체제 담당
- GPU: 그래픽 렌더링 및 비디오 처리 담당
- RAM: 단기 기억 장치 및 데이터 흐름 관리 담당
- Communication module: LTE, 5G Wi-Fi, Bluetooth 등 다양한 통신 지원 담당
SoC는 이러한 다양한 기능을 하나의 칩에 통합함으로써 전력 효율과 크기를 줄이고, 제조 비용을 절감할 수 있습니다. NPU는 이러한 컴포넌트 중 하나입니다.
NPU
NPU(Neural Processing Unit)은 인공지능(AI) 및 머신러닝 연산을 효율적으로 처리하기 위해 설계된 전용 프로세서입니다. NPU는 딥러닝 알고리즘의 복잡한 수학적 연산을 병렬로 신속하게 처리할 수 있어, AI 추론 기능을 보다 빠르고 효율적으로 수행할 수 있습니다.
- 이미지 및 비디오 처리: 사진의 실시간 보정, 얼굴 인식, 객체 인식 등
- 음성 인식 및 처리: 음성 명령의 인식 및 처리
- 자연어 처리: 실시간 번역, 구문 수정, 요약 등
NPU 칩을 개발하는 대표적인 회사로 삼성(Exynos), 퀄컴(Snapdragon) 등이 있습니다. 이러한 NPU의 특성을 활용하기 위해 여러 최적화 회사에서는 NPU 칩에 딥러닝 모델을 탑재하고자 합니다. 그러나 그 과정이 녹록지 않습니다. 기본적으로 NPU는 지원하는 연산자 한계가 분명합니다. 최근에는 FP16까지 지원하기는 하나, 효율성이 매우 낮습니다. 따라서, 주로 낮은 정밀도(INT 8,4)를 사용해야 하고 모델의 양자화가 필수적입니다. 또한, NPU 칩은 Systolic array라는 아키텍쳐를 통해 데이터와 행렬 연산을 최적화합니다. Systolic array는 다수의 연산 유닛을 동시에 작동시켜 대규모 데이터와 연산을 병렬 처리합니다. 그러나, Systolic array는 특정 연산에 최적화되어 있어, 다양한 종류의 연산을 처리하는 데 한계가 있습니다. 따라서, NPU 칩이 지원하지 않는 연산을 사용하기 위해서는, 딥러닝 모델의 특정 연산을 직접 지원하는 연산자로 수정해줘야 합니다. 그리고, Systolic array의 연산 유닛은 고정된 크기를 갖습니다. 예를 들어, 연산 유닛의 크기(지원하는 연산 크기)가 16x16이고, 연산해야 하는 모델의 행렬 크기가 20x20이라면 연산 유닛을 2개 사용해야 하므로 20x20 크기의 행렬을 연산하기 위해 32x32 크기의 연산 유닛을 사용해야 합니다. 물론 최근에는 동적으로 연산 유닛의 크기를 조절합니다.
이어서 소프트웨어 기술을 알아보겠습니다. AI 경량화란 말 그대로 AI 모델을 운용하는 데 사용하는 자원을 줄이는 모든 방법을 말합니다. 온디바이스 분야에서 AI 경량화란 일반적으로, AI 모델의 크기를 줄이는 것을 의미하는데, AI 모델의 크기란 모델이 갖는 파라미터의 개수 또는 AI 모델을 사용하는 데 필요한 메모리의 양을 말합니다. 모델 파라미터의 개수를 줄이는 방법은 성능에 유의미한 영향을 미치지 않는 파라미터를 제거하는 가지치기(프루닝, Pruning) 또는 대형 모델이 학습한 지식을 바탕으로 소형 모델을 효율적으로 훈련하는 지식 증류(Knowledge Distillation)등이 있습니다. 반면에 AI 모델을 사용하는 데 필요한 메모리의 크기를 줄이는 방법으로는양자화(Quantization)가 있습니다.
팀원이 모두 하드웨어에 최적화 기술은 익숙하지 않기 때문에, 이 프로젝트에서는 소프트웨어 최적화에 집중했습니다. 그 중에서도 양자화 개념을 주로 사용하였는데, 구체적인 건 후술하겠습니다.
2️⃣ Methodology
개발에 필요한 기술은?
LLM, VLM
도입부에서 프로젝트에 실제로 사용할 모델의 종류는 VLM이라고 했습니다. 그리고 이는 이미지 처리 능력을 갖춘 LLM이라고 했죠. 여기서는 각각을 아주 조금 더 구체적으로 살펴보고, 이어서 양자화가 어떤 개념인지 알아보겠습니다.
인공지능을 잘 몰라도, 대규모 언어 모델(Large Language Model, LLM)이라는 용어는 이제 익숙할 겁니다. 본래 언어 모델(Language Model, LM)은 인간의 언어, 즉 자연어를 이해하고 처리하는 모델을 말합니다. 처리라는 용어는 다양한 의미로 사용될 수 있는데, 최근 가장 흔히 사용되는 형태는 생성(Generation)입니다.
언어는 같은 단어나 표현도 상황에 따라 다른 의미를 가질 수 있죠. 이처럼 자연어는 워낙 복잡하다 보니, 하나의 작은 모델이 다양한 과제를 수행하기에는 어려움이 있었습니다. 그런데, 일반적으로 AI 모델은 크기가 클 수록 더 나은 성능을 보이는 걸로 알려져 있습니다. 그러다 보니까, 복잡한 언어를 잘 처리할 수 있는 모델을 만드는 과정에서 자연스럽게 언어 모델의 규모가 거대해졌습니다. 그렇게 LLM이 탄생하게 됩니다.
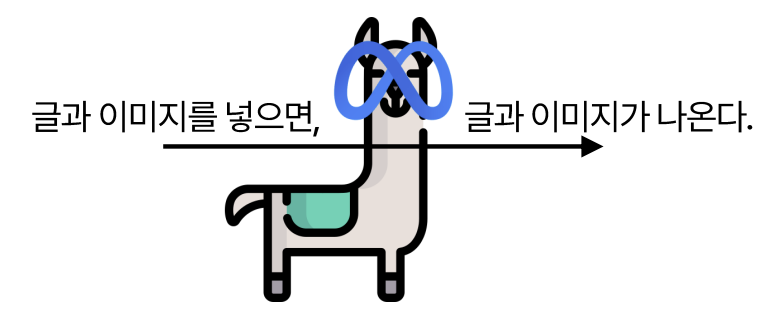
LLM의 동작 원리를 가장 단순하게 표현하면 아래 왼쪽 그림과 같습니다. 글을 넣으면, 글이 나오죠. ChatGPT가 대표적이죠. VLM은 LLM에 시각 정보를 처리할 수 있는 별도의 장치를 더한 것입니다. 그래서 Vision Language Model이라는 이름이 붙은 것입니다. 아래 오른쪽 그림과 같이, 글과 이미지를 넣으면 글과 이미지 또는 둘 중 하나가 출력됩니다. 일반적으로는 글과 이미지를 넣으면 글이 나오는 형태를 갖습니다.
참고로 언어 정보 외 시각 정보를 처리할 수 있는 LLM을 VLM 외에도 Multimodal LLM(MLLM), Large Multimodal Model(LMM)라고 부르기도 합니다. 본래 멀티모달이란 언어, 이미지 외에도 오디오를 비롯한 다른 어떤 형태의 데이터든 포함할 수 있지만, 여기서는 그냥 세 표현이 같은 걸 의미한다고 생각하겠습니다.

경량화 개요
이미 여러 뉴스를 통해 접했을테지만, AI 모델의 성능은 이제 놀라울 정도로 좋아졌습니다. 그게 LLM이든 VLM이든 다른 어떤 형태의 AI 모델이든 말이죠. 그런데 문제는 AI 모델의 크기가 너무 거대해졌다는 겁니다. 성능이 좋으면 실제로 우리의 일을 대신 해줬으면 하는데, 그러기에는 운용하는 데 필요한 비용이 너무 많이 듭니다. 그래서 최근에는 작은 모델에서 큰 모델의 성능을 따라하는 방법이 연구되고 있습니다. 앞서 말한 양자화, 프루닝, 지식 증류 등이 그러한 방법들인데, 여기서는 양자화에 대해 구체적으로 설명하겠습니다.
양자화
양자화는 AI 모델의 파라미터가 사용하는 공간을 절약하는 방법입니다. 컴퓨터 과학을 공부한 분들이라면 데이터 타입이라는 용어가 익숙할 겁니다. 대표적으로 실수형(Float)과 정수형(Int)이 있습니다. 실수형 데이터 타입의 대표적인 형태인 float32를 사용하면 하나의 데이터를 표현하는 데, 32개의 비트를 사용해서 연속적인 실수(Real Number)로 표현합니다. 정수형 데이터 타입의 대표적인 형태인 Int8을 사용하면 하나의 데이터를 표현하는 데, 8개의 비트를 사용해서 정수(Integer Number)로 표현합니다.
양자화는 같은 데이터를 표현하는 데 사용하는 비트의 수를 줄이는 과정입니다. 기존에 32개의 비트로 표현한 데이터(또는 정보)를 8개의 비트만으로 표현하겠다는 것이죠. 그런데 32 비트와 8 비트는 엄연히 표현력이 다릅니다. 그래서 양자화 과정에선 어쩔 수 없이 정보 손실이 발생합니다. 양자화의 핵심은 이 정보 손실을 최소화하면서, 한정된 메모리를 효율적으로 사용하는 것입니다. 여기서는 어떻게 양자화 손실을 줄이는지를 설명하기 보다는, 온디바이스 AI에서 양자화가 어떻게 사용되는지, 그리고 그와 관련된 개념들엔 무엇이 있는지를 설명하겠습니다.
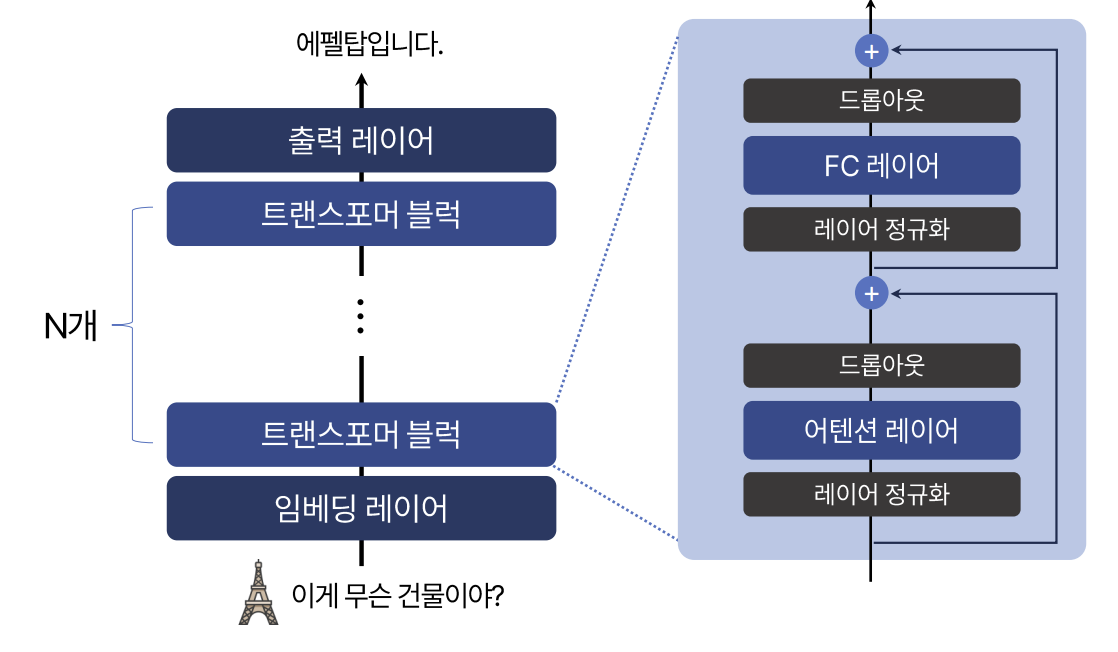
그 전에 양자화가 적용되는 대상이 무엇인지 간단히 살펴보겠습니다. 아래는 일반적인 언어 모델의 구조입니다. 어떤 입력이 들어가면 가장 먼저 임베딩 레이어(Embedding Layer)를 거칩니다. 임베딩 레이어는 자연어를 기계가 이해할 수 있는 형태로 변환해 줍니다. 가장 먼저 입력의 의미를 이해하는 부분이라고 보면 됩니다.
이어서 여러 개의 트랜스포머 블럭(Transformer Block)을 거칩니다. 각각의 트랜스포머 블럭은 그림의 오른쪽과 같이 세부적인 구성 요소로 이뤄집니다. 일일히 설명하진 않겠습니다. 트랜스포머 블럭은 입력된 글의 의미를 맥락을 고려해서 조금 더 명확하게 이해하는 역할을 합니다. 예를 들어, 문장에 “배”라는 단어가 있으면, 이게 먹는 배인지, 바다에 떠다니는 배인지 등 주변 단어를 통해 의미를 구체화하는 거죠.
맥락을 고려해서 입력된 글을 충분히 이해했으면, 마지막으로 출력 레이어(Output Layer)에 이릅니다. 참고로 이 레이어는 분류 헤드(Classification Head), 언임베딩(Unembedding)과 같은 용어로 표현되기도 합니다. 출력 레이어는 입력에 대한 적절한 응답을 생성하는 역할을 한다고 보면 됩니다. 원래 정확한 설명으로는, 출력에 이어질 적절한 다음 단어를 예측(Next Token Prediction)하는 것이지만, 이 상황에선 그냥 질문에 적절한 답을 생성한다고 설명하겠습니다.
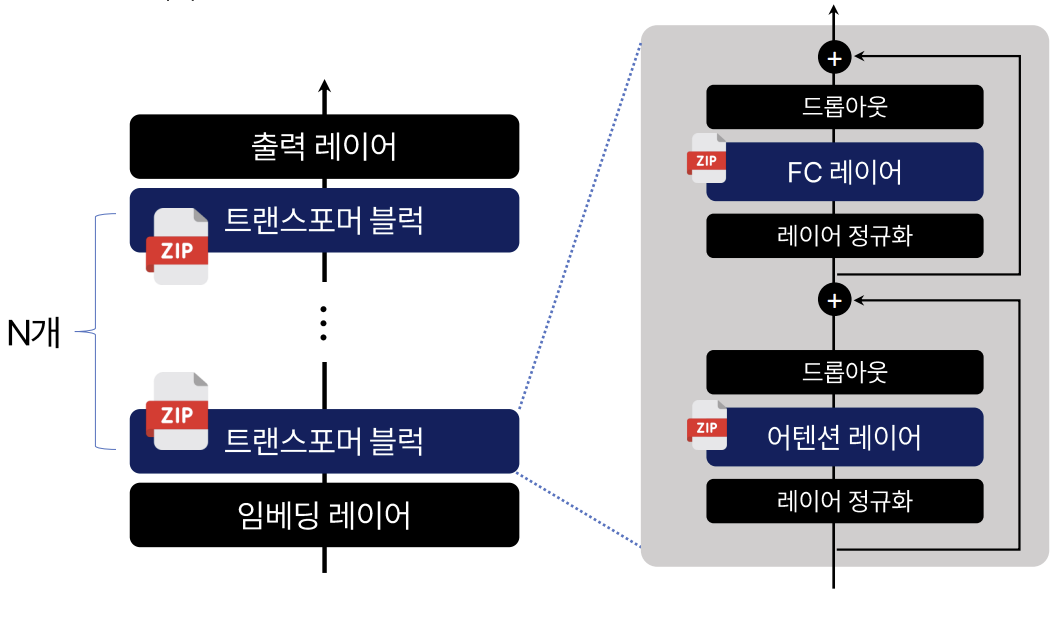
여기서부터는 조금 복잡해집니다. 앞서 언어 모델의 구조를 설명한 이유는, 각각의 구성 요소는 숫자형 데이터로 표현되기는 하지만, 모두를 양자화하진 않기 때문입니다. 일반적으로는 아래 그림처럼 아이콘이 달려 있는 부분만 양자화를 수행합니다. 경우에 따라, 임베딩 레이어와 출력 레이어를 양자화하기도 하지만, 일반적으론 모델 용량의 대부분을 차지하는 트랜스포머 블럭을 양자화합니다.
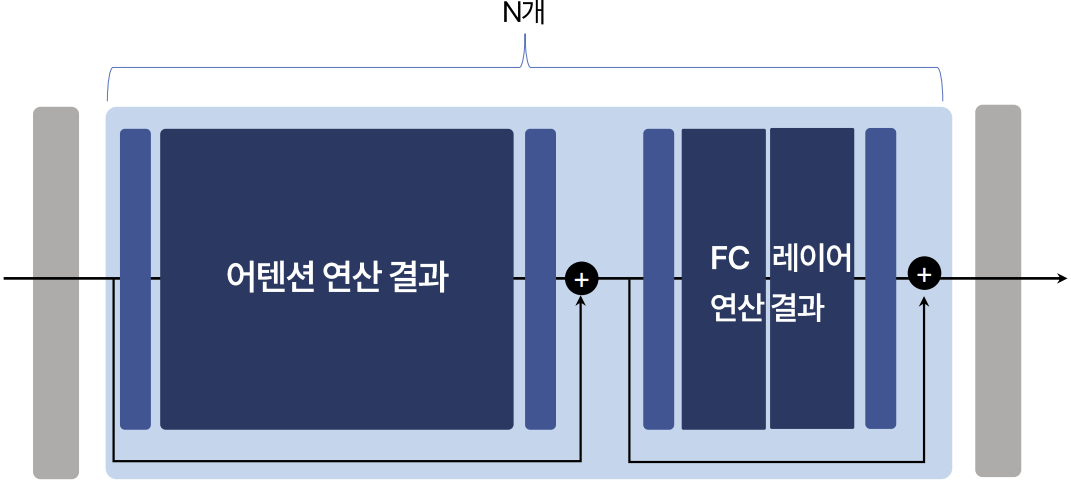
그런데 LLM을 사용할 때, 메모리를 발생하는 요소가 몇 가지 더 있습니다. 앞서 살펴본 건, 단순히 LLM을 불러오는 상황만을 생각한 겁니다. LLM이 입력을 처리하는 과정에서는 중간 연산 결과(Activation)를 저장해야 합니다. 그런데 이 또한 메모리 사용량이 적지 않습니다. 따라서 Activation도 필요에 따라 양자화를 수행합니다.
여기서부터는 트랜스포머 아키텍처와 어텐션 메커니즘을 잘 모른다면 내용이 전혀 이해가 되지 않을 수 있습니다. 이런 게 있구나 정도만 보고 넘어가셔도 됩니다. 언어 모델이 입력을 처리할 때는, 먼저 입력 문장을 구성하는 각 토큰 사이의 관계를 수치로 표현합니다. 그러면 아래와 같이 각 토큰 사이의 관계를 수치화한 행렬을 생각할 수 있습니다.
마찬가지로 언어 모델이 출력을 생성할 때는 한 번에 출력 문장 전체를 생성하는 게 아니라, 출력을 구성하는 토큰을 순차적으로 하나씩 생성합니다. 이 때, 입력 문장을 구성하는 토큰과 새로 생성된 토큰에 대한 관계를 매번 새롭게 계산할 필요가 있습니다. 그래야만, 이어지는 토큰을 계속해서 상황에 맞게 예측할 수 있습니다.
예를 들어, 아래 그림과 같이 최초에 “고양이”라는 입력이 들어왔고, 이어서 “가”, “매트”라는 토큰을 생성한 상황을 생각해 보죠. 앞으로 “위에”라는 토큰을 예측해야 하는데, 사실 “고양이”, “가”, “매트”라는 토큰들 사이의 관계는 이미 앞에서 계산을 했습니다. 그래서 이 계산 결과를 버리지 않고 유지한다면, “위에”라는 토큰과의 관계만을 새롭게 계산하면 됩니다. 이처럼 앞선 단계에서 이미 생성한 토큰들 사이의 관계를 유지하는 기술을 KV Caching이라고 합니다.
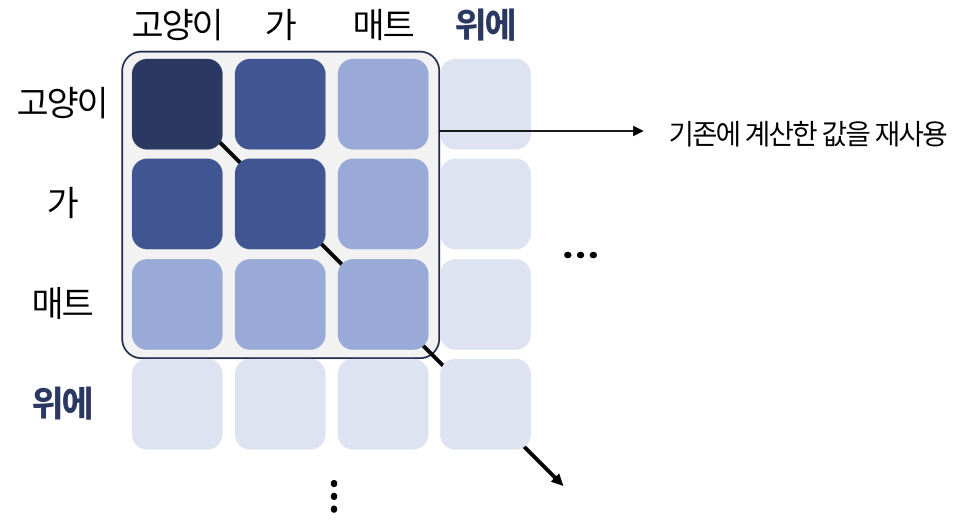
문제는 이 KV Cache도 처리할 문장이 길어지게 되면, 또 다른 메모리 부하를 유발합니다. 그래서 Activation과 마찬가지로 KV Cache도 상황에 따라 양자화를 적용합니다. 결국 정리하자면, 양자화가 적용되는 대상은 총 세 가지입니다. 모델 가중치(Model Weight 또는 Model Parameter), 중간 연산 결과(Activation), 그리고 KV Cache입니다.
Source Transformation
앞서 언급한 것처럼 NPU에 딥러닝 모델을 탑재하고, 추론하려면 연산자들을 수정해줘야한다고 했습니다. 이는 NPU의 연상 효율성을 극대화 시켜 추론 속도를 향상시키기 위함이지요. 그러나, CPU에서도 비슷한 기능을 사용할 수 있습니다. 바로 XNNPACK 이라는 가속기입니다. XNNPACK은 CPU 칩의 연산자를 최적화시켜 추론 속도를 향상시켜 줍니다.
- Replace SDPA data type: 여러 데이터 타입의 입력을 FP32로 변환해 고정시킴. 이는 XNNPACK 라이브러리의 연산이 FP32에 최적화되어있기 때문입니다.
- KV Cache → Custom KV Cache: 기존의 [B, H, S, D] 구조를 [B, S, H, D] 로 변경합니다. 이는 하드웨어 친화적인 데이터 구조를 사용하기 위함입니다.
Executorch
ExecuTorch는 PyTorch의 새로운 온디바이스 추론 런타임으로, 모바일 및 엣지 디바이스에서 AI 모델을 효율적으로 실행하기 위한 엔드투엔드 솔루션입니다. 스마트폰, 웨어러블, 임베디드 시스템 등 다양한 장치에서 PyTorch 모델을 효과적으로 배포할 수 있도록 설계되었습니다. 주요 특징:
- 이식성: ExecuTorch는 고성능 스마트폰부터 제한된 리소스를 가진 임베디드 시스템 및 마이크로-컨트롤러까지 다양한 컴퓨팅 플랫폼과 호환됩니다.
- 생산성: 개발자는 PyTorch 모델 작성, 변환, 디버깅, 배포에 이르는 동일한 툴체인과 SDK를 활용하여 다양한 플랫폼에서 작업할 수 있습니다.
- 성능: 경량화된 런타임을 통해 CPU, NPU, DSP 등 하드웨어의 전체 기능을 활용하여 최적의 성능을 제공합니다.
ExecuTorch는 현재 Meta의 AR, VR, Family of Apps 등 다양한 제품과 서비스에서 활용되고 있으며, 개발자 커뮤니티의 참여를 통해 온디바이스 AI 스택을 더욱 발전시키고 있습니다. 또한, ExecuTorch는 ARM의 Kleidi 기술과 통합되어, ARM CPU에서 대규모 언어 모델(LLM)을 실행할 수 있도록 지원합니다. 이 통합을 통해 클라우드부터 엣지 디바이스에 이르는 다양한 환경에서 AI 워크로드를 효율적으로 실행할 수 있습니다. ExecuTorch는 PyTorch 스택의 핵심 구성 요소로, 개발자들이 쉽게 접근하고 활용할 수 있도록 설계되었습니다.
3️⃣ Implementation
그래서 실제로 무엇을 만들었나? 모델 구현 과정은 크게 3단계로 구분됩니다. 가장 먼저 데이터 생성 및 수집 단계, 다음으로 모델 훈련 단계, 마지막으로 양자화 변환 단계입니다. 데이터 생성 단계부터 살펴보겠습니다. 일반적으로 VLM 학습을 위한 QA 데이터셋은 확보하기 쉽지 않습니다. 저희는 2020년 공개된 Google Landmark 데이터셋을 기반으로 QA 데이터셋을 직접 생성했습니다. Google이 제공한 데이터셋은 아이디로 표현되어 있어 이를 랜드마크명으로 변환한 아래 데이터셋을 활용했습니다.
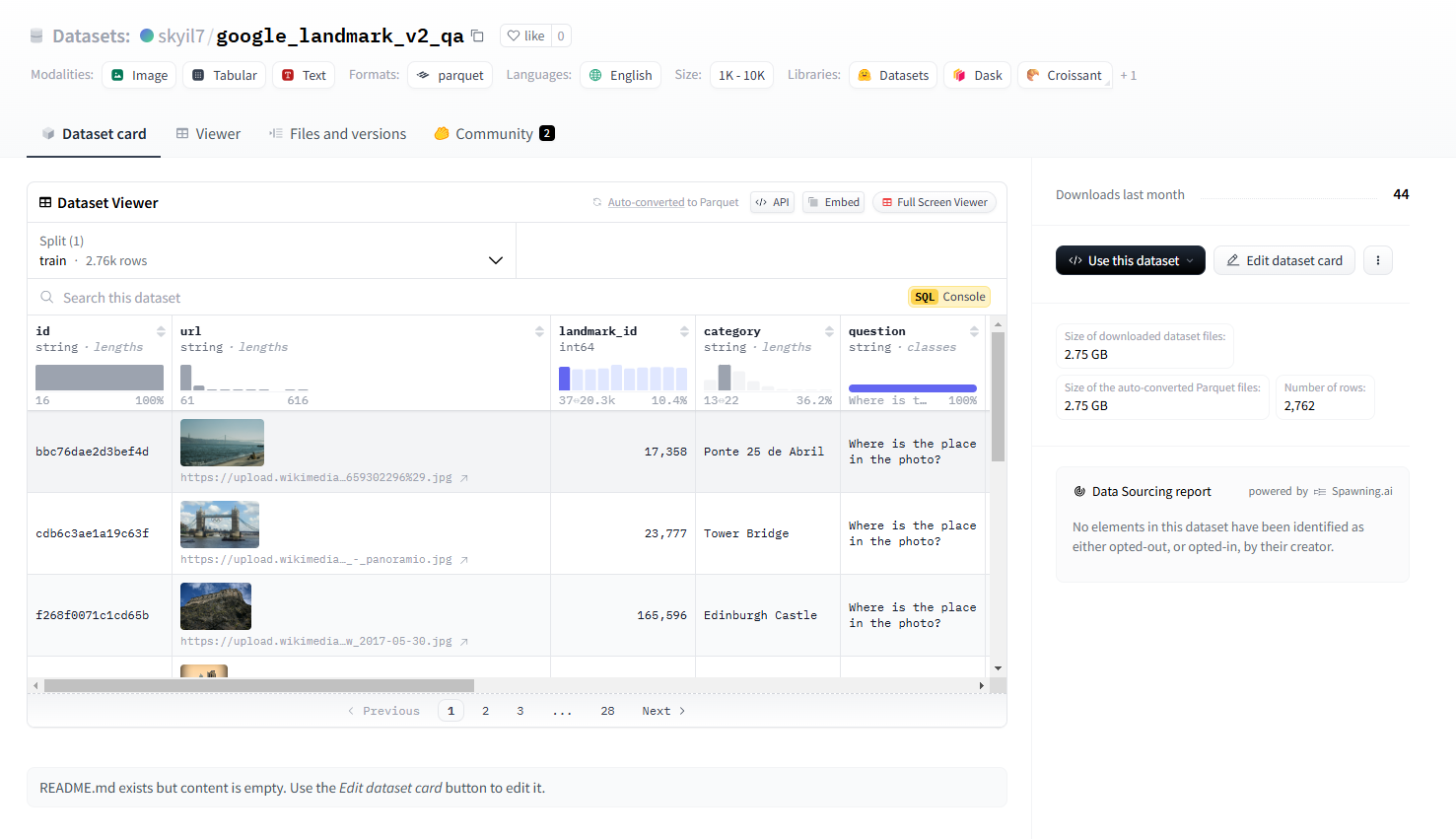
데이터 생성에 활용한 모델은 Llama 3.2 11B Vision입니다. 이 모델은 지난해 9월 Meta가 공개한 오픈 소스 모델로 속도보다 양질의 데이터를 생성하기 위해 성능을 우선시하여 선정했습니다. 11B가 개인이 다루기에 충분히 큰 모델이긴 하지만 그래도 지식의 양이 많지 않을 수 있기 때문에 랜드마크 데이터셋이 제공하는 카테고리 정보를 반영하여 질문과 답변을 생성해달라는 프롬프트를 작성했습니다. 생성 과정에서는 뜻밖의 효과를 얻을 수 있었는데요. 바로 사진의 카테고리와 사진이 일치하지 않는 경우 자체적으로 필터링한다는 것입니다. 예를 들어, 에펠탑 카테고리에 포함된 사진 중 에펠탑이 아닌 사진이 포함되어 있는 경우 에펠탑과 관련된 정보가 아니라 이미지 자체를 설명해줍니다. 이렇게 약 500개의 QA 데이터를 생성했습니다.

Question: What is the main subject of this image?
Answer: The main subject of this image is a cityscape with a large building and trees in the foreground.<|eot_id|> 데이터 필터링 예시
다음으로 파인튜닝 단계입니다. 파인튜닝에 활용한 모델은 LLaVA-1.5-7B입니다. 파인튜닝 모델은 실제로 저희가 추출하여 양자화해야 하는 모델이기 때문에 크기와 성능을 모두 고려했습니다. 파인튜닝은 LoRA 모듈을 활용했습니다. 이 데이터셋은 위키피디아에 공개된 정보를 바탕으로 구성되어 있습니다. XNNPACK 8DA4W Embedding Layer quantization: int4(groupsize: 32)
4️⃣ Analysis
프로젝트의 의의와 한계, 그리고 발전 방향은? 결과적으로 디바이스에 LLM과 VLM을 올리는 데는 성공을 했습니다. 도입부에서 언급한 대로 On-device AI의 장점을 활용할 수 있게 된 것이죠. 이제 네트워크에 연결되어 있지 않아도, 모르는 정보를 LLM에게 물어보거나 번역을 요청할 수 있습니다. 게다가 이 대화 내용은 외부로 유출되지도 않고, 필요에 따라 개인의 선호도를 반영한 개인화된 AI를 구축할 수도 있습니다.
다만 몇 가지 한계는 분명히 존재합니다. Executorch 프레임워크에 대한 이해가 부족했기 때문에, 다양한 모델을 자유롭게 디바이스에 올리진 못했습니다. VLM은 7B 규모의 Llava 모델을 사용하였고, LLM은 3B의 Llama 모델을 사용했습니다. 최근에는 1B 내외의 VLM 및 LLM도 여럿 배포되었기 때문에, 이런 모델을 사용해서 빠른 추론 속도를 누려보고 싶었지만, 결과적으로는 잘 되지 않았습니다.
한 가지 아쉬운 점은, Executorch는 현재도 계속해서 개발이 되고 있는 단계입니다. 우리가 사용하는 동안에도 라이브러리 업데이트가 활발하게 이뤄졌고, 오늘 되던 기능이 내일 될지 보장이 안되는 상황이었습니다. 몇가지 버그는 사용자인 우리가 직접 수정했어야 할 정도입니다. 아무래도 첨단에서 연구되는 산업이다 보니, 약간의 불안정성이 있었습니다.
또 한 가지 한계는 프로젝트를 실제로 진행한 기간이 넉넉하지 못해서, 모델 학습에 필요한 데이터셋을 만족스러운 수준으로 구축하지 못했다는 점입니다. 여유가 있었다면, 여행 지식에 특화된 모델을 구축한 후에 디바이스에 올리는 과정까지를 경험하고 싶었지만, 기존에 계획한 모든 것을 이루진 못했습니다.
다만 LLM 사전 학습과 파인 튜닝은 온디바이스 AI에 대한 이해가 부족해도 데이터셋만 마련이 된다면 해결할 수 있는 문제입니다. 따라서 여행 정보를 포함한 데이터와 디바이스에서 직접 수집한 데이터를 활용한다면 개인화된 AI를 구축할 수 있습니다. 이를 바탕으로 향후에는 하나의 거대 모델을 사용하는 게 아니라, 목적에 따라 작은 규모의 모델을 여러 개 사용하는 방식으로 가볍지만 강력한 모델을 개발할 수 있을 것으로 기대됩니다.
5️⃣ Conclusion
관심 가져주셔서 감사합니다! 프로젝트를 마치고 나서 든 생각은, “On-device AI 구축은 어렵다”는 것입니다. 하지만 이 산업, 그리고 연구에는 이름만 대면 모두 알만한 다수의 거대 기업이 모두 뛰어들고 있는 만큼 중요하고, 유망하다고 생각합니다. 전세계로 보면, 메타, 애플을 비롯한 여러 기업이 디바이스용 AI 모델 개발에 집중하고 있고, 국내에서도 삼성, LG 등의 대기업이 같은 연구를 진행하고 있습니다. 소프트웨어 뿐만 아니라 하드웨어 개발사도 AI용 칩을 개발하거나, 기존에 개발한 반도체를 최적화하는 데 최선을 다하고 있죠. 적어도 지금은, 온디바이스 AI 시장은 매우 유망하다고 예측할 수 있습니다.
AI의 성능은 이미 검증을 마쳤습니다. 그리고 이제는 일상에 파고들 때입니다.